 小白必读:到底什么是FP32、FP16、INT8?
小白必读:到底什么是FP32、FP16、INT8?

网上关于算力的文章,如果提到某个芯片或某个智算中心的算力,都会写:在FP32精度下,英伟达H100的算力大约为 0.9 PFlops。在FP16精度下,某智算中心的算力是 6.7 EFlops。在INT8精度下,骁龙8Gen1的算力是 9 TOPS。……那么,评估算力的大小,为什么要加上FP32、FP16、INT8这样的前提?它们到底是什么意思?其实,FP32、FP16、INT8,都是数字在计算机中存储的格式类型,是计算机内部表示数字的方式。大家都知道,数字在计算机里是以二进制(0和1)的形式进行存储和处理。但是,数字有大有小、有零有整,如果只是简单地进行二进制的换算,就会很乱,影响处理效率。 所以,我们需要一个统一的“格式”,去表达这些数字。
所以,我们需要一个统一的“格式”,去表达这些数字。
- FP32、FP16
我们先来说说最常见的FP32和FP16。FP32和FP16,都是最原始的、由IEEE定义的标准浮点数类型(Floating Point)。
浮点数,是表示小数的一种方法。所谓浮点,就是小数点的位置不固定。与浮点数相对应的,是定点数,即小数点的位置固定。
