 FPGA常用运算模块-除法器
FPGA常用运算模块-除法器

写在前面
本文是本系列的第四篇,本文主要介绍FPGA常用运算模块-除法器,xilinx提供了相关的IP以便于用户进行开发使用。
除法器
除法器生成器IP 创建了一个基于基数 2 非恢复除法或具有预分频的高基数除法的整数除法电路。 Radix-2 算法利用 FPGA 逻辑来实现一系列吞吐量选项,包括单周期,而高基数算法在较低吞吐量下利用 DSP 切片,但通过重用来减少资源。
该IP符合 AXI4-Stream 的接口。操作数最大为 64 位宽的整数除法。提供Radix-2、LUTMult 和High Radix 实现算法以允许选择资源和延迟权衡。可选操作数宽度、同步控制和可选延迟。可选的除以零检测。
三种除法器实现方式
LUTMult
除数倒数的简单查找估计,后跟乘数。 由于倒数估计中需要偏差,因此仅支持余数输出类型。 如果用于创建小数输出,此偏差会引入偏移(错误)。 推荐用于小于或等于 12 位的操作数宽度。 此实现方式使用 DSP Slice、块 RAM 和少量 FPGA 逻辑原语(寄存器和 LUT)。 对于可以使用 Radix2 或 LUTMult 选项的操作数宽度,由于使用了 DSP 和块 RAM 原语,LUTMult 解决方案提供了使用较少 FPGA 逻辑资源的解决方案。
该实现方式特点如下:
提供了带有整数余数的商;
可以使用流水线并行架构以提高吞吐量;
可配置延迟;
2 到 17 位的分频宽度;
2 到 12 位的除数宽度(被除数宽度和除数宽度之和限制为 23 位);
独立的除数和除数位宽;
使用单个时钟的完全同步设计;
支持无符号或二进制补码有符号数。
Radix-2
使用整数操作数的基数 2 非恢复整数除法,允许生成小数或整数余数。 对于小于 16 位左右的操作数宽度或需要高吞吐量的应用程序,建议使用该种实现方式。 实现使用 FPGA 逻辑原语(寄存器和 LUT)。Radix2 解决方案不使用 DSP 或块 RAM 原语,因此当其他地方需要这些原语时,建议使用此实现。
该实现方式特点如下:
提供整数或小数余数的商;
流水线并行架构以提高吞吐量;
减少流水线大小与吞吐量可选;
被除数宽度从 2 到 64 位;
除数宽度从 2 到 64 位;
独立的被除数、除数和小数位宽;
使用单个时钟的同步设计;
支持无符号数或二进制补码有符号数;
可以实现 1/X(倒数)功能。
High Radix
带有预缩放的高基数除法。 对于大于 16 位左右的操作数宽度,建议这样做。 此实现使用 DSP Slice 和 Block RAM。
该实现方式特点如下:
通过预缩放启用高基数除法;
提供可选的商和小数输出;
可配置宽度、同步控制、可选延迟和除以零检测;
使用 DSP Slices。
Divider Generator 内核使用三种实现中的一种。 LUTMult 推荐用于非常小的操作数宽度、高吞吐量以及必须最小化切片使用的情况。 对于较小的操作数宽度、高吞吐量或必须最小化 DSP 切片使用的情况,建议使用 Radix-2 解决方案。 对于较大的操作数宽度,建议使用高基数解决方案。
三种实现方式延迟对比
分频器内核的延迟是 AXI4-Stream 配置参数和所选算法延迟的函数。 当 AXI4-Stream 模式设置为非阻塞且核心算法和吞吐量设置为每个时钟周期输入一个样本时,延迟仅是一个常数。 如果选择了完整的 AXI4-Stream 行为。 这是因为 FIFO 用于管理此模式的数据,并且 FIFO 的深度增加了延迟。
LUTMult
完全流水线化的 LUTMult 的延迟为 8。
Radix-2
完全流水线分频器的延迟(内核生成第一个有效输出之前所需的启用时钟周期数)是被除数位宽的函数。 如果需要小数输出,则完全流水线延迟也是小数位宽的函数。 一般来说:
