 浅析Slub分配器的设计需求与设计思想
浅析Slub分配器的设计需求与设计思想

slab分配器设计的需求
在Linux内核的内存子系统中,伙伴系统无疑处于内存管理的核心地带,但是如果将内存管理从逻辑上分层,它的位置则处于最底层。Buddy是所有物理内存的管家,不论使用何种接口申请内存都要经由伙伴系统进行分配。但是,伙伴系统管理的物理内存是以页为单位,以4K页为例,它也包含了4096个字节。但是无论是内核自己还是用户程序,在日常的使用中都很少会需要使用四千多字节大小的内存。试想如果我们仅需要为10个字符的字符串分配内存,但是伙伴系统却给了我们一页,那这一页剩余没有使用的内存就浪费了,而且这个浪费近乎奢侈。除了浪费的问题, 还有一个更需要关心的问题是,在这样的分配情况下,如果分配非常频繁,系统可能很快就会面临严重的碎片化问题。因为频繁使用的数据结构也会频繁的分配和释放,加速生产内存碎片。另外,直接调用伙伴系统的操作对系统的数据和指令高速缓存也有很大的影响。所以,基于以上的原因,也源于现实需求,内核需要一种轻量的、快速的、灵活的新型内存分配器,最主要的是,它可以提供小块内存的分配。为了实现这样的小内存分配器,Sun公司的J.Bonwick首先在Solaris 2.4中设计并实现了slab分配器,并对其开源。在Linux中也实现了具有相同的基本设计思想的同名分配器slab。
slab、slob和slub关系
slab、slob和slub都是小内存分配器,slab是slob和slub实现的基础,而slob和slub是针对slab在不同场景下的优化版本。在slab引入Linux的很多年内,其都是Linux内核管理对象缓冲区的主流算法。并且由于slab的实现非常复杂,很长一段时间内都少有对它的改动。随着多处理器的发展和NUMA架构的广泛应用,slab的不足也逐渐显现。slab的缓存队列管理复杂,其用于管理的数据结构存储开销大,对NUMA支持复杂,slab着色机制效果不明显。这些不足让slab很难在两种场景下提供最优的性能:小型嵌入式系统和配备有大量物理内存的大规模并行系统。对于小型嵌入式系统来说,slab分配器的代码量和复杂性都太高;对于大规模并行系统,slab用于自身管理的数据结构就需要占用很多G字节内存。针对slab的不足,内核开发人员Christoph Lameter在在内核版本2.6开发期间,引入了新的Slub分配器。Slub简化了slab一些复杂的设计,但保持slab的基本设计思想。同时,一种新的针对小型嵌入式系统的分配器slob也被引入,为了适应嵌入式系统的特点,slob进行了特别的优化,以大幅减少代码量(slob只有大约600行代码)。
slab层在内存管理子系统的层次
slab层可以理解为一个通用层,其包含了slab、slob和slub,至于底层具体使用哪种分配器可以通过配置内核选项进行选择。对于内核的其他模块,则不需要关注底层使用了哪个分配器。因为为了保证内核的其他模块都可以无缝迁移到Slub/slob,所有分配器的接口都是相同的,它们都实现了一组特定的接口用于内存分配。下图为Slab层在内存管理中的层次图:
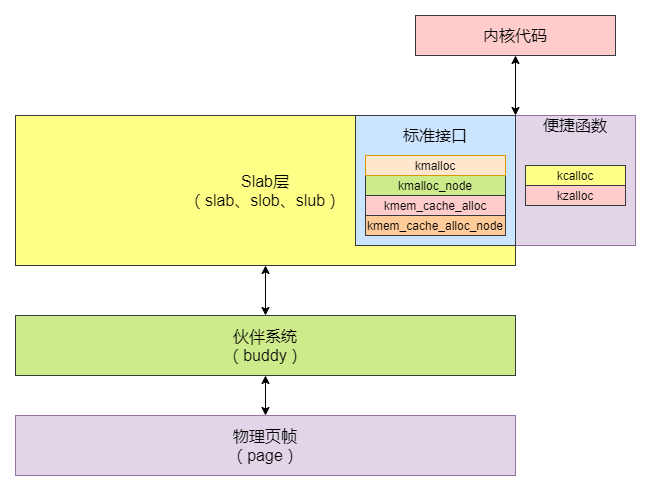
逻辑上看,slab层位于伙伴系统之上。因为Buddy是最底层的分配器,Slub需要先向Buddy申请内存,而不能越过Buddy获取page。从Buddy申请到内存后,Slub才可以对其进行自己的操作。
slub分配器框架
下图是在读完宋牧春大侠的《图解Slub》后,我也总结了一张Slub分配器框架图,可以大致的看到Slub的框架。Slub的框架如下图(图片很大,可以放大):
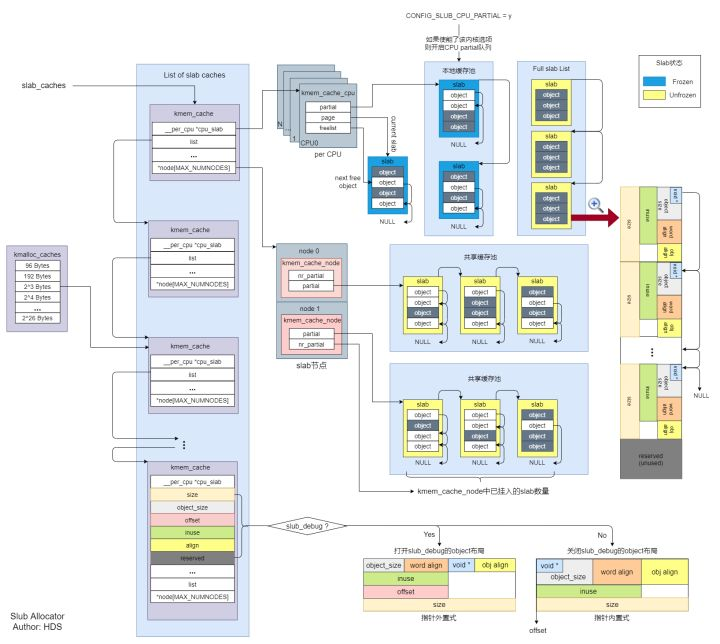
这篇文章中用了一个通俗易懂的例子来介绍Slub的工作原理,我觉的这个例子很恰当,所以这里继续借举一下。
每个数组元素对应一种大小的内存,可以把一个kmem_cache结构体看做是一个特定大小内存的零售商,整个Slub系统中有很多个这样的零售商,每个“零售商”只“零售”特定大小的内存,例如:有的“零售商”只"零售"8Byte大小的内存,有的只”零售“16Byte大小的内存。——引自luken.《linux内核内存管理slub算法(一)原理》
Slub的工作原理和日常生产生活的产销环节很类似,所以为了清晰直观的看到其工作原理,我把这个过程画了一幅图来表示,如下图:
