 NVIDIA Triton 系列文章(7):image_client 用户端参数
NVIDIA Triton 系列文章(7):image_client 用户端参数

作为服务器的最重要任务,就是要接受来自不同终端所提出的各种请求,然后根据要求执行对应的计算,再将计算结果返回给终端。
当 Triton 推理服务器运行起来之后,就进入等待请求的状态,因此我们所要提出的请求内容,就必须在用户端软件里透过参数去调整请求的内容,这部分在 Triton 相关使用文件中并没有提供充分的说明,因此本文的重点就在于用Python 版的 image_client.py 来说明相关参数的内容,其他用户端的参数基本上与这个端类似,可以类比使用。
本文的实验内容,是将 Triton 服务器安装在 IP 为 192.168.0.10 的 Jetson AGX Orin 上,将 Triton 用户端装在 IP 为 192.168.0.20 的树莓派上,读者可以根据已有的设备资源自行调配。
在开始进行实验之前,请先确认以下两个部分的环境:
在服务器设备上启动 Triton 服务器,并处于等待请求的状态:
如果还没启动的话,请直接执行以下指令:
# 根据实际的模型仓根目录位置设定TRITON_MODEL_REPO路径
$ export TRITON_MODEL_REPO=${HOME}/triton/server/docs/examples/model_repository
执行Triton服务器
$ dockerrun--rm--net=host-v${TRITON_MODEL_REPO}:/modelsnvcr.io/nvidia/tritonserver:22.09-py3tritonserver--model-repository=/models在用户端设备下载 Python 的用户端范例,并提供若干张要检测的图片:
先执行以下指令,确认Triton服务器已经正常启动,并且从用户端设备可以访问:
curl -v 192.168.0.10:8000/v2/health/ready只要后面出现的信息中有“HTTP/1.1 200 OK”部分,就表示一切正常。
如果还没安装 Triton 的 Python 用户端环境,并且还未下载用户端范例的话,请执行以下指令:
$ cd ${HOME}/triton
$ git clone https://github.com/triton-inference-server/client
$ cd client/src/python/examples
# 安装 Triton 的 Python用户端环境
$ pip3installtritonclient[all]attrdict-ihttps://pypi.tuna.tsinghua.edu.cn/simple最后记得在用户端设备上提供几张图片,并且放置在指定文件夹(例如~/images)内,准备好整个实验环境,就可以开始下面的说明。
现在执行以下指令,看一下 image_client 这个终端的参数列表:
python3 image_client.py会出现以下的信息:

接下来就来说明这些参数的用途与用法。
用“-u”参数对远程服务器提出请求:
如果用户端与服务器端并不在同一台机器上的时候,就可以用这个参数对远程 Triton 服务器提出推理请求,请执行以下指令:
python3 image_client.py -m inception_graphdef -u 192.168.0.10:8000 -s INCEPTION ${HOME}/images/mug.jpg由于 Triton 的跨节点请求主要透过 HTTP/REST 协议处理,需要透过 8000 端口进行传输,因此在“-u”后面需要接上“IP:8000”就能正常使用。
请自行检查回馈的计算结果是否正确!
2. 用“-m”参数去指推理模型:
从“python3 image_client.py”所产生信息的最后部分,可以看出用“-m”参数去指定推理模型是必须的选项,但是可以指定哪些推理模型呢?就得从 Triton 服务器的启动信息中去寻找答案。
下图是本范例是目前启动的 Triton 推理服务器所支持的模型列表:
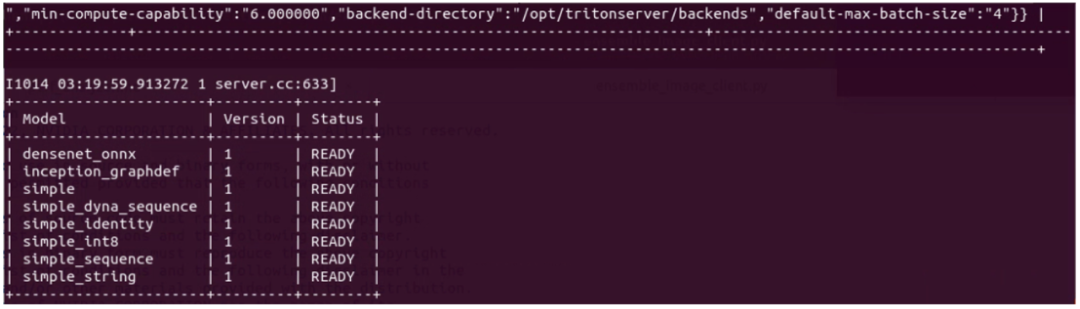
这里显示有的 8 个推理模型,就是启动服务器时使用“--model-repository=”参数指定的模型仓内容,因此客户端使用“-m”参数指定的模型,必须是在这个表所列的内容之列,例如“-mdensenet_onnx”、“-m inception_graphdef”等等。
现在执行以下两道指令,分别看看使用不同模型所得到的结果有什么差异:
$ python3 image_client.py -m densenet_onnx -u 192.168.0.10:8000 -s INCEPTION ${HOME}/images/mug.jpg
$ python3image_client.py-minception_graphdef-u192.168.0.10:8000-sINCEPTION${HOME}/images/mug.jpg使用 densenet_onnx 模型与 inception_graphdef 模型所返回的结果,分别如下:

