 FPGA如何实现FP16格式点积级联运算
FPGA如何实现FP16格式点积级联运算

通过使用Achronix Speedster7t FPGA中的机器学习加速器MLP72,开发人员可以轻松选择浮点/定点格式和多种位宽,或快速应用块浮点,并通过内部级联可以达到理想性能。
神经网络架构中的核心之一就是卷积层,卷积的最基本操作就是点积。向量乘法的结果是向量的每个元素的总和相乘在一起,通常称之为点积。此向量乘法如下所示:
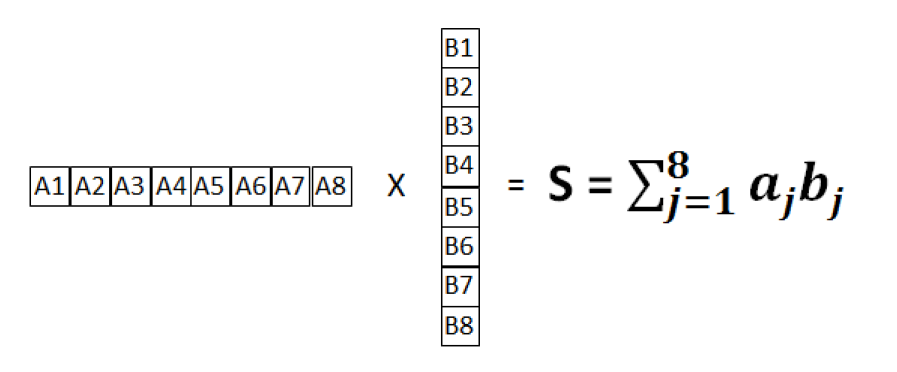
图1点积操作
该总和S由每个矢量元素的总和相乘而成,因此
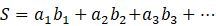 本文讲述的是使用FP16格式的点积运算实例,展示了MLP72支持的数字类型和乘数的范围。
此设计实现了同时处理8对FP16输入的点积。该设计包含四个MLP72,使用MLP内部的级联路径连接。每个MLP72将两个并行乘法的结果相加
本文讲述的是使用FP16格式的点积运算实例,展示了MLP72支持的数字类型和乘数的范围。
此设计实现了同时处理8对FP16输入的点积。该设计包含四个MLP72,使用MLP内部的级联路径连接。每个MLP72将两个并行乘法的结果相加 ,每个乘法都是i_a输入乘以i_b输入(均为FP16格式)的结果。来自每个MLP72的总和沿着MLP72的列级联到上面的下一个MLP72块。在最后一个MLP72中,在每个周期上,计算八个并行FP16乘法的总和。
