 NVIDIA与飞桨共同深度适配的NGC飞桨容器在NVIDIA GPU上体验
NVIDIA与飞桨共同深度适配的NGC飞桨容器在NVIDIA GPU上体验

PaddleOCR 发版 v2.6,带来全新升级的 PP-StructureV2 智能文档分析系统,实现一键 PDF 转 Word。欢迎广大开发者使用 NVIDIA 与飞桨共同深度适配的 NGC 飞桨容器在 NVIDIA GPU 上体验!
1. PaddleOCR v2.6 版本升级
随着企业数字化进程不断加速,PDF 转 Word 的功能、纸质文本的电子化存储、文件复原与二次编辑、信息检索等应用都有着强烈的企业需求。目前市面上已有一些软件,但普遍需要繁琐的安装注册操作,大多还存在额度限制。此外,最终转换效果也依赖于版面形态,无法做到针对性适配。
针对开发者的需求,飞桨文字识别套件 PaddleOCR 全新发布 PP-StructureV2 智能文档分析系统,支持一行命令实现 PDF 转 Word 功能,文字、表格、标题、图片都可完整恢复,一键实现 PDF 编辑自由!

文档分析示例
PP-StructureV2 智能文档分析系统升级点包括以下 2 方面:
系统功能升级:新增图像矫正和版面复原模块,支持标准格式 PDF 和图片格式 PDF 解析!
系统性能优化:
版面分析:发布轻量级版面分析模型,速度提升 11 倍,平均 CPU 耗时仅需 41ms!
表格识别:设计 3 大优化策略,预测耗时不变情况下,模型精度提升 6%。
关键信息抽取:设计视觉无关模型结构,语义实体识别精度提升 2.8%,关系抽取精度提升超过 9.1%。
GitHub 传送门:
https://github.com/PaddlePaddle/PaddleOCR
1.1 PP-StructureV2 智能文档分析系统优化策略概述
PP-StructureV2 系统流程图如下所示,文档图像首先经过图像矫正模块,判断整图方向并完成转正,随后可以完成版面信息分析与关键信息抽取 2 类任务。
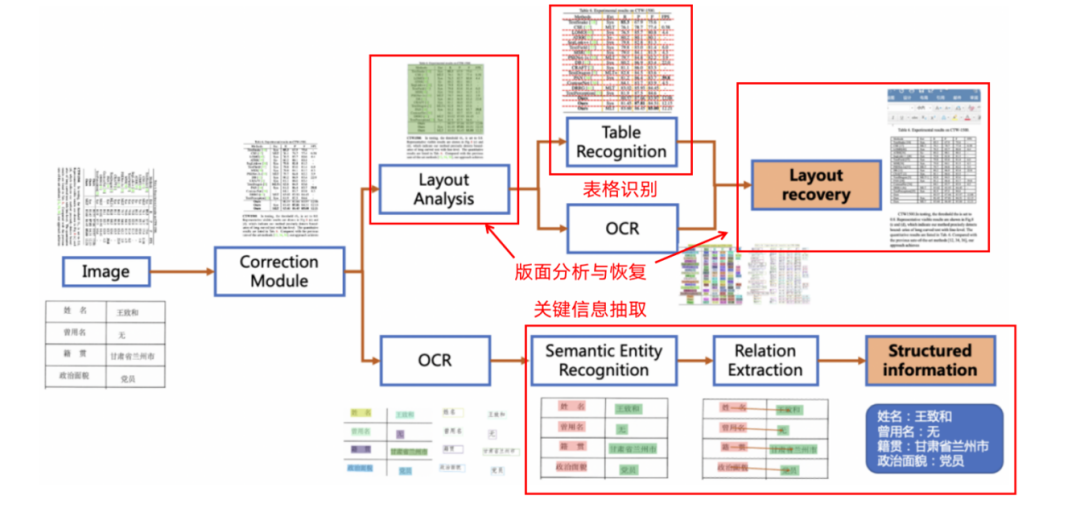
在版面分析任务中,图像首先经过版面分析模型,将图像划分为文本、表格、图像等不同区域,随后对这些区域分别进行识别,如,将表格区域送入表格识别模块进行结构化识别,将文本区域送入 OCR 引擎进行文字识别,最后使用版面恢复模块将其恢复为与原始图像布局一致的 Word 或者 PDF 格式的文件。
在关键信息抽取任务中,首先使用 OCR 引擎提取文本内容,然后由语义实体识别模块获取图像中的语义实体,最后经关系抽取模块获取语义实体之间的对应关系,从而提取需要的关键信息。
从算法改进思路来看,对系统中的 3 个关键子模块,共进行了 8 个方面的改进:
版面分析
PP-PicoDet:轻量级版面分析模型
FGD:兼顾全局与局部特征的模型蒸馏算法
表格识别
PP-LCNet: CPU 友好型轻量级骨干网络
CSP-PAN:轻量级高低层特征融合模块
SLAHead:结构与位置信息对齐的特征解码模块
关键信息抽取
VI-LayoutXLM:视觉特征无关的多模态预训练模型结构
TB-YX:考虑阅读顺序的文本行排序逻辑
UDML:联合互学习知识蒸馏策略
最终,与 PP-StructureV1 相比:
版面分析模型参数量减少 95%,推理速度提升 11 倍,精度提升 0.4%;
表格识别预测耗时不变,模型精度提升 6%,端到端 TEDS 提升 2%;
关键信息抽取模型速度提升 2.8 倍,语义实体识别模型精度提升 2.8%;关系抽取模型精度提升 9.1%。
PP-StructureV2 优化详细策略解析三日课回放,可以扫描下方二维码,加入 PaddleOCR 官方交流群获取。除此之外,入群福利还包括:社区开发者基于 PP-StructureV2 开发的 PDF2Word 应用程序、《动手学 OCR》电子书、10 个 OCR 场景应用垂类模型等。
PP-StructureV2 技术报告:
https://arxiv.org/abs/2210.05391v2
2. NGC 飞桨容器介绍
