 数据中心将进入完全可编程时代
数据中心将进入完全可编程时代

大家看到这个标题,第一个反应应该会是疑问:难道现在数据中心的处理器不可编程? 首先,强调一下,现在数据中心的处理器,当然是可编程的。但是,我标题这么写,一定是有原因的。 NVIDIA有DPU和DOCA;Intel有IPU和IPDK,而且还发起了OPI;然后博通刚刚宣布收购VMWare。这些看似没有联系的事情之间,其实有一个共通的底层逻辑。
01先聊聊功能机到智能机的发展
直到现在,我仍然印象深刻的记得,在2010年的时候,诺基亚还保持着全球手机销量霸主的地位。但这个时候,整个市场已经不看好诺基亚了,它的日子并不好过。当时我还觉得诺基亚就是再不济,也应该作为智能手机和移动互联网时代的一个重要的参与者而存在。谁能想到,短短几年,诺基亚手机就“烟消云散”了。 据说,当年诺基亚迟迟未推出能够挑战iPhone的产品的主要原因,是该公司认为iPhone注定失败,因为其未能通过抗摔测试。第一代iPhone面市时,诺基亚工程师就对其进行了全面的研究,最终认定,它不会对诺基亚产生威胁,原因是造价太高,并且只兼容2G网络,而且未能通过基本的抗摔测试。而此时的诺基亚正如日中天,诺基亚引领了很多手机功能的“创新”,比如手机摄像、全功能键盘、塞班操作系统,当然也包括和旋铃声、换壳等。 换汤不换药,不本质创新的诺基亚,难以改变被市场无情抛弃的命运。 我们来总结一下iPhone这样的智能手机的成功之处。我个人总结,主要有两点:
一个是,不要试图帮助用户决策。智能手机提供给用户的是一个平台,而不是一个具有具体功能的产品。用户是通过安装APP来实现自己要的五花八门又各自不同的具体功能的。
另一个是,易用性。在智能手机表现的则是人机交互,也就是划时代意义的触摸划屏交互。在2017年iPhone之前,其实微软已经早在2000年就发布了基于Windows的智能手机。但其因为通过触控笔实现类似鼠标的单击双击,非常难用,所以一直没能流行起来。
02再分析一下各类处理引擎
2.1 CPU
在数据中心等复杂计算场景,对灵活可编程性要求非常高。 CPU是可编程的,而且CPU还是灵活性最好的可编程平台。因此,目前数据中心的处理器主要还是CPU。而GPU/ASIC等均不满足灵活可编程性的要求。 而随着技术发展,CPU的性能逐渐瓶颈,基于CPU的摩尔定律失效。但算力的需求并没有停滞,仍在不断提升,因此,各类其他的处理引擎和芯片逐渐走上了舞台。
2.2 GPU
GPU(默认为GPGPU),一方面其数以千计的引擎可编程能力不错,可以覆盖非常多的领域。也因为CUDA强大生态的加持,使得GPU这几年以及未来若干年,在数据中心会得到非常大规模的采用。 但是,相比DSA/ASIC来说,GPU的性能还是不够极致。
2.3 DSA
John Hennessy和David Patterson是体系结构领域的权威,两人在其2017年图灵奖获奖演讲时说,未来十年是体系机构的黄金年代,在CPU性能达到瓶颈的情况下,需要针对特定的领域定制专用处理器,这也就是当前大家熟悉的DSA。 已经被Intel收购的Barefoot公司,设计的可编程网络DSA芯片Tofino已经得到非常多的落地;但AI类的DSA目前仍没有看到比较广泛的落地。两者的主要区别在于:
