 高频系列:单词拆分问题
高频系列:单词拆分问题

140.单词拆分II(困难)

之前手把手带你刷二叉树(纲领篇)把递归穷举划分为「遍历」和「分解问题」两种思路,其中「遍历」的思路扩展延伸一下就是回溯算法,「分解问题」的思路可以扩展成动态规划算法。
我在手把手带你刷二叉树(思路篇)对一些二叉树问题进行举例,同时给出「遍历」和「分解问题」两种思路的解法,帮大家借助二叉树理解更高级的算法设计思想。
当然,这种思维转换不止局限于二叉树相关的算法,本文就跳出二叉树类型问题,来看看实际算法题中如何把问题抽象成树形结构,从而进行「遍历」和「分解问题」的思维转换,从回溯算法顺滑地切换到动态规划算法。
先说句题外话,前文动态规划核心框架详解说,标准的动态规划问题一定是求最值的,因为动态规划类型问题有一个性质叫做「最优子结构」,即从子问题的最优解推导出原问题的最优解。
但在我们平常的语境中,就算不是求最值的题目,只要看见使用备忘录消除重叠子问题,我们一般都称它为动态规划算法。严格来讲这是不符合动态规划问题的定义的,说这种解法叫做「带备忘录的 DFS 算法」可能更准确些。不过咱也不用太纠结这种名词层面的细节,既然大家叫的顺口,就叫它动态规划也无妨。
本文讲解的两道题目也不是求最值的,但依然会把他们的解法称为动态规划解法,这里提前跟大家说下这里面的细节,免得细心的读者疑惑。其他不多说了,直接看题目吧。
单词拆分 I
首先看下力扣第 139 题「单词拆分」:

函数签名如下:
booleanwordBreak(Strings,ListwordDict) ;
这是一道非常高频的面试题,我们来思考下如何通过「遍历」和「分解问题」的思路来解决它。
先说说「遍历」的思路,也就是用回溯算法解决本题。回溯算法最经典的应用就是排列组合相关的问题了,不难发现这道题换个说法也可以变成一个排列问题:
现在给你一个不包含重复单词的单词列表wordDict和一个字符串s,请你判断是否可以从wordDict中选出若干单词的排列(可以重复挑选)构成字符串s。
这就是前文回溯算法秒杀排列组合问题的九种变体中讲到的最后一种变体:元素无重可复选的排列问题,前文我写了一个permuteRepeat函数,代码如下:
List>res=newLinkedList<>();
LinkedListtrack=newLinkedList<>();
//元素无重可复选的全排列
publicList>permuteRepeat(int[]nums){
backtrack(nums);
returnres;
}
//回溯算法核心函数
voidbacktrack(int[]nums){
//basecase,到达叶子节点
if(track.size()==nums.length){
//收集根到叶子节点路径上的值
res.add(newLinkedList(track));
return;
}
//回溯算法标准框架
for(inti=0;i< nums.length; i++) {
//做选择
track.add(nums[i]);
//进入下一层回溯树
