 更强更通用:智源「悟道3.0」Emu多模态大模型开源,在多模态序列中「补全一切」
更强更通用:智源「悟道3.0」Emu多模态大模型开源,在多模态序列中「补全一切」

当前学界和工业界都对多模态大模型研究热情高涨。去年,谷歌的 Deepmind 发布了多模态视觉语言模型 Flamingo ,它使用单一视觉语言模型处理多项任务,在多模态大模型领域保持较高热度。Flamingo 具备强大的多模态上下文少样本学习能力。
Flamingo 走的技术路线是将大语言模型与一个预训练视觉编码器结合,并插入可学习的层来捕捉跨模态依赖,其采用图文对、图文交错文档、视频文本对组成的多模态数据训练,在少样本上下文学习方面表现出强大能力。但是,Flamingo 在训练时只使用预测下一个文本单词作为目标,并没有对视觉部分施加专门的监督信号,直接导致了在推理阶段,其只能支持以文本作为输出的多模态任务,大大限制了模型的能力以及应用场景。
Flamingo 目前并没有开源,今年 3 月,非盈利机构 LAION 开源了 Flamingo 模型的复现版本 OpenFlamingo。
近日,智源研究院「悟道・视界」研究团队提出了一种新的多模态大模型训练范式,发布并开源了首个打通从多模态输入到多模态输出的「全能高手」,统一多模态预训练模型 Emu 。
Emu 模型创造性地建立了统一的多模态预训练框架,即将图文对、图文交错文档、视频、视频文本对等海量形式各异的多模态数据统一成图文交错序列的格式,并在统一的学习目标下进行训练,即预测序列中的下一个元素 (所有元素,包含文本 token 和图像 embedding)。此外,Emu 首次提出使用大量采用视频作为图文交错数据源,视频数据相比于 Common Crawl 上的图文交错文档,视觉信号更加稠密,且图像与文本之间的关联也更加紧密,更加适合作为图文交错数据去激发模型的多模态上下文学习能力。
论文结果显示,Emu 超越了此前 DeepMind 的多模态大模型 Flamingo,刷新 8 项性能指标。
除以文本作为输出的任务指标之外,Emu 模型具有更加通用的功能,能够同时完成以图片作为输出的任务,如文生图;且具备很多新型能力,如多模态上下文图像生成。Emu 的能力覆盖图像与文本的生成及视频理解。
-
论文链接:https://arxiv.org/pdf/2307.05222.pdf
-
模型链接:https://github.com/baaivision/Emu
-
Demo 链接:https://emu.ssi.plus/
作为一种通用界面,Emu 可用于多种视觉、语言应用
超越 Flamingo、Kosmos,8 项基准测试表现优异