最终结果是多个输入周期内的累加总和,其中累加由i_first和i_last输入控制。i_first输入信号指示累加和归零的第一组输入。i_last信号指示要累加和加到累加的最后一组输入。最终的i_last值可在之后的六个周期使用,并使用i_last o_valid进行限定。两次运算之间可以无空拍。
,每个乘法都是i_a输入乘以i_b输入(均为FP16格式)的结果。来自每个MLP72的总和沿着MLP72的列级联到上面的下一个MLP72块。在最后一个MLP72中,在每个周期上,计算八个并行FP16乘法的总和。
最终结果是多个输入周期内的累加总和,其中累加由i_first和i_last输入控制。i_first输入信号指示累加和归零的第一组输入。i_last信号指示要累加和加到累加的最后一组输入。最终的i_last值可在之后的六个周期使用,并使用i_last o_valid进行限定。两次运算之间可以无空拍。
- 配置说明

表1 FP16点积配置表
- 端口说明

表2 FP16点积端口说明表
- 时序图
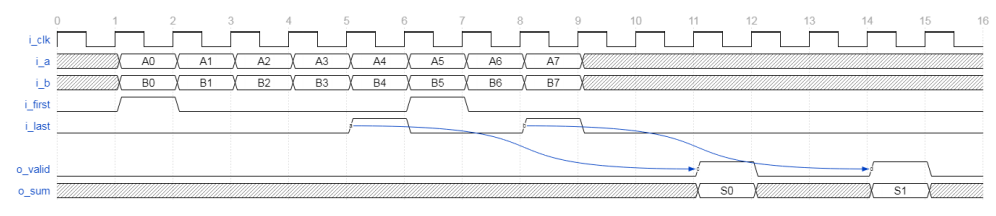
图2 FP16点积时序图
其中,
