 利用Block Design加速设计
利用Block Design加速设计

一 Block Design设计方法
早期的FPGA,资源是比较有限的,设计规模相对也比较小,之前的设计流程中工程师常用的设计以HDL+Xilinx IP为结构,设计中也会顾虑到FPGA资源的节省。
随着FPGA的资源越来越大,设计的快速构建、易修改、随着版本可迭代的要求越来越高。好比在早期单片机时代,C语言是主流的工具;而处理器越来越强,脚本类语言能更快构建最终应用。
Xilinx越来越多的例程,给出的参考设计是基于Block Design设计方法的,block design设计方法具备如下优势:
A. 框图形式,直观易懂
Block Design基于框图的形式,搭积木+连线的方式; B. 节省大量的Coding时间
互联总线连线,可以鼠标单一连线。Block Design的一个IP往往可以独立运行,比代码的方式只是一个wrapper包含的内容更多;
C. 可以随着Vivado升级,快速更新IP,保持设计更新
传统HDL+IP的方式,IP升级后还需要检查对应HDL的适配。Block Design一般来说,IP作为一个模块升级,基本上Block Design直接升级,内部不用再干预; D. 包括大量的通用IP,可以灵活构建设计
尤其是基于AMBA的IP,可以帮助用户快速灵活构建设计;
二 Block Design设计实例
如何理解Block Design设计方法、工具如何使用等问题Xilinx有详细的文档手册来介绍,本文中不做介绍,本文简单以一个实际的案例,介绍使用Block Design加速设计。
本文描述的这个设计,需要4路光纤,运行Aurora协议,各路Aurora线速率不同。最终Aurora协议的数据部分,还需要通过PCIe上传到上位机。反过程是上位机的数据,通过PCIe最终分发到4路Aurora光纤,向外传输。
本文描述的这个设计中的两个要点:
1. 利用DDR做大容量缓存
有很多应用需要用DDR做缓存,例如常见的PCIe+Aurora收发,或者ADC/DAC,图像采集卡等,两边速率不匹配并且累计需要的容量超过FPGA内部FIFO的时候,需要外部的DDR做缓冲。
早期Xilinx DDR IP的用户接口,只提供了类似于FIFO那样的接口,并且只有一个用户接口。
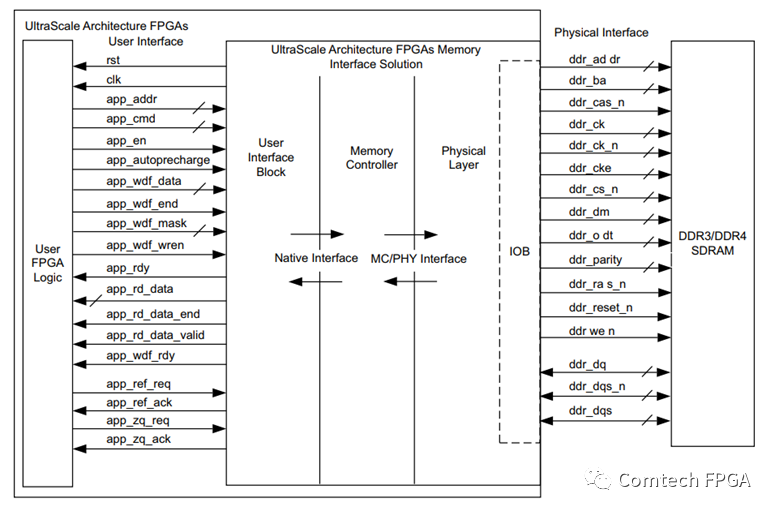
