 一个具有泛化性的小样本语义分割(GFS-Seg)
一个具有泛化性的小样本语义分割(GFS-Seg)

1 前言
之前已经有过关于小样本语义分割的论文解读,关于如何用 Transformer 思想的分类器进行小样本分割。本篇是发表在 CVPR 2022 上的 Generalized Few-shot Semantic Segmentation(后文简称 GFS-Seg),既一种泛化的小样本语义分割模型。在看论文的具体内容之前,我们先了解一些前置知识。
深度学习是 Data hunger 的方法, 需要大量的数据,标注或者未标注。少样本学习研究就是如何从少量样本中去学习。拿分类问题来说,每个类只有一张或者几张样本。少样本学习可以分为 Zero-shot Learning(即要识别训练集中没有出现过的类别样本)和 One-Shot Learning/Few shot Learning(即在训练集中,每一类都有一张或者几张样本)。以 Zero-shot Learning 来说,比如有一个中文 “放弃”,要你从 I, your、 she、them 和 abnegation 五个单词中选择出来对应的英文单词,尽管你不知道“放弃”的英文是什么,但是你会将“放弃”跟每个单词对比,而且在你之前的学习中,你已经知道了 I、 your、she 和 them 的中文意思,都不是“放弃”,所以你会选择 abnegation。还需要明确几个概念:
Support set:支撑集,每次训练的样本集合。
Query set:查询集,用于与训练样本比对的样本,一般来说 Query set 就是一个样本。
