 用Python算法预测客户行为案例!
用Python算法预测客户行为案例!

这是一份kaggle上的银行的数据集,研究该数据集可以预测客户是否认购定期存款y。这里包含20个特征。
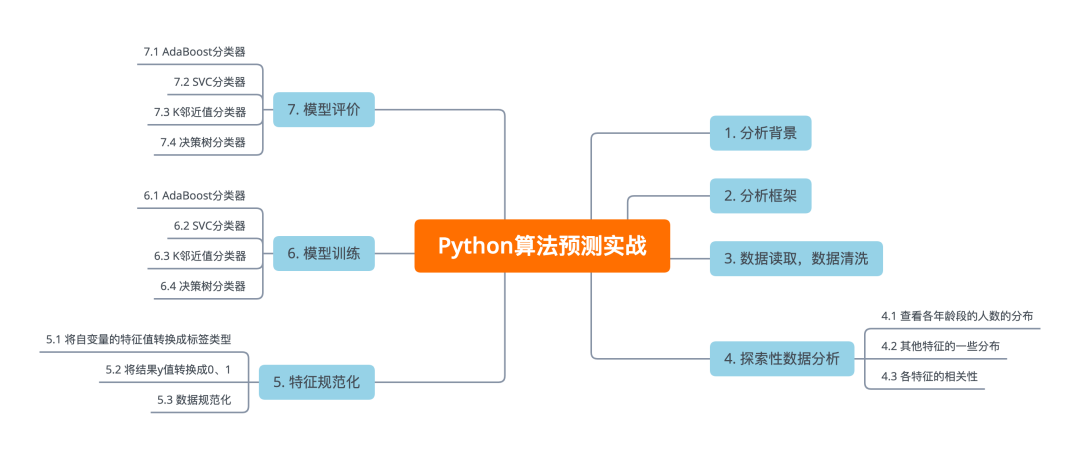
1. 分析框架
2. 数据读取,数据清洗
#导入相关包
importnumpyasnp
importpandasaspd
#读取数据
data=pd.read_csv('./1bank-additional-full.csv')
#查看表的行列数
data.shape
输出:
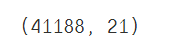
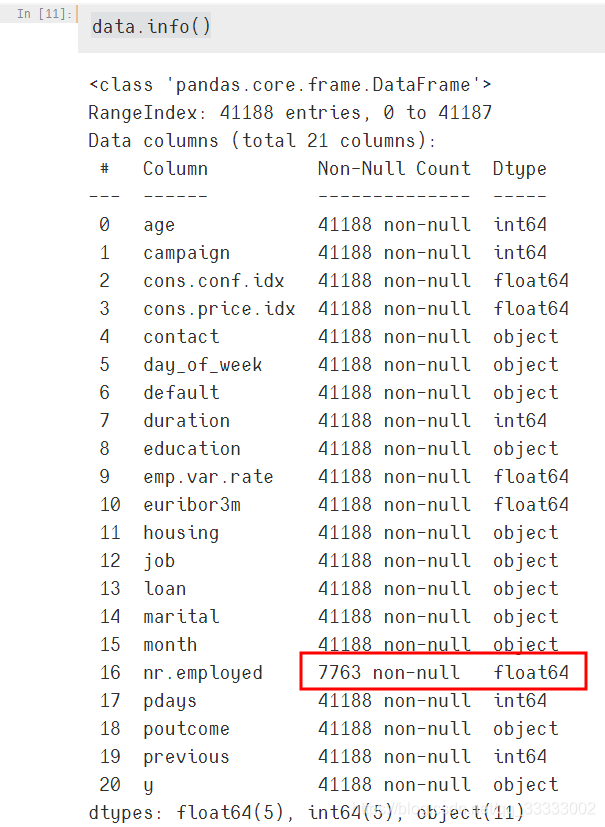
这里只有nr.employed这列有丢失数据,查看下:
data['nr.employed'].value_counts()

这里只有5191.0这个值,没有其他的,且只有7763条数据,这里直接将这列当做异常值,直接将这列直接删除了。
#data.drop('nr.employed',axis=1,inplace=True)
3. 探索性数据分析
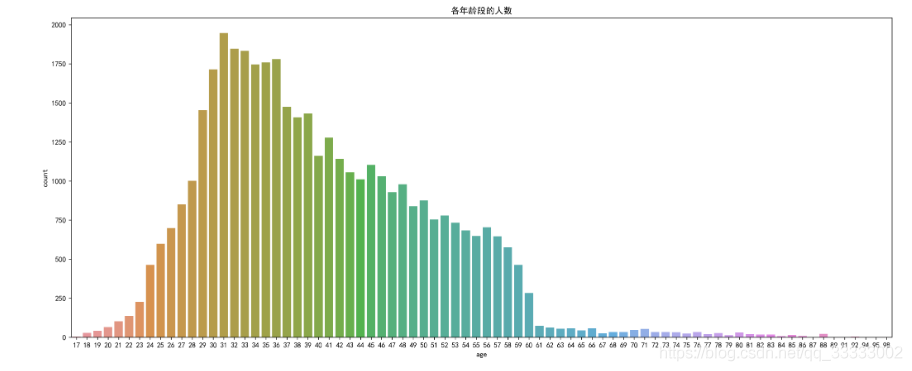
3.1查看各年龄段的人数的分布
这里可以看出该银行的主要用户主要集中在23-60岁这个年龄层,其中29-39这个年龄段的人数相对其他年龄段多。
importmatplotlib.pyplotasplt
importseabornassns
plt.rcParams['font.sans-serif']='SimHei'
plt.figure(figsize=(20,8),dpi=256)
sns.countplot(x='age',data=data)
plt.title("各年龄段的人数")
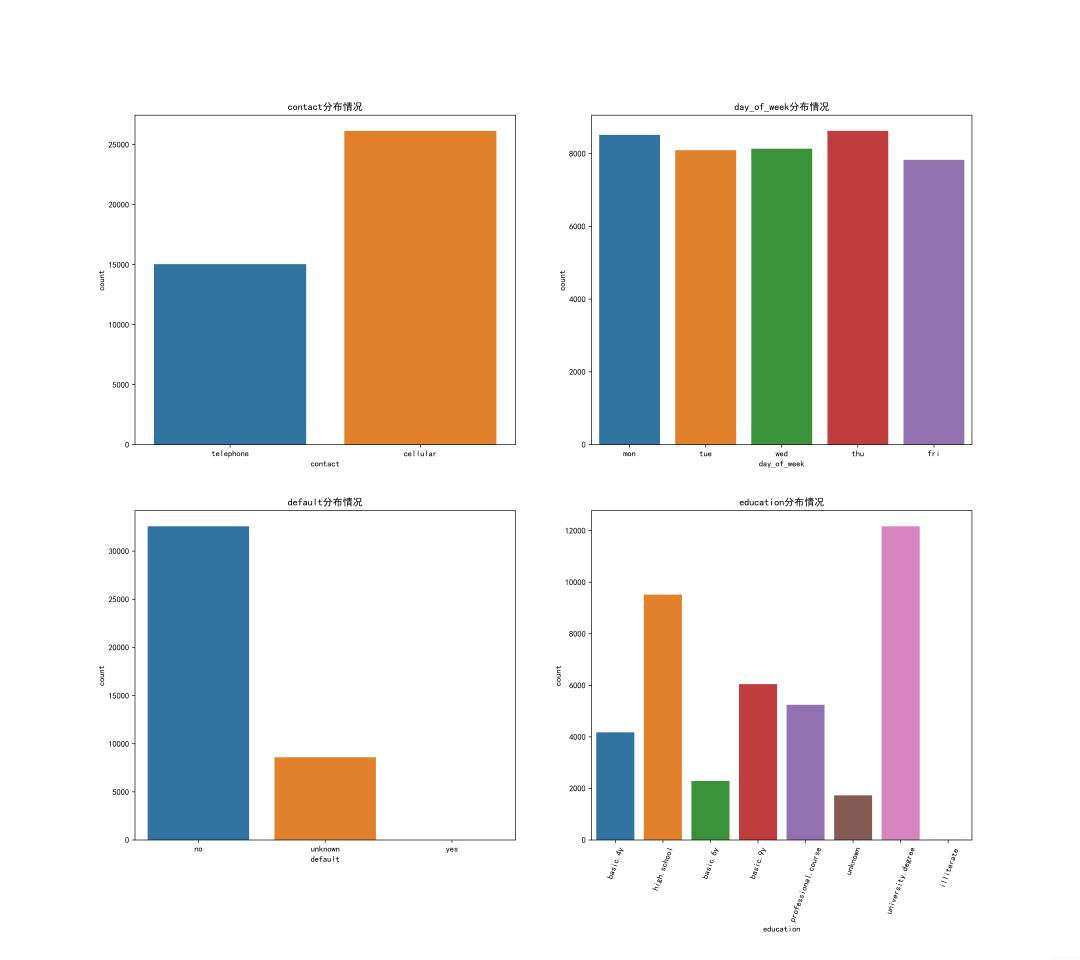
3.2 其他特征的一些分布
plt.figure(figsize=(18,16),dpi=512)