backtrack(nums);
//取消选择
track.removeLast();
}
}
给这个函数输入nums = [1,2,3],输出是 3^3 = 27 种可能的组合:
[
[1,1,1],[1,1,2],[1,1,3],[1,2,1],[1,2,2],[1,2,3],[1,3,1],[1,3,2],[1,3,3],
[2,1,1],[2,1,2],[2,1,3],[2,2,1],[2,2,2],[2,2,3],[2,3,1],[2,3,2],[2,3,3],
[3,1,1],[3,1,2],[3,1,3],[3,2,1],[3,2,2],[3,2,3],[3,3,1],[3,3,2],[3,3,3]
]
这段代码实际上就是遍历一棵高度为N + 1的满N叉树(N为nums的长度),其中根到叶子的每条路径上的元素就是一个排列结果:
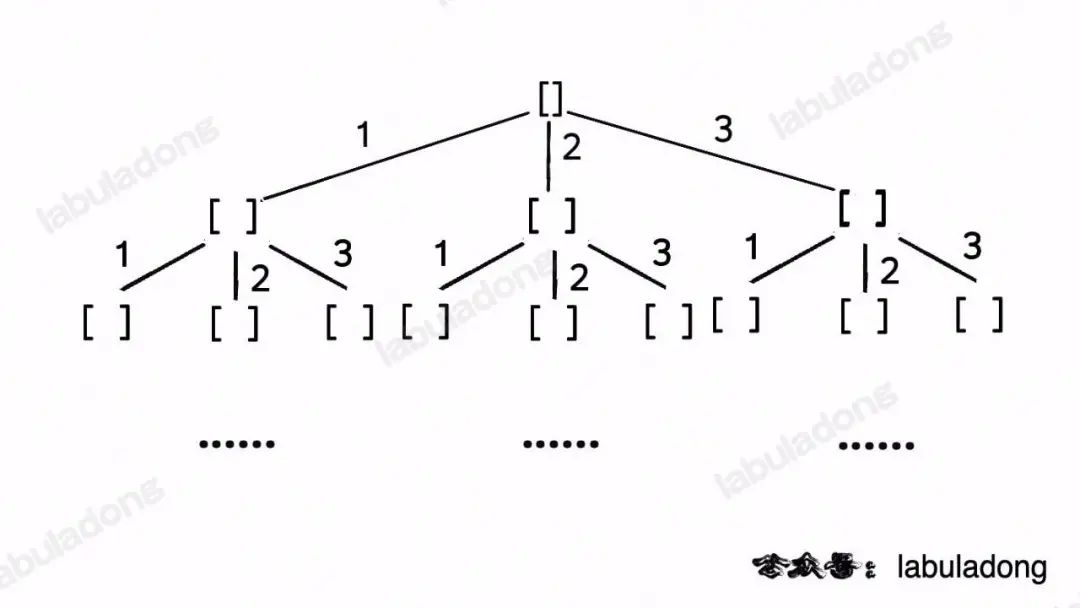
类比一下,本文讲的这道题也有异曲同工之妙,假设wordDict = ["a", "aa", "ab"], s = "aaab",想用wordDict中的单词拼出s,其实也面对着类似的一棵M叉树,M为wordDict中单词的个数,你需要做的就是站在回溯树的每个节点上,看看哪个单词能够匹配s[i..]的前缀,从而判断应该往哪条树枝上走:
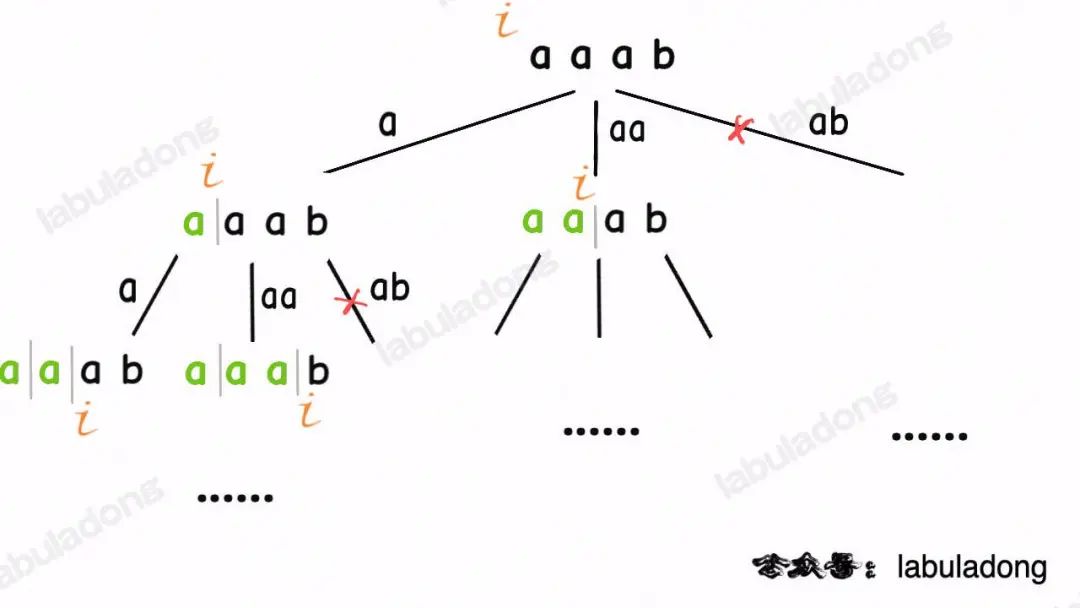
然后,按照前文回溯算法框架详解所说,你把backtrack函数理解成在回溯树上游走的一个指针,维护每个节点上的变量i,即可遍历整棵回溯树,寻找出匹配s的组合。
回溯算法解法代码如下:
ListwordDict;
//记录是否找到一个合法的答案
booleanfound=false;
//记录回溯算法的路径
LinkedListtrack=newLinkedList<>();
//主函数
publicbooleanwordBreak(Strings,ListwordDict) {
this.wordDict=wordDict;
//执行回溯算法穷举所有可能的组合
backtrack(s,0);
returnfound;
}
//回溯算法框架
voidbacktrack(Strings,inti){
//basecase
if(found){
//如果已经找到答案,就不要再递归搜索了
return;
}
if(i==s.length()){
//整个s都被匹配完成,找到一个合法答案
found=true;
return;
}
//回溯算法框架
for(Stringword:wordDict){
//看看哪个单词能够匹配s[i..]的前缀
intlen=word.length();
if(i+len<= s.length()
&& s.substring(i, i + len).equals(word)) {
//找到一个单词匹配s[i..i+len)
//做选择
track.addLast(word);
//进入回溯树的下一层,继续匹配s[i+len..]