对于整数余数除法器,完全流水线延迟的数量级为 M,其中 M 是商的宽度。
对于分数余数除法器,完全流水线延迟的数量级为 M + F,其中 F 是分数输出的宽度。
下表提供了用于分频器选择的完全流水线延迟公式的列表。 通过完整的流水线,可以实现最大可能的性能。 当每格时钟数为 1 时,可以手动将延迟设置为介于 0 和表 2-1 中所示值之间的数字。 这允许以降低内核可以计时的最大时钟频率为代价来减少内核的延迟。 减少延迟会减少使用的寄存器数量,但 LUT 计数保持大致相同。
| Signed | Fractional | Clocks Per Division | Fully Pipelined Latency |
|---|---|---|---|
| FALSE | FALSE | 1 | M+A+2 |
| FALSE | FALSE | >1 | M+A+3 |
| FALSE | TRUE | 1 | M+F+A+2 |
| FALSE | TRUE | >1 | M+F+A+3 |
| TRUE | FALSE | 1 | M+A+4 |
| TRUE | FALSE | >1 | M+A+5 |
| TRUE | TRUE | 1 | M+F+A+4 |
| TRUE | TRUE | >1 | M+F+A+5 |
M = 被除数和商宽度,F = 小数宽度,A = AXI 接口的总延迟。
High Radix
表中位宽范围为被除数和商宽度 + 分数宽度。
| 4 to 12 | 13 to 26 | 27 to 40 | 41 to 54 | 55 to 68 | 69 to 82 |
|---|---|---|---|---|---|
| 2 | 3 | 4 | 5 | 6 | 7 |
表中行位宽范围为被除数和商宽度 + 分数宽度。
| Divisor Width | 4 to 12 | 13 to 26 | 41 to 54 | 27 to 40 | 55 to 68 | 69 to 82 |
|---|---|---|---|---|---|---|
| 4 to 8 | 16 | 20 | 29 | 24 | 33 | 37 |
| 9 to 18 | 17 | 21 | 30 | 25 | 34 | 38 |
| 19 to 32 | 18 | 22 | 31 | 26 | 35 | 39 |
| 33 to 35 | 19 | 23 | 32 | 27 | 36 | 40 |
| 36 to 48 | 20 | 24 | 33 | 28 | 37 | 41 |
| 49 to 52 | 22 | 26 | 35 | 30 | 39 | 43 |
| 53 to 54 | 23 | 27 | 36 | 31 | 40 | 44 |
三种实现方式吞吐量对比
LUTMult
此解决方案始终支持全吞吐量。
Radix-2
Clocks per Division 参数允许对吞吐量与资源进行一系列选择。当 Clocks per Division 设置为 1 时,内核是完全流水线化的,因此每个时钟周期的最大吞吐量为一个分频,但使用的资源最多。 Clock per Division 设置为 2、4 和 8,对于较小的内核尺寸,这些相应的因素会降低吞吐量。AXI 接口为非阻塞提供 0 的额外延迟,无输出线程的阻塞为 1,输出线程为阻塞 (m_axis_dout_tready) 为 3。但是,当选择阻塞模式时,延迟会随运行时间而变化。
High Radix
迭代过程是作为循环来实现的,以减少资源。 这意味着必须推迟新输入,直到在迭代电路中完成先前的计算。 因此,最大可能的吞吐量是每个时钟 1/N 分频,其中 N 是所需的迭代次数。 然而,为了达到这个最大吞吐量,输入可能需要是突发的。 这是因为迭代引擎可以通过管道的每个阶段进行流水线化,为隔行分割提供一个轮播位置。
