 超异构带来的算力指数级提升,使得Chiplet的价值得到更加充分的发挥
超异构带来的算力指数级提升,使得Chiplet的价值得到更加充分的发挥

编者按
Chiplet标准UCIe已经得到很多主流大厂的认可,席卷之势愈发明显。但就Chiplet的价值挖掘,目前可见的,都还停留在如何降成本和简单地扩大设计规模方面。我们觉得,Chiplet的价值还没有得到充分挖掘。 Chiplet带来的价值,不应该是线性增长,而应该是指数增长:
一方面,量变会引起质变,Chiplet的流行,快速增加的单芯片设计规模,会给系统架构创新提供更大的发挥空间,使得计算的架构,从异构走向超异构。
另一方面,超异构带来的算力指数级提升,使得Chiplet的价值得到更加充分的发挥,反过来会促进Chiplet的大范围流行。
1 背景知识
1.1 单DIE性能和成本
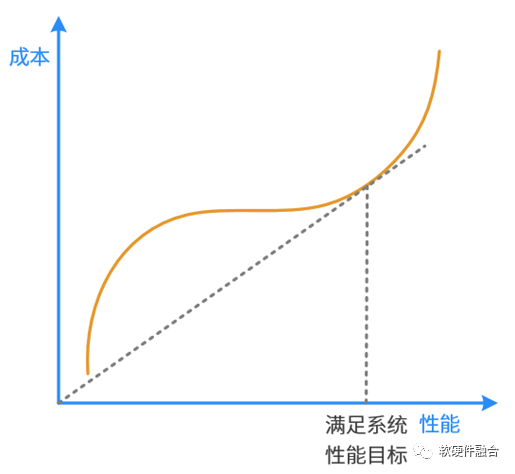
单DIE的性能和成本,是正相关的关系。通常的芯片DIE设计,一定是在保证系统所需性能的条件下,选择最合适的工艺,达到最合适的面积(成本),达到在性能约束条件下的性能成本比最优。或者说:
在系统性能成本最优的状态下,受边际效应影响,想再想增加单DIE性能,所需要付出的成本代价非常高,会显著影响性价比。
在系统性能成本最优的状态下,想要再优化单DIE成本,可能会引起性能的大比例下降,反而不是性价比最优。
1.2 Chiplet协议UCIe
英特尔、AMD、ARM、高通、三星、台积电、日月光等大厂,以及Google Cloud、Meta、微软于2022年3月2日宣布了一项新技术标准UCIe(Universal Chiplet Interconnect Express)。UCIe是一个开放的行业互连标准,可以实现小芯片之间的封装级互连,具有高带宽、低延迟、经济节能的优点。 UCIe能够满足几乎所有计算领域,包括云端、边缘端、企业、5G、汽车、高性能计算和移动设备等,对算力、内存、存储和互连不断增长的需求。UCIe 具有封装集成不同Die的能力,这些Die可以来自不同的晶圆厂、采用不同的设计和封装方式。