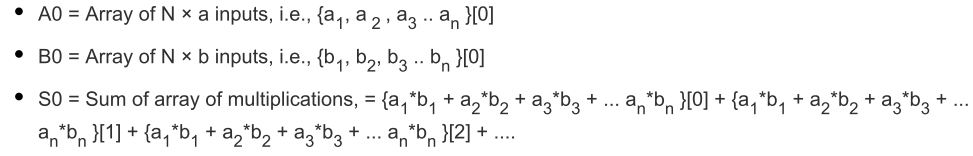 那么,以上运算功能如何对应到MLP内部呢?其后的细节已分为MLP72中的多个功能阶段进行说明。
那么,以上运算功能如何对应到MLP内部呢?其后的细节已分为MLP72中的多个功能阶段进行说明。
- 进位链
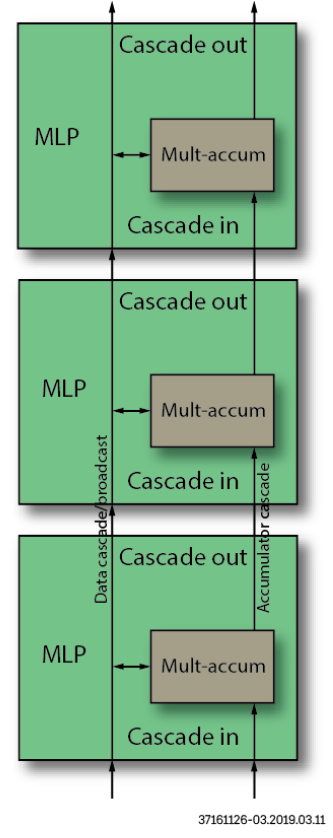
图3 MLP进位链
- 乘法阶段
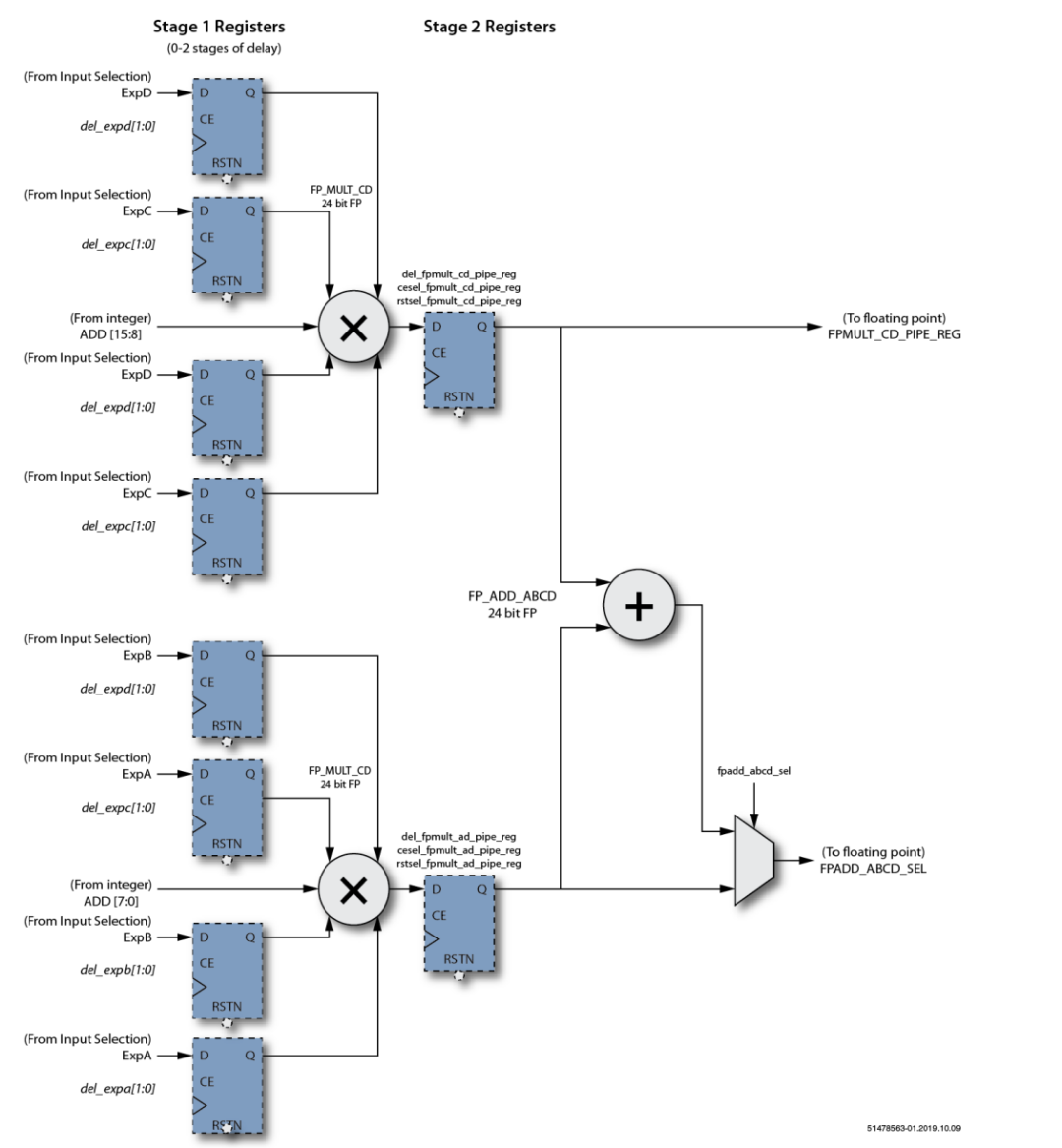
图4 MLP乘法功能阶段框图
MLP72浮点乘法级包括两个24位全浮点乘法器和一个24位全浮点加法器。两个乘法器执行A×B和C×D的并行计算。加法器将两个结果相加得到A×B + C×D。 乘法阶段有两个输出。下半部分输出可以在A×B或(A×B + C×D)之间选择。上半部分输出始终为C×D。 乘法器和加法器使用的数字格式由字节选择参数以及和参数设置的格式确定。 浮点输出具有与整数输出级相同的路径和结构。MLP72可以配置为在特定阶段选择整数或等效浮点输入。输出支持两个24位全浮点加法器,可以对其进行加法或累加配置。进一步可以加载加法器(开始累加),可以将其设置为减法,并支持可选的舍入模式。 最终输出阶段支持将浮点输出格式化为MLP72支持的三种浮点格式中的任何一种。此功能使MLP72可以外部支持大小一致的浮点输入和输出(例如fp16或bfloat16),而在内部以fp24执行所有计算。
