 一种360°全景定制的Transformer框架
一种360°全景定制的Transformer框架

导读
现有的基于CNN 的全景深度估计方法侧重于消除全景失真,由于CNN中固定的接收场,无法有效地感知全景结构。本文提出了一种360°全景定制的Transformer框架,可以很容易地迁移到全景视觉其他dense prediction任务上,比如全景图像语义分割,无需改变任何网络结构便能取得SOTA性能。

论文链接:
https://arxiv.org/pdf/2203.09283.pdf
代码链接:
https://github.com/zhijieshen-bjtu/PanoFormer
文案:申志杰,廖康
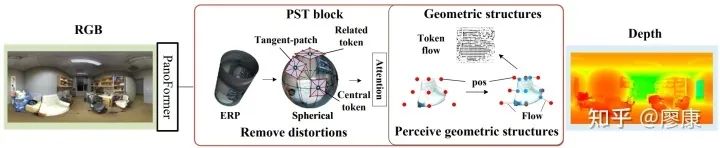
PanoFormer简介图
1. 研究背景及动机
单目全景深度估计(monocular omnidirectional depth estimation, MODE)是三维场景理解中的一个子领域,其任务设定为给定一张360°全景RGB图像,通过网络建模推理得到对应的360°深度图,相较于立体视觉而言具有更好的便利性。
MODE使用更为常见的等距柱状投影(ERP)全景图作为输入。这与正常的2D perspective图像存在较大差异:ERP全景图的360°视角增益是以畸变为代价,因此导致整幅图像存在规律性的扭曲(畸变程度由图片水平轴线向垂直边逐渐增大)。受限于CNN有限的感受野和固定的采样位置,这种畸变特性使得MODE具有独立于传统单目深度估计任务之外的挑战性。
当然,此前的一些工作提出基于CUBE和ERP投影的双分支融合结构来增强网络对于大畸变区域的特征提取和建模能力,但需要注意的是,CUBE格式的全景图在投影过程中会有25%像素的丢失,这直接导致CUBE分支深度图的模糊。如此两个分支的有限结果决定了其性能上限。为了解决像素损失这一问题,后续有工作提出基于旋转CUBE设计双分支结构,一定程度上缓和了这一矛盾。
随着Transformer网络框架的兴起,其独特的long-range建模能力为解决大畸变问题提供了一个新的思路。但“拿来主义”真能行得通吗?
2. 应用挑战
首先,我们回顾一下传统的视觉Transformer在处理图像时的步骤并分析一下其在ERP图像上的应用挑战:
划分patch
在以ERP格式作为输入的前提下会有两种划分patch的方法:(1)直接等间距划分patch;(2)将球面全景图投影成重叠的perspective视口自然地作为patch。首先,直接划分patch的方法会显著破坏大畸变区域的结构,而perspective视口可以将跨度非常大的物体投影回一个patch。这样对比来看似乎后者更有趣且合理。
Patch->Embedding->Token
视觉Transformer中做位置嵌入是通过线性层压缩特征维度实现的,那这种特征维度的压缩对于深度估计这一类像素级回归任务来说会不会造成信息的丢失,从而导致性能的下降?
位置嵌入
此前的一些工作指出,在视觉领域位置嵌入能够贡献的力量似乎并没有很大,且比较鸡肋,很多工作甚至直接摒弃了位置嵌入模块,他们认为网络中所引入的卷积结构会暗含位置信息。但考虑步骤1,如果我们采用perspective视口patch的划分方式,其真实的空间位置已经发生了改变,因此一个合适的位置嵌入策略在MODE中是迫切需要的。那么如何设计一个合理的位置嵌入方式呢?
Self-attention
自注意力模块通过压缩后的特征生成q, k, v依次查询计算全局注意力,如果我们的embedding设计成像素级,将会带来很大的计算复杂度,如何解决?
为了解决这些问题我们提出了一种360°全景定制的Transformer框架。
3. 方法
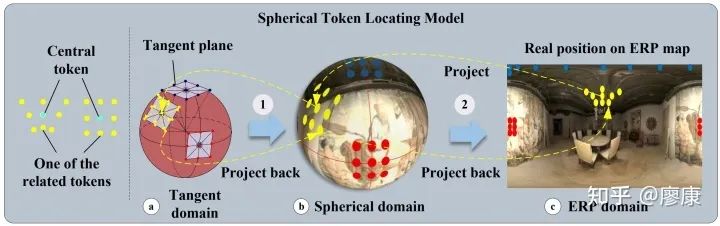
Spherical Token Locating Model (STLM)
划分patch
