 纳多德端到端IB解决方案
纳多德端到端IB解决方案

在 ChatGPT 引爆科技领域之后,人们一直在讨论 AI「下一步」的发展会是什么,很多学者都提到了多模态,我们并没有等太久。近期,OpenAI 发布了多模态预训练大模型 GPT-4,GPT-4 实现了以下几个方面的飞跃式提升:强大的识图能力、文字输入限制提升至 2.5 万字、回答准确性显著提高、能够生成歌词、创意文本,实现风格变化。
如此高效的迭代,离不开人工智能大规模模型训练,需要大量的计算资源和高速的数据传输网络。其中,端到端IB(InfiniBand)网络是一种高性能计算网络,特别适合用于高性能计算和人工智能模型训练。本文将介绍什么是AIGC模型训练,为什么需要端到端IB网络以及如何使用ChatGPT模型进行AIGC训练。
AIGC是什么?
AIGC 即 AI Generated Content,是指人工智能自动生成内容,可用于绘画、写作、视频等多种类型的内容创作。2022年AIGC高速发展,这其中深度学习模型不断完善、开源模式的推动、大模型探索商业化的可能,成为AIGC发展的“加速度”。以最近爆火的聊天机器人ChatGPT为例,这款机器人既会写论文,也能创作小说,还可编代码,上线仅2个月,月活用户达1亿。因为出乎意料的“聪明”,AIGC被认为是“科技行业的下一个颠覆者”“内容生产力的一次重大革命”。
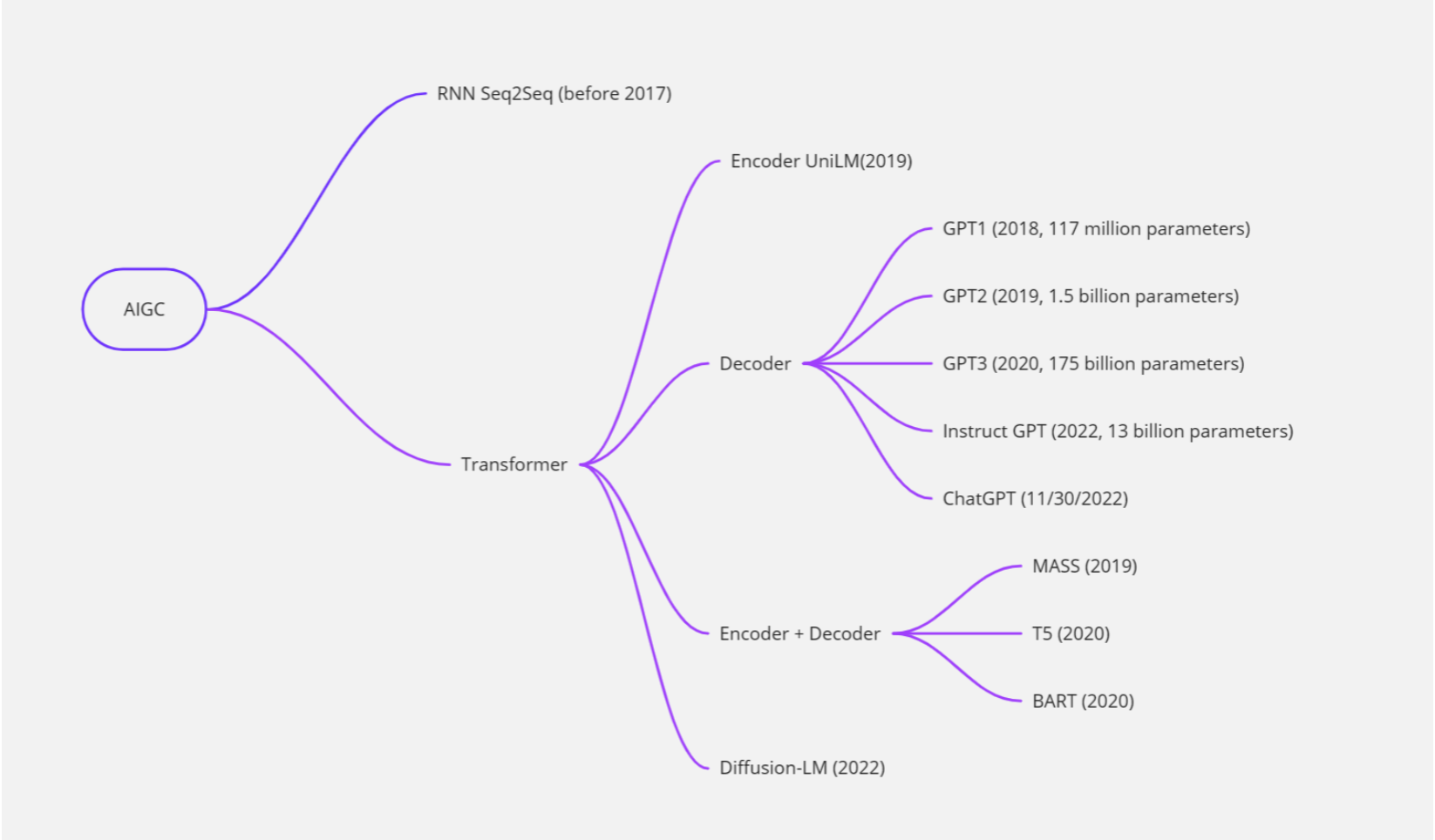
大型语言模型(LLM)和ChatGPT