添加 AXI4-Stream 接口后,平均吞吐量保持不变。 阻塞模式为数据提供了 FIFO 缓冲元素,因此无法对内核何时准备好接受新数据进行确定性预测。 对于 NonBlocking 模式,时序更可预测。 Vivado IDE 中的分频器生成器接口提供分频器以恒定间隔连续接受输入的速率(N 中的 1)的反馈。 这在接口的吞吐量字段上表示,并表示为每 N 个启用的时钟周期 1 个输入。
IP核图示及端口介绍
IP核图示如下图所示:
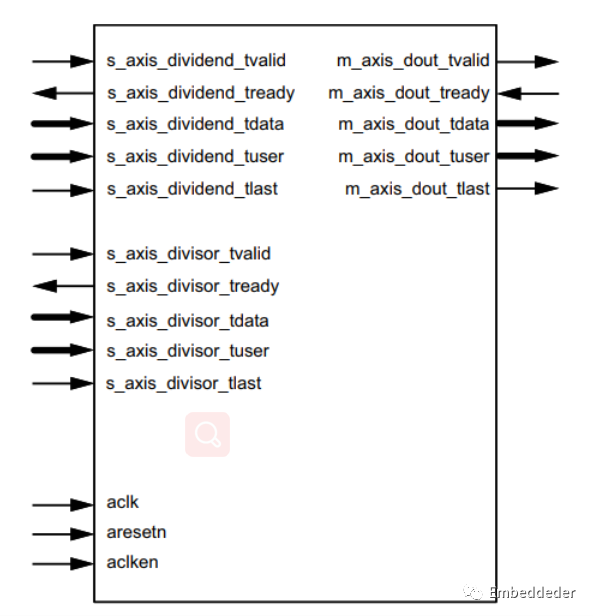
| Signal | I/O | Optional | Description |
|---|---|---|---|
| aclk | I | No | 时钟 |
| ACLKEN | I | Yes | 高有效使能 |
| ARESETn | I | Yes | Active-Low 同步清零(可选,始终优先于 ACLKEN) ARESETn 应被置位或置位不少于两个 aclk 周期。 |
| s_axis_dividend_tvalid | I | No | s_axis_dividend 通道的 tvalid。(被除数) |
| s_axis_dividend_tready | O | Yes | s_axis_dividend 通道的 tready。(被除数) |
| s_axis_dividend_tdata | I | No | s_axis_dividend 通道的 tdata。 (被除数) |
| s_axis_dividend_tuser | I | Yes | s_axis_dividend 通道的 tuser。(被除数) |
| s_axis_dividend_tlast | I | Yes | s_axis_dividend 通道的 tlast。(被除数) |
| s_axis_divisor_tvalid | I | No | s_axis_divisor 通道的 tvalid。(除数) |
| s_axis_divisor_tready | O | Yes | s_axis_divisor 通道的 tready 。(除数) |
| s_axis_divisor_tdata | I | No | s_axis_divisor 通道的 tdata。 (除数) |
| s_axis_divisor_tuser | I | Yes | s_axis_divisor 通道的 tuser。 (除数) |
| s_axis_divisor_tlast | I | Yes | s_axis_divisor 通道的 tlast。(除数) |
| m_axis_dout_tvalid | O | No | m_axis_dout 通道的 tvalid。(结果) |
| m_axis_dout_tready | I | Yes | m_axis_dout 通道的 tready。(结果) |
| m_axis_dout_tdata | O | No | m_axis_dout 通道的 tdata。(结果) |
| m_axis_dout_tuser | O | Yes | m_axis_dout 通道的 tuser。(结果) |
| m_axis_dout_tlast | O | Yes | m_axis_dout 通道的 tlast。(结果) |
运算方式区别
LUTMult
此参数化解决方案将M位宽的变量除数除以N位宽的变量除数。输出由商和整数余数组成。除法的结果是M位宽的商和N位宽的整数余数。
被除数商除数整数余数
当选择有符号运算时,所有操作数和结果都使用两个补号,但会导致结果的大小减少一位。