在 Support set 中,如果有 n 个种类,每个种类有 k 个样本,那么这个训练过程叫 n-way k-shot。如每个类别是有 5 个 examples 可供训练,因为训练中还要分 Support set 和 Query set,5-shots 场景至少需要 5+1 个样例,至少一个 Query example 去和 Support set 的样例做距离(分类)判断。
2 概述
训练语义分割模型需要大量精细注释的数据,这使得它很难快速适应不满足这一条件的新类,FS-Seg 在处理这个问题时有很多限制条件。在这篇文章中引入了一个新的方法,称为 GFS-Seg,能同时分割具有极少样本的新类别和具有足够样本的基础类别的能力。建立了一个 GFS-Seg baseline,在不对原模型进行结构性改变的情况下能取得不错的性能。此外,由于上下文信息对语义分割至关重要,文中提出了上下文感知原型学习架构(CAPL),利用 Support Set 样本共同的先验知识,根据每个 Query Set 图像的内容动态地丰富分类器的上下文信息,显著提高性能。
3 GFS-Seg 和 FS-Seg 的 Pipeline 区别
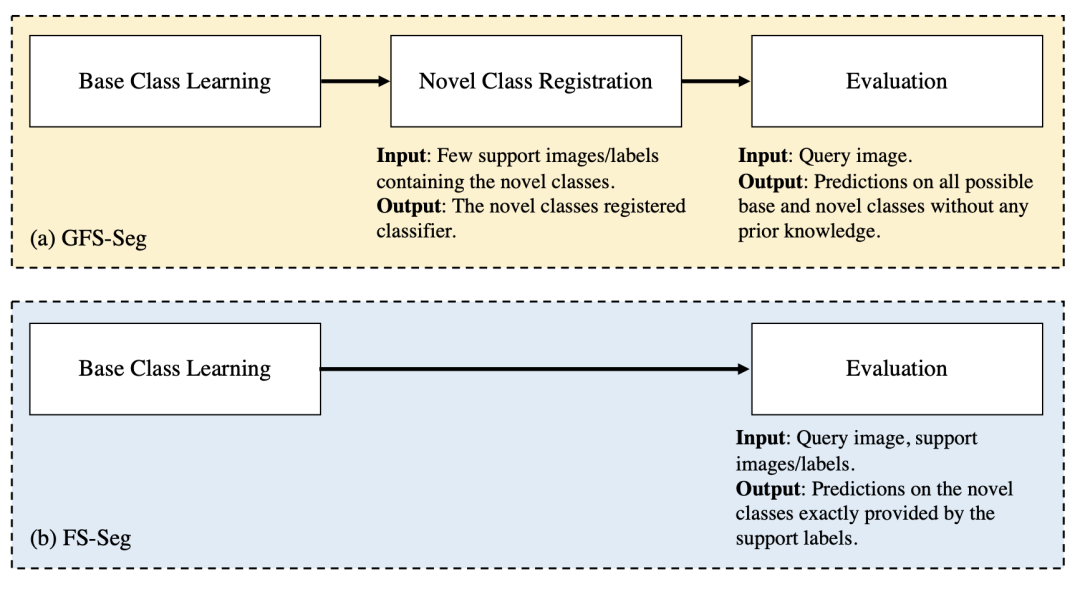
如下图所示,GFS-Seg 有三个阶段。分别是:基类的学习阶段;新类的注册阶段,其中包含新类的少数 Support set 样本;对基类和新类的评估阶段。也就是说,GFS-Seg 与 FS-Seg 的区别在于,在评估阶段,GFS-Seg 不需要转发测试(Query set)样本中包含相同目标类的 Support set 样本来进行预测,因为 GFS-Seg 在基类学习阶段和新类注册阶段应该已经分别获得了基类和新类的信息。GFS-Seg 在事先不知道查询图像中包含哪些类别的情况下,同时对新类进行预测时,可以在不牺牲基类准确性的情况下仍表现良好。
4 Towards GFS-Seg