大型语言模型(Large Language Model)是一种能够自动学习并理解自然语言的人工智能技术。它通常基于深度学习算法,通过对大量文本数据的学习来获取语言知识,并能够自动生成自然语言文本,如对话、文章等。
ChatGPT是一种基于大型语言模型的聊天机器人,它采用了OpenAI开发的GPT(Generative Pre-trained Transformer)模型,通过对大量文本数据的预训练和微调,能够生成富有语言表达力的自然语言文本,并实现与用户的交互。
因此,可以说ChatGPT是一种基于大型语言模型技术的聊天机器人,它利用了大型语言模型的强大语言理解和生成能力,从而能够在对话中进行自然语言文本的生成和理解。
随着深度学习技术的发展,大型语言模型的能力和规模不断提升。最初的语言模型(如N-gram模型)只能考虑有限的上下文信息,而现代的大型语言模型(如BERT、GPT-3等)能够考虑更长的上下文信息,并且具有更强的泛化能力和生成能力。
大型语言模型通常采用深度神经网络进行训练,如循环神经网络(RNN)、长短时记忆网络(LSTM)、门控循环单元(GRU)和变压器网络(Transformer)等。在训练中,模型利用大规模的文本数据集,采用无监督或半监督的方式进行训练。例如,BERT模型通过预测掩码、下一个句子等任务来训练,而GPT-3则采用了大规模的自监督学习方式。
大型语言模型在自然语言处理领域有广泛的应用,例如机器翻译、自然语言生成、问答系统、文本分类、情感分析等。
当前训练LLM的瓶颈在哪里?