UCIe白皮书中给出的Chiplets封装集成的价值:
首先是面积的影响。为了满足不断增长的性能需求,芯片面积增加,有些设计甚至会超出掩模版面积的限制。即使不超过面积限制,改用多个小芯片也更有利于提升良率。另外,多个相同Die的集成封装能够适用于更大规模的场景。
另一个价值体现在降低成本。例如,处理器核心可以采用先进的工艺,用更高的成本换取极致的性能,而内存和I/O控制器则可以复用非先进工艺。随着工艺节点的进步,成本增长非常迅速。若采用多Die集成模式,有些Die的功能不变,我们不必对其采用先进工艺,可在节省成本的同时快速抢占市场。Chiplet封装集成模式还可以使用户能够自主选择Die的数量和类型。例如,用户可以根据需求挑选任意数量的计算、内存和I/O Die,并无需进行Die的定制设计,可降低产品的SKU成本。
允许厂商能够以快速且经济的方式提供定制解决方案。如图1所示,不同的应用场景可能需要不同的计算加速能力,但可以使用同一种核心、内存和I/O。Chiplet方式允许厂商根据功能需求对不同的功能单元应用不同的工艺节点,并实现共同封装。相比板级互连,封装级互连具有线长更短、布线更紧密的优点。
1.3 超异构计算
系统变得越来越庞大,系统可以分解成很多个子系统,子系统的规模已经达到传统单系统的规模。因此,都升级一下:系统变成了宏系统,子系统变成了系统。 系统足够庞大,场景综合,单类型架构无法包打天下:
CPU灵活性最好,但性能较差;
DSA性能很好,但灵活性差;
GPU介于两者之间,可以说能较好的平衡性能和灵活性,也可以说,性能和灵活性都不够极致。
规模庞大的复杂系统存在很多硬件加速的空间:
复杂系统最核心的一个特征是二八定律。用户只关心自己的应用,而应用通常只占系统的20%,另外80%用户不关心的也相对确定的部分,一般称为基础设施,这些是可以通过硬件加速来优化性能的。
系统是逐步发展和沉淀的。很多原本属于应用层的工作任务,随着时间推移,越来越成熟,逐渐地沉淀成了基础设施。这些沉淀的工作任务可以通过硬件加速来优化性能。最典型的场景是AI推理,现在已经成为了基础的服务,供不同的应用调用。
在云计算、边缘计算等形式的综合计算模式下,单个用户应用的规模可能不大,但因为云计算的超大规模和多租户,很多相似的用户应用其总和规模足够庞大,因此,也可以通过GPU、FPGA或专用芯片的方式进行加速优化。
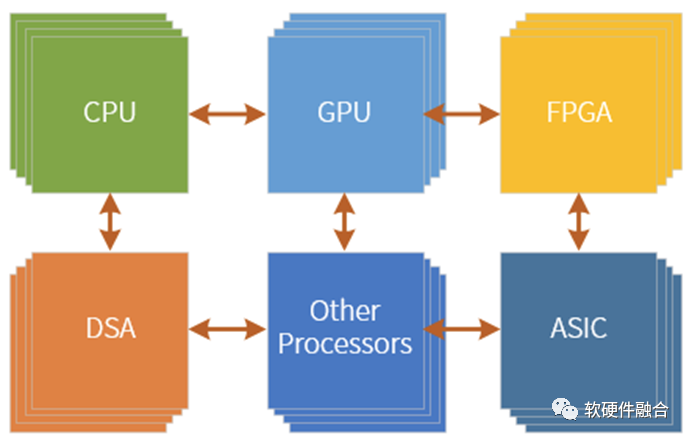
那么,要做的就是扬长避短,把不同类型的处理引擎协作起来,把各种引擎的优势充分利用起来,形成超异构计算架构:
DSA负责相对确定的大计算量的工作;
GPU负责应用层有一些性能敏感的并且有一定弹性的工作;
CPU啥都能干,负责兜底。
于是整个系统架构就变成了超异构架构。
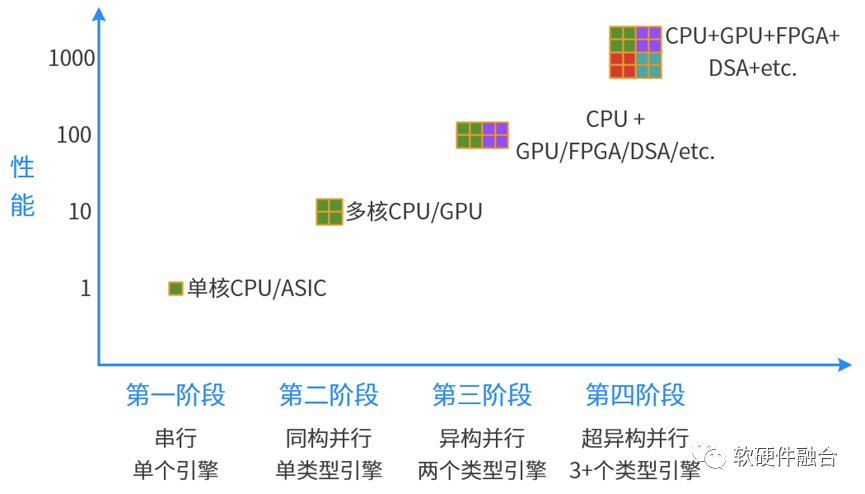
总结一下计算架构发展的四个阶段:
第一阶段,单CPU串行计算;
第二极端,多核CPU的并行计算;
第三阶段,CPU+xPU的异构计算;
第四阶段,CPU+GPU+DSA+etc.的超异构计算。
2 Chiplet技术方案
2.1 方案1:设计规模不变,优化单DIE面积和良率等