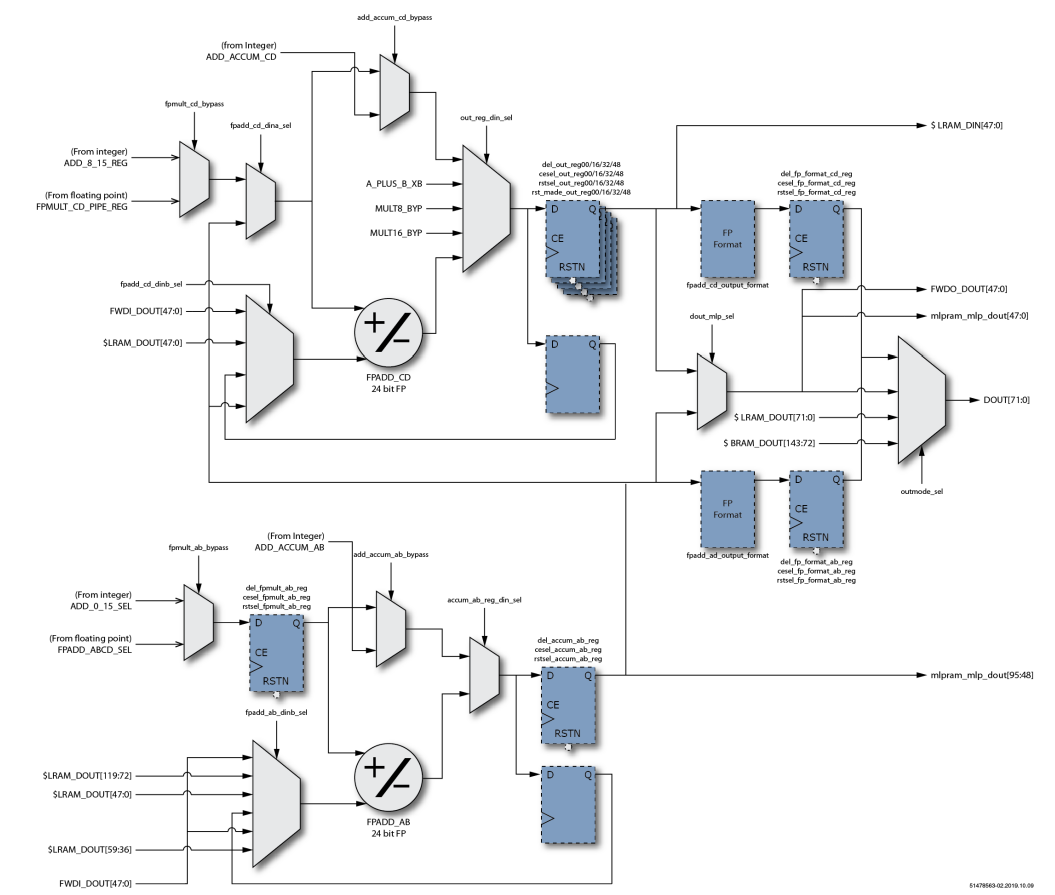
图5 MLP浮点输出阶段框图
需要强调的是本设计输入和输出都是FP16格式,中间计算过程,即进位链上的fwdo_out和fwdi_dout 都是FP24格式。具体逻辑框图如下所示:
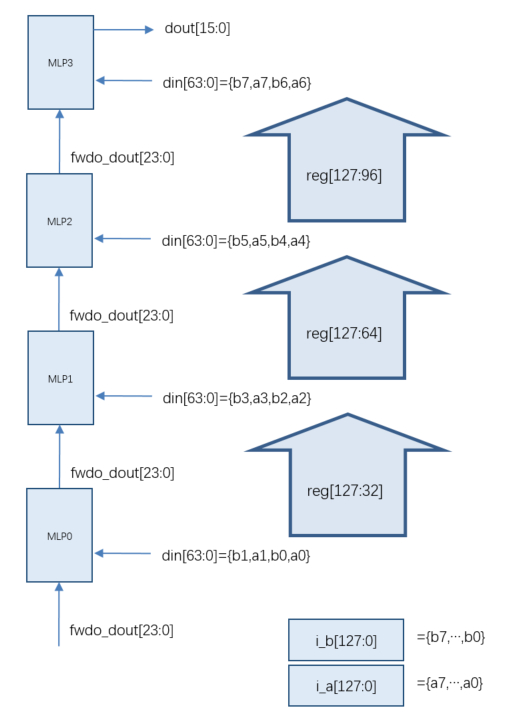
图6 FP16点积逻辑框图
MLP内部数据流示意图:
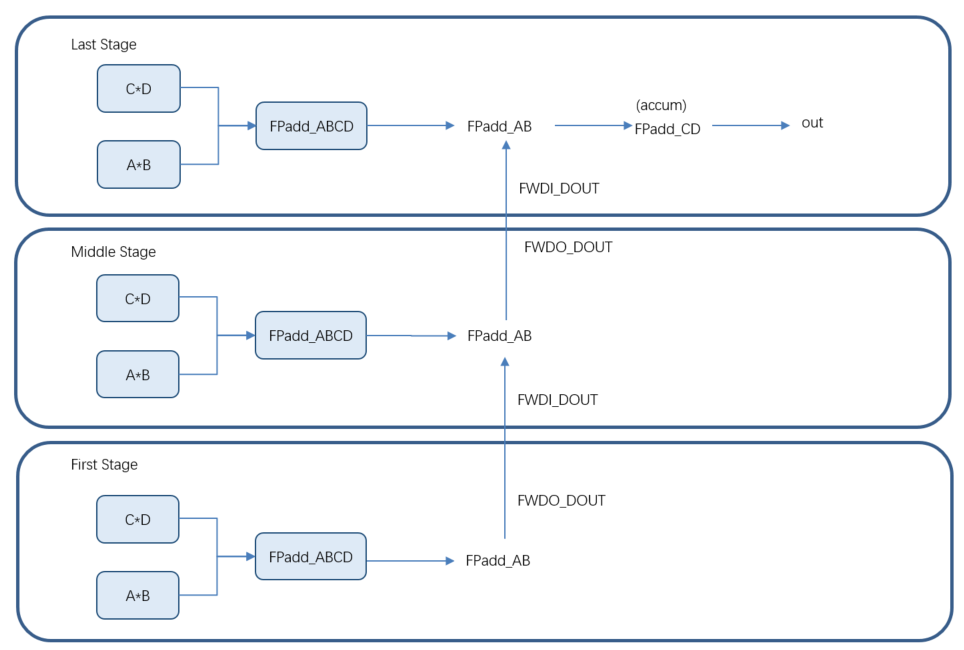
图7 FP16点积在MLP内部数据流图
最终ACE的时序结果如下:
审核编辑 :李倩
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
FPGA
+关注
关注
1664文章
22502浏览量
639139 -
机器学习
+关注
关注
67文章
8562浏览量
137211 -
MLP
+关注
关注
0文章
57浏览量
5030
原文标题:详解FPGA如何实现FP16格式点积级联运算
文章出处:【微信号:zhuyandz,微信公众号:FPGA之家】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
热点推荐
低精度浮点数定义——什么是 FP8、FP6、FP4?
