 “伶荔”(Linly) 开源大规模中文语言模型
“伶荔”(Linly) 开源大规模中文语言模型

为了开发高性能中文基础模型,填补中文基础模型百亿到千亿级预训练参数的空白,大数据系统计算技术国家工程实验室团队在人工智能项目伶荔(Linly)框架下,推出了伶荔说系列中文语言大模型,目前包含中文基础模型和对话模型。
其中,中文基础模型以 LLaMA 为底座,利用中文和中英平行增量预训练,将它在英文上强大语言能力迁移到中文上。更进一步,汇总了目前公开的多语言指令数据,对中文模型进行了大规模指令跟随训练,实现了 Linly-ChatFlow 对话模型。

根据介绍,相比已有的中文开源模型,伶荔模型具有以下优势:
在 32*A100 GPU 上训练了不同量级和功能的中文模型,对模型充分训练并提供强大的 baseline。据知,33B 的 Linly-Chinese-LLAMA 是目前最大的中文 LLaMA 模型。
公开所有训练数据、代码、参数细节以及实验结果,确保项目的可复现性,用户可以选择合适的资源直接用于自己的流程中。
项目具有高兼容性和易用性,提供可用于 CUDA 和 CPU 的量化推理框架,并支持 Huggingface 格式。
目前公开可用的模型有:
Linly-Chinese-LLaMA:中文基础模型,基于 LLaMA 在高质量中文语料上增量训练强化中文语言能力,现已开放 7B、13B 和 33B 量级,65B 正在训练中。
Linly-ChatFlow:中文对话模型,在 400 万指令数据集合上对中文基础模型指令精调,现已开放 7B、13B 对话模型。
Linly-ChatFlow-int4 :ChatFlow 4-bit 量化版本,用于在 CPU 上部署模型推理。
进行中的项目:
Linly-Chinese-BLOOM:基于 BLOOM 中文增量训练的中文基础模型,包含 7B 和 175B 模型量级,可用于商业场景。
项目特点
Linly 项目具有以下特点:
1. 大规模中文增量训练,利用翻译数据提速中文模型收敛
在训练数据方面,项目尽可能全面的收集了各类中文语料和指令数据。无监督训练使用了上亿条高质量的公开中文数据,包括新闻、百科、文学、科学文献等类型。和通常的无监督预训练不同,项目在训练初期加入了大量中英文平行语料,帮助模型将英文能力快速迁移到中文上。
在指令精调阶段,项目汇总了开源社区的指令数据资源,包括多轮对话、多语言指令、GPT4/ChatGPT 问答、思维链数据等等,经过筛选后使用 500 万条数据进行指令精调得到 Linly-ChatFlow 模型。训练使用的数据集也在项目里提供。
训练流程如图所示:
2. 全参数训练,覆盖多个模型量级
目前基于 LLaMA 的中文模型通常使用 LoRA 方法进行训练,LoRA 冻结预训练的模型参数,通过往模型中加入额外的网络层,并只训练这些新增的网络层参数,来实现快速适配。虽然 LoRA 能够提升训练速度且降低设备要求,但性能上限低于全参数训练。为了使模型获得尽可能强的中文语言能力,该项目对所有参数量级都采用全参数训练,开销大约是 LoRA 的 3-5 倍。