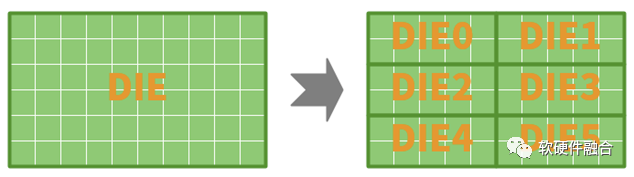
一般情况下,在同等工艺同等功耗技术下,我们可以简单地认为,面积和成本成正比的。Chiplet实现用面积更小的DIE,实现同等规模设计,其优势主要为:
单DIE面积变小,增加芯片良率。而通常,单DIE的面积是已经平衡好良率的情况下的,再减小面积优化良率,可能效果并不是很明显。并且,多DIE封装会带来额外的良率风险。这样,一里一外的问题,通过多DIE来优化良率的效果可能就不会很明显。
可以让一些DIE不采用先进工艺,通过较低一些的工艺降低成本。
在不改变性能的条件下,通过Chiplet封装可以降低成本;也可以反过来说,在同样成本条件下,通过Chiplet封装可以提升性能。
2.2 方案2:单DIE设计规模不变,多DIE集成
当我们确定好单个DIE的性能和面积(功耗)的时候,这个时候相当于是把工艺的价值挖掘到了最优。需要Chiplet的价值,也同样需要工艺的价值,都不能少。 我们要做的是在工艺价值的基础上,再叠加Chiplet封装的价值。而不是如方案1一样,为了Chiplet而Chiplet,反而放弃工艺的价值。 因此,我们可以在原有DIE的基础上,通过多DIE封装来立竿见影地提升性能。
2.3 方案3:多DIE集成设计规模倍增,并且重构系统
通常,CPU组成的芯片,性能不够;而GPU、DSA组成的芯片无法单独工作,需要外挂CPU,形成CPU+XPU的异构计算架构;而SOC本质上是CPU+xPU的多个异构系统的集成。 异构计算和SOC,本质上都是以CPU为中心的系统,XPU是一个个孤岛,所有的事情都需要CPU的参与才能把这些处理引串起来。 超异构完全打破不同处理引擎之间的界限,CPU和其他XPU同样的地位,XPU间可以非常充分的交互,达到系统充分的整合。超异构计算可以做到:
性能和灵活性兼顾。因为二八定律的缘故,绝大部分计算是在DSA级别的处理引擎中完成,所以性能效率很好。而用户关心的应用依然是在CPU级别的处理引擎完成,又兼顾了灵活可编程性。
因为超异构计算架构可以驾驭更大的系统,因此,可以做到,在性能效率和DSA同量级的情况下,性能相比DSA再数量级的提升。
2.4 方案性能提升对比
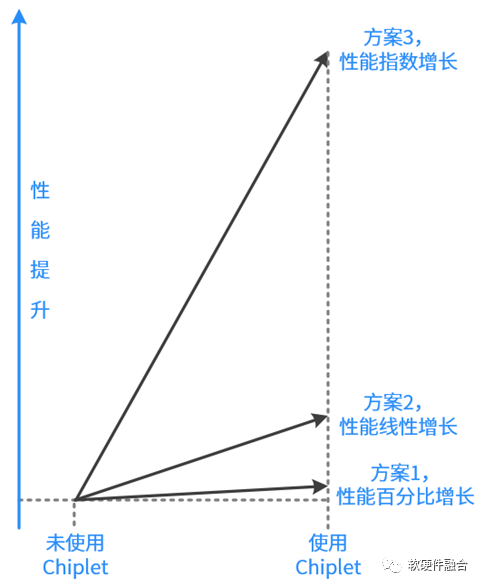
注意:本节内容是定性分析,还无法做到定量分析。 方案1,可以实现性能的百分比增长。方案1的道理很好理解,本来的目标是优化成本,在同等性能情况下,能够百分比地优化成本。我们相应地折算一下,在同等成本下,方案1可以做到性能的百分比提升。 方案2,可以实现性能的线性增长。方案2也很好理解,通过增加更多数量的DIE来提升并行度,以此来提升性能。集成多少个DIE,性能就增加到多少倍。 方案3,可以实现性能的指数增长。方案3通过整个系统重构,挖掘系统的一些可加速的点,然后再实现整个系统的充分整合重构。以此来提升性能。可以达到数量级的性能增长。
3 总结
3.1 设计规模的量变,引起系统架构的质变