分数余数整数余数除数
LUTMult解决方案支持可选的零除输出。对于除零,商和余数结果是未定义的。LUTMult解决方案始终支持全吞吐量(每个时钟周期一个结果)。延迟可以配置为完全流水线所需的最大值(超过该值,进一步的寄存器将无法提高性能)。由于LUTMult解使用倒数的常数有限精度估计乘以被除数,从而获得结果,因此除数的最大宽度是被除数宽度的函数。操作数宽度之和限制为23位。就商和余数的符号而言,LUTMult解决方案以与Radix2解决方案相同的方式处理负操作数。
Radix-2
此参数化解决方案将M位宽的变量除数除以N位宽的变量除数。输出由商和整数余数或分数结果(商继续超过二进制点)组成。在整数余数情况下,除法的结果是商的M位宽字段和整数余数的N位宽字段。对于带整数余数的有符号模式,商和余数的正负也对应于下式。
被除数商除数整数余数
在分数情况下,结果是商的M位宽字段,结果的分数部分为F位宽字段。
分数余数整数余数除数
当选择有符号运算时,所有操作数和结果都使用一个2补符号位,从而使结果的大小减少一位。
分数余数整数余数除数
对于带分数输出的带符号模式,在商和分数字段中都有符号位。对于除零,商、余数和分数结果未定义。IP是高度流水化的。核心的吞吐量是可配置的,可以从每个分区1个时钟周期减少到每个分区2、4或8个时钟周期,以减少资源。可以独立设置被除数和除数的位宽度。商的位宽度等于被除数的位宽度。整数余数的位宽度等于除数的宽度。对于分数输出,余数位宽度与被除数和除数无关。核心处理2到64位的数据范围,用于被除数、除数和分数输出。
除法器可用于实现X的倒数;这就是1/X函数。为此,将被除数位宽度设置为2,并选择分数模式。然后,对于无符号或有符号运算,被除数输入都绑定到01,并且X值通过除数输入提供。上电复位或ARESETn后,IP的输出商和分数的零,直到出现新结果。
High Radix Solution
高基数实现在采用加速高基数除法算法之前,通过预缩放操作数执行除法。该设计是完全流水线的最大时钟频率。首先,对除数进行归一化,然后对其倒数进行估计。两个操作数都乘以此估计值,使除数更接近1。预刻度的精度和精确度决定了在每次后续迭代中可以解析的商位数。预缩放除数接近于1的事实允许新商位的估计正好是上一次迭代剩余的顶部位。迭代操作本身以进位保存表示法执行,因此没有长进位链限制性能。由于只使用剩余的顶部位作为估计值,且除数不完全为1,因此每次迭代的内部结果中都会出现错误;因此,在每次迭代中解析的商位与先前解析的位略微重叠,以允许在后续迭代中校正错误。 由于迭代计算由进位-保存乘法和减法组成,因此它非常适合于DSP(乘法-加法)切片,从而提供高效、低延迟的迭代。
协议描述
该内核遵循AXI4流规范。
AXI4-Stream注意事项
转换为AXI4流接口,使得接口协议更加标准并增强了IP的互操作性。除aclk、ACLKEN和ARESETn等常规控制信号外,除法器发生器的所有输入和输出均通过AXI4流通道传输。通道由tvalid和tdata always以及几个可选端口和字段组成。在除法器中,支持的可选端口为tready、tlast和tuser。tvalid和tready一起执行握手以传输消息,其中有效负载为tdata、tuser和tlast。除法器对tdata中包含的操作数进行操作,并在输出通道的tdata中输出结果。除法器不使用input、tuser和tlast,但提供了以与tdata延迟传输的功能。
除法器使用输出tuser保持除法零(divide_by_zero)指示信号。这种将tlast和tuser从输入传递到输出的功能旨在简化系统中除法器的使用。例如,除法器可能对流式分组数据进行操作。在此示例中,可以将核心配置为通过打包数据通道的tlast,从而减小工作量。
基本握手协议
下图显示了AXI4流通道中的数据传输。