网络领域处于基础设施层次,其场景变化相对较小。DSA相比ASIC较好,但相比GPU较差,的灵活可编程能力,基本符合网络领域的灵活性要求。因此,其可以在确保灵活可编程能力的基础上实现最极致的性能。
而AI领域,目前算法多种多样,很多新的算法还在出现。AI领域,在性质上,仍然属于应用层次,也即场景灵活多变。这样对引擎的灵活可编程能力提出了更高要求,而DSA架构的处理器很难满足。从实践可以看到,目前大量的AI是基于更高灵活性的GPU部署的。
当然,随着时间推移,很多AI类的算法沉淀,势必逐渐从应用变成基础设施。当AI逐渐稳定,对灵活性的要求降低,就是AI DSA大显身手之时。
2.4 ASIC
越是复杂场景,对灵活性的要求越高。 在大芯片场景,ASIC形态的处理引擎会完全消失。
03未来发展:完全可编程
3.1 智能网卡、DPU等芯片的落地困境
因为CPU性能不够,因此出现了很多类型的芯片来卸载CPU的任务,减轻CPU的负担,以此来实现性能提升。如单功能加速卡、智能网卡、DPU等。这些处理器目前存在一些共性的挑战:
因为不同用户业务场景存在差异化,并且用户业务场景仍在快速迭代。
跟客户场景深度绑定,是偏ASIC级别的定制,会导致市场碎片化。碎片化的市场会导致某一芯片产品能覆盖的规模较小,也即出货量会少。
偏ASIC的定制会导致芯片设计复杂度高。ASIC紧耦合的系统,把业务逻辑完全变成电路,芯片设计工作量大,设计复杂度高。另外场景的多种多样和快速迭代,也使得ASIC设计难以覆盖更多的差异。
芯片NRE、IP等费用高,需要芯片大规模落地。工艺进步,使得大芯片的研发成本进一步提升。这就需要芯片销量进一步提升,才能摊薄一次性成本。而偏定制的方案则完全走向了相反的方向。大芯片,一定需要足够通用灵活可编程,才好大规模落地。
类比前面功能机和智能机的区别,可以认为:
目前很多加速卡、智能网卡、DPU的做法仍是类似功能机的做法。整个功能是确定的,硬件中实现了很多具体功能和业务逻辑,越庖代俎,帮助用户决策。
还没有做到,类“智能手机”的做法,完全可编程的硬件平台,把决策交给用户。
3.2 架构:从同构到异构,再到超异构

常见的多核CPU,即是同构并行计算。CPU是最常见的并行计算架构,但由于单个CPU核的性能已经到达瓶颈,并且单颗芯片所能容纳的核数也逐渐到头。CPU同构并行已经没有多少性能挖潜的空间。 CPU+xPU的异构加速并行架构,一般情况下,GPU、FPGA及DSA加速器都是作为CPU的协处理加速器的形态存在,不是图灵完备的。异构计算CPU是辅助,系统的特点跟加速器是一致的,符合我们之前关于GPU、DSA等处理引擎的分析,各有优缺点。
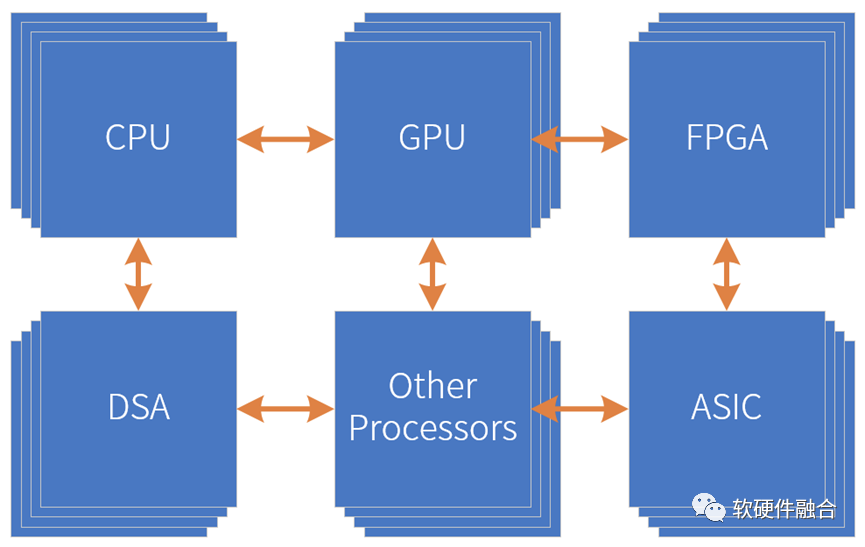
芯片工艺带来的资源规模越来越大,所能支撑的设计规模也越来越大,这给架构创新提供了非常坚实的基础。可以采用多种处理引擎,从单兵作战到团队协作,来共同完成复杂系统的计算任务,这就是超异构。