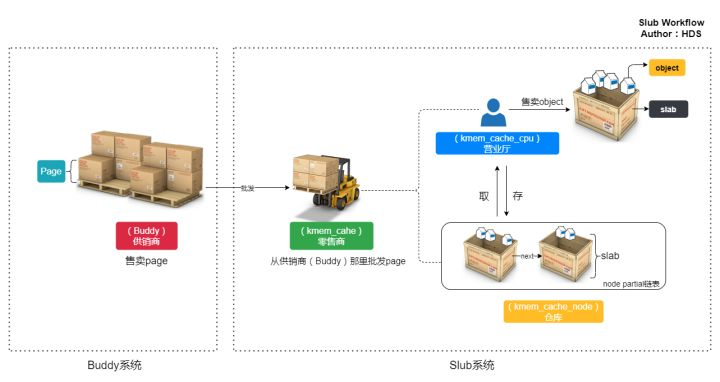
每个零售商(kmem_cache)有两个“部门”,一个是“仓库”:kmem_cache_node,一个“营业厅”:kmem_cache_cpu。“营业厅”里只保留一个slab,只有在营业厅(kmem_cache_cpu)中没有空闲内存的情况下才会从仓库中换出其他的slab。所谓slab就是零售商(kmem_cache)批发的连续的整页内存,零售商把这些整页的内存分成许多小内存,然后分别“零售”出去,一个slab可能包含多个连续的内存页。slab的大小和零售商有关。——引自luken.《linux内核内存管理slub算法(一)原理》
总的来说,Slub就相当于零售商,它从伙伴系统“批发”内存,然后再零售出去。
slub的重要数据结构
- kmem_cache
structkmem_cache{
structkmem_cache_cpu__percpu*cpu_slab;
/*Usedforretrivingpartialslabsetc*/
unsignedlongflags;
unsignedlongmin_partial;
/*size=object_size+对象后面下个空闲对象的指针的size*/
intsize;/*Thesizeofanobjectincludingmetadata*/
intobject_size;/*Thesizeofanobjectwithoutmetadata*/
/*object首地址+offset=下一个空闲对象的指针地址*/
intoffset;/*Freepointeroffset.*/
intcpu_partial;/*Numberofpercpupartialobjectstokeeparound*/
/*
*oo表示存放最优slab的order和object的数量
*低16位表示对象数,高16位表示slab的order
*/
structkmem_cache_order_objectsoo;
/*Allocationandfreeingofslabs*/
structkmem_cache_order_objectsmax;
/*
*最小slab只需要足够存放一个对象。当设备长时间运行以后,内存碎片化严重,
*分配连续物理页很难成功,如果分配最优slab失败,就分配最小slab。
*/
structkmem_cache_order_objectsmin;
gfp_tallocflags;/*gfpflagstouseoneachalloc*/
intrefcount;/*Refcountforslabcachedestroy*/
void(*ctor)(void*);
intinuse;/*Offsettometadata*/
intalign;/*Alignment*/
//当slab长度不是对象长度的整数倍的时候,尾部有剩余部分,保存在reserved中
intreserved;/*Reservedbytesattheendofslabs*/
constchar*name;/*Name(onlyfordisplay!)*/
structlist_headlist;/*Listofslabcaches*/
intred_left_pad;/*Leftredzonepaddingsize*/
#ifdefCONFIG_SYSFS
structkobjectkobj;/*Forsysfs*/
#endif
#ifdefCONFIG_MEMCG
structmemcg_cache_paramsmemcg_params;
intmax_attr_size;/*forpropagation,maximumsizeofastoredattr*/
#ifdefCONFIG_SYSFS
structkset*memcg_kset;
#endif
#endif
#ifdefCONFIG_NUMA
/*
*Defragmentationbyallocatingfromaremotenode.
*/
intremote_node_defrag_ratio;
#endif
#ifdefCONFIG_SLAB_FREELIST_RANDOM
unsignedint*random_seq;
#endif
#ifdefCONFIG_KASAN