如果您希望体验 PaddleOCRv2.6 的新特性,欢迎使用 NGC 飞桨容器。NVIDIA 与百度飞桨共同开发了 NGC 飞桨容器,将最新版本的飞桨与最新的 NVIDIA 的软件栈(如 CUDA)进行了无缝的集成与性能优化,最大程度的释放飞桨框架在 NVIDIA 最新硬件上的计算能力。这样,用户不仅可以快速开启 AI 应用,专注于创新和应用本身,还能够在 AI 训练和推理任务上获得飞桨+NVIDIA 带来的飞速体验。
最佳的开发环境搭建工具 - 容器技术。
容器其实是一个开箱即用的服务器。极大降低了深度学习开发环境的搭建难度。例如你的开发环境中包含其他依赖进程(redis,MySQL,Ngnix,selenium-hub等等),或者你需要进行跨操作系统级别的迁移。
容器镜像方便了开发者的版本化管理
容器镜像是一种易于复现的开发环境载体
容器技术支持多容器同时运行
最好的 PaddlePaddle 容器
NGC 飞桨容器针对 NVIDIA GPU 加速进行了优化,并包含一组经过验证的库,可启用和优化 NVIDIA GPU 性能。此容器还可能包含对 PaddlePaddle 源代码的修改,以最大限度地提高性能和兼容性。此容器还包含用于加速 ETL (DALI, RAPIDS)、训练(cuDNN, NCCL)和推理 (TensorRT)工作负载的软件。
PaddlePaddle 容器具有以下优点:
适配最新版本的 NVIDIA 软件栈(例如最新版本 CUDA),更多功能,更高性能。
更新的 Ubuntu 操作系统,更好的软件兼容性
按月更新
满足 NVIDIA NGC 开发及验证规范,质量管理
通过飞桨官网快速获取
环境准备
使用 NGC 飞桨容器需要主机系统(Linux)安装以下内容:
Docker 引擎
NVIDIA GPU 驱动程序
NVIDIA 容器工具包
有关支持的版本,请参阅 NVIDIA 框架容器支持矩阵和 NVIDIA 容器工具包文档。
不需要其他安装、编译或依赖管理。无需安装 NVIDIA CUDA Toolkit。
3. 飞桨与 NVIDIA NGC 合作介绍
目前飞桨已拥有超过 470 万的开发者。而在过去五年,飞桨与 NVIDIA 团队紧密合作,双方深度融合,做了大量适配工作。
今年,NVIDIA 在国内也已经设立了专门的工程团队支持,赋能飞桨生态。
而为了让更多的开发者能用上基于 NVIDIA 最新的高性能硬件和软件栈。当前,NVIDIA 团队正在进行全新一代 GPU 的适配工作,以及提高飞桨对 CUDA Operation API 的使用率,让飞桨的开发者拥有优秀的用户体验及极致性能。
以上的各种适配,仅仅是让飞桨的开发者拥有高性能的推理训练成为可能。但是,这些离行业开发者还很远,门槛还很高,难度还很大。
为此,我们将刚刚这些集成和优化工作,整合到三大产品线中。其中 NGC 飞桨容器最为闪亮。
-
NVIDIA
+关注
关注
14文章
5696浏览量
110119 -
存储
+关注
关注
13文章
4892浏览量
90292 -
gpu
+关注
关注
28文章
5272浏览量
136075 -
飞桨
+关注
关注
0文章
37浏览量
2667
原文标题:在 NVIDIA NGC 上体验一键 PDF 转 Word
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
瀚博半导体宣布深度参与百度飞桨黑客松生态活动
沐曦股份与百度飞桨黑客松硬核赛题来袭

NVIDIA向Kubernetes社区捐赠动态资源分配GPU驱动程序
沐曦曦索GPU产品赋能AI4S重塑材料研发新范式

NVIDIA RTX PRO 5000 Blackwell GPU的深度评测

NVIDIA RTX PRO 4000 Blackwell GPU性能测试

在Python中借助NVIDIA CUDA Tile简化GPU编程

NVIDIA RTX PRO 2000 Blackwell GPU性能测试

智能变桨:基于DSP与CPLD协同处理的高动态飞行器主桨电动变桨距伺服控制系统

飞桨PaddleMaterials完成与沐曦AI芯片深度适配

沐曦与百度飞桨PaddleScience实现全面深度适配
NVIDIA RTX PRO 4500 Blackwell GPU测试分析




评论