如前所述,我们划分patch可以尽可能地通过投影的方式划分patch而不是直接在ERP图上划分。投影我们选择CUBE格式的perspective视口。那么问题是,我们如何选择CUBE patch的切点?以及如何确定patch的大小?不考虑计算复杂度,我们可以将每个像素点都作为一次切点,这样信息会尽可能地全部保留。至于大小,我们在前面讨论了CUBE投影的弊端之一是像素丢失,在这里我们还要讨论一种弊端:对于CUBE投影面,理想情况下仅有CUBE的中心点(即切点)不存在畸变,除此之外,其他位置会呈现出由切点向四周逐渐增大的畸变趋势。考虑一种极端的情况,当CUBE的大小收缩到极致,即每个CUBE面仅由中心切点及其周围的八个点组成,CUBE面近似贴近球面,畸变影响降至最小。我们将此时的CUBE面称为Tangent patch。
Embedding
从尽可能提高性能的角度出发,我们可以通过等价映射将每个像素点映射成一个Token。区别于传统Transformer中将每个Patch嵌入为每个Token,我们直接将每个Tangent Patch上的采样点当作Token。直观的理解,我们的patch和token都是手工划分的,patch在我们的网络中多为一种抽象的概念,我们直接的操作对象是Token(采样点),即每个切点及其周围的八个点。
位置嵌入
Tangent Patch是相对于球面而言,为了定义其空间位置属性,我们将手工划分的patch反投影到ERP图上。注意在球面全景图上每个patch由切点及其周围的八个投影点组成,而在ERP图上这种空间对应关系发生了改变,由于畸变的存在,他们在ERP上几乎不再相邻。这种位置投影对应关系恰恰提供了我们Transformer里面所需要的位置嵌入。
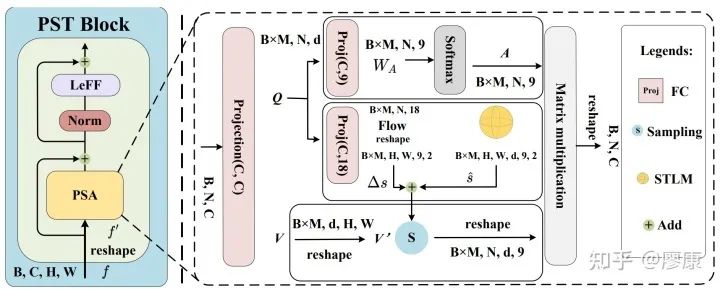
Panoramic Structure-guided Transformer (PST) block
计算注意力
首先如果我们像传统Transformer那样计算注意力,其计算开销非常大,但得益于我们patch划分方式和位置嵌入策略,我们似乎找到了其最相关的位置对应关系,即切点token及与其最相关的8个token。那么我们可以仅仅通过计算切点token(或中心token)与这8个token的注意力即可。但问题如果这样做,我们会犯了一个非常大的错误,即把token的位置锁死了,使得我们的网络架构丧失了传统Transformer固有的灵活性。为了解决这一问题,我们提出了token flow的概念,即通过学习一个偏移来弥补其结构上灵活性的丧失。意外之喜是,这种流式的概念可以使网络更好地建模全景结构这一重要的深度线索。
最后,我们基于设计的PST block构建最终的PanoFormer网络框架:
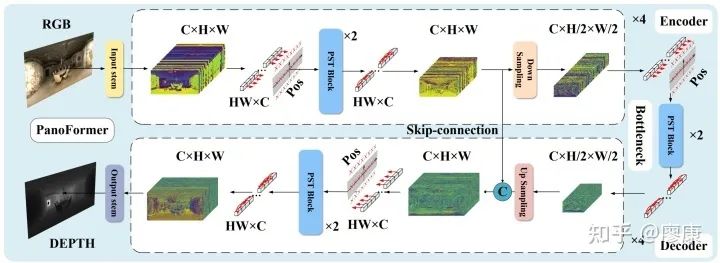
PanoFormer网络架构图
4. 新指标
为了突出模型对于大畸变区域的建模能力,我们通过选取6个CUBE投影面的上下两个面来设计Pole-RMSE指标。(注意此指标的应用的一个前提条件是全景相机水平放置,目前的流行的数据集大都遵循这一假设。)
考虑到ERP全景图的特性,左右可以实现无缝拼接,我们提出LRCE指标来反映模型的长距离建模能力。
详细计算过程请参考论文。
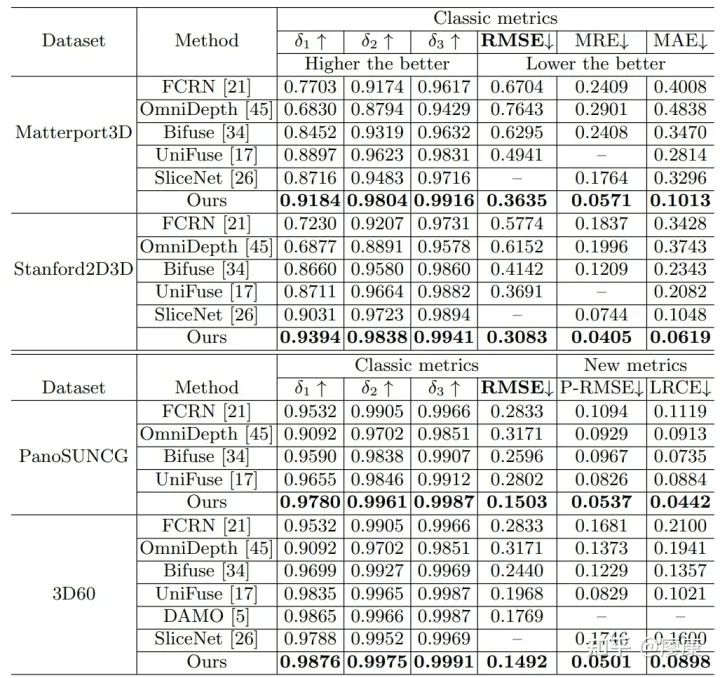
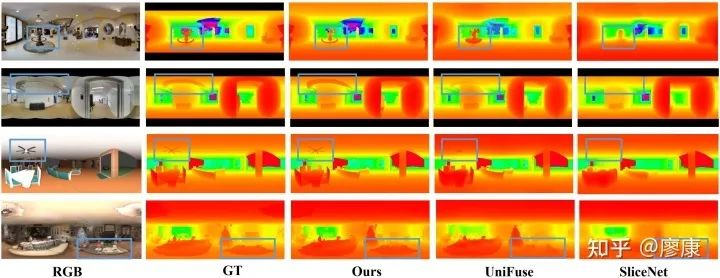
5. 实验结果
我们在四个主流的MODE数据集上对我们的模型进行了评估,结果显示我们的模型取得了更有竞争力的结果。但由于Stanford2D3D以及Matterport3D数据集的固有缺陷导致我们没有办法在这两个数据集上评测我们的新指标(P-RMSE),因此我们在这两个数据集上只报道了MRE和MAE的指标性能,这两个指标的计算参照SliceNet(CVPR'21)所开源的代码执行。此外,关于数据集的一些讨论详情见gihub代码链接。
值得一提的是,PanoFormer可以很容易地迁移到全景视觉其他dense prediction任务上,比如全景图像语义分割,无需改变任何网络结构便能取得SOTA性能。
客观指标
主观对比