structkasan_cachekasan_info;
#endif
structkmem_cache_node*node[MAX_NUMNODES];/*每个NUMA节点都有一个kmem_cache_node*/
};
根据是否打开Slub Debug,next object指针可以有两种方式放置,如果打开了Slub Debug,则采用指针外置式;反之,采用指针内置式。两种指针放置方式如下图:
- 指针外置式
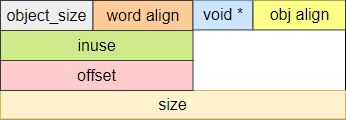
- 指针内置式
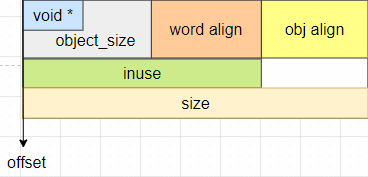
指针内置式的方法实际上是复用了object的前8个字节,因为在object被分配出去之前,这一段内存具体存放什么内容并不重要,所以可以利用这一段内存来保存下一个free object的地址。
- kmem_cache_cpu
structkmem_cache_cpu{
/*指向下一个空闲的object,用于快速找到可用对象*/
void**freelist;/*Pointertonextavailableobject*/
/*
*要保证tid和kmem_cache是由同一个CPU访问。
*开启了内核抢占后,访问tid和kmem_cache的CPU可能不是同一个CPU,
*所以要检查是否匹配,直到它们是由同一个CPU进行访问
*/
unsignedlongtid;/*Globallyuniquetransactionid*/
/*指向当前使用的slab*/
structpage*page;/*Theslabfromwhichweareallocating*/
/*指向当前cpu上缓存的部分空闲slab链表*/
structpage*partial;/*Partiallyallocatedfrozenslabs*/
#ifdefCONFIG_SLUB_STATS
/*
*记录对slab操作的状态变化,这个stat非常重要,
*通过这个stat就大概了解object从申请到释放经过了哪些步骤
*/
unsignedstat[NR_SLUB_STAT_ITEMS];
#endif
};
- kmem_cache_node
structkmem_cache_node{
spinlock_tlist_lock;
/*此处省略掉SLAB的配置*/
#ifdefCONFIG_SLUB
/*挂入kmem_cache_node中的slab数量*/
unsignedlongnr_partial;
/*指向当前内存节点上的部分空闲slab链表*/
structlist_headpartial;
#ifdefCONFIG_SLUB_DEBUG
atomic_long_tnr_slabs;
atomic_long_ttotal_objects;
structlist_headfull;
#endif
#endif
};
page中描述Slub信息的字段:
structpage{
/*如果flag设置成PG_slab,表示页属于slub分配器*/
unsignedlongflags;
union{
structaddress_space*mapping;
/*指向当前slab中第一个object*/
void*s_mem;/*slabfirstobject*/
atomic_tcompound_mapcount;/*firsttailpage*/
};
union{
pgoff_tindex;/*Ouroffsetwithinmapping.*/
/*指向当前slab中第一个空闲的object*/
void*freelist;/*sl[aou]bfirstfreeobject*/
};
union{
unsignedcounters;
struct{
union{
atomic_t_mapcount;
unsignedintactive;/*SLAB*/
struct{/*SLUB*/
/*该slab中已经分配使用的object数量*/
unsignedinuse:16;
/*该slab中的所有object数量*/
unsignedobjects:15;
/*
*如果slab在kmem_cache_cpu中,表示处于冻结状态;
*如果slab在kmem_cache_node的部分空闲slab链表中,表示处于解冻状态