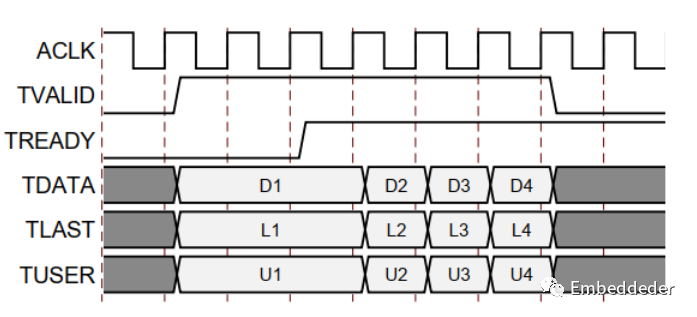
tvalid 由通道的源(主)端驱动,而tready 由接收器(从)驱动。 tvalid 表示有效载荷字段(tdata、tuser 和 tlast)中的值有效。 tready 表示从机已准备好接收数据。 当循环中 tvalid 和treaty 都为TRUE 时,就会发生传输。master 和 slave 分别为下一次传输适当地设置了 tvalid 和tready。
非阻塞模式
除法器提供了一种模式,用于简化从该内核以前的非 AXI 版本迁移。 非阻塞用于表示一个输入通道上缺少数据不会导致另一通道上的传入数据被缓冲。 因为在 NonBlocking 模式下,输出通道没有不稳定的信号。 并非总是需要 AXI4-Stream 的完整流量控制。 使用 FlowControl 参数或用户界面字段选择阻塞或非阻塞行为。Blocking 或 NonBlocking 的选择适用于整个IP,而不是单独的每个通道。 通道仍然具有非可选的 tvalid 信号,这类似于采用 AXI4-Stream 之前许多内核上的新数据 (ND) 信号。 由于没有阻止数据流的功能,内部实现大大简化,因此这种模式需要的资源更少。 对于希望从 AXI 之前的版本迁移到此版本且更改最少的用户,建议使用此模式。
当所有当前的输入通道都接收到一个有效的 tvalid(并且tready被断言),那么这个操作是有效的。这是为了允许从 v3.0 进行最小的迁移。如果一个通道接收到 tvalid 而另一个没有接收,则不会发生操作,即使存在和断言tready也是如此。 因此,与完全符合 AXI4-Stream 的阻塞模式不同,在非阻塞模式下可以忽略单个通道上的有效事务。 出于性能考虑,ARESETn 是在内部的,这会将其操作延迟一个时钟周期。效果是在取消置位 ARESETn 之后的循环中,内核仍然复位并且不接受输入。 tvalid 在此周期的输出通道上也处于非活动状态。
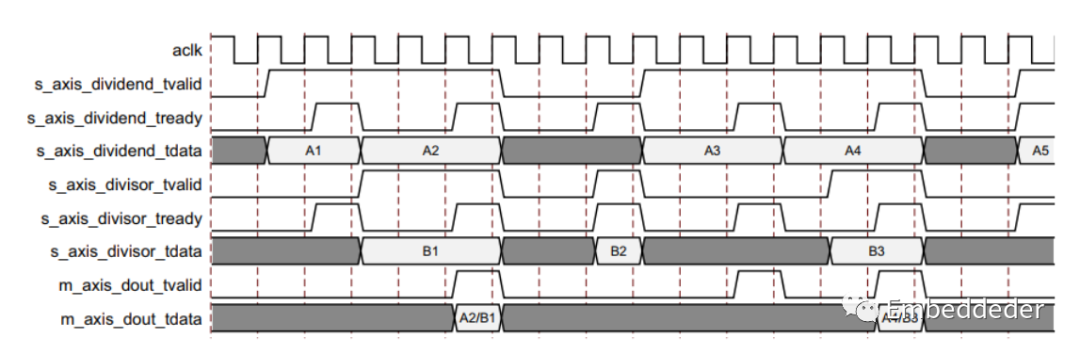
上图显示了操作中的非阻塞模式。 内核的延迟为零。 正如 s_axis_dividend_tready 和 s_axis_divisor_tready 所指示的,它们最终是相同的信号,内核可以每三个周期接受一次数据。 由于 s_axis_divisor_tvalid 被置低,被除数通道中的数据 A1 被忽略。 数据输入 A2 和 B1 被接受,因为 tvalids 和 traily 都被断言。
阻塞模式
术语“阻塞”意味着每个通道都在缓冲数据以供使用。 AXI4-Stream 的完整流控制有助于系统设计,因为数据流是自我调节的。使用 FlowControl 参数选择阻塞或非阻塞行为。 背压(tready)的存在可以防止数据丢失,因此只有在下游数据路径准备好处理数据时才会传播数据。
除法器有两个输入通道和一个输出通道。 当所有输入通道都有可用的有效数据时,就会发生操作,结果在输出上可用。 如果由于 m_axis_dout_tready 为低而阻止输出装载数据,则数据会在内部的输出缓冲区中累积。当这个输出缓冲器快满时,内核停止进一步的操作。 这可以防止输入缓冲区为新操作装载数据,以便在输入新数据时填充输入缓冲区。 当输入缓冲区填满时,它们各自(s_axis_divisor_tready 和 s_axis_dividend_tready)被置为无效以防止进一步输入。
从某种意义上说,这两个输入通道是相互关联的,每个通道都必须先接收经过有效的数据,然后才能继续进行操作。 因此,有一种额外的阻塞机制,其中一个输入通道不接收有效数据,而另一个接收。 在这种情况下,经过有效的数据存储在通道的输入缓冲区中。