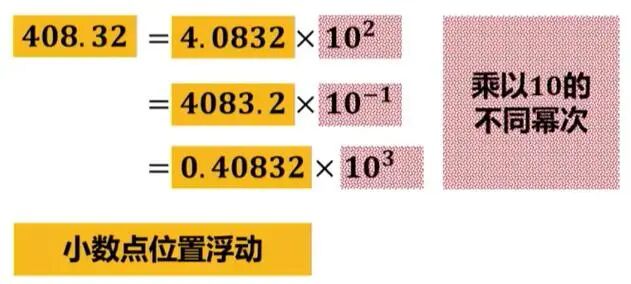
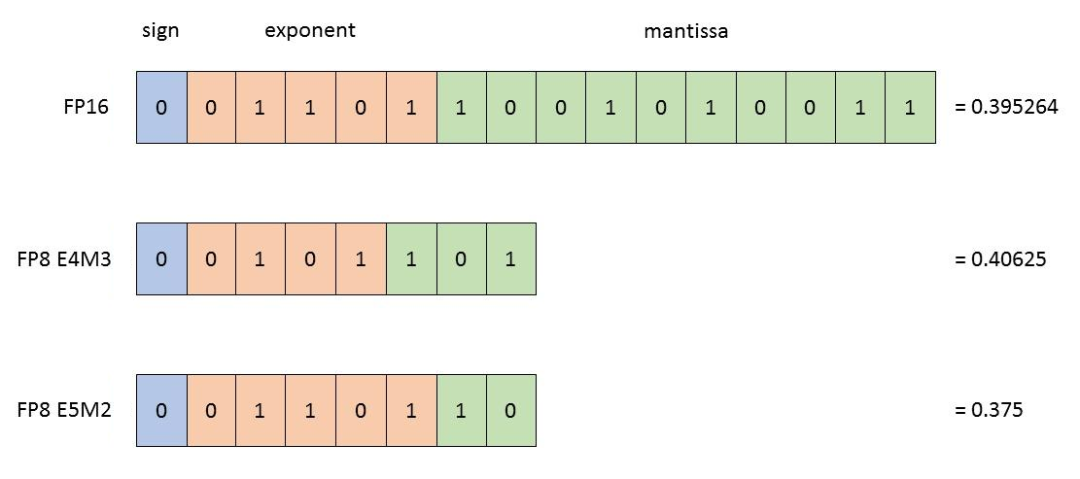
浮点数先看看FP32。FP32是一种标准的32位浮点数,它由三部分组成:
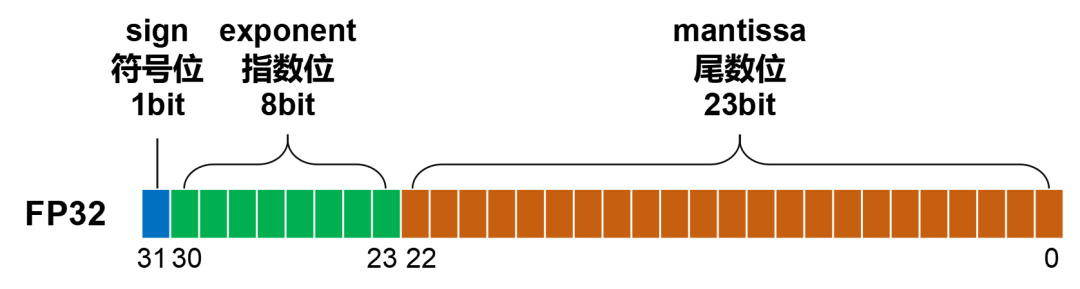
符号位(Sign):表示数字的正负,0表示正数,1 表示负数。
指数位(Exponent):用于表示数字的大小范围(也叫动态范围,dynamic range),可以表示从非常小到非常大的数。
尾数位(Mantissa):也叫小数位(fraction),用于表示数字的精度(precision,相邻两个数值之间的间隔)。
这三个部分的位数,分别是:1、8、23。加起来,刚好是32位。
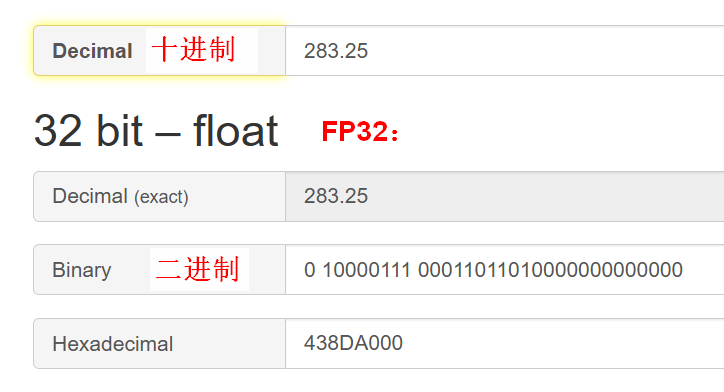
十进制和FP32之间的转换有一个公式,过程有点复杂。需要具体了解的,可以看下面的灰字和图。数学不好的童鞋,直接跳过吧:
转换公式:

转换过程示例:

下面这个网址,可以直接帮你换算:
https://baseconvert.com/ieee-754-floating-point