backtrack(s,i+len);
//撤销选择
track.removeLast();
}
}
}
这段代码就是严格按照回溯算法框架写出来的,应该不难理解,但这段代码无法通过所有测试用例,我们按照之前算法时空复杂度使用指南中讲到的方法来分析一下它的时间复杂度。
递归函数的时间复杂度的粗略估算方法就是用递归函数调用次数(递归树的节点数) x 递归函数本身的复杂度。对于这道题来说,递归树的每个节点其实就是对s进行的一次切割,那么最坏情况下s能有多少种切割呢?
长度为N的字符串s中共有N - 1个「缝隙」可供切割,每个缝隙可以选择「切」或者「不切」,所以s最多有O(2^N)种切割方式,即递归树上最多有O(2^N)个节点。
当然,实际情况可定会好一些,毕竟存在剪枝逻辑,但从最坏复杂度的角度来看,递归树的节点个数确实是指数级别的。
那么backtrack函数本身的时间复杂度是多少呢?主要的时间消耗是遍历wordDict寻找匹配s[i..]的前缀的单词:
//遍历wordDict的所有单词
for(Stringword:wordDict){
//看看哪个单词能够匹配s[i..]的前缀
intlen=word.length();
if(i+len<= s.length()
&& s.substring(i, i + len).equals(word)) {
//找到一个单词匹配s[i..i+len)
//...
}
}
设wordDict的长度为M,字符串s的长度为N,那么这段代码的最坏时间复杂度是O(MN)(for 循环O(M),Java 的substring方法O(N)),所以总的时间复杂度是O(2^N * MN)。
这里顺便说一个细节优化,其实你也可以反过来,通过穷举s[i..]的前缀去判断wordDict中是否有对应的单词:
//注意,要转化成哈希集合,提高contains方法的效率
HashSetwordDict=newHashSet<>(wordDict);
//遍历s[i..]的所有前缀
for(intlen=1;i+len<= s.length(); len++) {
//看看wordDict中是否有单词能匹配s[i..]的前缀
Stringprefix=s.substring(i,i+len);
if(wordDict.contains(prefix)){
//找到一个单词匹配s[i..i+len)
//...
}
}
这段代码和刚才那段代码的结果是一样的,但这段代码的时间复杂度变成了O(N^2),和刚才的代码不同。
到底哪样子好呢?这要看题目给的数据范围。本题说了1 <= s.length <= 300, 1 <= wordDict.length <= 1000,所以O(N^2)的结果较小,这段代码的实际运行效率应该稍微高一些,这个是一个细节的优化,你可以自己做一下,我就不写了。
不过即便你优化这段代码,总的时间复杂度依然是指数级的O(2^N * N^2),是无法通过所有测试用例的,那么问题出在哪里呢?