*/
unsignedfrozen:1;
};
intunits;/*SLOB*/
};
atomic_t_refcount;
};
};
union{
/*作为链表节点加入到kmem_cache_node的部分空闲slab链表中
structlist_headlru;/*Pageoutlist*/
structdev_pagemap*pgmap;
struct{/*slubpercpupartialpages*/
structpage*next;/*Nextpartialslab*/
intpages;/*Nrofpartialslabsleft*/
intpobjects;/*Approximate#ofobjects*/
};
structrcu_headrcu_head;
struct{
unsignedlongcompound_head;/*Ifbitzeroisset*/
unsignedintcompound_dtor;
unsignedintcompound_order;
};
};
union{
unsignedlongprivate;
structkmem_cache*slab_cache;/*SL[AU]B:Pointertoslab*/
};
......
}
Slub的分配过程
Slub的分配流程大致如下:首先从kmem_cache_cpu中分配,如果没有则从kmem_cache_cpu的partial链表分配,如果还没有则从kmem_cache_node中分配,如果kmem_cache_node中也没有,则需要向伙伴系统申请内存。
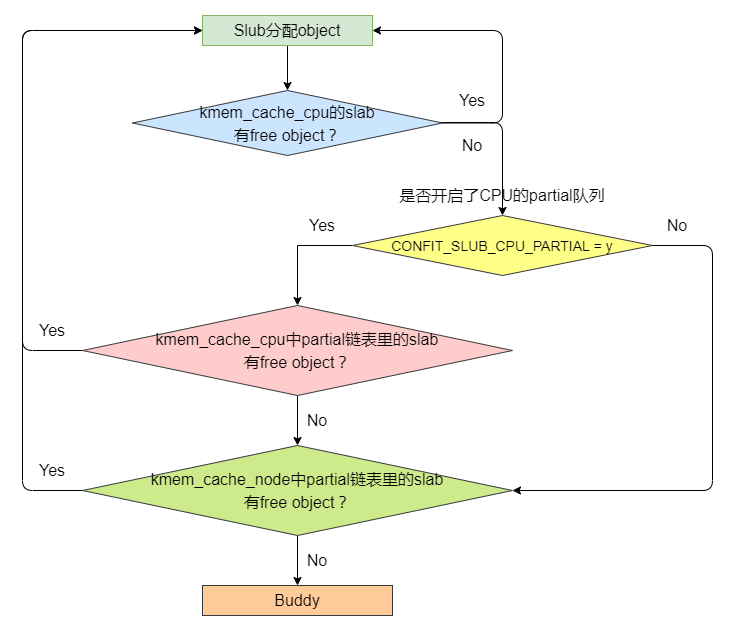
Slub的分配接口是kmem_cache_malloc()。其分配object的流程大概如下:首先在kmem_cache_cpu所使用的slab中查找free object,如果当前slab中有free object,则返回这个object。如果当前slab没有free object,就要看Slub是否开启了kmem_cache_cpu的Partial队列,如果开启了partial队列,就在Partial队列中查看有没有free object的slab,如果有的话就选定这个slab,并返回其free object。如果kmem_cache_cpu的partial链表中也没有拥有free object的slab,则在kmem_cache_node中查找。如果kmem_cache_node中的slab有free object,则选定这个slab并返回free object。如果kmem_cache_node中也没有free object,则需要向伙伴系统申请内存,制作新的slab。
创建slab缓存(kmem_cache)的函数分析
斗胆分析一下slab缓存的创建过程,新手小白分析内核代码,分析的可能不够深度和完整,如有不对还请各路高手指教,提前谢过。
函数调用流程:
kmem_cache_create()
——>kmem_cache_create_usercopy()
——>create_cache()
——>__kmem_cache_create()
——>kmem_cache_open()
下面是每个函数的主干分析,代码有精简。
kmem_cache_create():
kmem_cache_create()里继续调用了kmem_cache_create_usercopy()。
kmem_cache_create(){
returnkmem_cache_create_usercopy(name,size,align,flags,0,0,ctor);
}
kmem_cache_create_usercopy():
kmem_cache_create_usercopy(){
structkmem_cache*s=NULL;
constchar*cache_name;
/*
*Someallocatorswillconstraintthesetofvalidflagstoasubset
*ofallflags.WeexpectthemtodefineCACHE_CREATE_MASKinthis
*case,andwe'lljustprovidethemwithasanitizedversionofthe
*passedflags.