在训练大型语言模型时,需要高速、可靠的网络来传输大量的数据。例如OpenAI发布了第一版GPT模型(GPT-1),其模型规模为1.17亿个参数。之后,OpenAI相继发布了GPT-2和GPT-3等更大的模型,分别拥有1.5亿和1.75万亿个参数。如此大的参数在单机训练是完全不可能的,需要高度依赖GPU计算集群,目前的瓶颈在于如何解决训练集群中各节点之间高效通信的问题。
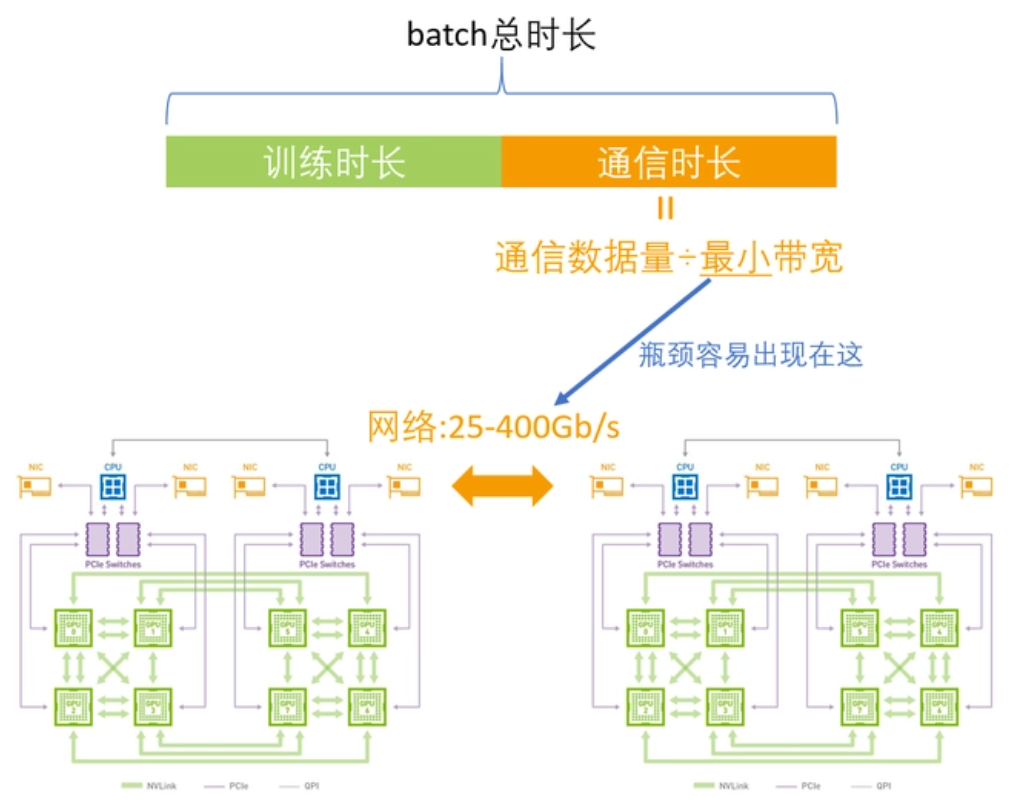
目前比较常用的GPU通信算法就是Ring-Allreduce。其基本思想就是让GPU形成一个环,让数据在环内流动。环中的GPU都被安排在一个逻辑中,每个GPU有一个左邻和一个右邻,它只会向它的右邻居发送数据,并从它的左邻居接收数据。
该算法分两个步骤进行:首先是scatter-reduce,然后是allgather。在scatter-reduce步骤中,GPU将交换数据,使每个GPU可得到最终结果的一个块。在allgather步骤中,GPU将交换这些块,以便所有GPU得到完整的最终结果。
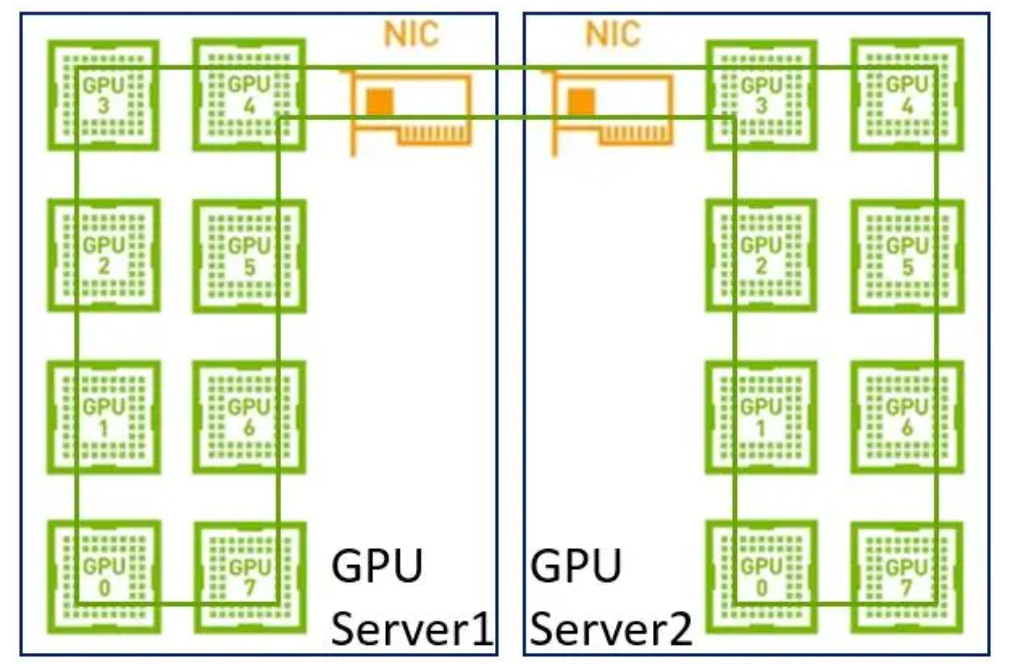
在早期,单机内部没有NVLink,网络上没有RDMA,带宽相对较低,单机分布式和多机分布式在带宽上没太大差别,所以建一个大环即可。
但是现在我们单机内部有了NVLink,在使用同样的方法就不合适了。因为网络的带宽是远低于NVLink,如果再用一个大环,那会导致NVLink的高带宽被严重拉低到网络的水平。其次,现在是具备多网卡的环境,如果只用一个环也无法充分利用多网卡优势。