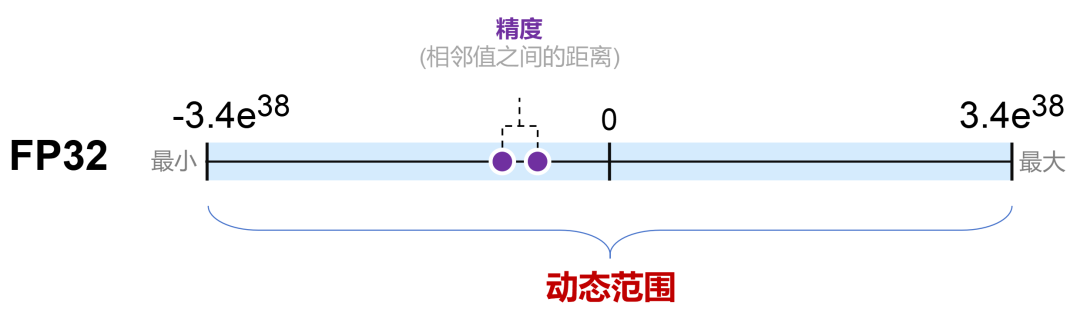
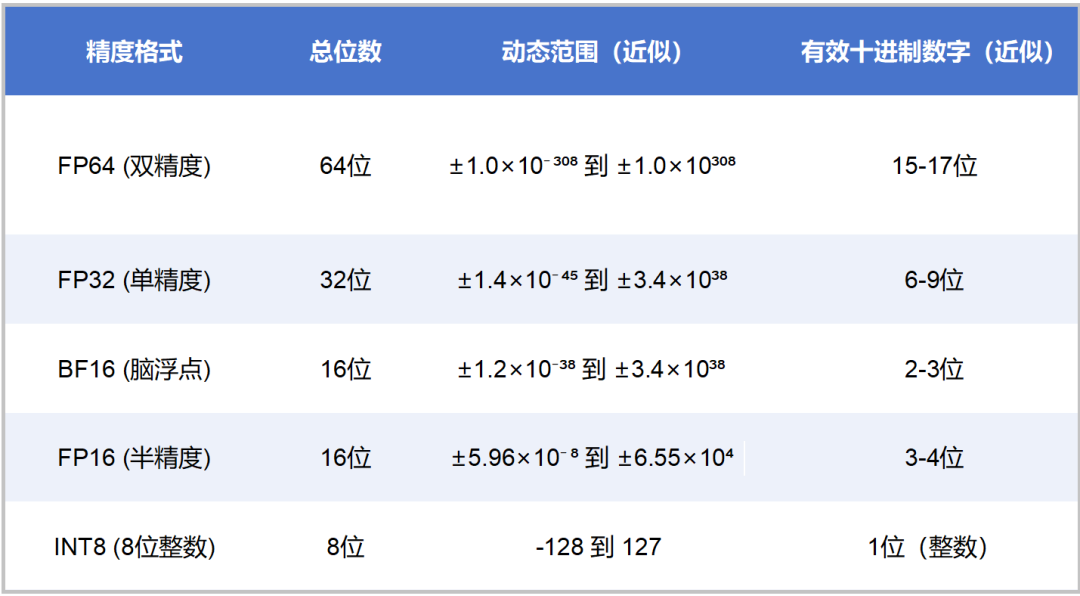
FP32的表示范围非常广泛,大约是±3.4×10³⁸,精度可以达到小数点后7位左右。
再看看FP16。
FP16的位数是FP32的一半,只有16位。三部分的位数,分别是符号位(1位)、指数位(5位)、尾数位(10位)。
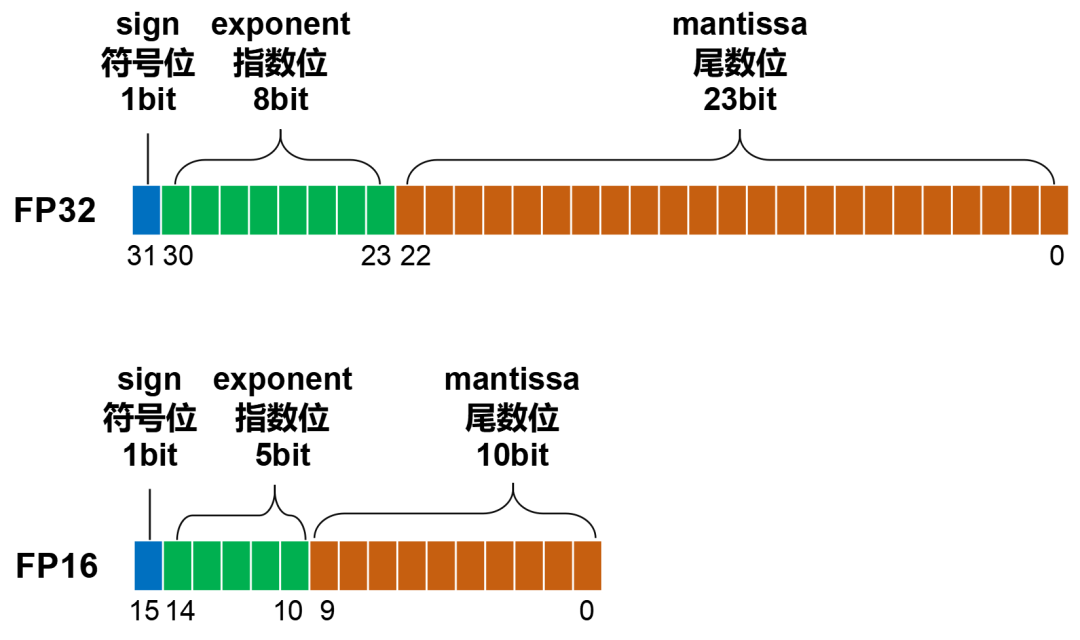 FP16的表示范围是±65504(±6.55×10⁴),精度只能达到小数点后3位左右。也就是说,1.001和1.0011在FP16下的表示是相同的。
FP16的表示范围是±65504(±6.55×10⁴),精度只能达到小数点后3位左右。也就是说,1.001和1.0011在FP16下的表示是相同的。
FP16的十进制换算过程如下: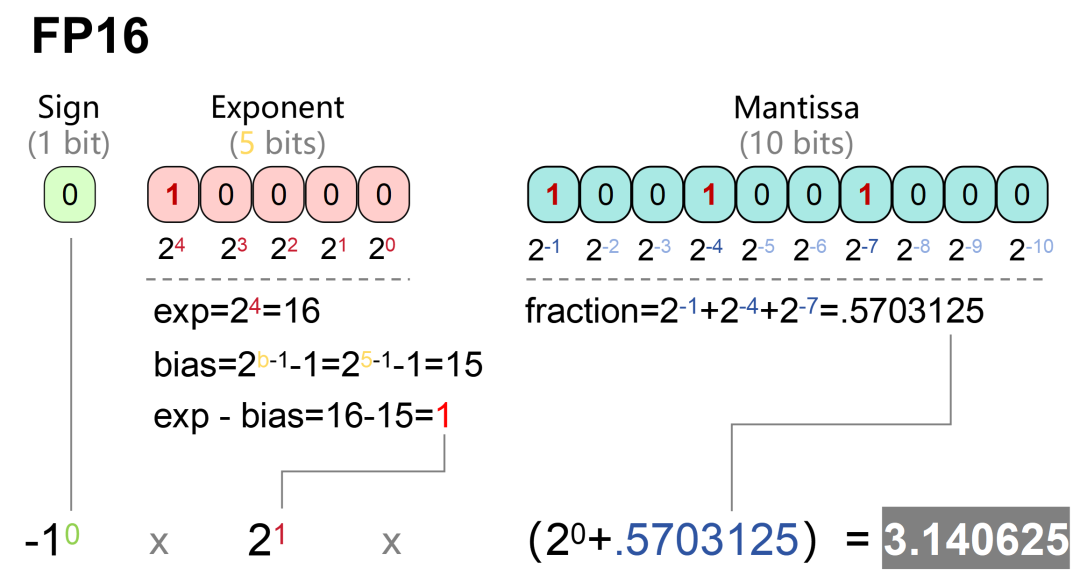 很显然,FP32的位数更长,表达的范围更大,精度也更高。
很显然,FP32的位数更长,表达的范围更大,精度也更高。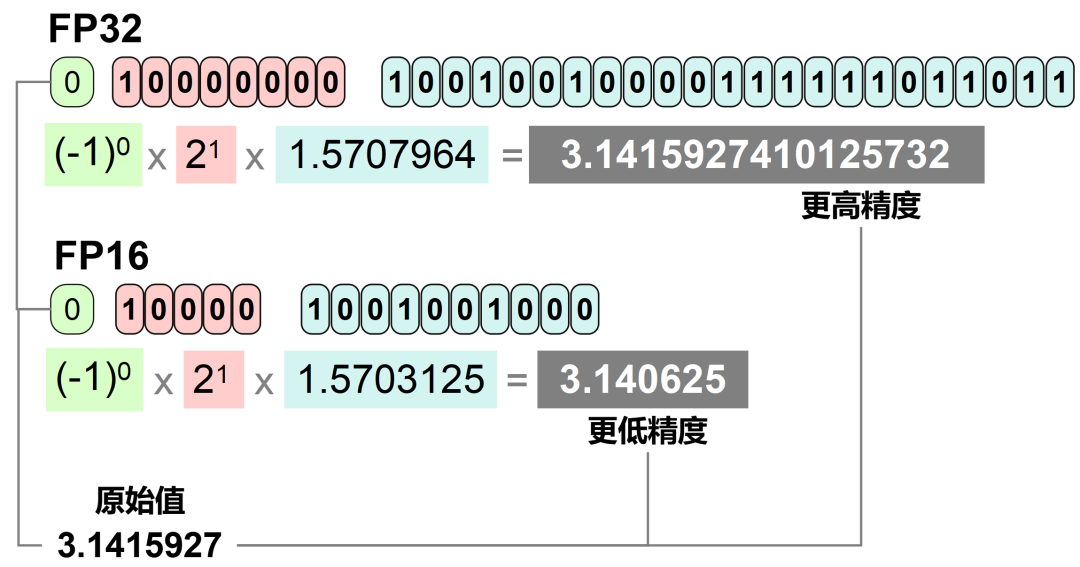
FP64、FP8、FP4