比如输入wordDict = ["a", "aa"], s = "aaab",算法无法找到一个可行的组合,所以一定会遍历整棵回溯树,但你注意这里面会存在重复的情况:
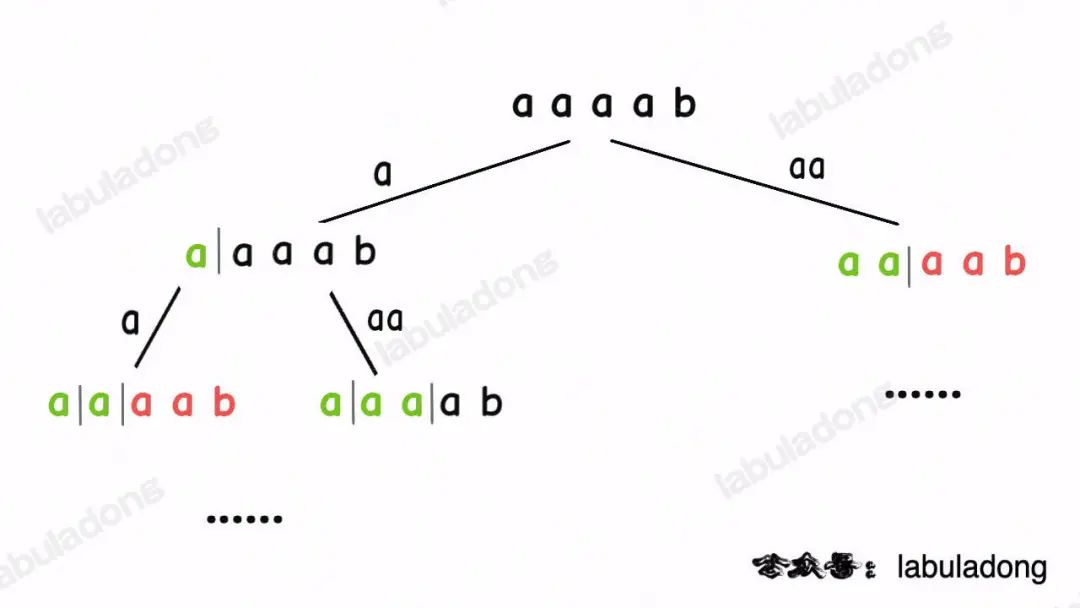
图中标红的这两部分,虽然经历了不同的切分,但是切分得出的结果是相同的,所以这两个节点下面的子树也是重复的,即存在冗余计算,极端情况下会消耗大量时间。
如何消除冗余计算呢?这就要稍微转变一下思维模式,用「分解问题」的思维模式来考虑这道题。
我们刚才以排列组合的视角思考这个问题,现在我们换一种视角,思考一下是否能够把原问题分解成规模更小,结构相同的子问题,然后通过子问题的结果计算原问题的结果。
对于输入的字符串s,如果我能够从单词列表wordDict中找到一个单词匹配s的前缀s[0..k],那么只要我能拼出s[k+1..],就一定能拼出整个s。
换句话说,我把规模较大的原问题wordBreak(s[0..])分解成了规模较小的子问题wordBreak(s[k+1..]),然后通过子问题的解反推出原问题的解。
有了这个思路就可以定义一个dp函数,并给出该函数的定义:
//定义:返回 s[i..]是否能够被拼出
intdp(Strings,inti);
//计算整个s是否能被拼出,调用dp(s,0)
有了这个函数定义,就可以把刚才的逻辑大致翻译成伪码:
ListwordDict;
//定义:返回 s[i..]是否能够被拼出
intdp(Strings,inti){
//basecase,s[i..]是空串
if(i==s.length()){
returntrue;
}
//遍历wordDict,
//看看哪些单词是s[i..]的前缀
for(Strnigword:wordDict){
ifword是s[i..]的前缀{
intlen=word.length();
//只要s[i+len..]可以被拼出,
//s[i..]就能被拼出
if(dp(s,i+len)==true){
returntrue;
}
}
}
//所有单词都尝试过,无法拼出整个s
returnfalse;
}
类似之前讲的回溯算法,dp函数中的 for 循环也可以优化一下:
//注意,用哈希集合快速判断元素是否存在
HashSetwordDict;
//定义:返回 s[i..]是否能够被拼出
intdp(Strings,inti){
//basecase,s[i..]是空串
if(i==s.length()){
returntrue;
}
//遍历s[i..]的所有前缀,
//看看哪些前缀存在wordDict中
for(intlen=1;i+len<= s.length(); len++) {
ifwordDict中存在s[i..len){
//只要s[i+len..]可以被拼出,
//s[i..]就能被拼出
if(dp(s,i+len)==true){
returntrue;
}
}
}
//所有单词都尝试过,无法拼出整个s
returnfalse;
}
对于这个dp函数,指针i的位置就是「状态」,所以我们可以通过添加备忘录的方式优化效率,避免对相同的子问题进行冗余计算。最终的解法代码如下:
//用哈希集合方便快速判断是否存在