因此,在这样的场景下建议采用两级环:首先利用NVLink高带宽优势在单机内部的GPU之间完成数据同步;然后多机之间的GPU利用多网卡建立多个环,对不同分段数据进行同步;最后单机内部的GPU再同步一次,最终完成全部GPU的数据同步,在这里就不得不提到NCCL。
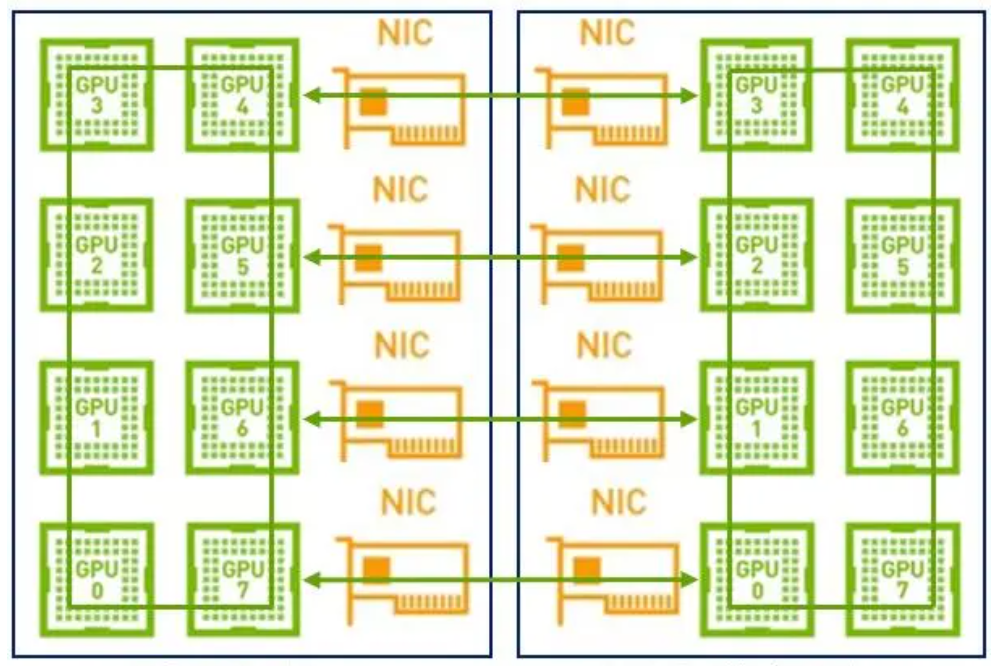
NVIDIA集体通信库(NCCL)实现了针对NVIDIA GPU和网络优化的多GPU和多节点通信原语。
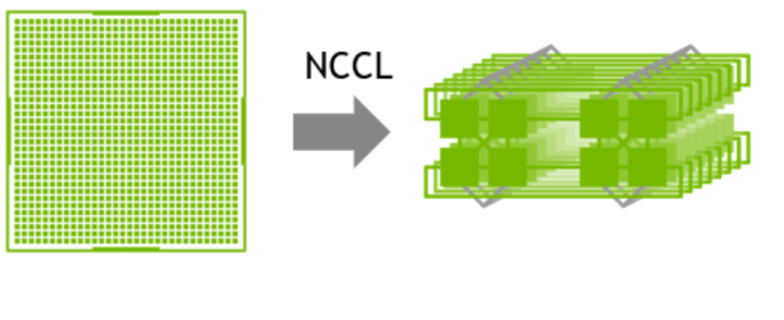
1GPU->multi-GPU multi node
NCCL提供全收集、全减、广播、减少、减少散射以及点对点发送和接收等例程,这些例程经过优化,通过节点内和NVIDIA Mellanox网络通过PCIe和NVLink高速互连实现高带宽和低延迟。
为什么要使用端到端IB网络?
以太网是一种广泛使用的网络协议,但其传输速率和延迟无法满足大型模型训练的需求。相比之下,端到端IB(InfiniBand)网络是一种高性能计算网络,能够提供高达 400 Gbps 的传输速率和微秒级别的延迟,远高于以太网的性能。这使得IB网络成为大型模型训练的首选网络技术。
此外,端到端IB网络还支持数据冗余和纠错机制,能够保证数据传输的可靠性。这在大型模型训练中尤为重要,因为在处理如此多的数据时,数据传输错误或数据丢失可能会导致训练过程中断甚至失败。
随着网络节点数目的急剧增加和计算能力不断上升,高性能计算消除性能瓶颈和改进系统管理变得比以往更加重要。InfiniBand被认为是可以提升当前I/O架构性能瓶颈的一种极具潜力的I/O技术,如图所示。InfiniBand是一种普及的、低延迟的、高带宽的互连通信协议,处理开销很低,非常适合在单个连接上承载多种流量类型(集群、通信、存储和管理)。