在经典的 Few-Shot Segmentation 任务中,有两个关键标准:(1) 模型在训练期间没有看到测试类的样本。(2) 模型要求其 Support set 样本包含 Query set 中存在的目标类,以做出相应的预测。
通过下图,我们来看下 GFS-Seg 与经典人物有哪些不同。下图中用相同的 Query 图像说明了 FS-Seg 和 GFS-Seg 的一个 2-way K-shot 任务,其中牛和摩托车是新的类,人和车是基类。先来看下 (a),Prototype Network 通过 Embedding Generation 函数,将牛和摩托车的少量训练样本映射为 2 个向量,在检测分类时候,将待分割图像的特征也通过 Embedding Generation 映射为向量,最后计算待检测向量与 2 个向量的特征差异(假设是距离),认定距离最小的为预测类别。(a) 只限于预测 Support set 中包含的类的二进制分割掩码。右边的人和上面的车在预测中缺失,因为支持集没有提供这些类的信息,即使模型已经在这些基类上训练了足够的 epoch。此外,如果 (a) 的支持集提供了查询图像中没有的多余的新类(如飞机),这些类别可能会影响模型性能,因为 FS-Seg 有一个前提条件,即 Query 图像必须是 Support set 样本提供的类。
FS-Seg 模型只学习并预测给定的新类的前景掩码,所以在我们提出的 GFS-Seg 的通用化设置中,性能会大大降低,因为所有可能的基类和新类都需要预测。不同的是,(b) 也就是 GFS-Seg,在没有 Query 图像中包含的类的先验知识的情况下,同时识别基类和新类,额外的 Support set(如 (b) 左上角的飞机)应该不会对模型产生很大影响。在评估过程中,GFS-Seg 不需要事先了解 Query 图像中存在哪些目标类别,而是通过注册新的类别,对所有测试图像一次性形成一个新的分类器((b) 中的蓝色区域代表新的类别注册阶段)。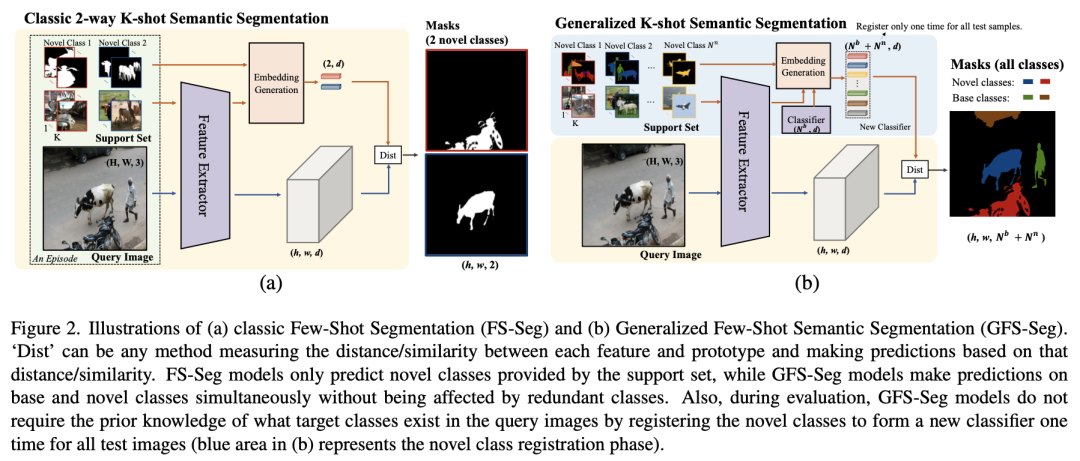