在 8 个涵盖多模态图像 / 视频和语言任务的基准测试中,Emu 均有不俗表现,对比来自 DeepMind 的 Flamingo 与来自微软的 Kosmos 亦有所超越。
Emu 在众多常用测试基准上表现出极强的零样本性能,展现了模型在遇到未知任务时强大的泛化能力。其中,Emu 在图像描述 COCO Caption 的 CIDEr 得分为 112.4,且模型对图片的描述中包含丰富的世界知识。此外,Emu 在图像问答 VQAv2 和视频问答 MSRVTT 数据集上也展现了强劲的视觉问答功能。
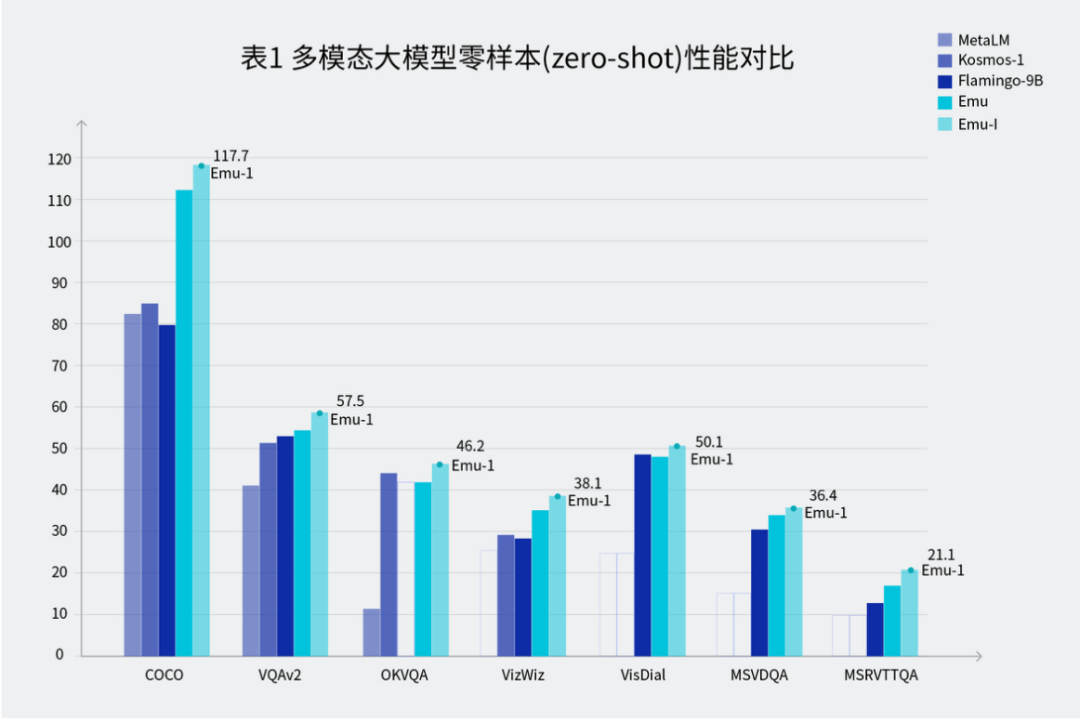
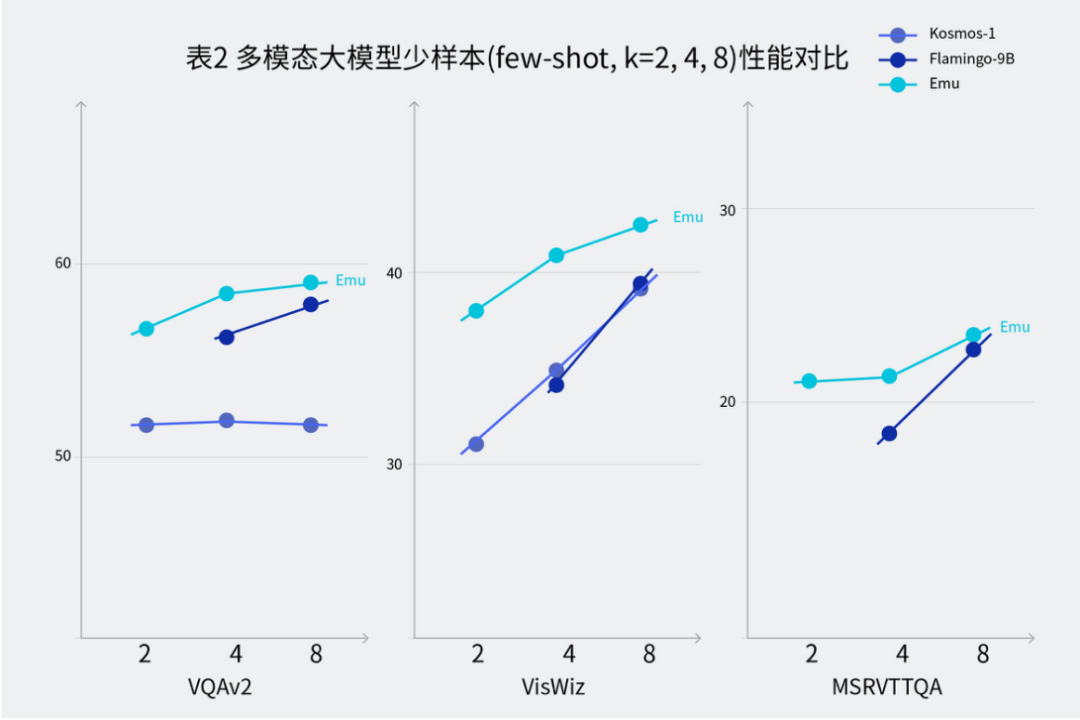
同时,Emu 具备强大的少样本上下文学习能力,即对于给定任务提供几个示例样本,模型可以进行上下文学习从而更好地完成任务。Emu 在视觉问答数据集 VQAv2、VizWiz、MSRVTTQA 上的少样本上下文学习表现突出。
全能高手:在多模态序列中进行「图文任意模态生成」
Emu 模型能力覆盖图像与文本的生成及视频理解, 相比其他多模态模型更具通用性,能完成任意图生文以及文生图的多模态任务。例如,精准图像认知、少样本图文推理、视频问答、文图生成、上下文图像生成、图像融合、多模态多轮对话等。
Emu 是一个基于 Transformer 的多模态基础模型,可以接受并处理形式各异的多模态数据,输出指定的多模态数据。Emu 将图文对、图文交错文档、视频、视频文本对等形式各异的海量多模态数据统一成图文交错序列的格式,并在统一的学习目标下进行训练,即预测序列中的下一个元素 (所有元素,包含文本 token 和图像 embedding)。训练完成后,Emu 能对任意形式的多模态上下文序列进行多模态补全,对图像、文本和视频等多种模态的数据进行感知、推理和生成。
视频理解、多模态上下文生成、多模态对话是 Emu 模型的技术亮点。
Emu 模型具有强大的视频理解能力,如在下图演示中,针对下面 “视频中的女主人公在干什么” 这一问题,Emu 模型给出了具有精准事实细节(苹果 VR 设备)、连贯动作描述(坐在飞机上并使用 VR 设备)、合理行动猜测(可能在看一段视频或 360 度视角的飞机外景象)的丰富回答。
Emu 不只能理解视频信息,还能做到对视频中时序信息的精细理解。例如下图展示的奶昔制作视频,Emu 分步且完整地描述了奶昔制作步骤。
Emu 新增了图像融合能力,可以对输入的图像进行创造性地融合,并生成新的图片。例如下图最后一行,将两幅世界名画作为输入,Emu 可以生成风格、元素类似的全新画作:
上下文图像生成也是一项全新的功能,Emu 可以将输入的文本 - 图片对作为 prompt,结合上下文信息进行图片生成。例如在下图第一行,输入两张图片,并输入文本指令让 Emu 生成以图 1 的动物为中心,但以图 2 为风格的图片。依赖于强大的多模态上下文生成能力,Emu 可以完成相应的指令。下图的第二行展示了如果在 “文生图” 时提供了 context,Emu 会结合 context 的风格,生成油画风格的图片,而相同的文本在无 context 的情况下进行 “文生图” 只会生成现实风格的图片:
图像生成方面,Emu 可以根据给定的文本生成多幅语义相关的图像:
Emu 可根据一张或者多张图或视频进行问答和多轮对话。如下第一张图所示,给出一张景点图并询问旅游注意事项,Emu 给出了 5 个要点,其中再就第 5 个要点 “ safety equipment” 提问时,Emu 能够针对这一点进行更加详细地阐述。最后,Emu 还可以根据图片作诗。
Emu 还有一项突出的能力是它的世界知识更丰富。如下图所示,给出两张动物的图,询问这两张图的区别,Emu 可以准确描述动物的名称及分布地:
Emu 模型可以准确识别画作,例如下图输入莫奈的《日出・印象》这幅作品, Emu 不仅准确回答出了作品的名字,描述了画面信息,还给出了很多背景知识,例如这是著名印象派风格的作品。而 mPLUG-Owl 、LLaVA 并不知道画作的名称,只是简单描述了画中场景。InstructBLIP 给出了作品名称和描述,但在背景知识上略逊于 Emu。
再看下图,给出阿加莎・克里斯蒂的肖像,问题是 “说出这位女性写的 8 本书并推荐一本给我”,Emu 正确理解了这个问题,识别出作者并列出其 8 个作品,并从中挑选了伟大的代表作推荐。LLaVA 人物识别准确,只部分理解了题意,给出推荐作品,但并没有给出 8 个代表作。mPLUG-Owl 识别出了人物 ,也是部分理解了问题,只给出了 4 部作品和一句话简介。InstructBLIP 则给出了一个错误答案。
首次大量采用视频数据,创新性建立统一的多模态学习框架
现有多模态领域的研究工作常将大语言模型与预训练视觉编码器连接来构建多模态大模型(LMM)。尽管现有的 LMMs 很有效,但主要以预测下一个文本 token 作为训练目标,而对视觉模态缺乏监督。这样的训练目标也限制了模型在推理应用时只能输出文本回复,而不具有生成图片回复的能力。
此外,数据直接影响到模型的搭建,视频数据愈来愈成为图像信息时代的主要信息形态。带有交错图像字幕的视频数据,相比于图文交错文档,天然包含更密集的视觉信号,且与文本编码有更强的跨模态关联性。而现有工作主要利用图像 - 文本对及图文文档进行训练,对视频数据有所忽略。