1999年,IBTA (InfiniBand Trade Association)制定了InfiniBand相关标准,在InfiniBand™中规范定义了用于互连服务器、通信基础设施设备、存储和嵌入式系统的输入/输出体系结构。InfiniBand是一项成熟的、经过现场验证的技术,被广泛应用于高性能计算集群中。
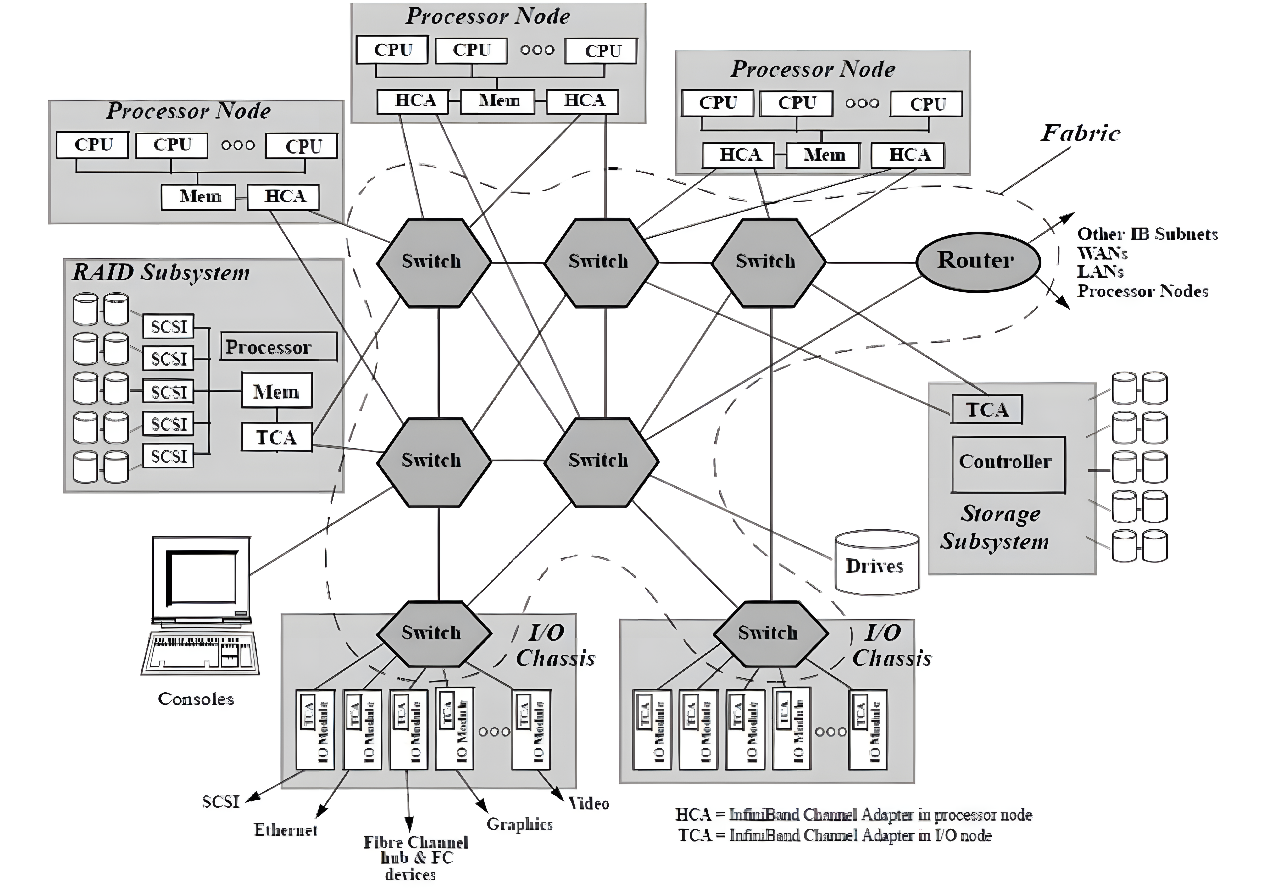
InfiniBand互连架构图
InfiniBand互联协议中规定,每个端节点必须有一个主机通道适配器(HCA)来设置和维护与主机设备的链接,交换机包含多个端口,并将数据包从一个端口转发到另一个端口,完成在子网内传输数据的功能。子网管理器(Subnet Manager, SM)用于配置其本地子网并确保其持续运行,借助子网管理器数据包(Subnet Manager Packet, SMP)和每个InfiniBand设备上的子网管理代理(Subnet Manager Agent, SMA),子网管理器发现并初始化网络,为所有设备分配唯一标识符,确定MTU(Maximum Transmission Unit,最小传输单元),并根据选定的路由算法生成交换机路由表。SM还定期对子网进行光扫描,以检测任何拓扑变化,并相应地配置网络。与其他网络通信协议相比,InfiniBand网络提供了更高的带宽、更低的延迟和更强的可扩展性。此外,由于InfiniBand提供了基于credit的流控制(其中发送方节点发送的数据不会超过链路另一端的接收缓冲区公布的credit数量),传输层不需要像TCP窗口算法那样的丢包机制来确定最佳的正在传输的数据包数量,这使得InfiniBand网络能够以极低的延迟和极低的CPU使用率为应用程序提供极高的数据传输速率。