在这种情况下,经过有效的数据存储在通道的输入缓冲区中。 在这种情况的几个循环之后,接收数据的通道的缓冲区被填满并且该通道的tready被取消断言,直到饥饿的通道接收到一些数据。
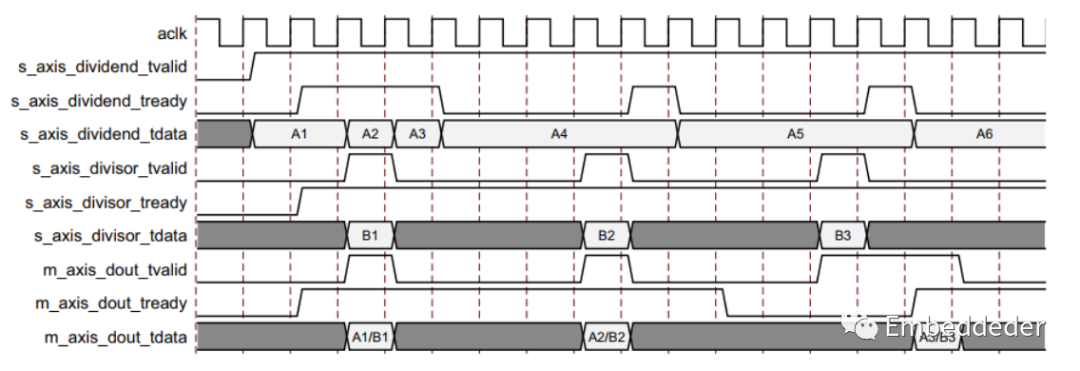
上图显示了阻塞行为和背压。 通道 s_axis_dividend 上的第一个数据与通道 s_axis_divisor 上的第一个数据配对,第二个与第二个数据配对,依此类推。 这展示了“阻塞”的概念。 概念上使用通道名称 s_axis_dividend 和 s_axis_divisor。 两者都可以表示除数或被除数通道。
并且在图中进一步显示了数据输出是如何被延迟的,不仅是延迟,还有握手信号 m_axis_dout_tready。 是背压的。 输出上的持续背压以及输入上的数据可用性最终会导致核心缓冲区饱和,从而导致核心发出信号,表明它无法再通过取消断言来接受进一步的输入通道的tready信号。
这个例子中的最小延迟是两个周期,但需要注意的是,Blocking 操作中的延迟并不是一个有用的概念。 一个重要的思想是每个通道都充当一个队列,确保每个通道上的第一个、第二个、第三个数据样本与其他通道上的相应样本配对以进行每次操作。
TDATA包
AXI4-Stream 接口中的遵循特定的命名法。 在该内核中,操作数通过通道 tdata 端口传入或传出内核。 为了简化协议的互操作性,如果需要时,首先扩展 tdata 中可以独立使用的每个子字段,以适应 8 位倍数的位字段。 对于输出 DOUT 通道,结果字段符号扩展到字节边界。 由字节方向添加的位被内核忽略并且不会导致额外的资源使用。
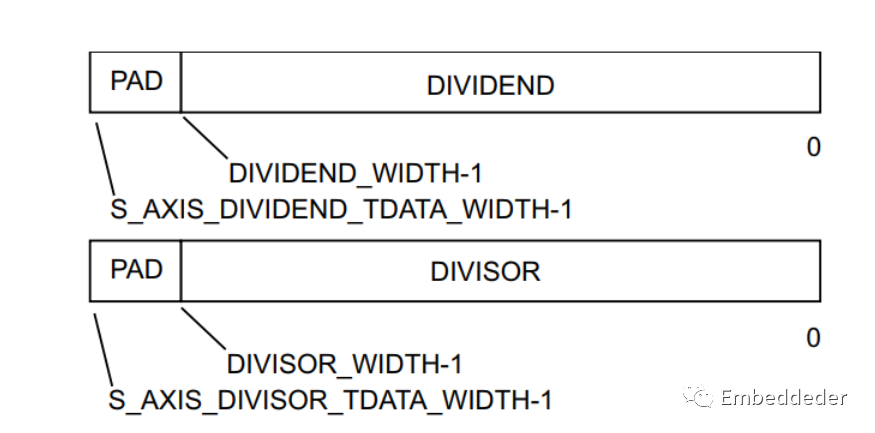
被除数和除数通道的 TDATA 结构
输入通道 Dividend 和 Divisor 仅在其 tdata 字段中携带其操作数。 对于每个操作数占据最低有效位。tdata 端口宽度本身是包含操作数所需的字节宽度的最小倍数。
输出(DOUT)通道的TDATA结构
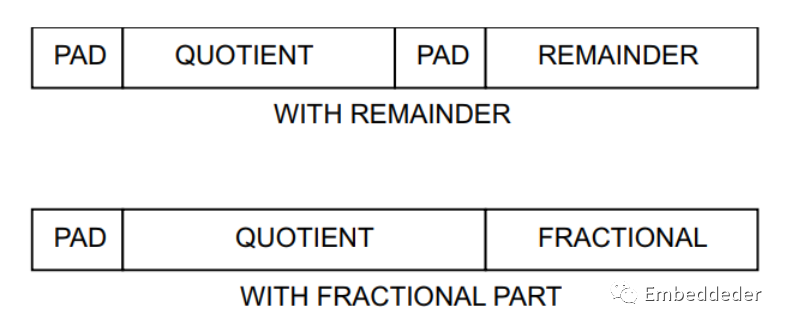
m_axis_dout_tdata 的结构比较复杂。 此端口包含商和(余数或小数输出如果存在)。当余数类型设置为余数时,两个输出被认为是分开的,因此在串联以形成 m_axis_dout_tdata 信号之前是面向字节的。 当余数类型为小数时,小数部分被视为商的扩展,因此这两个字段在填充到下一个字节边界之前连接。
TLAST and TUSER握手
AXI4-Stream 中的 tlast 用于表示数据块的最后一次传输。 tuser 用于限定或扩充 tdata 中的主要数据的辅助信息。 除法器在每个样本的基础上运行,其中每个操作都独立于之前或之后的任何操作。因此,不需要在除法器上放置 tlast。
在每个输入通道上支持 tlast 和 tuser 信号纯粹是作为系统设计的一个可选辅助,在这种情况下,通过除法器的数据流确实具有一些分组化或辅助字段,但不是与除法器相关。 传递 tlast 或 tuser 的功能消除了通过除法器将延迟匹配到 tdata 路径的负担,该路径可以是可变的。
当选择Divide_by_zero detect(除以零检测)时,指示除以零的信号在输出通道tuser端口的最低有效位上输出。
TLAST Options
每个输入通道的 tlast 是可选的。 每个存在时,都可以通过除法器,或者,当多个通道启用了 tlast 时,可以通过 tlast 输入的逻辑 AND 或逻辑 OR。 当任何输入通道上不存在 tlasts时,输出通道也没有 tlast。
TUSER Options