此外,还有更多关于 GFS-Seg 的 baseline 细节,这里就不详细展开了,读者们可以一遍看代码一边看论文中的解释,不难理解。
5 上下文感知原型学习(CAPL)
原型学习(PL)适用于小样本分类和 FS-Seg,但它对 GFS-Seg 的效果较差。在 FS-Seg 的设置中,查询样本的标签只来自于新的类别。因此,新类和基类之间没有必要的联系,可以利用它来进一步改进。然而,在 GFS-Seg 中,对每个测试图像中包含的类别没有这样的限制,需要对所有可能的基类和新颖类进行预测。
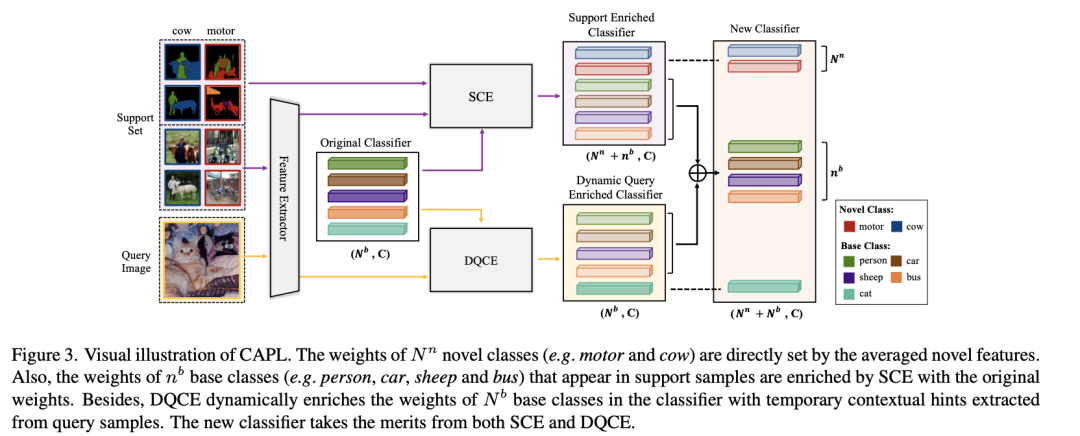
如上图所示,我们不关注 SCE 和 DQCE 的计算过程。SCE 只发生在新的类注册阶段,它利用支持 Support set 样本来提供先验知识。然而,在评估阶段,新分类器由所有 Query 图像共享,因此引入的先验可能会偏向于有限的 Support set 样本的内容,导致对不同 Query 图像的泛化能力较差。为了缓解这个问题,进一步提出了动态查询上下文丰富计算(DQCE),它通过动态合并从单个查询样本中挖掘的基本语义信息,使新分类器适应不同的上下文。继续看上图,N‘n 个新类别(例如摩托车和奶牛)的权重直接由特征平均得出。此外,Support set 中出现的 N’b 个基类(例如人、汽车、羊和公共汽车)的权重由 SCE 用原始权重计算得出。此外,DQCE 通过从 Query set 样本中提取的临时上下文特征,动态丰富了分类器中 N'b 个基类的权重。综上,新的分类器结合了 SCE 和 DQCE 的优点。