plt.subplot(221)
sns.countplot(x='contact',data=data)
plt.title("contact分布情况")
plt.subplot(222)
sns.countplot(x='day_of_week',data=data)
plt.title("day_of_week分布情况")
plt.subplot(223)
sns.countplot(x='default',data=data)
plt.title("default分布情况")
plt.subplot(224)
sns.countplot(x='education',data=data)
plt.xticks(rotation=70)
plt.title("education分布情况")
plt.savefig('./1.png')
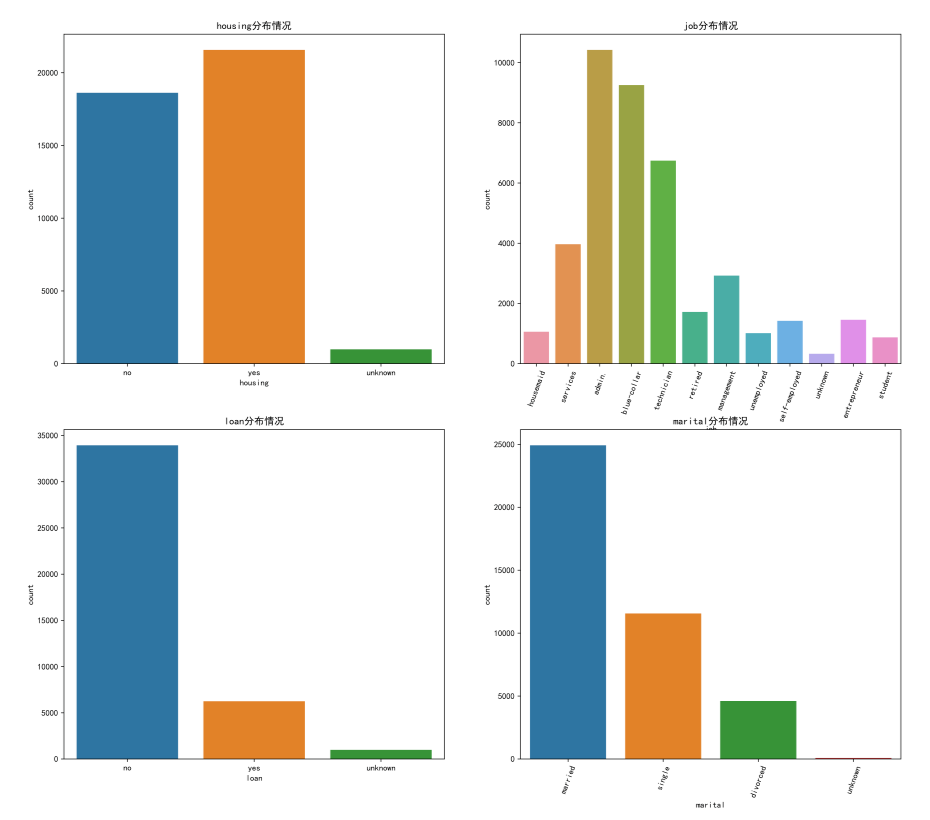
plt.figure(figsize=(18,16),dpi=512)
plt.subplot(221)
sns.countplot(x='housing',data=data)
plt.title("housing分布情况")
plt.subplot(222)
sns.countplot(x='job',data=data)
plt.xticks(rotation=70)
plt.title("job分布情况")
plt.subplot(223)
sns.countplot(x='loan',data=data)
plt.title("loan分布情况")
plt.subplot(224)
sns.countplot(x='marital',data=data)
plt.xticks(rotation=70)
plt.title("marital分布情况")
plt.savefig('./2.png')
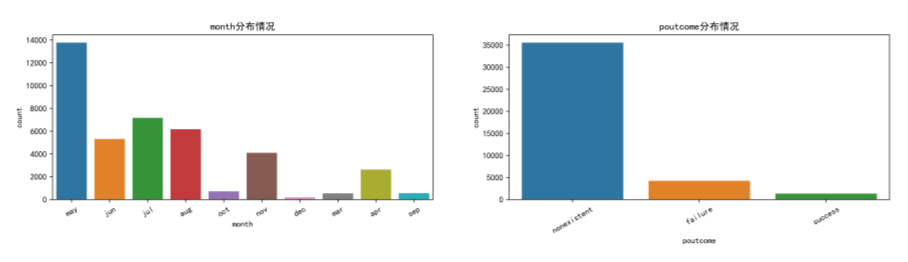
plt.figure(figsize=(18,8),dpi=512)
