 Transformer架构概述
Transformer架构概述

由于Transformer模型的出现和快速发展,深度学习领域正在经历一场翻天覆地的变化。这些突破性的架构不仅重新定义了自然语言处理(NLP)的标准,而且拓宽了视野,彻底改变了AI的许多方面。
以其独特的attention机制和并行处理能力为特征,Transformer模型证明了在理解和生成人类语言方面的创新飞跃,其准确性和效率是以前无法实现的。
谷歌在2017年一篇题为《attention就是你所需要的一切》的文章中首次提出,Transformer架构是ChatGPT等突破性模型的核心。它们在OpenAI的尖端语言模型中发挥了重要作用,并在DeepMind的AlphaStar中发挥了关键作用。
在这个AI的变革时代,Transformer模型对有抱负的数据科学家和NLP从业者的重要性怎么强调都不为过。作为大多数最新技术飞跃的核心领域之一,本文旨在破译这些模型背后的秘密。
什么是Transformer?
Transformer最初是为了解决序列转导或神经机器翻译的问题而开发的,这意味着它们旨在解决将输入序列转换为输出序列的任何任务。这就是为什么他们被称为“Transformer”。
什么是Transformer模型?
Transformer模型是一个神经网络,它学习顺序数据的上下文并从中生成新数据。简单地说是一种AI模型,它通过分析大量文本数据中的模式来学习理解和生成类似人类的文本。
Transformer是当前最先进的NLP模型,被认为是编码器-解码器架构的演变。但编码器-解码器架构主要依赖于循环神经网络(RNN)来提取序列信息,Transformer则完全缺乏这种循环性。
那么,他们是怎么做到的呢?

Transformer是专门设计来通过分析不同元素之间的关系来理解上下文和意义的,它们几乎完全依赖于一种叫做attention的数学技巧来做到这一点。
历史背景
Transformer模型起源于谷歌2017年的一篇研究论文,是机器学习领域最新和最有影响力的发展之一。第一个Transformer模型在有影响力的论文《attention就是你所需要的一切》中得到了解释。
这个开创性的概念不仅是一个理论的进步,而且还找到了实现,特别是在TensorFlow的Tensor2Tensor包中。此外,哈佛NLP小组通过提供论文的注释指南以及PyTorch实现对这个新兴领域做出了贡献。
它们的引入刺激了该领域的显著增长,通常被称为Transformer AI。这个革命性的模型为随后在大型语言模型领域(包括BERT)的突破奠定了基础。到2018年,这些发展已经被誉为NLP的分水岭。
2020年,OpenAI的研究人员宣布了GPT-3。在几周内,GPT-3的多功能性很快得到了证明,人们用它来创作诗歌、程序、歌曲、网站和更多吸引全球用户想象力的东西。
在2021年的一篇论文中,斯坦福大学的学者们恰当地将这些创新称为基础模型,强调了它们在重塑AI方面的基础作用。他们的工作突出了Transformer模型如何不仅彻底改变了该领域,而且推动了AI可实现的前沿,预示着一个充满可能性的新时代。
谷歌的前高级研究科学家、企业家Ashish Vaswani说:“我们正处在这样一个时代,像神经网络这样的简单方法正在给我们带来新能力的爆炸式增长。”
从像LSTM这样的RNN模型到用于NLP问题的transformer的转变
在Transformer模型引入时,RNN是处理顺序数据的首选方法,其特征在于其输入中的特定顺序。RNN的功能类似于前馈神经网络,但它按顺序处理输入,每次处理一个元素。
Transformer的灵感来自于RNN中的编码器-解码器架构。但是,Transformer模型完全基于attention机制,而不是使用递归。
除了提高RNN的性能,Transformer还提供了一种新的架构来解决许多其他任务,如文本摘要、图像字幕和语音识别。
那么,RNN的主要问题是什么呢?它们对于NLP任务是无效的,主要有两个原因:
它们依次处理输入数据。这种循环过程不使用现代GPU,GPU是为并行计算而设计的,因此,使得这种模型的训练相当缓慢。
当元素彼此距离较远时,它们就变得无效。这是因为信息是在每一步传递的,链越长,信息在链上丢失的可能性越大。
从像LSTM这样的RNN到NLP中Transformer的转变是由这两个主要问题驱动的,Transformer通过利用attention机制的改进来评估这两个问题的能力:
注意具体的词语,不管它们相距多远。
提高性能速度。
因此,Transformer成为RNN的自然改进。接下来,让我们来看看Transformer是如何工作的。
Transformer架构
概述
最初设计用于序列转导或神经机器翻译,Transformer擅长将输入序列转换为输出序列。这是第一个完全依靠自关注来计算输入和输出表示的转导模型,而不使用序列对齐RNN或卷积。Transformer架构的主要核心特征是它们维护编码器-解码器模型。
如果我们开始将用于语言翻译的Transformer视为一个简单的黑盒,那么它将接受一种语言(例如英语)的句子作为输入,并输出其英语翻译。

如果稍微深入一点,我们会发现这个黑盒子由两个主要部分组成:
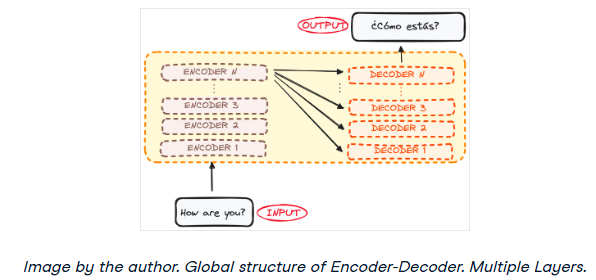
编码器接受输入并输出该输入的矩阵表示。例如,英语句子“How are you?”
解码器接受该编码表示并迭代地生成输出。在我们的例子中,翻译后的句子“¿Cómo estás?”

然而,编码器和解码器实际上都是一个多层的堆栈(每层的数量相同)。所有编码器都呈现相同的结构,输入进入每个编码器并传递给下一个编码器。所有解码器也呈现相同的结构,并从最后一个编码器和前一个解码器获得输入。
最初的架构由6个编码器和6个解码器组成,但我们可以根据需要复制尽可能多的层。假设每个都有N层。
现在对整个Transformer架构有了一个大致的了解,让我们把重点放在编码器和解码器上,以更好地理解它们的工作流程。
-
编码器
+关注
关注
45文章
4030浏览量
143891 -
模型
+关注
关注
1文章
3894浏览量
52401 -
Transformer
+关注
关注
0文章
156浏览量
7002
原文标题:Transformer架构详细解析——概述
文章出处:【微信号:SSDFans,微信公众号:SSDFans】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
基于DINO知识蒸馏架构的分层级联Transformer网络
关于深度学习模型Transformer模型的具体实现方案
如何更改ABBYY PDF Transformer+界面语言
概述隔离式电源集中式电源架构
CMSIS软件架构概述
谷歌将AutoML应用于Transformer架构,翻译结果飙升!
解析Transformer中的位置编码 -- ICLR 2021

如何使用Transformer来做物体检测?
Transformer深度学习架构的应用指南介绍
Inductor and Flyback Transformer Design .pdf

利用Transformer和CNN 各自的优势以获得更好的分割性能
RetNet架构和Transformer架构对比分析
基于Transformer模型的压缩方法

Transformer架构在自然语言处理中的应用
Transformer架构中编码器的工作流程




评论