如何把海量多模态数据包括视频数据纳入一个更加「统一」的多模态学习框架,从而提升多模态大模型的通用性,智源视觉团队解决了几个重要问题:
-
对不同来源的多模态交错数据进行处理,以自动回归的方式统一建模。
智源视觉团队采用的多模态交错数据具体包括图像 - 文本对 (LAION-2B、LAION-COCO)、交错图像 - 文本数据 (MMC4)、视频 - 文本对 (Webvid-10M) 和交错视频 - 文本数据 (YT-Storyboard-1B),将视觉表征与文本序列共同构成多模态序列,并进行统一的自回归建模。
Emu 以自动回归的方式统一了不同模态的建模
-
特别地,Emu 首次采用了海量视频作为图文交错序列数据。
视频训练数据源自研究团队从 YouTube 上收集的 1800 万个视频(非原始视频,故事板图像)及其相应的字幕,二者结合创造了一个按时间戳顺序排序的视频和文本的自然交错序列。
交错的视频 - 文本数据
-
预测多模态序列的下一个元素。
模型训练方面,Emu 将自回归地预测多模态序列中的下一个元素(既包含文本也包含图像)作为统一的学习目标进行预训练。在这种不同形式的数据、统一形式的目标下完成训练后。Emu 便成为了一个 “通才” 模型,可以轻松应对各种多模态任务,包括图生文以及文生图。
原文标题:更强更通用:智源「悟道3.0」Emu多模态大模型开源,在多模态序列中「补全一切」
文章出处:【微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
-
物联网
+关注
关注
2951文章
48287浏览量
419835
原文标题:更强更通用:智源「悟道3.0」Emu多模态大模型开源,在多模态序列中「补全一切」
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
NVIDIA发布Nemotron 3 Nano Omni开放式多模态模型
《多模态大模型 前沿算法与实战应用 第一季》精品课程简介
海光DCU完成Qwen3.5多模态MoE模型全量适配
商汤科技正式开源多模态自主推理模型SenseNova-MARS

商汤开源SenseNova-MARS:突破多模态搜索推理天花板
格灵深瞳多模态大模型荣登InfoQ 2025中国技术力量年度榜单

商汤科技正式发布并开源全新多模态模型架构NEO

格灵深瞳多模态大模型Glint-ME让图文互搜更精准

亚马逊云科技上线Amazon Nova多模态嵌入模型




评论