plt.subplot(221)
sns.countplot(x='month',data=data)
plt.xticks(rotation=30)
plt.subplot(222)
sns.countplot(x='poutcome',data=data)
plt.xticks(rotation=30)
plt.savefig('./3.png')
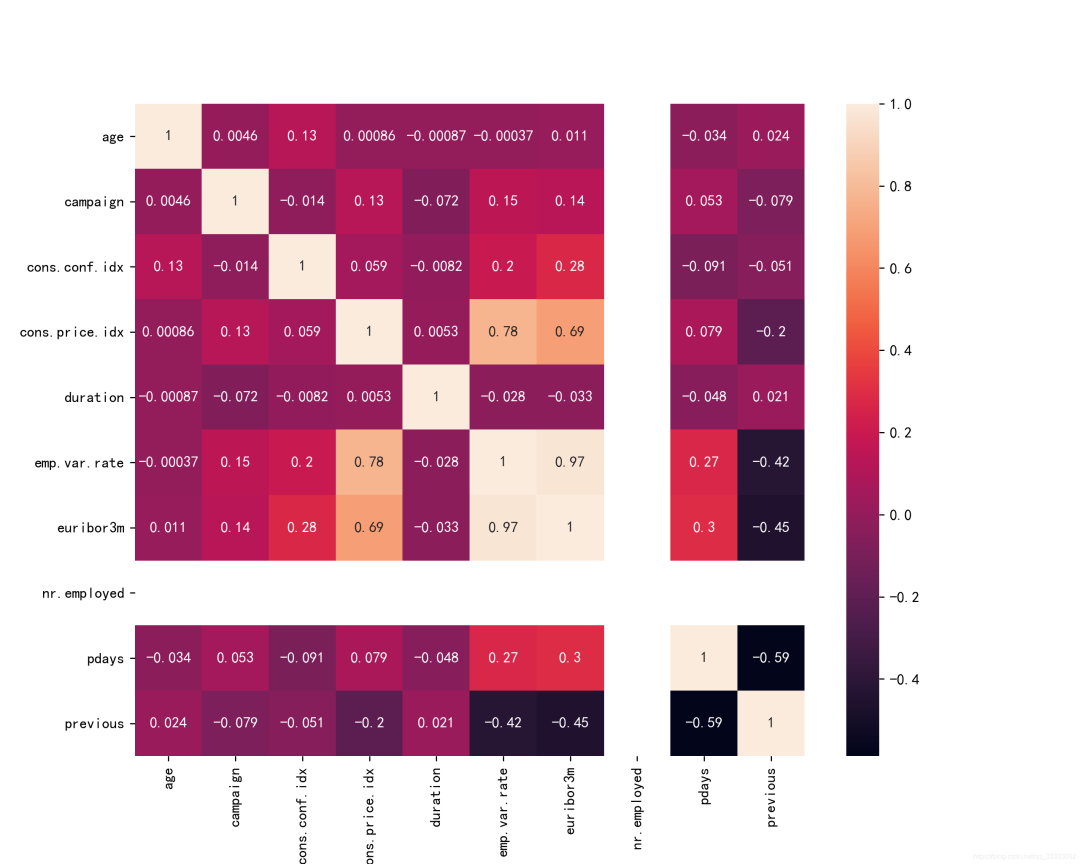
3.3 各特征的相关性
plt.figure(figsize=(10,8),dpi=256)
plt.rcParams['axes.unicode_minus']=False
sns.heatmap(data.corr(),annot=True)
plt.savefig('./4.png')
4. 特征规范化
4.1 将自变量的特征值转换成标签类型
#特征化数据
fromsklearn.preprocessingimportLabelEncoder
features=['contact','day_of_week','default','education','housing',
'job','loan','marital','month','poutcome']
le_x=LabelEncoder()
forfeatureinfeatures:
data[feature]=le_x.fit_transform(data[feature])
4.2 将结果y值转换成0、1
defparse_y(x):
if(x=='no'):
return0
else:
return1
data['y']=data['y'].apply(parse_y)
data['y']=data['y'].astype(int)
4.3 数据规范化
#数据规范化到正态分布的数据
#测试数据和训练数据的分割
fromsklearn.preprocessingimportStandardScaler