虽然两个模型所得到的检测结果一致,但是二者所得到的置信度表达方式并不相同,而且标签编号并不一样(504 与 505)。
这个参数后面还可以使用“-x”去指定“版本号”,不过目前所使用的所有模型都只有一个版本,因此不需要使用这个参数。
3. 使用“-s”参数指定图像缩放方式:
有些神经网络算法在执行推理之前,需要对图像进行特定形式的缩放(scaling)处理,因此需要先用这个参数指定缩放的方式,如果没有指定正确的模式,会导致推理结果的错误。目前这个参数支持{NONE, INSPECTION, VGG}三个选项,预设值为“NONE”。
在本实验 Triton 推理服务器所支持的 densenet_onnx 与 inception_graphdef 模型,都需要选择 INSPECTION 缩放方式,因此执行指令中需要用“-s INSPECTION”去指定,否则会得到错误的结果。
请尝试以下指令,省略前面指定中的“-s INSPECTION”,或者指定为 VGG 模式,看看结果如何?
python3 image_client.py -m inception_graphdef -u 192.168.0.10:8000 -s VGG ${HOME}/images/mug.jpg4. 对文件夹所有图片进行推理
如果有多个要进行推理计算的标的物(图片),Triton 用户端可用文件夹为单位来提交要推理的内容,例如以下指令就能一次对 ${HOME}/images 目录下所有图片进行推理:
python3 image_client.py -m inception_graphdef -u 192.168.0.10:8000 -s INCEPTION ${HOME}/images例如我们在文件夹中准备了 car.jpg、mug.jpg、vulture.jpg 三种图片,如下:

执行后反馈的结果如下:

显示推理检测的结果是正确的!
5. 用“-b”参数指定批量处理的值
执行前面指令的结果可以看到“batch size 1”,表示用户端每次提交一张图片进行推理,所以出现 Request1、Request 2 与 Request 3 总共提交三次请求。
现在既然有 3 张图片,可否一次提交 3 张图片进行推理呢?我们可以用“-b”参数来设定,如果将前面的指令中添加“-b3”这个参数,如下:
python3 image_client.py -m inception_graphdef -u 192.168.0.10:8000 -s INCEPTION ${HOME}/images -b 3现在显示的结果如下:

现在看到只提交一次“batch size 3”的请求,就能对三张图片进行推理。如果 batch 值比图片数量大呢?例如改成“-b 5”的时候,看看结果如何?如下:

现在可以看到所推理的图片数量是 5,其中 1/4、2/5 是同一张图片,表示重复使用了。这样就应该能清楚这个“batchsize”值的使用方式。
但如果这里将模型改成 densenet_onnx 的时候,执行以下指令:
python3 image_client.py -m densenet_onnx -u 192.168.0.10:8000 -s INCEPTION ${HOME}/images -b 3会得到“ERROR: This model doesn't support batching.”的错误信息,这时候就回头检查以下模型仓里 densenet_onnx 目录下的 config.pbtxt 配置文件,会发现里面设置了“max_batch_size: 0”,并不支持批量处理。
而 inception_graphdef 模型的配置文件里设置“max_batch_size: 128”,如果指令给定“-b”参数大于这个数值,也会出现错误信息。
6. 其他:
另外还有指定通讯协议的“-i”参数、使用异步推理 API 的“-a”参数、使用流式推理 API 的“--streaming”参数等等,属于较进阶的用法,在这里先不用过度深入。
以上所提供的 5 个主要参数,对初学者来说是非常足够的,好好掌握这几个参数就已经能开始进行更多图像方面的推理实验。
推荐阅读
NVIDIA Jetson Nano 2GB 系列文章(1):开箱介绍