除了常见的FP32和FP16之外,还有FP64、FP8、FP4。
图我就懒得画了。列个表,方便对比:
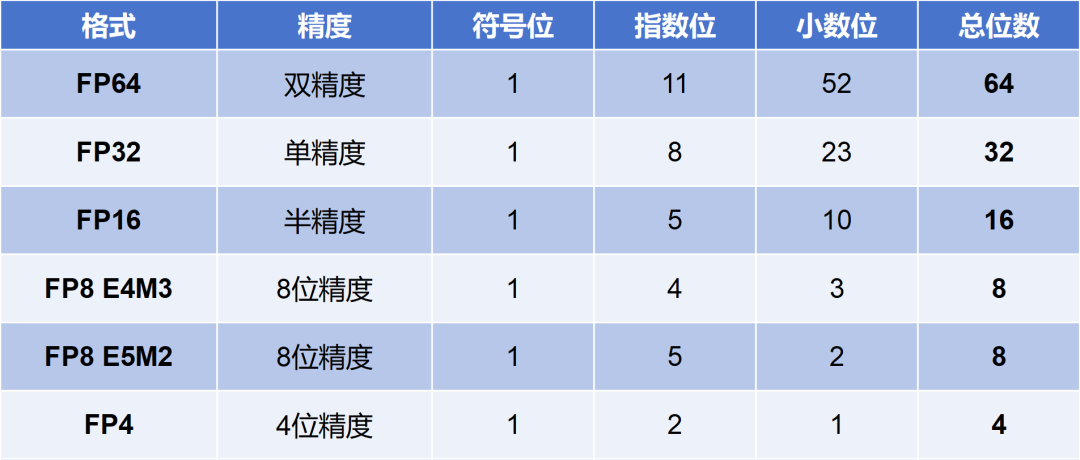
大家肯定能看出来,FP64所表示的动态范围最大,精度最高。FP4反之。
FP32通常称为单精度浮点数,FP16被称为半精度浮点数。其它的命名,上面表格也有。
FP8有点特别,有E4M3(4位指数和3位尾数)和E5M2(5位指数和2位尾数)两种表示方式。E4M3精度更高,而E5M2范围更宽。
不同格式的应用区别
好了,问题来了——为什么要搞这么多的格式呢?不同的格式,会带来什么样的影响呢?
简单来说,位数越多,范围越大,精度越高。但是,占用内存会更多,计算速度也会更慢。
举个例子,就像圆周率π。π可以是小数点后无数位,但一般来说,我们都会取3.14。这样虽然会损失一点精度,但能够大幅提升计算的效率。
换言之,所有的格式类型,都是在“精度”和“效率”之间寻找平衡。不同的应用场景有不同的需求,采用不同的格式。
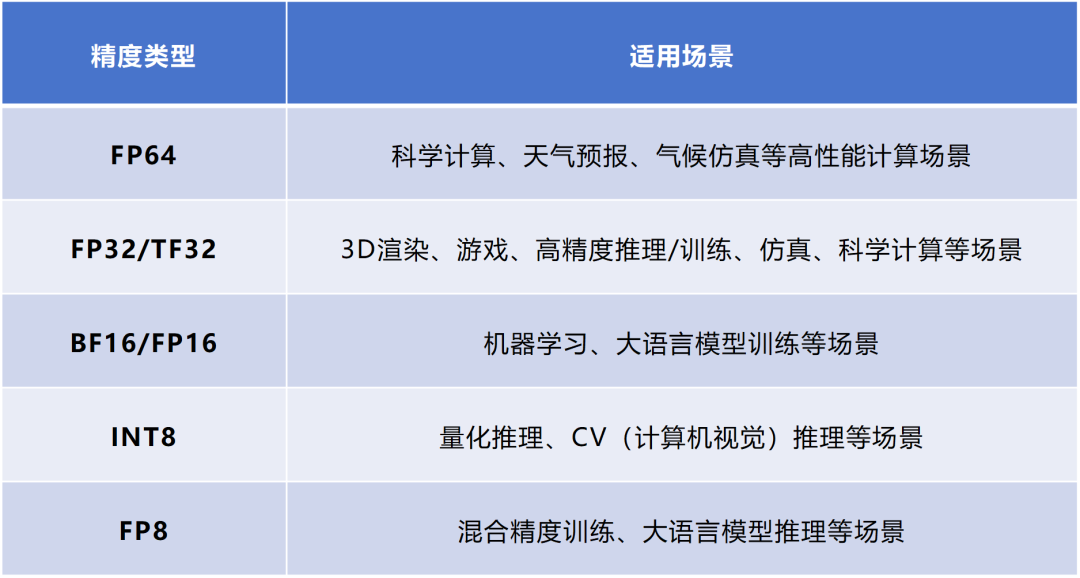
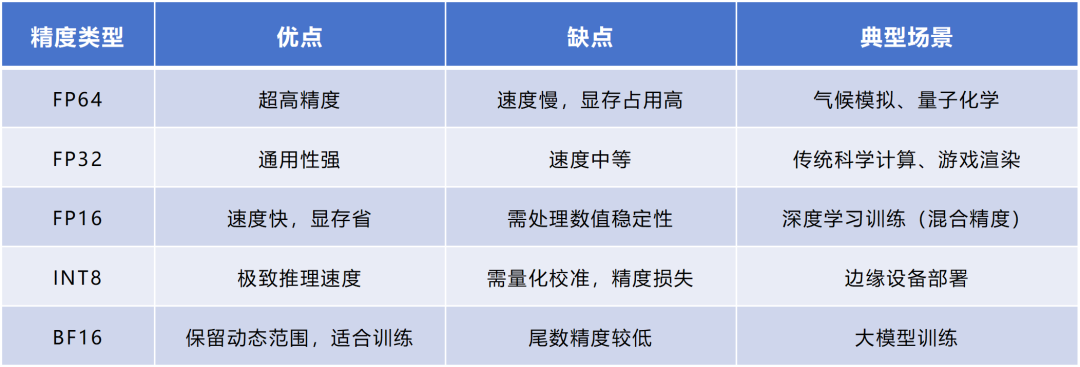