fromsklearn.model_selectionimporttrain_test_split
ss=StandardScaler()
train_x,test_x,train_y,test_y=train_test_split(data.iloc[:,:-1],
data['y'],
test_size=0.3)
train_x=ss.fit_transform(train_x)
test_x=ss.transform(test_x)
5. 模型训练
5.1 AdaBoost分类器
fromsklearn.ensembleimportAdaBoostClassifier
fromsklearn.metricsimportaccuracy_score
ada=AdaBoostClassifier()
ada.fit(train_x,train_y)
predict_y=ada.predict(test_x)
print("准确率:",accuracy_score(test_y,predict_y))
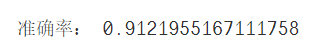
5.2 SVC分类器
fromsklearn.svmimportSVC
svc=SVC()
svc.fit(train_x,train_y)
predict_y=svc.predict(test_x)
print("准确率:",accuracy_score(test_y,predict_y))
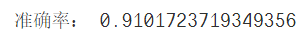
5.3 K邻近值分类器
fromsklearn.neighborsimportKNeighborsClassifier
knn=KNeighborsClassifier()
knn.fit(train_x,train_y)
predict_y=knn.predict(test_x)
print("准确率:",accuracy_score(test_y,predict_y))
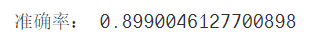