在传统的RTL设计方法中,需要将DDR作为缓存,需要自己做如下设计:
A. 多数据输入输出的接口,将app_接口扩展多个独立的接口,供不同的端口使用
B. 总线仲裁,多个独立接口仲裁,按照round-robin,或者抢占式的方式提供仲裁
C. 地址管理,不同的端口深度要求不同的情况下,对应管理不同的地址空间。
实现这些功能,大概需要写这么多代码,对一个工程师来说,这些代码可能需要2-4周的代码和仿真时间:
如果使用Block Design实现,1个小时差不多就可以实现上面的这些内容,在Block Design中:
A. 最右侧的DDR IP 直接出AXI接口;
B. 使用AXI Smart Connect实现多端口扩展,自带仲裁功能;
C. 使用DATAMOVER完成外围FIFO数据到DDR的数据读写;
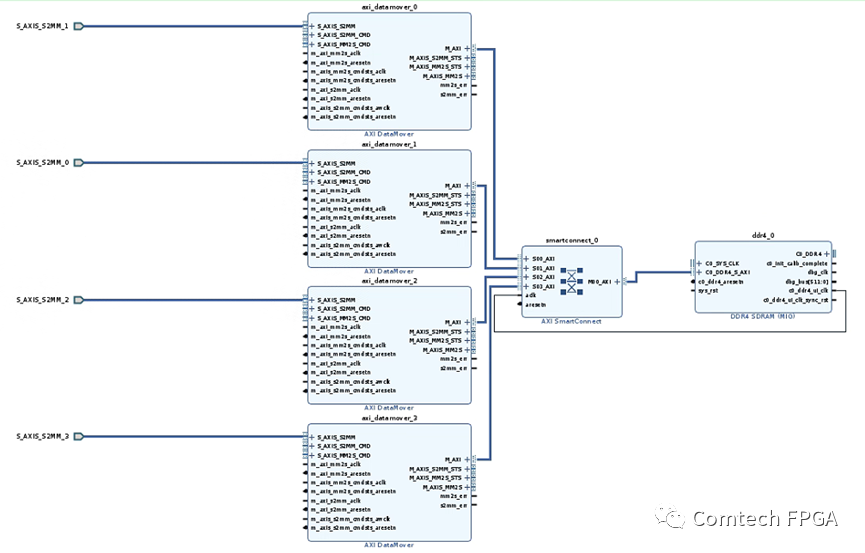
搭建这个Block只需要10分钟,到这一步为止,剩下的工作只需要控制DATAMOVER的命令接口即可。
2. 使用XDMA直接和DDR交互
过去Xilinx 平台设计DMA,从最早的XAPP1052,到后来一些付费的PLDA和NWlogicIP,设计复杂度不用说,哪怕购买了IP也需要一些时间融入到自己的产品中。
Xilinx有一个XDMA IP,这个IP的介绍和使用参考PG195。这里使用Block Design,添加XDMA。
XDMA对外有2个接口:
A. 一个是AXI_LITE接口,这里接AXI_BRAM IP,对外是一个bram接口,用作寄存器接口,控制PCIe卡内部的寄存器;
B. 一个是AXI Memory Full接口,可以直接对接DDR空间,访问所有的DDR部分;
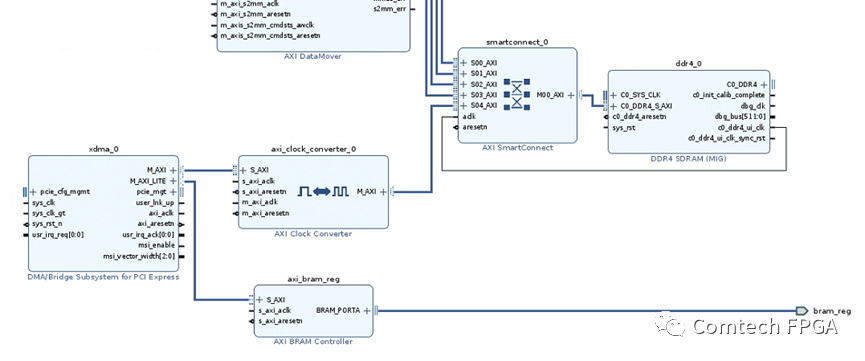
通过地址空间来看,DDR被PCIe XDMA和4路DATAMOVER共享,DATAMOVER外部接收的数据缓存在DDR空间,上位机可以直接读走这片缓存的数据,从而实现外部数据到上位机的过程。
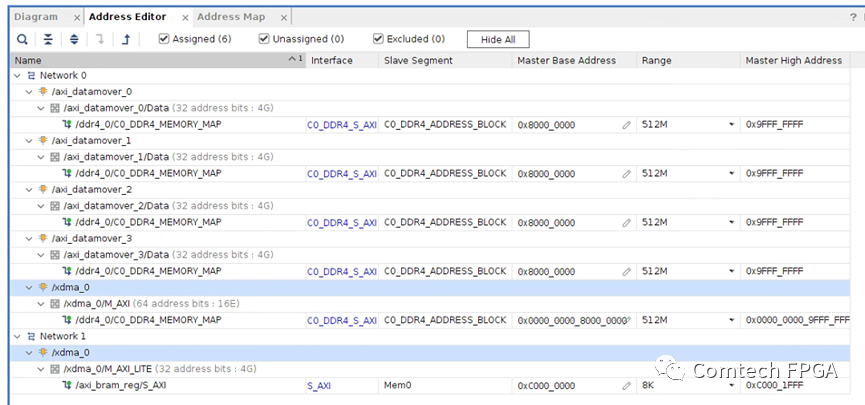
一个实际的PCIe Aurora光纤收发的工程,在Block Design中搭建这些框图,外围的代码非常简单。下面是一个实际的工程,4光口的Aurora收发卡,使用DDR缓存,并且使用PCIe和上位机交互。