3.3 用户/开发者视角:完全可编程的芯片平台
像智能手机一样,完全可编程的处理芯片提供给用户的是一个没有具体功能的芯片平台,具体的功能由用户通过软件编程实现。 完全可编程的含义:
所有功能由用户通过软件定义。授人以鱼不如授人以渔,既然提供的是平台化解决方案。那么一些主要的组件一定是要集成的,然后这些单元又可以自由组合,给用户提供一个几乎“无限”可能的平台。不同的用户,根据自己的需求组合功能,实现功能和场景差异。
所有业务逻辑由用户通过编程实现。用户自己的软件已经存在,业务逻辑也是经过长期打磨。业务逻辑是一个非常重要的事情:一些大的云计算公司,其底层业务逻辑支撑的上层云客户的业务都超万亿。这样,底层的业务逻辑修改一定是慎之又慎。用户期望的是不修改业务逻辑情况下,通过硬件实现业务处理的加速。
用户没有平台依赖。软件热迁移需要一致性接口的硬件,上层业务逻辑也需要一致性的硬件功能支持。这些都需要,站在用户视角,不同芯片厂家提供的是接口和架构完全一致标准化的产品。
讲完这里,我想大家可能还是有点疑惑,因为CPU就可以做到完全可编程,RISC-v架构CPU可以实现真正的无平台依赖。完全可编程是个什么? 那么,请接着看下一节。
3.4 性能和灵活性,似拔河一样拉扯到各自极致
完全可编程性能和灵活性的权衡,像天平,更像拔河比赛。 我们经常讲balance或tradeoff,也就是均衡(名词)/权衡(动词)。但总觉得少了点什么。思来想后,发现是少了点主动、少了点极致:
完全可编程,是要在满足灵活可编程的基础上,实现最极致的性能;
完全可编程,是要在性能满足要求的情况下,实现最极致的灵活可编程性。
完全可编程:
并不是说所有的事情,都CPU来完成,这是一种“懒惰”、“躺平”,因为CPU的性能是最差的;
也不是说,所有的事情都DSA完成。这样又会过犹不及。因为很多场景,对灵活性的要求超过了DSA可提供的灵活性能力。最典型场景就是AI加速,目前很多AI芯片落地困难的原因就是不满足灵活性的要求。

如何做? 系统是分层分块的,我们大体上可以把系统的工作任务分为三类:
应用层。站在硬件平台的视角,应用是完全不确定的,也不确定知道运行的应用到底是什么。这样,应用层的工作就适合CPU来做。
应用加速。有很多应用层的工作,性能敏感,需要通过加速的方式。但一方面受限于应用本身的算法变化较大,另一方面,硬件平台也可能给其他用户的相似应用使用,因此,弹性一些的加速会更合适一些。这样,GPU就成了应用加速的首选。
基础设施层。基础设施层相对变化较少(但并不意味着不变化),所以通常DSA架构处理引擎可以满足灵活性的基础上,实现最极致的性能。
这个划分,并不一定完全准确。还需要根据具体的工作任务特定,决定选择具体的处理器类型。
还有一点就是动态变化。可能随着系统的发展,有的任务会“上浮”,越来越需要灵活性;有的任务会“下沉”,更可以通过更优的硬件加速来极致的提升性能。
总之,大原则是:要在满足性能的基础上,提供最极致的灵活性;或者,在满足灵活性要求的基础上尽可能的选择性能更优的处理引擎方案,实现尽可能极致的性能。 每个引擎都有优势,也有劣势,通过单兵作战,我们只能“权衡”。但通过“团队协作”的超异构,我们能够实现优势互补,可以像拔河一样,把性能和灵活性都拉扯到极致。