*/
flags&=CACHE_CREATE_MASK;
/*定义这个缓存的名字,用于在/proc/slabinfo中显示*/
cache_name=kstrdup_const(name,GFP_KERNEL);
/*kmem_cache结构,并返回其地址*/
s=create_cache(cache_name,size,
calculate_alignment(flags,align,size),
flags,useroffset,usersize,ctor,NULL,NULL);
returns;
}
create_cache():
create_cache(){
structkmem_cache*s;
interr;
/*为kmem_cache结构申请一段内存并清零*/
s=kmem_cache_zalloc(kmem_cache,GFP_KERNEL);
/*初始化kmem_cache结构的部分成员*/
s->name=name;
s->size=s->object_size=object_size;
s->align=align;
s->ctor=ctor;
s->useroffset=useroffset;
s->usersize=usersize;
/*核心函数,slub/slab/slob都实现了这个函数*/
err=__kmem_cache_create(s,flags);
/*将新创建的kmem_cache加入slabcaches链表*/
list_add(&s->list,&slab_caches);
returns;
}
__kmem_cache_create():
__kmem_cache_create(){
interr;
/*在kmem_cache_open中处理剩余的结构成员,如min_partial、cpu_partial等*/
err=kmem_cache_open(s,flags);
}
kmem_cache_open():
kmem_cache_open(){
/*设置kmem_cache中的min_partial,它表示kmem_cache_node中partial链表可挂入的slab数量*/
set_min_partial(s,ilog2(s->size)/2);
/*设置kmem_cache中的cpu_partial,它表示percpupartial上所有slab中freeobject总数*/
set_cpu_partial(s);
/*为每个节点分配kmem_cache_node*/
if(!init_kmem_cache_nodes(s))
gotoerror;
/*为kmem_cache_cpu变量创建每CPU副本*/
if(alloc_kmem_cache_cpus(s))
return0;
}
分配对象(object)的函数分析
函数调用流程:
kmem_cache_alloc()
——>slab_alloc()
——>slab_alloc_node()
——>__slab_alloc()
——>___slab_alloc()
kmem_cache_alloc():
kmem_cache_alloc(){
/*直接调用slab_alloc*/
void*ret=slab_alloc(s,gfpflags,_RET_IP_);
returnret;
}
slab_alloc():
slab_alloc(){
returnslab_alloc_node(s,gfpflags,NUMA_NO_NODE,addr);
}
slab_alloc_node():
slab_alloc_node(){
void*object;
structkmem_cache_cpu*c;
structpage*page;
redo:
/*
*要保证tid和kmem_cache是由同一个CPU访问。但是如果配置了CONFIG_PREEMPT = y,
*即开启了内核抢占后,访问tid和kmem_cache的CPU可能不是同一个CPU,所以要检查
*是否匹配,直到它们是由同一个CPU进行访问。
*
*内核态抢占的时机是:
*1.中断处理函数返回内核空间之前会检查请求重新调度的标志(TIF_NEED_RESCHED),
*如果置位则调用preempt_schedule_irq()执行抢占。
* 2. 当内核从non-preemptible(禁止抢占)状态变成preemptible(允许抢占)的时候。
*/
do{
tid=this_cpu_read(s->cpu_slab->tid);/*访问当前CPU的perCPU变量的副本的tid*/
c=raw_cpu_ptr(s->cpu_slab);
}while(IS_ENABLED(CONFIG_PREEMPT)&&/*检查是否开启了内核抢占*/
unlikely(tid!=READ_ONCE(c->tid)));
barrier();/*内存屏障,消除指令乱序执行的影响*/
object=c->freelist;/*下一个freeobject的地址*/
page=c->page;/*当前使用的slab*/