GFS-Seg 使用 CAPL 的方式完成训练,具体性能表现在下面的实验部分列出。
6 实验
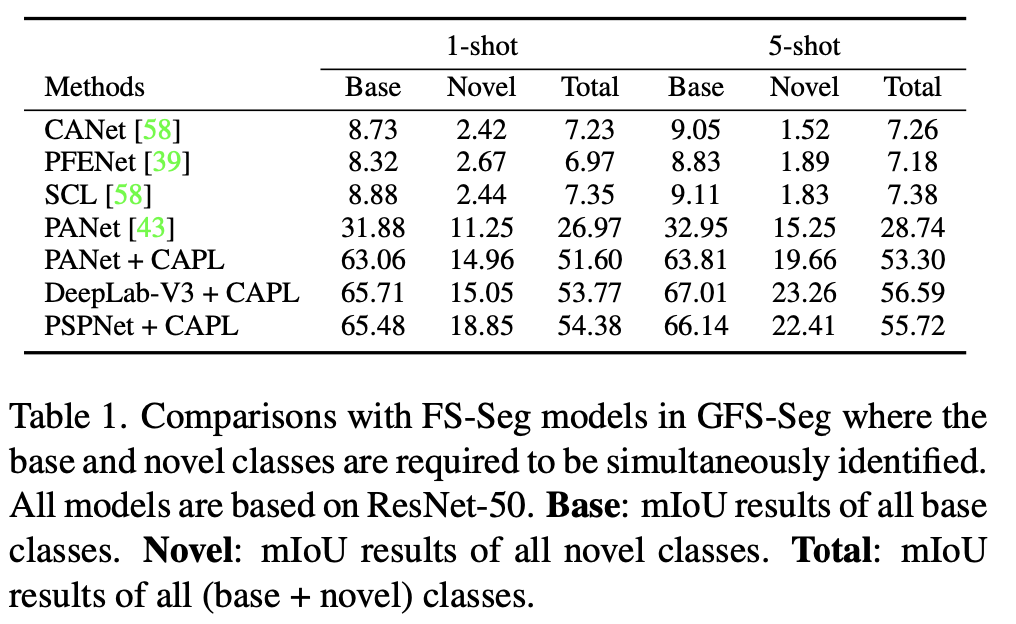
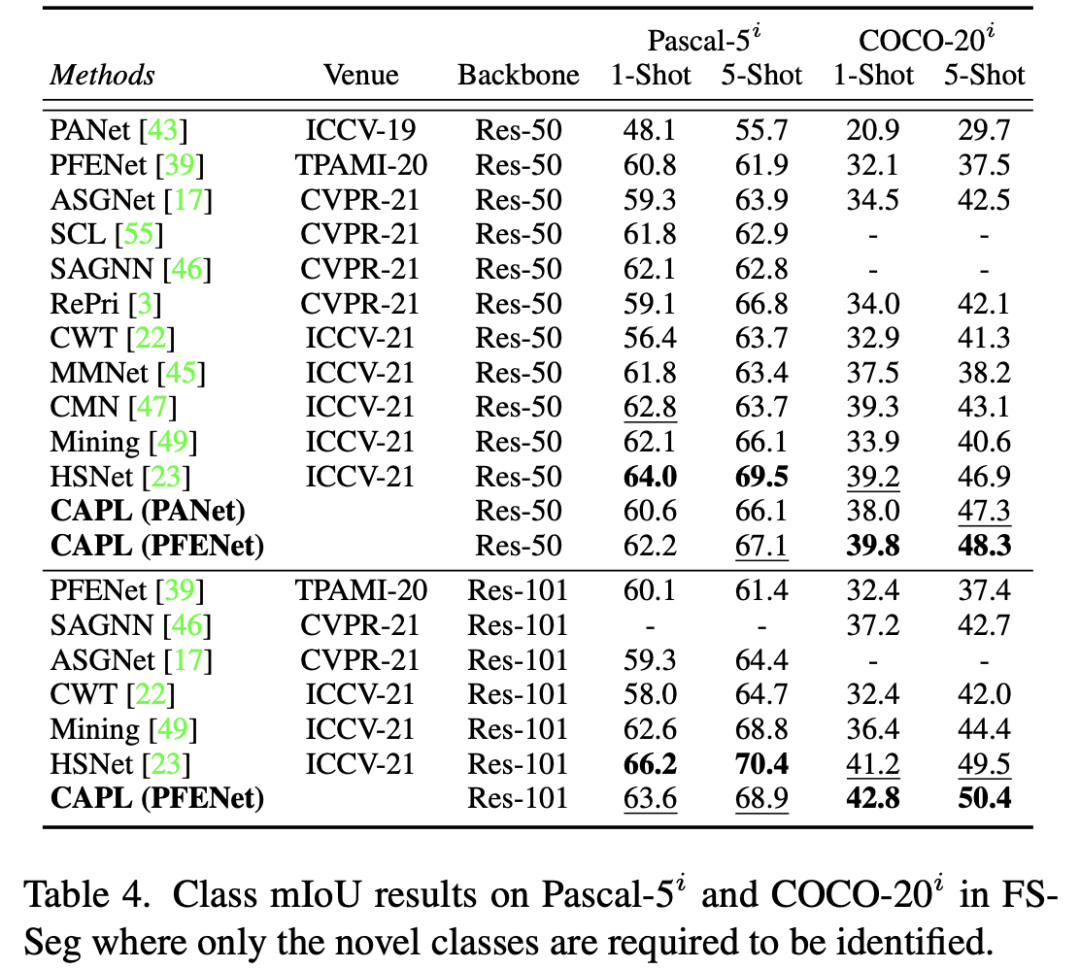
如下表所示,CANet、SCL、PFENet 和 PANet 与用 CAPL 实现的模型相比表现不佳。值得注意的是,下表中的 mIoU 的结果是在 GFS-Seg 配置下的,因此它们低于这些 FS-Seg 模型的论文中给出的结果,这种差异是由不同的全局设置造成的。在 GFS-Seg 中,模型需要在给定的测试图像中识别所有的类,包括基类和新类,而在 FS-Seg 中,模型只需要找到属于一个特殊的新类的像素,不会去分割基类,Support set 的样本提供了目标类是什么的先验知识。因此,在 GFS-Seg 中,存在基类干扰的情况下,识别新类要难得多,所以数值很低。
FS-Seg 是 GFS-Seg 的一个极端情况。所以为了在 FS-Seg 的中验证提出的 CAPL,在下表中,我们将 CAPL 合并到 PANet 和 PFENet。可以看出, CAPL 对 baseline 实现了显着的改进。数据集是 Pascal-5i 和 COCO-20i ,只需要识别新类。
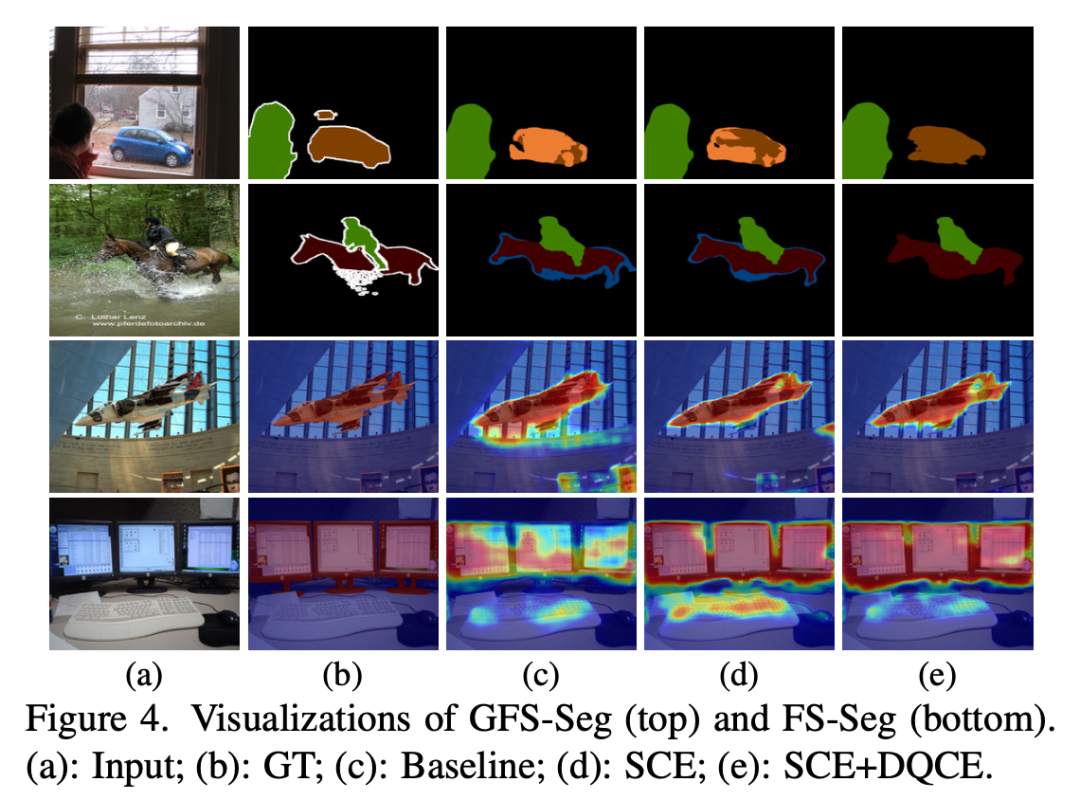
下图对分割结果进行了可视化,其中 SCE 和 DQCE 的组合进一步完善了 baseline 的预测,还有一些消融实验的效果这里不一一列出了。
7 结论