全景语义分割客观指标
6. 局限性
关于更高分辨率的扩展计算复杂度可能是我们工作的一个待提升的点。这可以通过在encoder阶段增加下采样层,在decoder阶段增加插值操作得到缓解。此外,如果仔细观察可以发现attention计算部分存在比较多重复计算的情况,这可能是优化我们网络的一个方向。
希望我们的工作可以为该领域带来启发。
审核编辑 :李倩
-
框架
+关注
关注
0文章
404浏览量
18491 -
数据集
+关注
关注
4文章
1240浏览量
26261 -
Transformer
+关注
关注
0文章
156浏览量
6961
原文标题:首个360°全景定制的单目深度估计Transformer-PanoFormer(ECCV 2022)
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Transformer 入门:从零理解 AI 大模型的核心原理
Transformer如何让自动驾驶大模型获得思考能力?
一种无OS的MCU实用软件框架
Transformer如何让自动驾驶变得更聪明?
为什么360°镜头容易“踩坑”?

【「AI芯片:科技探索与AGI愿景」阅读体验】+第二章 实现深度学习AI芯片的创新方法与架构
12 路 1080P 满负载!米尔 RK3576 补全车载 360° 全景影像视野
一种适用于动态环境的自适应先验场景-对象SLAM框架
米尔RK3576核心板,让360环视技术开发更简单
Transformer架构中编码器的工作流程

Transformer架构概述

这一重量级玩家入局,全景相机越来越卷?



评论