 GTC 2023:多模态短视频模型推理优化方案解析
GTC 2023:多模态短视频模型推理优化方案解析


声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
gpu
+关注
关注
28文章
5271浏览量
136070 -
英伟达
+关注
关注
23文章
4115浏览量
99628 -
gtc
+关注
关注
0文章
75浏览量
4775 -
短视频
+关注
关注
1文章
129浏览量
9583
发布评论请先 登录
相关推荐
热点推荐
基于米尔瑞芯微RK3576开发板的Qwen2-VL-3B模型NPU多模态部署评测
,RKLLM 通过量化优化、多模态支持等降低模型内存占用与推理延迟。实测中,RK3576 运行 Qwen2-VL-3B
发表于 08-29 18:08
米尔RK3576部署端侧多模态多轮对话,6TOPS算力驱动30亿参数LLM
话的 KV-Cache 维护与手动清除;
Prompt 模板的动态渲染;
用户输入的解析处理与推理结果的回显展示。
1.3 核心逻辑:多轮对话的处理流程该方案的
发表于 09-05 17:25
CDN高级技术专家周哲:深度剖析短视频分发过程中的用户体验优化技术点
和分发的角度介绍整体方案,并且重点讲解短视频加速的注意事项和用户体验优化要点。深圳云栖大会已经圆满落幕,在3月29日飞天技术汇-弹性计算、网络和CDN专场中,阿里云CDN高级技术专家周哲为我们带来
发表于 04-03 14:32
GTC 2023:短视频多模态超大模型的场景应用
快手科技围绕提高模型计算效率和可部署开展技术攻关,沉淀了一套通用的混合并行训练、压缩、推理整体解决方案。

VisCPM:迈向多语言多模态大模型时代
可以大致分为两类: 1. 在图生文(image-to-text generation)方面,以 GPT-4 为代表的多模态大模型,可以面向图像进行开放域对话和深度推理; 2. 在文生图

更强更通用:智源「悟道3.0」Emu多模态大模型开源,在多模态序列中「补全一切」
热度。Flamingo 具备强大的多模态上下文少样本学习能力。 Flamingo 走的技术路线是将大语言模型与一个预训练视觉编码器结合,并插入可学习的层来捕捉跨模态依赖,其采用图文对、

北大&华为提出:多模态基础大模型的高效微调
深度学习的大模型时代已经来临,越来越多的大规模预训练模型在文本、视觉和多模态领域展示出杰出的生成和推理能力。然而大

大模型+多模态的3种实现方法
我们知道,预训练LLM已经取得了诸多惊人的成就, 然而其明显的劣势是不支持其他模态(包括图像、语音、视频模态)的输入和输出,那么如何在预训练LLM的基础上引入跨模态的信息,让其变得更强

自动驾驶和多模态大语言模型的发展历程
多模态大语言模型(MLLM) 最近引起了广泛的关注,其将 LLM 的推理能力与图像、视频和音频数据相结合,通过多
发表于 12-28 11:45
•1446次阅读

李未可科技正式推出WAKE-AI多模态AI大模型
李未可科技多模态 AI 大模型正式发布,积极推进 AI 在终端的场景应用 4月18日,2024中国生成式AI大会上李未可科技正式发布为眼镜等未来终端定向优化等自研WAKE-AI
发表于 04-18 17:01
•1191次阅读

利用OpenVINO部署Qwen2多模态模型
多模态大模型的核心思想是将不同媒体数据(如文本、图像、音频和视频等)进行融合,通过学习不同模态之间的关联,实现更加智能化的信息处理。简单来说
亚马逊云科技上线Amazon Nova多模态嵌入模型
Embeddings多模态嵌入模型现已在Amazon Bedrock上线,这是一款专为Agentic RAG与语义搜索应用打造的顶尖多模态

商汤开源SenseNova-MARS:突破多模态搜索推理天花板
今日,商汤正式开源多模态自主推理模型 SenseNova-MARS(8B/32B 双版本),其在多模态搜索与
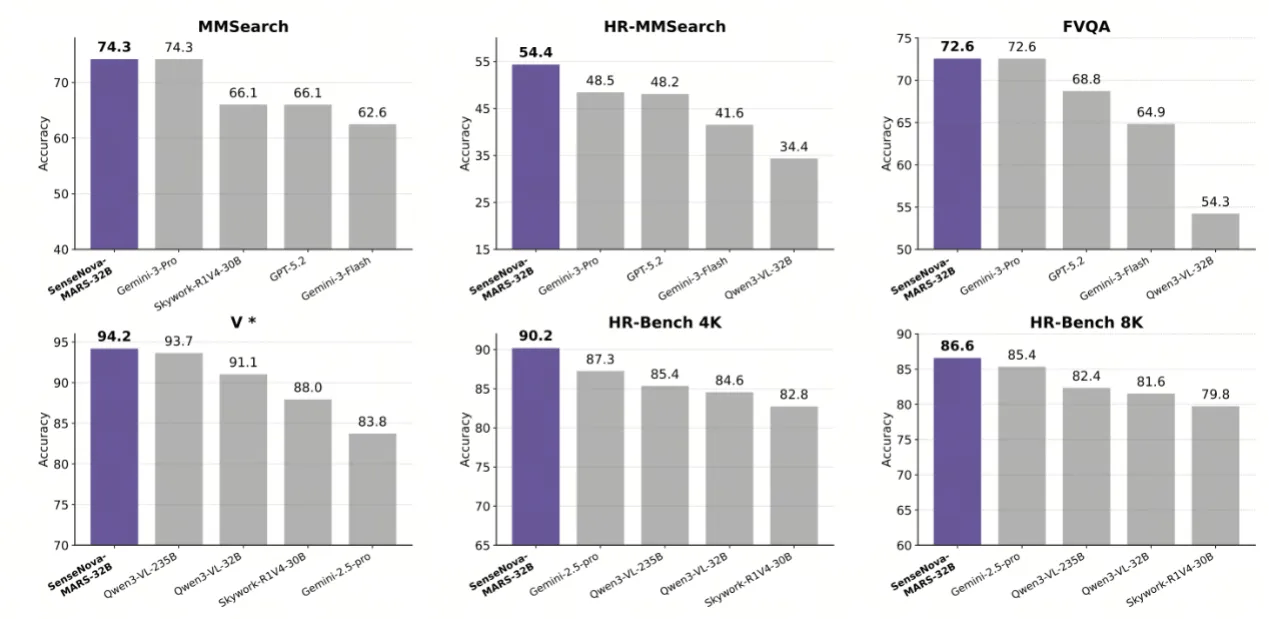
商汤科技正式开源多模态自主推理模型SenseNova-MARS
今日,商汤正式开源多模态自主推理模型 SenseNova-MARS(8B/32B 双版本),其在多模态搜索与




评论