5.4 决策树分类器
fromsklearn.treeimportDecisionTreeClassifier
dtc=DecisionTreeClassifier()
dtc.fit(train_x,train_y)
predict_y=dtc.predict(test_x)
print("准确率:",accuracy_score(test_y,predict_y))
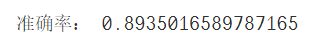
6 模型评价
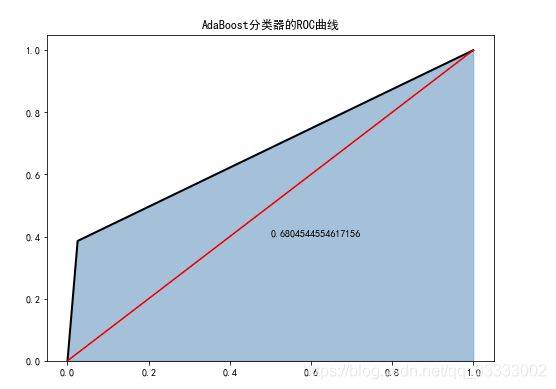
6.1 AdaBoost分类器
fromsklearn.metricsimportroc_curve
fromsklearn.metricsimportauc
plt.figure(figsize=(8,6))
fpr1,tpr1,threshoulds1=roc_curve(test_y,ada.predict(test_x))
plt.stackplot(fpr1,tpr1,color='steelblue',alpha=0.5,edgecolor='black')
plt.plot(fpr1,tpr1,linewidth=2,color='black')
plt.plot([0,1],[0,1],ls='-',color='red')
plt.text(0.5,0.4,auc(fpr1,tpr1))
plt.title('AdaBoost分类器的ROC曲线')
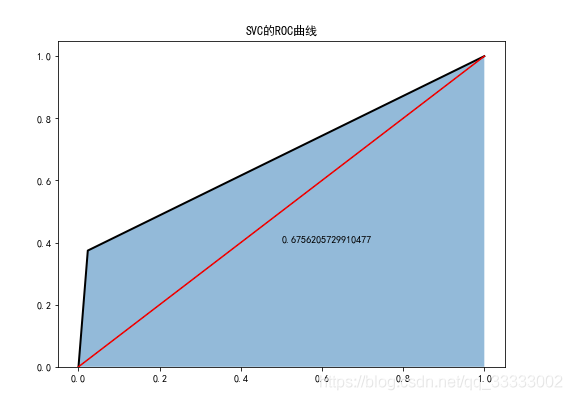
6.2 SVC分类器
plt.figure(figsize=(8,6))
fpr2,tpr2,threshoulds2=roc_curve(test_y,svc.predict(test_x))
plt.stackplot(fpr2,tpr2,alpha=0.5)
plt.plot(fpr2,tpr2,linewidth=2,color='black')