什么是浮点精度?浮点精度是一种以二进制格式表示数字的方法,计算机将数字解读为由0和1组成的二进制序列。本文将聚焦于更小众的低精度格式——FP8、FP6和

如何用 STM32 + FP7208 + FP6195 打造一款真正的音乐律动氛围灯?
基于FP6195降压与FP7208升压恒流的氛围灯控设计
当前市面上的 KTV 氛围灯控方案普遍存在一个痛点:所谓的“音乐律动”大多只是简单跟随音量大小做机械式闪烁,无法识别音乐的
发表于 04-22 10:10
如何用 STM32 + FP7208 + FP6195 打造一款真正的音乐律动氛围灯?
基于FP6195降压与FP7208升压恒流的氛围灯控设计
当前市面上的KTV 氛围灯控方案普遍存在一个痛点:所谓的“音乐律动”大多只是简单跟随音量大小做机械式闪烁,无法识别音乐的节奏
发表于 04-08 14:04
AWQ/GPTQ量化模型加载与显存优化实战
大语言模型(LLM)推理显存需求呈指数级增长,70B参数的模型需要约140GB显存(FP16),远超单卡GPU容量。量化技术通过降低模型参数精度(从FP16到INT4),在精度损失最小的情况下减少50-75%显存占用,使得大模型在消费级GPU上运行成为可能。
大模型推理服务的弹性部署与GPU调度方案
7B 模型 FP16 推理需要约 14GB 显存,70B 模型需要 140GB+,KV Cache 随并发数线性增长,显存碎片化导致实际利用率不足 60%。
今日看点:消息称 AMD、高通考虑导入 SOCAMM 内存;曦望发布新一代推理GPU芯片启望S3
推理深度定制的GPGPU芯片。其单芯片推理性能提升5倍,支持从FP16到FP8、FP6、FP4等多精度灵活切换,释放低精度推理效率,这种设计更贴合当前MoE和长上下文模型在推理阶段的需
发表于 01-28 11:09
•1325次阅读
三电阻可调增益设计:FP130A与FP355的灵活配置实现
在30V以下的低压应用中,精准的电流监控对实现系统保护至关重要。FP130A与FP355是两款专为此设计的高端电流检测芯片。FP130A可精确监测电流大小与方向,协助MCU智能判断设备

利用C语言union特性来定义RGB565格式
本次分享的内容是利用C语言union特性来定义RGB565格式
1)前言
在做视觉相关的任务时,相机的输入一般会是RGB565(uint16_t)的格式,而我们需要把它显式转换成RGB
发表于 10-30 08:26
基于级联分类器的人脸检测基本原理
。这里需要指出的一点是,可能会存在多个检测结果为阳性的窗口,鉴于此类情况,我们会在最后进行一次聚类,把多个阳性窗口合并成为一个。
该算法还具有支持多尺度和任意旋转角度的扩展版本。关于多尺度,算法的实现细节
发表于 10-30 06:14
小白必读:到底什么是FP32、FP16、INT8?
网上关于算力的文章,如果提到某个芯片或某个智算中心的算力,都会写:在FP32精度下,英伟达H100的算力大约为0.9PFlops。在FP16精度下,某智算中心的算力是6.7EFlops。在INT8

西井科技推出Hymala多式联运物流枢纽大模型矩阵
近日,2025WAIC,上海市工商联"人工智能+数字化"转型解决方案和创新产品成果活动上,人工智能智慧物流解决方案商——西井科技重磅推出Hymala多式联运物流枢纽大模型矩阵,直
计算精度对比:FP64、FP32、FP16、TF32、BF16、int8
本文转自:河北人工智能计算中心在当今快速发展的人工智能领域,算力成为决定模型训练与推理速度的关键因素之一。为了提高计算效率,不同精度的数据类型应运而生,包括FP64、FP32、FP16、TF32
将Whisper大型v3 fp32模型转换为较低精度后,推理时间增加,怎么解决?
将 openai/whisper-large-v3 FP32 模型转换为 FP16、INT8 和 INT4。
推理所花费的时间比在 FP32 上花费的时间要多
发表于 06-24 06:23
SiC MOSFET并联运行实现静态均流的基本要求和注意事项
通过并联SiC MOSFET功率器件,可以获得更高输出电流,满足更大功率系统的要求。本章节主要介绍了SiC MOSFET并联运行实现静态均流的基本要求和注意事项。

RGB888格式的image怎么保存jpg格式?
01的K230板子 1.2.2固件
我用RGB565可以顺利保存jpg,但是RGB888就不行,提示如下
提问:RGB888格式的image怎么保存jpg格式
想保存888是因为感觉图像质量更好,后面用这些保存的图片来训练模型
试试这个
发表于 04-25 08:18



评论