每个输入通道的 tuser 是可选的。 每个都有用户可选择的宽度。 Divider IP也可能生成一个 tuser 位。 这是选择divide_by_zero 检测时。divide_by_zero 位占据最低有效位置,然后是来自除数通道的 tuser,然后是来自最高有效位置的被除数通道的 tuser。

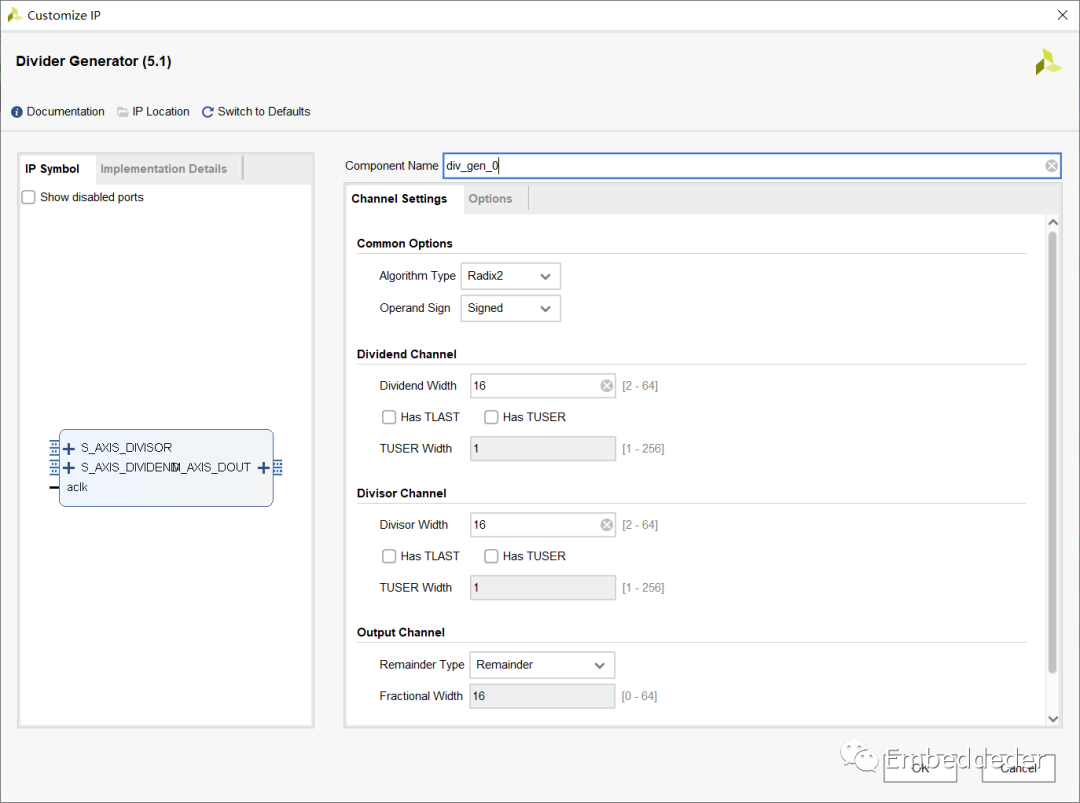
除法器IP配置
除法器IP配置界面如下:
Common Options
描述了两种实现的参数,并允许选择除法器实现。
Algorithm Type: 算法类型:这在基数 2、LUTMult 和高基数划分解决方案之间进行选择。
Dividend Channel
Dividend Width: 被除数宽度,指定在 DIVIDEND (s_axis_dividend_tdata) 和 QUOTIENT(m_axis_dout_tdata 的子字段)上提供的整数位数。 这必须设置为满足最大可能的商结果。 由于二进制补码表示的非对称性,从被除数到商的位增长是可能的,但仅适用于最大负数除以负数的单个组合(即 -2(M-1)/-1)。 如果需要适应这种情况,被除数(以及商)的宽度可以扩展 1 位。
Has TLAST: 指定此通道是否具有 tlast 端口。 除法器不使用此信息。 该项用于简化系统设计。tlast信息以和数据路径相同的延迟传送到输出通道。
Has TUSER: 指定此通道是否具有 tuser 端口。 与 tlast 一样, 除法器不使用此信息。 该项用于简化系统设计。 tuser 位以和数据路径相同的延迟传送到输出。
TUSER Width: 当 Has tuser 为 TRUE 时可用,这将设置此通道的 tuser 端口的宽度。
Divisor Channel
Divisor Width: 除数宽度。指定在 s_axis_divisor_tdata 的 DIVISOR 字段上提供的整数位数。 当配置有余数输出时,余数的宽度也等于该参数的值。
Has TLAST: 指定此通道是否具有 tlast 端口。 除法器不使用此信息。 该项用于简化系统设计。 tuser 位以和数据路径相同的延迟传送到输出。
Has TUSER: 指定此通道是否具有 tuser 端口。 与 tlast 一样, 除法器不使用此信息。 该项用于简化系统设计。 tuser 位以和数据路径相同的延迟传送到输出。
TUSER Width: 当 Has tuser 为 TRUE 时可用,这将设置此通道的 tuser 端口的宽度。
Output Channel
Remainder Type: 余数类型。这可以在输出 tdata 端口 (m_axis_dout_tdata) 的 FRACTIONAL 上显示的余数类型小数和余数之间进行选择。分数余数类型是高基数的唯一选项。
Fractional Width: 小数宽度。如果选择小数余数类型,这将确定在输出通道 (m_axis_dout_tdata) 的小数字段上提供的位数。 选择高基数时,总输出宽度(商部分加小数部分)限制为 82。
商的宽度等于被除数的宽度,并在被除数通道部分设置。
如果divide_by_zero 检测处于有效状态,tuser 端口的宽度是当前输入通道tuser 字段的总和加上1。 如果任一输入通道具有 tlast 端口,则该通道也具有 tlast 端口。
Detect Divide-by-Zero: 检测被零除。确定内核在输出 tuser 端口 (m_axis_dout_tuser) 中是否有 DIVIDE_BY_ZERO 以在执行除以零时发出信号。
Radix-2 Options
Clocks Per Division: 分频时钟。确定 Radix-2 解决方案的吞吐量(输入(或输出)之间的时钟间隔)。 此参数的低值会导致高吞吐量,但也会导致更多资源使用。