plt.plot([0,1],[0,1],ls='-',color='red')
plt.text(0.5,0.4,auc(fpr2,tpr2))
plt.title('SVD的ROC曲线')
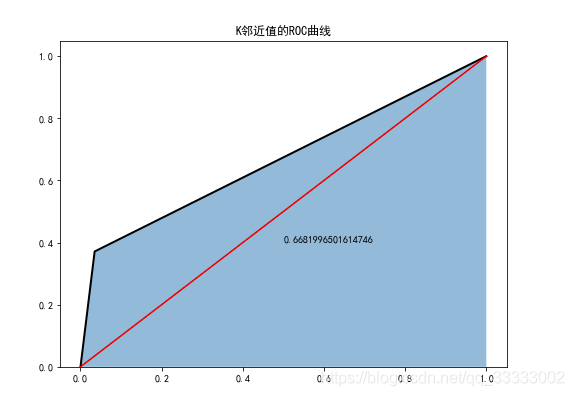
6.3 K邻近值分类器
plt.figure(figsize=(8,6))
fpr3,tpr3,threshoulds3=roc_curve(test_y,knn.predict(test_x))
plt.stackplot(fpr3,tpr3,alpha=0.5)
plt.plot(fpr3,tpr3,linewidth=2,color='black')
plt.plot([0,1],[0,1],ls='-',color='red')
plt.text(0.5,0.4,auc(fpr3,tpr3))
plt.title('K邻近值的ROC曲线')
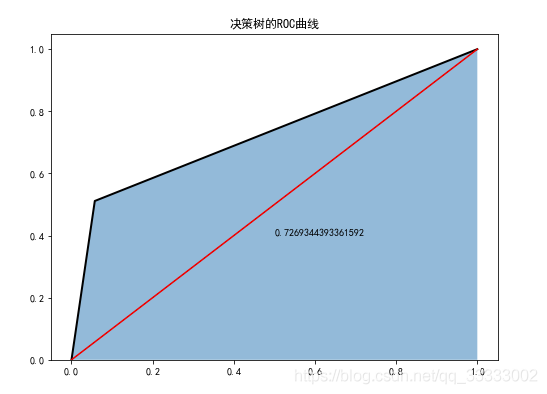
6.4 决策树分类器
plt.figure(figsize=(8,6))
fpr4,tpr4,threshoulds4=roc_curve(test_y,dtc.predict(test_x))
plt.stackplot(fpr4,tpr4,alpha=0.5)
plt.plot(fpr4,tpr4,linewidth=2,color='black')
plt.plot([0,1],[0,1],ls='-',color='red')
plt.text(0.5,0.4,auc(fpr4,tpr4))
plt.title('决策树的ROC曲线')
审核编辑 :李倩
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
算法
+关注
关注
23文章
4817浏览量
98863 -
数据分析
+关注
关注
2文章
1526浏览量
36432 -
python
+关注
关注
59文章
4892浏览量
90460
原文标题:用 Python 算法预测客户行为案例!