InfiniBand使用RDMA技术(Remote Direct Memory Access,远程直接内存访问)将数据从通道一端传输到另一端,RDMA是一种通过网络在应用程序之间直接传输数据的协议,无需操作系统的参与,同时消耗双方极低的CPU资源(零拷贝传输),一端的应用程序只需直接从内存中读取消息,消息就已成功传输,减少的CPU开销增加了网络快速传输数据的能力,并允许应用程序更快地接收数据。
纳多德端到端IB网络解决方案
纳多德基于对高速率网络发展趋势的理解,和丰富的HPC、AI项目实施经验,提供基于NVIDIA Quantum-2交换机、 ConnectX InfiniBand 智能网卡和灵活的400Gb/s InfiniBand端到端解决方案,在降低成本和复杂性的同时在高性能计算 (HPC)、AI 和超大规模云基础设施中带来超强性能。
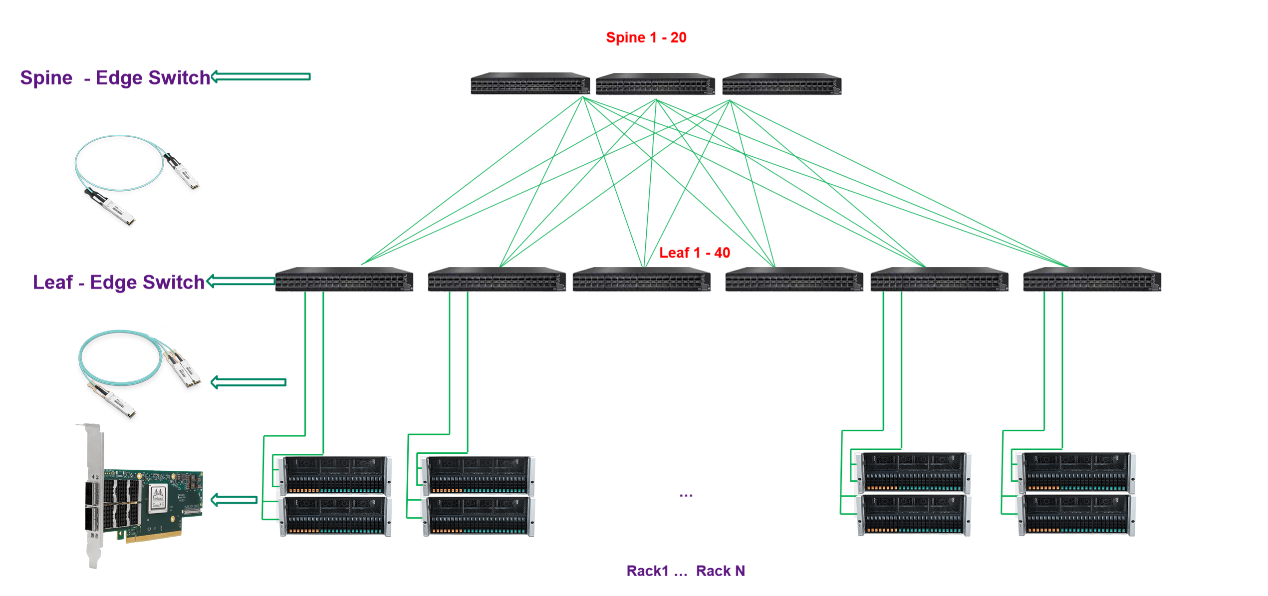
纳多德数据中心IB网络解决方案
交换机
更快的服务器、高性能存储和日益复杂的计算应用正在将数据带宽要求推向新的高度。NVIDIA Mellanox QM9700 交换机提供具有极低的延迟,NVIDIA Quantum-2 采用第七代 NVIDIA InfiniBand 架构,可为 AI 开发者和科学研究人员提供超强网络性能和丰富功能,帮助他们解决充满挑战性的问题。NVIDIA Quantum-2 通过软件定义网络、网络计算、性能隔离、高级加速引擎、远程直接内存访问 (RDMA) 以及高达 400 Gb/s 的超快的速度,为先进的超级计算数据中心提供助力。