FP64的精度最高,在基础科学、金融建模、气候模拟、医学研究、军事应用等领域会用得比较多。这些场景对误差比较敏感。
FP32是通用计算的“全能选手”,也是早期主要的数据类型。它的平衡性更强,精度和速度适中,适合图形渲染等很多任务。
FP16也是应用非常普遍的一种格式。它非常适合AI领域的应用,可以覆盖大多数深度学习任务的数值需求。这几年,FP16一直是智算场景下性价比最优的方案,配合Tensor Core(张量核心)算力利用率超92%。
FP16也很适合图像渲染。例如,GPU的着色器就大量使用了FP16,用于计算光照(如游戏中的人物阴影)、纹理映射,可以更好地平衡画面质量与帧率。
FP8和FP4是最近几年才崛起的新兴低精度浮点数格式。FP8于2022年9月由英伟达等多家芯片厂商共同定义。FP4则是2023年10月由某学术机构定义。
这几年全社会关注算力,主要是因为AI,尤其是AIGC大模型训练推理带来的需求。FP32和FP16的平衡性更强,占用内存比FP64更小,计算效率更高,非常适合这类需求,所以关注度和出镜率更高。
举个例子:如果一个神经网络有10亿(1 billion)个参数,一个FP32格式数占4字节数(32bit÷8=4byte),FP16占2字节。那么,FP32格式下,占用内存(显存)大约是4000MB(10亿×4byte÷1024÷1024)。FP16格式下,则是约2000MB。
更小的内存占用,允许模型使用更大的Batch Size(批量样本数),提升梯度估计的稳定性。运算速度越快,训练周期越短,成本越低,能耗也越低。
那么,这里提一个问题——不同的数据类型,有不同的特点。那么,有没有办法,可以将不同数据类型的优点进行结合呢?
当然可以。这里,就要提到两个重要概念——多精度与混合精度。
在计算领域,多精度计算与混合精度计算是两种重要的优化策略。
多精度计算,是在应用程序或系统的不同场景下,固定选用不同的精度模式,以此匹配计算需求。
混合精度计算,更为巧妙。它在同一操作或步骤中,巧妙动态融合多种精度级别,进行协同工作。
例如,在大模型的训练推理任务中,就可以采用FP16和FP32的混合精度训练推理。FP16,可以用于卷积、全连接等核心计算(减少计算量)。FP32,则可以用于权重更新、BatchNorm统计量等计算(避免精度损失)。
现在主流的AI计算框架,例如PyTorch、TensorFlow,都支持自动将部分计算(如矩阵乘法)切换至FP16,同时保留FP32主权重用于梯度更新。
大家需要注意,并不是所有的硬件都支持新的低精度数据格式!