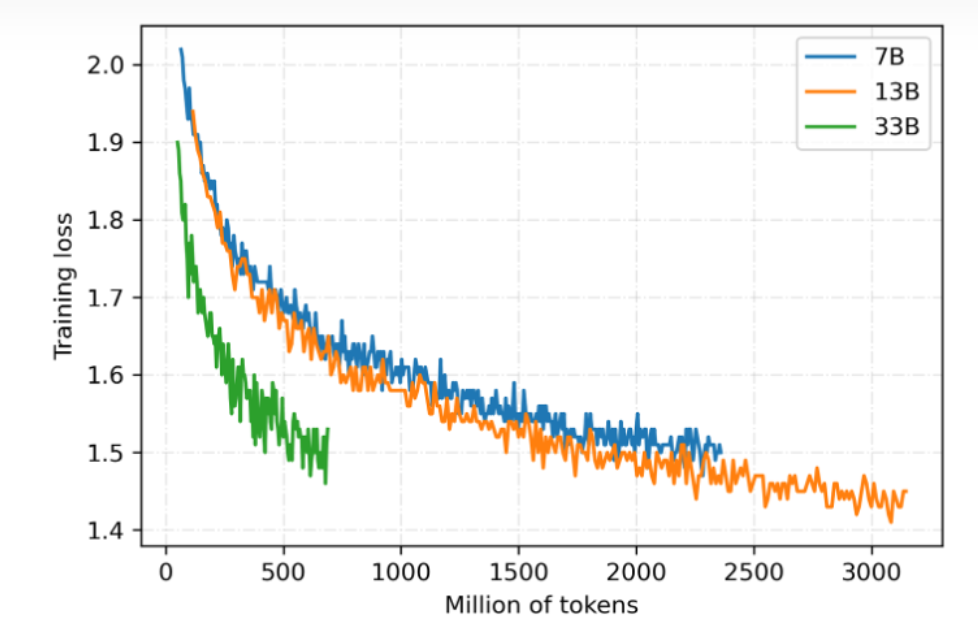
伶荔语言模型利用 TencentPretrain 多模态预训练框架,集成 DeepSpeed ZeRO3 以 FP16 流水线并行训练。目前已开放 7B、13B、33B 模型权重,65B 模型正在训练中。模型仍在持续迭代,将定期更新,损失收敛情况如图所示:
3. 可支持本地 CPU int4 推理、消费级 GPU 推理
大模型通常具有数百亿参数量,提高了使用门槛。为了让更多用户使用 Linly-ChatFlow 模型,开发团队在项目中集成了高可用模型量化推理方案,支持 int4 量化 CPU 推理可以在手机或者笔记本电脑上使用,int8 量化使用 CUDA 加速可以在消费级 GPU 推理 13B 模型。此外,项目中还集成了微服务部署,用户能够一键将模型部署成服务,方便二次开发。
未来工作
据透露,伶荔说系列模型目前仍处于欠拟合,正在持续训练中,未来 33B 和 65B 的版本或将带来更惊艳的性能。在另一方面,项目团队不仅公开了对话模型,还公开了中文基础模型和相应的训练代码与数据集,向社区提供了一套可复现的对话模型方案,目前也有团队基于其工作实现了金融、医学等领域的垂直领域对话模型。
在之后的工作,项目团队将继续对伶荔说系列模型进行改进,包括尝试人类反馈的强化学习(RLHF)、适用于中文的字词结合 tokenizer、更高效的 GPU int3/int4 量化推理方法等等。伶荔项目还将针对虚拟人、医疗以及智能体场景陆续推出伶荔系列大模型。
审核编辑 :李倩
-
cpu
+关注
关注
68文章
11326浏览量
225873 -
人工智能
+关注
关注
1820文章
50314浏览量
266885 -
开源
+关注
关注
3文章
4343浏览量
46440 -
语言模型
+关注
关注
0文章
574浏览量
11341
原文标题:“伶荔”(Linly) 开源大规模中文语言模型
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
NVIDIA推动面向数字与物理AI的开源模型发展
openDACS 2025 开源EDA与芯片赛项 赛题七:基于大模型的生成式原理图设计
NVIDIA ACE现已支持开源Qwen3-8B小语言模型
NVIDIA 利用全新开源模型与仿真库加速机器人研发进程

TensorRT-LLM的大规模专家并行架构设计

大规模专家并行模型在TensorRT-LLM的设计

基于大规模人类操作数据预训练的VLA模型H-RDT

【VisionFive 2单板计算机试用体验】3、开源大语言模型部署
华为宣布开源盘古7B稠密和72B混合专家模型
华为正式开源盘古7B稠密和72B混合专家模型
探索在Arm平台运行的Llama 4 Scout模型
薄型、多频段、大规模物联网前端模块 skyworksinc

带耦合器的大规模物联网半双工前端模块 skyworksinc
如何借助大语言模型打造人工智能生态系统




评论