智能网卡
纳多德在网卡侧提供NVIDIA ConnectX SmartNIC智能网卡,NVIDIA ConnectX InfiniBand 智能网卡支持更快的速度和创新的网络计算技术,实现了超强性能和可扩展性。NVIDIA ConnectX 降低了每次操作的成本,从而可为高性能计算 (HPC)、机器学习、高性能存储及数据库业务和低延迟嵌入式等应用提高投资回报率。来自 NVIDIA Quantum-2 InfiniBand 架构的 ConnectX-7 智能网卡(HCA)可提供超高的网络性能,用于处理极具挑战性的工作负载。ConnectX-7 支持超低时延、400Gb/s 吞吐量和创新的 NVIDIA 网络计算加速引擎,实现额外加速,为超级计算机、人工智能和超大规模云数据中心提供所需的高可扩展性和功能丰富的技术。
光模块
纳多德提供灵活的NVIDIA 400Gb/s InfiniBand光连接方案,包括使用单模和多模收发器、MPO光纤跳线、有源铜缆(ACC)和无源铜缆(DAC),用以满足搭建各种网络拓扑的需要。
>配有带鳍设计的 OSFP 连接器的双端口收发器适用于风冷固定配置交换机,而配有扁平式OSFP 连接器的双端口收发器则适用于液冷模块化交换机和 HCA 中。
>在交换机互连上,可选择采用全新OSFP封装 2XNDR(800Gbps) 光模块进行两台 QM9700交换机的互连,带鳍的设计,可以大大提高光模块散热性。
>交换机和HCA的互联上,交换机端采用OSFP封装2xNDR(800Gbps)带鳍光模块,网卡端采用带有扁平OSFP 400Gbps光模块,MPO光纤跳线可提供3-150米,一对二分光器光纤可提供3-50米。