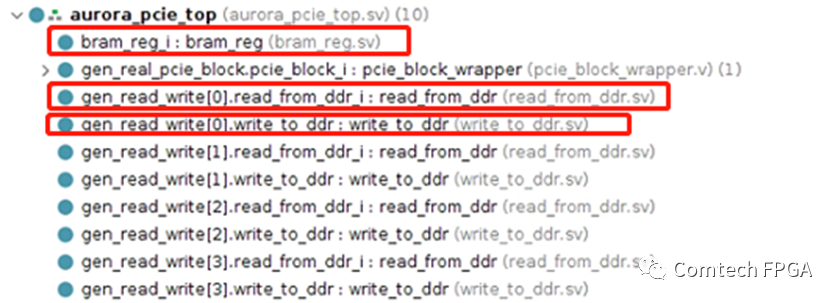
Block Design中包含了PCIe部分,以及上面的DDR缓冲的部分,外部只需要1个DATAMOVER写控制、1个DATAMOVER读控制、1个寄存器接口,即完成整个设计。
三 结语
使用Block Design设计方法,主体部分都可以快速拖拽和连线完成,使得外围所需要的的代码大大简化,只需要区区3个模块代码,完成从数据流到DDR的缓冲以及通过XDMA读取DDR的过程,从而完成外围接口和上位机的通讯。
这个设计可以适配很多种Stream形式的设计:
A. Aurora光纤收发卡;
B. Camera Link图像采集卡;
C. AD/DA数据采集回放卡;
审核编辑 :李倩
-
FPGA
+关注
关注
1664文章
22502浏览量
639106 -
代码
+关注
关注
30文章
4976浏览量
74373 -
Block
+关注
关注
0文章
26浏览量
15174
原文标题:利用Block Design加速设计
文章出处:【微信号:Comtech FPGA,微信公众号:Comtech FPGA】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
RDMA设计52:构建RoCE v2 高速数据传输系统板级测试平台
利用Solido Design Environment准确预测SRAM晶圆良率
利用NVIDIA Cosmos开放世界基础模型加速物理AI开发
NVMe高速传输之摆脱XDMA设计45:上板资源占用率分析
NVMe高速传输之摆脱XDMA设计44:工程设计考量?
利用蜂鸟E203搭建SoC【1】——AXI总线的配置与板级验证
利用蜂鸟E203搭建SoC【2】——外部中断扩展与验证
利用e203中NICE协处理器加速滤波运算
序祯达生物利用NVIDIA Parabricks技术加速多组学分析
如何利用硬件加速提升通信协议的安全性?

Diode.computer:AI 驱动的设计服务商(Design House)

The Ocean Cleanup携手亚马逊云科技 利用AI技术加速清除海洋塑料
全球各大品牌利用NVIDIA AI技术提升运营效率
粒子加速器 —— 科技前沿的核心装置




评论