HashSetwordDict;
//备忘录,-1代表未计算,0代表无法凑出,1代表可以凑出
int[]memo;
//主函数
publicbooleanwordBreak(Strings,ListwordDict) {
//转化为哈希集合,快速判断元素是否存在
this.wordDict=newHashSet<>(wordDict);
//备忘录初始化为-1
this.memo=newint[s.length()];
Arrays.fill(memo,-1);
returndp(s,0);
}
//定义:s[i..]是否能够被拼出
booleandp(Strings,inti){
//basecase
if(i==s.length()){
returntrue;
}
//防止冗余计算
if(memo[i]!=-1){
returnmemo[i]==0?false:true;
}
//遍历s[i..]的所有前缀
for(intlen=1;i+len<= s.length(); len++) {
//看看哪些前缀存在wordDict中
Stringprefix=s.substring(i,i+len);
if(wordDict.contains(prefix)){
//找到一个单词匹配s[i..i+len)
//只要s[i+len..]可以被拼出,s[i..]就能被拼出
booleansubProblem=dp(s,i+len);
if(subProblem==true){
memo[i]=1;
returntrue;
}
}
}
//s[i..]无法被拼出
memo[i]=0;
returnfalse;
}
这个解法能够通过所有测试用例,我们根据算法时空复杂度使用指南来算一下它的时间复杂度:
因为有备忘录的辅助,消除了递归树上的重复节点,使得递归函数的调用次数从指数级别降低为状态的个数O(N),函数本身的复杂度还是O(N^2),所以总的时间复杂度是O(N^3),相较回溯算法的效率有大幅提升。
单词拆分 II
有了上一道题的铺垫,力扣第 140 题「单词拆分 II」就容易多了,先看下题目:
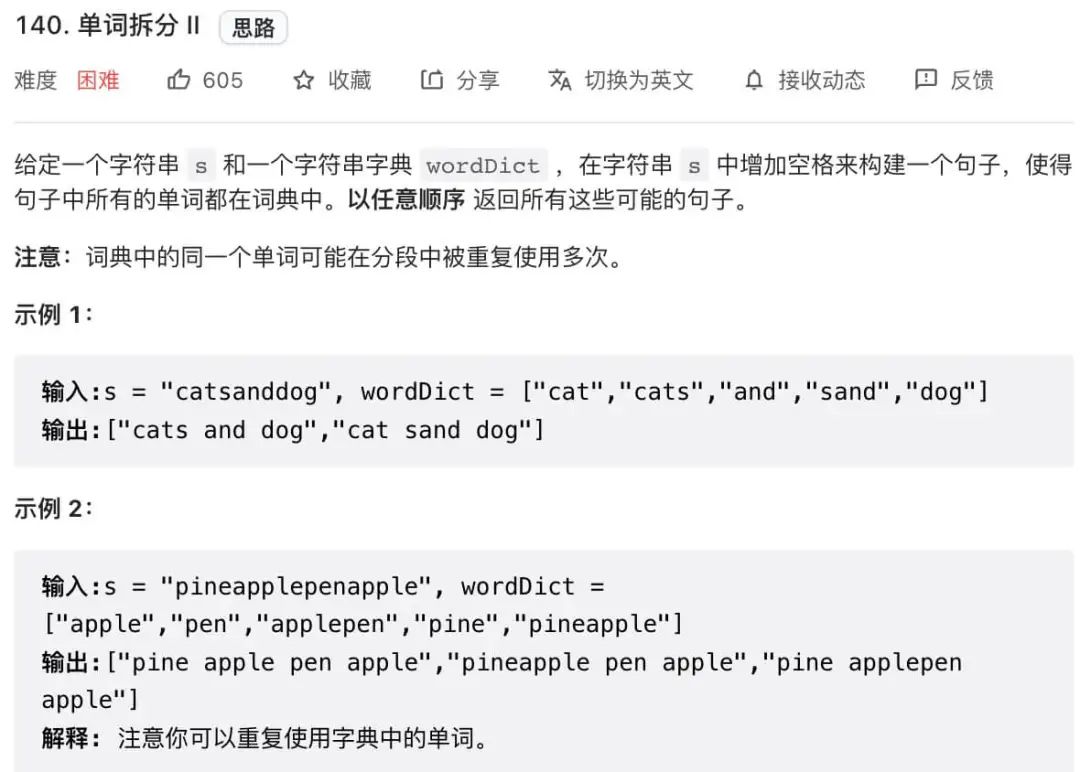
相较上一题,这道题不是单单问你s是否能被拼出,还要问你是怎么拼的,其实只要把之前的解法稍微改一改就可以解决这道题。
上一道题的回溯算法维护一个found变量,只要找到一种拼接方案就提前结束遍历回溯树,那么在这道题中我们不要提前结束遍历,并把所有可行的拼接方案收集起来就能得到答案:
//记录结果
Listres=newLinkedList<>();
//记录回溯算法的路径
LinkedListtrack=newLinkedList<>();
ListwordDict;
//主函数
publicListwordBreak(Strings,ListwordDict) {
this.wordDict=wordDict;
//执行回溯算法穷举所有可能的组合
backtrack(s,0);
returnres;
}
//回溯算法框架
voidbacktrack(Strings,inti){
//basecase
if(i==s.length()){
//找到一个合法组合拼出整个s,转化成字符串