文章出处:【微信号:DBDevs,微信公众号:数据分析与开发】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
热点推荐
瑞芯微(EASY EAI)RV1126B AI算法开发流程
1.概述AI算法开发流程由以下流程组成:2.需求分析算法的功能常常可以用一个短词概括,如人脸识别、司机行为检测、商场顾客行为分析等系统,但是

端子电流循环寿命试验机核心算法解析:温升预测模型与寿命衰减曲线拟合
端子电流循环寿命试验机的核心算法,是实现端子寿命精准预测、测试过程智能管控的关键,其中温升预测模型与寿命衰减曲线拟合两大核心算法,分别解决了测试过程中的温度动态调控与寿命趋势研判问题,

[VirtualLab] 使用Python运行VirtualLab Fusion光学仿真
摘要
VirtualLab Fusion允许Python外部访问其建模技术、求解器和结果。这个用例介绍了一种使用路径变量和Visual Studio代码将Python连接到VirtualLab
发表于 03-31 09:39
[VirtualLab] 使用Python进行跨平台参数扫描
如何收集结果,这些结果可以通过Python提供的所有功能进一步处理。以光栅为例,严格分析了光栅的衍射效率。
**此用例展示了…
**
在哪里找文件
README文件
**准备Python
发表于 03-31 09:36
算法工程师需要具备哪些技能?
、链式法则等。应用场景:梯度下降优化算法、反向传播计算等。
优化理论核心内容:凸优化、非凸优化、拉格朗日乘数法等。应用场景:模型参数调优、资源分配问题等。
编程语言Python:主流选择,用于数据处理、模型
发表于 02-27 10:53
没有专利的opencv-python 版本
所有 官方发布的 opencv-python 核心版本(无 contrib 扩展)都无专利风险——专利问题仅存在于 opencv-contrib-python 扩展模块中的少数算法(如早期 SIFT
发表于 12-13 12:37
在Python中借助NVIDIA CUDA Tile简化GPU编程
兼容未来的 GPU 架构。借助 NVIDIA cuTile Python,开发者可以直接用 Python 编写 tile kernels。

labview如何实现数据的采集与实时预测
现有以下问题:labview可以实现数据的采集以及调用python代码,但如何将这两项功能集成在一个VI文件里,从而实现数据的采集与实时预测。现有条件如下:已完成数据的采集系统,python中的
发表于 12-03 21:13
Python调用API教程
两个不同系统之间的信息交互。在这篇文章中,我们将详细介绍Python调用API的方法和技巧。 一、用Requests库发送HTTP请求 使用Python调用API的第一步是发送HTTP请求,通常
蜂鸟E203简单分支预测的改进
1.蜂鸟E203的原有分支预测
蜂鸟E203处理器为了能够连续不断的取指令,需要在每个时钟周期都能生成一条待取的指令。因此,在取指令的阶段,IFU单元模块进行了简单的译码处理,用以判别
发表于 10-24 07:45
基于全局预测历史的gshare分支预测器的实现细节
GShare预测机制简介
GShare预测机制作为一种常用的分支预测机制,通过基于分支历史和分支地址来预测分支指令的执行路径。分支历史是指处理器在执行程序时遇到的所有分支指令的执行情
发表于 10-22 06:50
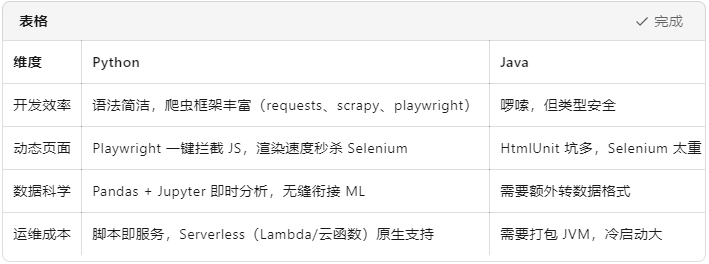
用 Python 给 Amazon 做“全身 CT”——可量产、可扩展的商品详情爬虫实战
一、技术选型:为什么选 Python 而不是 Java? 结论: “调研阶段用 Python,上线后如果 QPS 爆表再考虑 Java 重构。” 二、整体架构速览(3 分钟看懂) 三、开发前准备(5
电商API的五大应用场景:解锁增长新机遇
。
#### 4. 智能推荐系统:驱动销售转化和交叉销售
推荐API利用AI算法(如协同过滤)分析用户行为,推荐相关产品。协同过滤公式为:
预测评分_{u,i} = \\\\sum_{j \\\\in N
发表于 06-24 14:29
如何用AI实现电池寿命的精准预测?飞凌RK3588+融合算法给你答案
飞凌嵌入式将AI算法(CNN+LSTM融合)和RK3588核心板相结合,成功突破这些限制,带来高效、精准的锂电池寿命预测。




评论