3.5 案例:Intel愿景,完全可编程的网络
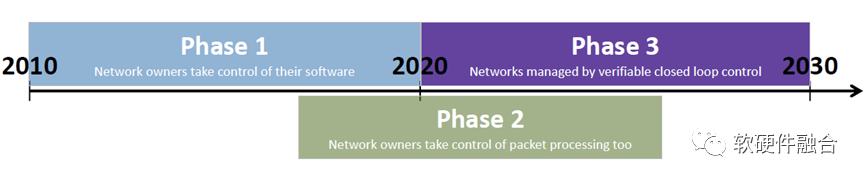
Intel SVP Nick McKeown 在 ONF Connect 2019演讲中第一次定义了SDN发展的三个阶段:
第一阶段(2010–2020年):通过Openflow将控制面和数据面分离,用户可以通过集中的控制端去控制每个交换机的行为;
第二阶段(2015–2025年):通过P4编程语言以及可编程FPGA或ASIC实现数据面可编程,这样,在包处理流水线加入一个新协议的支持,开发周期从数年降低到数周;
第三阶段(2020–2030年):展望未来,网卡、交换机以及协议栈均可编程,整个网络成为一个可编程平台。
这预示着,未来不管是交换机侧还是网卡侧,均需要实现类似CPU于通用程序设计的完全可编程的网络处理引擎,并且要基于此平台实现一整套的软件堆栈。把一个完全可编程的网络交给用户,支撑用户更快速的网络创新。
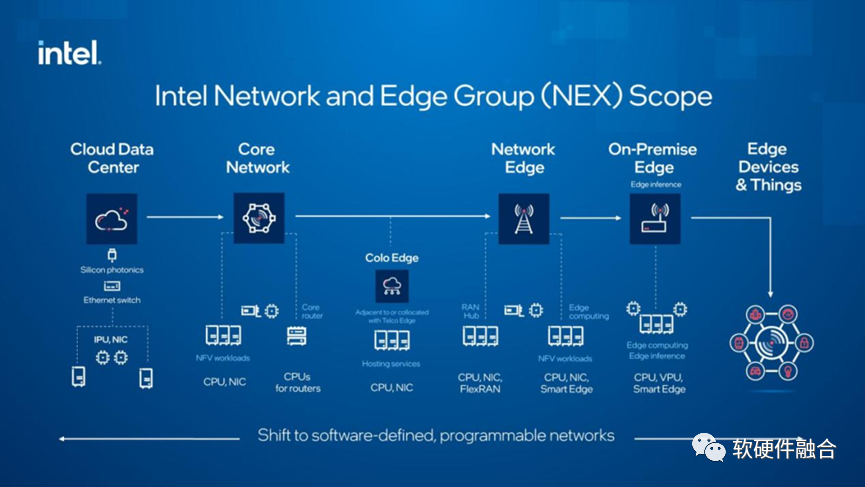
上图是Intel对整个未来网络演进趋势的看法:从云数据中心、核心网、接入网、边缘计算甚至终端设备,都会演化成完全“软件定义的可编程网络”。 当然,只是可编程的网络还不够。对数量众多的计算节点来说,对用户来说,完全可编程的计算(存储等其他处理都可以归到计算部分)才是更重要的。这样,可编程的网络和可编程的计算,共同组成了完全可编程的数据中心。
04完全可编程,还需要在硬件层次
提供更多通常属于软件的能力
4.1 可扩展
云计算有很多关键的能力,如弹性伸缩、虚拟化、多租户等。这些都对硬件的扩展能力提出了更高的要求:
功能的扩展。各类处理引擎的可编程能力来实现不同的功能;不同引擎的组合可以组织成不同的宏功能。
平行扩展。处理引擎要支持虚拟化,类似硬件里的多通道的概念。可以提供数以千计甚至数以万计的通道,使得每一个租户每个VM/容器甚至每一个应用都可以独占物理通道(资源)。
多芯片扩展。可以通过多芯片、多服务器、多Rack甚至多POD扩展,并且大家都是完全平行的,不产生新的Hierarchy分层(会显著增加系统复杂度,编程困难)。
4.2 软件实体和硬件平台分离
通常情况下,软件是附属于硬件而存在,软件实体和硬件平台是绑定的。 而在数据中心,软件和硬件是分离的:同一个软件实体会在不同的硬件实体迁移,而同样的一个硬件实体也需要运行不同的软件实体。 这样的需求,对硬件平台的一致性提出了很高的要求。
4.3 云网边端融合
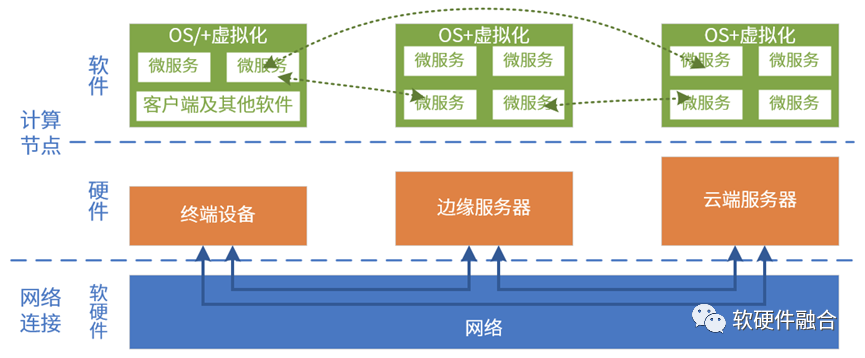
云计算、边缘计算、终端以及网络,算力需求不断提高,系统复杂度不断提高,对硬件的灵活可编程性要求也越来越高。 云网边端不是割裂的,而是组合成一个更大的系统的。微服务可运行在云端、边缘端,甚至终端本地。这就需要云数据中心内部,以及跨云边端的硬件平台一致性。
4.4 开放生态