像我们的消费级显卡,FP64就是阉割过的,FP16/FP32性能强,FP64性能弱。
英伟达的A100/H100,支持TF32(注意区别,不是FP32)、FP64、FP8,专为AI和高性能计算优化。
AMD GPU,CDNA架构(如MI250X)侧重FP64,RDNA架构(如RX 7900XTX)侧重FP32/FP16。
FP8最近几年热门,也是源于对计算效率的极致追求。
英伟达GPU从Ada架构和Hopper架构开始提供了对FP8格式的支持,分别是前面提到的E4M3和E5M2。到了Blackwell架构,开始支持名为MXFP8的新FP8,其实就是之前的传统FP8基础上增加了Block Scaling能力。
TF32、BF16
除了FP64/FP32/FP16/FP8/FP4之外,业界还推出了一些“改进型”的浮点数类型。例如刚才提到的TF32(及TF16),还有BF16。
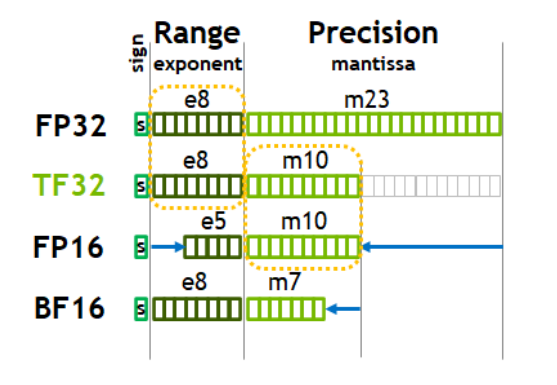
TF32和TF16,是英伟达针对机器学习设计的一种特殊数值类型,用于替代FP32。TF,是指Tensor Float,张量浮点数。
TF32的组成:1位符号位,8位指数位(对齐FP32),10位小数位(对齐FP16),实际有效位数为19位。
BF16由Google Brain提出,也是用于机器学习。BF,是指Brain Float。
BF16的组成:1位符号位,8位指数位(和FP32一致),7位小数位(低于FP16),实际有效位数为16位。
虽然BF16的精度低于FP16(牺牲尾数精度),但表示范围和FP32一致(指数范围相同),易于与FP32转换,适用于深度学习推理。
INT8、INT4
最后,我们再来说说INT8/INT4。
刚才介绍的,都是浮点数。INT是Integer的缩写,即整数类型。什么是整数?不用我解释了吧?没有小数的,就是整数(例如1、2、3)。
INT8,是用8位二进制数表示整数,范围(有符号数)是-128到127。INT4,是用4位二进制数来表示整数,范围(有符号数)是-8到7。
INT比FP更简单,对数据进行了“粗暴”的截断。例如FP32中的0.7,会变成1(若采用四舍五入),或0(若采用向下取整)。
这种方式肯定会引入误差。但是,对某些任务(如图像分类)影响较小。因为输入数据(例如像素值0-255)本身已经是离散的,模型输出的类别概率只需要“足够接近”即可。
这里,我们就要提到一个重要的概念——量化。
将深度学习模型中的权重和激活值从高精度浮点数(例如FP32)转换为低精度(INT8)表示的过程,就是“量化”。
量化的主要目的,是为了减少模型的存储需求和计算复杂度,同时尽量减少精度损失。
举个例子,量化就像是把一幅高分辨率的画变成一幅低分辨率的画,既要减少体积,也要尽可能降低精度损失。当你网速慢的时候,720p视频也能看。
INT8量化是目前应用最广泛的量化方法之一,行业关注度很高。因为它在保持较高精度的同时,大大减少了模型的尺寸和计算需求。大多数深度学习框架和硬件加速器,都支持INT8量化。INT8的走红,和AI端侧应用浪潮也有密切关系。端侧和边缘侧的设备,内存更小,算力更弱,显然更加适合采用INT8这样的量化数据格式(否则可能无法加载)。而且,这类设备通常是移动设备,对功耗更加敏感,需要尽量省电。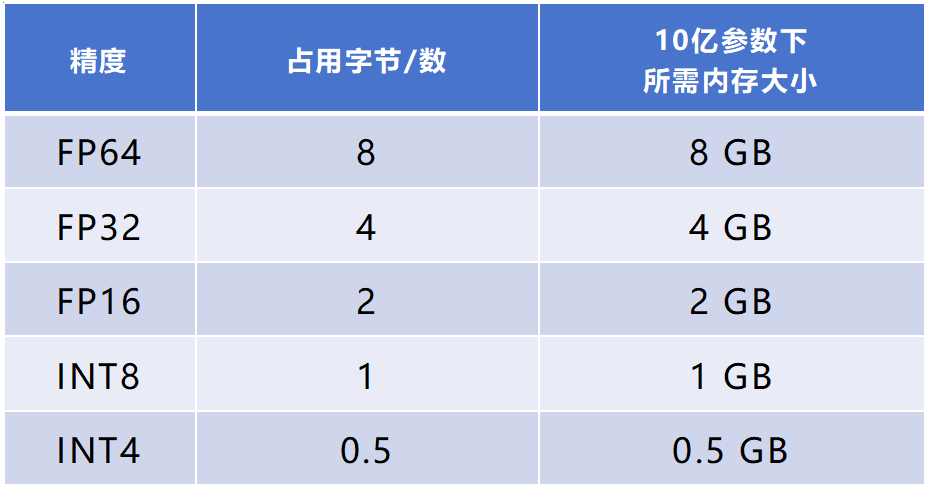 端侧和边缘侧,主要是进行推理任务。量化模型在推理时的计算量更少,能够加快推理速度。大家会注意到,GPU算卡和数据中心的算力,通常是FLOPS(每秒浮点运算次数)为单位。而手机终端的算力,通常是TOPS(每秒万亿次操作)为单位,没有FL。这正是因为手机终端、物联网模组以INT8量化数据类型(整数运算)为主。手机里面的NPU,往往还会专门针对INT8进行优化。