规模是一个很重要的因素。 云计算百万台的超大规模,其软硬件架构和运营模式跟传统的数百台的私有机房是完全迥异的。深度神经网络,通过更大量数据、更深层次网络的量变,成就了AI的“智”变。 芯片也是同样的道理,随着规模的增长,很多设计方案考虑的问题会跟以前完全不一样。在小规模的时候,我们强调定制,极度优化性能和功耗等;但等到超大规模IC设计,我们更多关注的是通用性、可编程性、易用性、生态等。 Chiplet机制,提供了立竿见影让芯片设计规模数量级增加的能力。如果我们不在系统架构层次创新,充分利用芯片规模数量级增加的这个优势,只是简单的平行扩展,那真是暴殄天物,浪费Chiplet给系统架构师们的馈赠。 换个角度,现有的异构计算也好,SOC也好,无法驾驭Chiplet提供的超大规模芯片系统。需要本质的、体系性的系统架构创新,来更好地驾驭Chiplet的价值。
3.2 超异构,让Chiplet价值得到更大的发挥
超异构集成更多的处理引擎,提供更高的并行性,实现更分布式的系统,可以更好地驾驭数量级增加的芯片设计规模。 此外,Chiplet更好地容纳现有宏系统的承载,通过超异构,使得很多性能优化措施得到落实,从而使得性能指数级增长(而不是根据面积的增加,线性增长)。 可以说,超异构,成就了Chiplet更大的价值,使得Chiplet方案得到更大范围的落地,促进Chiplet技术的成熟和市场繁荣。
3.3 Chiplet和超异构的关系:双剑合璧,相互成就
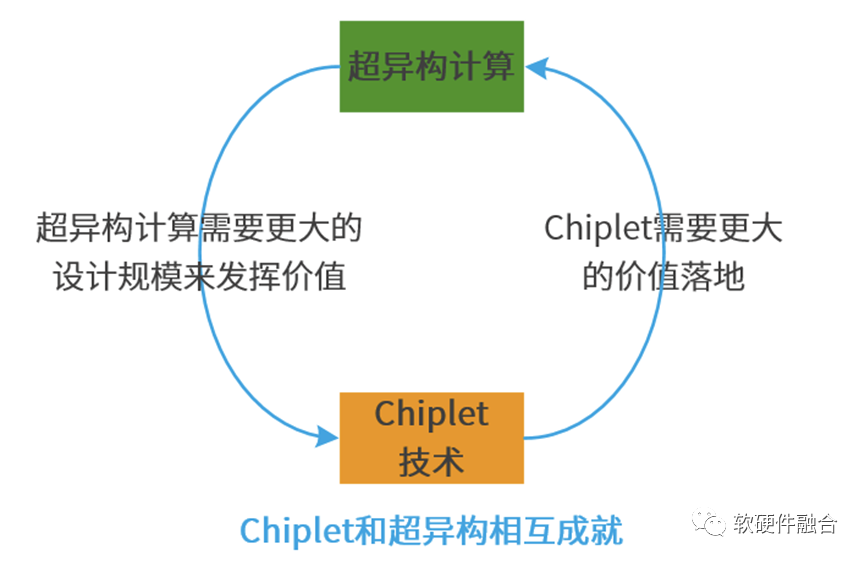
超异构计算和Chiplet技术是相互协同、相互成就的关系:
系统越大,设计规模越大,超异构的性能优势就越明显。
超异构计算,需要数量级提升的晶体管资源,而Chiplet可以在芯片层次提供如此规模的晶体管资源,实现超异构计算方案和价值落地。
超异构计算的价值得到充分体现,超异构不断落地,会带动Chiplet的价值发挥、更广泛的落地以及市场繁荣。
随着超异构的发展,对Chiplet的要求会不断提高,需要Chiplet技术向更高的能力迈进。
审核编辑 :李倩
-
单芯片
+关注
关注
3文章
498浏览量
36199 -
chiplet
+关注
关注
6文章
499浏览量
13645 -
UCIe
+关注
关注
0文章
53浏览量
2033
原文标题:超异构 x Chiplet:双剑合璧,实现算力指数级提升
文章出处:【微信号:IP与SoC设计,微信公众号:IP与SoC设计】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录

边缘AI算力临界点:深度解析176TOPS香橙派AI Station的产业价值
多Chiplet异构集成的先进互连技术

如何突破AI存储墙?深度解析ONFI 6.0高速接口与Chiplet解耦架构
北大团队最新研究:AI芯片算力提升数倍,能效提升超90倍

从CPU、GPU到NPU,美格智能持续优化异构算力计算效能

国产AI芯片真能扛住“算力内卷”?海思昇腾的这波操作藏了多少细节?

什么是AI算力模组?

什么是AI算力模组?

中科曙光超智融合方案助力国产算力中心建设
软通智算完成超亿级A轮融资,加速AI算力产业布局
润和软件发布StackRUNS异构分布式推理框架




评论