High Radix and LUTMult Options
Number of iterations (High Radix only) 迭代次数(仅限高基数): 只读,报告高基数操作模式为每次除法执行的迭代次数。 这设置了分频器的最大吞吐量。为实现此吞吐量,必须在s_axis_dividend_tready 和 s_axis_divisor_tready 输出请求时立即提供操作数。
Number of iterations (High Radix only)吞吐量(仅限高基数) :只读,报告以恒定速率提供操作数时除法器可维持的最大吞吐量。 在 AXI 阻塞模式下,由于缓冲,吞吐量可能略高。 当FlowControl 设置为 NonBlocking 并且输出通道 DOUT 没有tready 时,此速率适用。
AXI4-Stream Options
Flow Control: 流控制。阻塞或非阻塞。非阻塞模式提供了从之前版本的分频器生成器内核的更简单的迁移路径。 阻塞模式以一些额外的资源和延迟为代价,简化了进出其他 AXI4-Stream 阻塞模式内核的数据流管理。
Optimize Goal: 优化目标。这仅适用于阻塞模式。 选择ACLKEN并优化目标设置为资源时,可能会降低性能。
Output has TREADY: 选择输出通道是否有tready信号。 这是允许来自下游的背压所必需的。例如,如果连接到另一个 AXI4-Stream Blocking内核。 如果没有tready,下游电路无法停止来自分频器的数据流,但会节省一些资源。
Output TLAST Behavior: 输出 TLAST行为。选择输出通道 tlast 信号的来源。 当没有或只有一个输入通道有 tlast 时,输出 tlast 不存在或适当地从输入 tlast 派生。当两个输入通道都有 tlast 时,输出通道 tlast 可以单独从两个输入的逻辑 OR或逻辑 AND 得出。
Latency Options
Latency Configuration: 延迟配置。自动(完全流水线)或手动。Radix2 解决方案的延迟配置仅在每格时钟设置为 1 时才可配置。这是由于迭代反馈,因此当每格时钟大于 1 时非可选寄存器。
Latency :延迟,当Latency Configuration 设置为Automatic 时,提供从输入到输出的延迟,以时钟使能时钟周期为单位。 手动时,此字段用于指定所需的延迟。 当不需要高性能(时钟频率)时,该字段中较低的值可以节省资源。
Control Signals
ACLKEN :确定内核是否具有时钟使能输入 (ACLKEN)。信号ARESETn始终优先于ACLKEN,即无论ACLKEN的状态如何,ARESETn都生效。
ARESETn :确定内核是否具有低电平有效同步清零输入 (ARESETn)。为低电平有效。信号 ARESETn 应保持有效至少两个时钟周期。 这是因为,为了性能,ARESETn 在被馈送到原语的重置端口之前在内部注册。
-
dsp
+关注
关注
561文章
8275浏览量
368205 -
FPGA
+关注
关注
1664文章
22502浏览量
639087 -
接口
+关注
关注
33文章
9596浏览量
157608 -
Xilinx
+关注
关注
73文章
2206浏览量
131865 -
除法器
+关注
关注
2文章
15浏览量
14150
发布评论请先 登录
基于FPGA的高效除法器设计

基于FPGA的除法器纯逻辑设计案例
AT32硬件除法器应用指南
FPGA除法器IP核运算出错
FPGA中的除法运算及初识AXI总线
乘除法和开方运算的FPGA串行实现
并行除法器 ,并行除法器结构原理是什么?

实例九— 除法器设计

如何实现FPGA中的除法运算
FPGA常用运算模块-复数乘法器





评论