>交换机到HCA的连接也提供DAC(最长1.5米)或者ACC(最长3米)的解决方案,一对二式分接线缆可用于交换机的一个OSFP端口(配备两个400Gb/s InfiniBand端口)和两个独立的400Gb/s HCA。一分四式分接线缆可用于连接交换机的一个OSFP交换机端口和四个200Gb/s HCA。
纳多德是光网络解决方案的领先提供商,是NVIDIA网络产品的Elite Partner,携手NVIDIA实现光连接+网络产品与解决方案的强强联合,尤其是在InfiniBand高性能网络建设与应用加速方面拥有深刻的业务理解和丰富的项目实施经验,可根据用户不同的应用场景,提供最优的InfiniBand高性能交换机+智能网卡+AOC/DAC/光模块产品组合方案,为数据中心、高性能计算、边缘计算、人工智能等应用场景提供更具优势与价值的光网络产品和整体解决方案,以低成本和出色的性能,大幅提高客户业务加速能力。
审核编辑:汤梓红
-
NVIDIA
+关注
关注
14文章
5687浏览量
110112 -
光模块
+关注
关注
84文章
1688浏览量
64559 -
ChatGPT
+关注
关注
31文章
1600浏览量
10392 -
AIGC
+关注
关注
1文章
393浏览量
3270
发布评论请先 登录
恩智浦完整的Matter端到端解决方案
华为端到端解决方案
集成数据网络端到端和段到段监测解决方案
Airvana宣布全球首个端到端LTE毫微微蜂窝解决方案
USB Type-C端到端解决方案的应用
首个基于APP应用端的5G SA端到端切片解决方案成功实现
中兴通讯端到端传输解决方案实现承载业务“光速直达”

松下帮助高校提供端到端解决方案
Mobileye端到端自动驾驶解决方案的深度解析





评论