这篇阅读笔记仅为个人理解,文章提出了一个具有泛化性的小样本语义分割(GFS-Seg),并提出了一个新的解决方案:上下文感知原型学习(CAPL)。与经典的 FS-Seg 不同,GFS-Seg 旨在识别 FS-Seg 模型所不能识别的基础类和新类。提出的 CAPL 通过动态地丰富上下文信息的适应性特征,实现了性能的显著提高。CAPL 对基础模型没有结构上的限制,因此它可以很容易地应用于普通的语义分离框架,并且它可以很好地推广到 FS-Seg。
审核编辑:刘清
原文标题:CVPR 2022:Generalized Few-shot Semantic Segmentation 解读
文章出处:【微信号:GiantPandaCV,微信公众号:GiantPandaCV】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
【幸狐Omni3576边缘计算套件试用体验】YOLO26 板端部署
SAM(通用图像分割基础模型)丨基于BM1684X模型部署指南
VK1616 点阵数显LED驱动IC可支持7SEG×4GRID的点阵LED显示面板

【NPU实战】在迅为RK3588上玩转YOLOv8:目标检测与语义分割一站式部署指南

手机板 layout 走线跨分割问题
模板驱动 无需训练数据 SmartDP解决小样本AI算法模型开发难题

基于黄金分割搜索法的IPMSM最大转矩电流比控制
RK3576 yolo11-seg训练部署教程

北京迅为itop-3588开发板NPU例程测试deeplabv3 语义分割

EL非监督分割白皮书丨5张OK图、1分钟建模、半小时落地的异常检测工具!

如何将32个步进伺服驱动器塞进小型板材分割机中?

51Sim利用NVIDIA Cosmos提升辅助驾驶合成数据场景的泛化性
【正点原子STM32MP257开发板试用】基于 DeepLab 模型的图像分割
嵌入式AI技术漫谈:怎么为训练AI模型采集样本数据
选态信号的 COM 线和 SEG 线,通过光通过率变化,实现液晶线路检测和修复




评论