随着系统越来越复杂,未来,所有的芯片都会是超异构架构芯片。所有的芯片也都需要支持虚拟化。并且,随着性能的提升,软件虚拟化代价越来越高,要尽可能的把虚拟化下沉到硬件加速。广义的虚拟化,不仅仅包括Hypervisor和I/O设备模拟,也包括网络VPC和分布式存储。DPU等芯片,本质上就是实现整个广义虚拟化的加速。 关于生态,这里讲三个仍在早期发展的对比案例:
NVIDIA DPU和DOCA。NVIDIA走的是一套完全封闭的路子,给客户提供性强劲功能相对完善的解决方案;但对可编程能力的支持,不是很友好。我们是不是可以类比为塞班?
Intel IPU和IPDK和OPI。Intel走的是开放平台的路子,如果类比到智能手机领域,那么IPDK是否可以类比为安卓?
博通计划收购VMWare。博通走的是直接收购现有技术生态的路子。底层芯片公司收购虚拟化技术和生态公司,强强整合,从DPU芯片到系统到生态,在企业和私有云场景,基本上可以通吃。VMWare的虚拟化技术本身,也是全球领先。博通可以通过这次收购,引领虚拟化相关技术发展趋势。现在收购还未成功,说类比苹果iOS还为时尚早,未来发展,继续观察。
从CPU到ASIC,越来越多的不同领域/不同场景的处理引擎。而且即使是同一领域或场景,不同厂家的实现架构也会完全不同。领域或场景越来越碎片化,构建生态越来越困难。系统的设计,逐步从硬件定义软件,转向软件定义硬件。这也符合目前“软件定义一切”的大趋势。 此外,需要软件原生支持硬件加速。软件在架构设计的时候就要区分控制平面和计算平面,实现两者分离,然后把计算平面下沉到硬件。 当异构处理器的引擎架构越来越多,(不同厂家)芯片数量越来越多,所处的环境(云网边端)也越来越多,需要构建高效的、标准的、开放的生态体系。
审核编辑 :李倩
-
处理器
+关注
关注
68文章
20381浏览量
255636 -
cpu
+关注
关注
68文章
11375浏览量
226427 -
NVIDIA
+关注
关注
14文章
5727浏览量
110298 -
数据中心
+关注
关注
18文章
5848浏览量
75252
原文标题:类似智能手机的发展,数据中心将进入完全可编程时代
文章出处:【微信号:算力基建,微信公众号:算力基建】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录

探索UPSD3212A/C/CV:集成8032 MCU、USB与可编程逻辑的闪存可编程系统设备
跳线架在数据中心的应用与优化策略
Altera与Arm深化合作以共筑AI数据中心高效可编程新方案
确保稳定供电的IT6600大功率可编程直流电源

10AX022C3U19I2SG现场可编程门阵列(FPGA)芯片
AI数据中心,正在将光纤产业带入新的时代

Zynq全可编程片上系统详解
数据中心发展的三大驱动力
LMK3H0102无基准可编程时钟发生器
核芯互联发布超低抖动可编程晶体振荡器CLG9501
睿海光电以高效交付与广泛兼容助力AI数据中心800G光模块升级
中型数据中心中的差分晶体振荡器应用与匹配方案
可编程SLIC语音芯片哪家好?




评论