端侧和边缘侧,主要是进行推理任务。量化模型在推理时的计算量更少,能够加快推理速度。大家会注意到,GPU算卡和数据中心的算力,通常是FLOPS(每秒浮点运算次数)为单位。而手机终端的算力,通常是TOPS(每秒万亿次操作)为单位,没有FL。这正是因为手机终端、物联网模组以INT8量化数据类型(整数运算)为主。手机里面的NPU,往往还会专门针对INT8进行优化。
INT4量化,是一种更为激进的量化方式。但是,在实际应用中相对较少见。
因为过低的精度,可能导致模型性能显著下降。此外,并不是所有的硬件都支持INT4操作,需要考虑硬件的兼容性。

需要特别注意的是,在实际应用中,存在量化和反量化过程。
例如,在大模型训练任务中,会先将神经网络的参数(weight)、特征图(activation)等原本用浮点表示的量值,换成用定点(整型)表示。后面,再将定点数据反量化回浮点数据,得到结果。
量化包括很多种算法(如权重量化、激活量化、混合精度量化等),以及量化感知训练(QAT)、训练后量化(PTQ)等类型。具体的过程还是非常复杂的。限于篇幅,这里就不多介绍了,大家感兴趣可以自行检索。
结语
好啦,以上就是关于FP32、FP16、INT8等数据格式类型的介绍。
现在整个社会的算力应用场景越来越多,不同的场景会用到不同的数据类型。这就给厂商们提出了难题——需要让自家的算卡,尽可能支持更多的数据类型。
所以,今年以来,包括国产品牌在内的一些算卡厂商,都提出了全场景、全数据类型、全功能GPU(NPU)的说法。也就是说,自家的算卡,需要能够通吃所有的应用场景,支持所有的数据类型。
未来,随着AI浪潮的发展,FP4、INT4甚至二值化(Binary/Temary)的更低精度数据类型,会不会更加普及呢?会不会取代FP32/FP16/INT8?
让我们拭目以待!
参考文献:
1、《从精度到效率,数据类型如何重塑计算世界?》,不完美的代码,CSDN;
2、《大模型精度:FP32、TF32、FP16、BF16、FP8、FP4、NF4、INT8》,知乎;
3、《现在谈论大模型参数,其中的“fp8”是什么意思?》,Edison Chen,知乎;
4、《GPU服务器计算精度是什么?FP32、FP16和INT8全解析》,熵云智能中心,知乎;
5、《大模型涉及到的精度有多少种?》,一步留神,知乎;
6、百度百科、维基百科、腾讯元宝。
文章来源于鲜枣课堂,作者小枣君
-
芯片
+关注
关注
462文章
53538浏览量
459156 -
算力
+关注
关注
2文章
1385浏览量
16566 -
智算中心
+关注
关注
0文章
108浏览量
2451
发布评论请先 登录
【算能RADXA微服务器试用体验】+ GPT语音与视觉交互:2,图像识别
Optimum Intel / NNCF在重量压缩中选择FP16模型的原因?
将Whisper大型v3 fp32模型转换为较低精度后,推理时间增加,怎么解决?
实例!详解FPGA如何实现FP16格式点积级联运算
详解天线系统解决方案中的FP16格式点积级联运算
Arm Cortex-M系列处理器中m4 dsp如何做到只支持fp32一种数据类型
推断FP32模型格式的速度比CPU上的FP16模型格式快是为什么?
INT8量化常见问题的解决方案
BM1684架构介绍
NVIDIA宣布推出新一代计算平台“HGX-2”
NVIDIA TensorRT的数据格式定义
基于算能第四代AI处理器BM1684X的边缘计算盒子

计算精度对比:FP64、FP32、FP16、TF32、BF16、int8






 工商网监
工商网监
评论