NVIDIA Jetson Nano 2GB 系列文章(2):安装系统
NVIDIA Jetson Nano 2GB 系列文章(3):网络设置及添加 SWAPFile 虚拟内存
NVIDIA Jetson Nano 2GB 系列文章(4):体验并行计算性能
NVIDIA Jetson Nano 2GB 系列文章(5):体验视觉功能库
NVIDIA Jetson Nano 2GB 系列文章(6):安装与调用摄像头
NVIDIA Jetson Nano 2GB 系列文章(8):执行常见机器视觉应用
NVIDIA Jetson Nano 2GB 系列文章(9):调节 CSI 图像质量
NVIDIA Jetson Nano 2GB 系列文章(10):颜色空间动态调节技巧
NVIDIA Jetson Nano 2GB 系列文章(11):你应该了解的 OpenCV
NVIDIA Jetson Nano 2GB 系列文章(12):人脸定位
NVIDIA Jetson Nano 2GB 系列文章(13):身份识别
NVIDIA Jetson Nano 2GB 系列文章(14):Hello AI World
NVIDIA Jetson Nano 2GB 系列文章(15):Hello AI World 环境安装
NVIDIA Jetson Nano 2GB 系列文章(16):10行代码威力
NVIDIA Jetson Nano 2GB 系列文章(17):更换模型得到不同效果
NVIDIA Jetson Nano 2GB 系列文章(18):Utils 的 videoSource 工具
NVIDIA Jetson Nano 2GB 系列文章(19):Utils 的 videoOutput 工具
NVIDIA Jetson Nano 2GB 系列文章(20):“Hello AI World” 扩充参数解析功能
NVIDIA Jetson Nano 2GB 系列文章(21):身份识别

NVIDIA Jetson Nano 2GB 系列文章(22):“Hello AI World” 图像分类代码
NVIDIA Jetson Nano 2GB 系列文章(23):“Hello AI World 的物件识别应用
NVIDIAJetson Nano 2GB 系列文章(24): “Hello AI World” 的物件识别应用
NVIDIAJetson Nano 2GB 系列文章(25): “Hello AI World” 图像分类的模型训练
NVIDIAJetson Nano 2GB 系列文章(26): “Hello AI World” 物件检测的模型训练
NVIDIAJetson Nano 2GB 系列文章(27): DeepStream 简介与启用
NVIDIAJetson Nano 2GB 系列文章(28): DeepStream 初体验
NVIDIAJetson Nano 2GB 系列文章(29): DeepStream 目标追踪功能
NVIDIAJetson Nano 2GB 系列文章(30): DeepStream 摄像头“实时性能”
NVIDIAJetson Nano 2GB 系列文章(31): DeepStream 多模型组合检测-1
NVIDIAJetson Nano 2GB 系列文章(32): 架构说明与deepstream-test范例
NVIDIAJetsonNano 2GB 系列文章(33): DeepStream 车牌识别与私密信息遮盖
NVIDIA Jetson Nano 2GB 系列文章(34): DeepStream 安装Python开发环境
NVIDIAJetson Nano 2GB 系列文章(35): Python版test1实战说明
NVIDIAJetson Nano 2GB 系列文章(36): 加入USB输入与RTSP输出
NVIDIAJetson Nano 2GB 系列文章(37): 多网路模型合成功能
NVIDIAJetson Nano 2GB 系列文章(38): nvdsanalytics视频分析插件
NVIDIAJetson Nano 2GB 系列文章(39): 结合IoT信息传输
NVIDIAJetson Nano 2GB 系列文章(40): Jetbot系统介绍
NVIDIAJetson Nano 2GB 系列文章(41): 软件环境安装
NVIDIAJetson Nano 2GB 系列文章(42): 无线WIFI的安装与调试
NVIDIAJetson Nano 2GB 系列文章(43): CSI摄像头安装与测试
NVIDIAJetson Nano 2GB 系列文章(44): Jetson的40针引脚
NVIDIAJetson Nano 2GB 系列文章(46): 机电控制设备的安装
NVIDIAJetson Nano 2GB 系列文章(47): 组装过程的注意细节
NVIDIAJetson Nano 2GB 系列文章(48): 用键盘与摇杆控制行动
NVIDIAJetson Nano 2GB 系列文章(49): 智能避撞之现场演示
NVIDIAJetson Nano 2GB 系列文章(50): 智能避障之模型训练
NVIDIAJetson Nano 2GB 系列文章(51): 图像分类法实现找路功能
NVIDIAJetson Nano 2GB 系列文章(52): 图像分类法实现找路功能
NVIDIAJetson Nano 2GB 系列文章(53): 简化模型训练流程的TAO工具套件
NVIDIA Jetson Nano 2GB 系列文章(54):NGC的内容简介与注册密钥
NVIDIA Jetson Nano 2GB 系列文章(55):安装TAO模型训练工具
NVIDIA Jetson Nano 2GB 系列文章(56):启动器CLI指令集与配置文件
NVIDIA Jetson Nano 2GB 系列文章(57):视觉类脚本的环境配置与映射
NVIDIA Jetson Nano 2GB 系列文章(58):视觉类的数据格式
NVIDIA Jetson Nano 2GB 系列文章(59):视觉类的数据增强
NVIDIA Jetson Nano 2GB 系列文章(60):图像分类的模型训练与修剪
NVIDIA Jetson Nano 2GB 系列文章(61):物件检测的模型训练与优化
NVIDIA Jetson Nano 2GB 系列文章(62):物件检测的模型训练与优化-2
NVIDIA Jetson Nano 2GB 系列文章(63):物件检测的模型训练与优化-3
NVIDIA Jetson Nano 2GB 系列文章(64):将模型部署到Jetson设备
NVIDIA Jetson Nano 2GB 系列文章(65):执行部署的 TensorRT 加速引擎
NVIDIA Jetson 系列文章(1):硬件开箱