if(unlikely(!object||!node_match(page,node))){
/*调用核心函数__slab_alloc()*/
object=__slab_alloc(s,gfpflags,node,addr,c);
stat(s,ALLOC_SLOWPATH);
}else{
void*next_object=get_freepointer_safe(s,object);
if(unlikely(!this_cpu_cmpxchg_double(
s->cpu_slab->freelist,s->cpu_slab->tid,
object,tid,
next_object,next_tid(tid)))){
note_cmpxchg_failure("slab_alloc",s,tid);
gotoredo;
}
prefetch_freepointer(s,next_object);
stat(s,ALLOC_FASTPATH);
}
maybe_wipe_obj_freeptr(s,object);
/*如果gfpflags标志需要对object对象的内存清零*/
if(unlikely(slab_want_init_on_alloc(gfpflags,s))&&object)
memset(object,0,s->object_size);
slab_post_alloc_hook(s,gfpflags,1,&object);
returnobject;
}
__slab_alloc():
__slab_alloc(){
void*p;
unsignedlongflags;
/*
*关中断。关闭当前处理器上的所有中断处理
*
*local_irq_save()将当前的中断状态(开或关)
*保存在flags中然后再禁用处理器上的中断。
*
*与local_irq_save不同,local_irq_disable()
*不保存状态而关闭本地处理器的中断服务。
*/
local_irq_save(flags);
#ifdefCONFIG_PREEMPT
/*
*在关中断之前,可能已经被抢占并被调度在不同的CPU上,
*所以需要重新加载CPU区域的指针。
*/
c=this_cpu_ptr(s->cpu_slab);
#endif
/*调用核心函数___slab_alloc()*/
p=___slab_alloc(s,gfpflags,node,addr,c);
/*
*恢复本地处理器的中断。
*
*local_irq_restore()将local_irq_save()保存的状态值(flags)恢复,
*注意是恢复之前的中断状态,不一定会开启中断。如果之前的状态是
*开中断,就打开中断;如果之前的状态是关中断,就关闭中断。
*而local_irq_enable()会无条件开启中断,所以可能会破坏之前的中
*断环境。所以local_irq_restore()比local_irq_enable()更安全。
*/
local_irq_restore(flags);
returnp;
}
slub的frozen(冻结)和unfrozen(解冻)
如果cpu1的kcmem_cache_cpu的slab是frozen, 那么cpu1可以从该slab中取出或放回obj,但是cpu2不能从该slab中取obj, 只能把obj还给该slab。另外,cpu partial上的slab都是frozen状态。node partial上的slab都是unfrozen。耗尽kmem_cache_cpu的slab的obj后解冻slab。
审核编辑:刘清
-
处理器
+关注
关注
68文章
20378浏览量
255600 -
Linux
+关注
关注
88文章
11854浏览量
219822 -
分配器
+关注
关注
0文章
218浏览量
27456 -
LINUX内核
+关注
关注
1文章
321浏览量
23323 -
Slub
+关注
关注
0文章
1浏览量
798
原文标题:Slub分配器的来龙去脉
文章出处:【微信号:yikoulinux,微信公众号:一口Linux】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
2 - 18GHz 2 路威尔金森功率分配器(PDW06407):小身材大性能
MAX9174/MAX9175:670MHz LVDS 1:2 分配器的卓越性能与应用
Mi-Wave 608系列8路功率分配器
2026年3月分配器芯片方案白皮书
深入剖析 LTC6954:高性能时钟分配器的卓越之选
解析CDCL1810:高性能时钟分配器的技术剖析与应用指南
CDCE62005:高性能时钟发生器与分配器的深度剖析
深入解析CDCL1810A:高性能时钟分配器的卓越之选
低成本有源射频分配器ADA4304-3/ADA4304-4:特性、应用与设计要点
802-4-0.600功率分配器/合成器
802-2-0.670功率分配器/合成器


低损耗双向功率分配器/合路器 2.2–2.8 GHz skyworksinc

五路有源功率分配器 skyworksinc



评论