NVIDIA Jetson 系列文章(2):配置操作系统
NVIDIA Jetson 系列文章(3):安装开发环境
NVIDIA Jetson 系列文章(4):安装DeepStream
NVIDIA Jetson 系列文章(5):使用Docker容器的入门技巧
NVIDIA Jetson 系列文章(6):使用容器版DeepStream
NVIDIA Jetson 系列文章(7):配置DS容器Python开发环境
NVIDIA Jetson 系列文章(8):用DS容器执行Python范例
NVIDIA Jetson 系列文章(9):为容器接入USB摄像头
NVIDIA Jetson 系列文章(10):从头创建Jetson的容器(1)
NVIDIA Jetson 系列文章(11):从头创建Jetson的容器(2)
NVIDIA Jetson 系列文章(12):创建各种YOLO-l4t容器
NVIDIA Triton系列文章(1):应用概论
NVIDIA Triton系列文章(2):功能与架构简介
NVIDIA Triton系列文章(3):开发资源说明
NVIDIA Triton系列文章(4):创建模型仓
NVIDIA Triton 系列文章(5):安装服务器软件
NVIDIA Triton 系列文章(6):安装用户端软件
原文标题:NVIDIA Triton 系列文章(7):image_client 用户端参数
文章出处:【微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
-
英伟达
+关注
关注
23文章
4115浏览量
99613
原文标题:NVIDIA Triton 系列文章(7):image_client 用户端参数
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
沐曦股份曦云C系列GPU产品Day 0适配百度文心ERNIE-Image文生图模型
NVIDIA Jetson模型赋能AI在边缘端落地

借助NVIDIA CUDA Tile IR后端推进OpenAI Triton的GPU编程
电话光端机选广州邮科靠谱吗?局端和用户端到底有什么区别?能混用吗?一文全解答!

面向科学仿真的开放模型系列NVIDIA Apollo正式发布
在NVIDIA DGX Spark平台上对NVIDIA ConnectX-7 200G网卡配置教程
umqtt_deliver_message 用户端注册执行函数的回调,用户端的消息回调函数没有被执行到,为什么?
光缆怎么分ab端
NVIDIA桌面GPU系列扩展新产品
如何本地部署NVIDIA Cosmos Reason-1-7B模型
使用NVIDIA Triton和TensorRT-LLM部署TTS应用的最佳实践

普密斯IMAGE 3系列:珠宝加工行业的尺寸测量新宠

Acrel-3000峰平谷用电量统计电能计量管理系统
ServiceNow携手NVIDIA构建150亿参数超级助手
如何在Ubuntu上安装NVIDIA显卡驱动?



评论