res.add(String.join("",track));
return;
}
//回溯算法框架
for(Stringword:wordDict){
//看看哪个单词能够匹配s[i..]的前缀
intlen=word.length();
if(i+len<= s.length()
&& s.substring(i, i + len).equals(word)) {
//找到一个单词匹配s[i..i+len)
//做选择
track.addLast(word);
//进入回溯树的下一层,继续匹配s[i+len..]
backtrack(s,i+len);
//撤销选择
track.removeLast();
}
}
}
这个解法的时间复杂度和前一道题类似,依然是O(2^N * MN),但由于这道题给的数据规模较小,所以可以通过所有测试用例。
类似的,这个问题也可以用分解问题的思维解决,把上一道题的dp函数稍作修改即可:
HashSetwordDict;
//备忘录
List[]memo;
publicListwordBreak(Strings,ListwordDict) {
this.wordDict=newHashSet<>(wordDict);
memo=newList[s.length()];
returndp(s,0);
}
//定义:返回用 wordDict 构成 s[i..]的所有可能
Listdp(Strings,inti) {
Listres=newLinkedList<>();
if(i==s.length()){
res.add("");
returnres;
}
//防止冗余计算
if(memo[i]!=null){
returnmemo[i];
}
//遍历s[i..]的所有前缀
for(intlen=1;i+len<= s.length(); len++) {
//看看哪些前缀存在wordDict中
Stringprefix=s.substring(i,i+len);
if(wordDict.contains(prefix)){
//找到一个单词匹配s[i..i+len)
ListsubProblem=dp(s,i+len);
//构成s[i+len..]的所有组合加上prefix
//就是构成构成s[i]的所有组合
for(Stringsub:subProblem){
if(sub.isEmpty()){
//防止多余的空格
res.add(prefix);
}else{
res.add(prefix+""+sub);
}
}
}
}
//存入备忘录
memo[i]=res;
returnres;
}
这个解法依然用备忘录消除了重叠子问题,所以dp函数递归调用的次数减少为O(N),但dp函数本身的时间复杂度上升了,因为subProblem是一个子集列表,它的长度是指数级的。
再加上 Java 中用+拼接字符串的效率并不高,且还要消耗备忘录去存储所有子问题的结果,所以这个算法的时间复杂度并不比回溯算法低,依然是指数级别。
综上,我们处理排列组合问题时一般使用回溯算法去「遍历」回溯树,而不用「分解问题」的思路去处理,因为存储子问题的结果就需要大量的时间和空间,除非重叠子问题的数量较多的极端情况,否则得不偿失。
以上就是本文的全部内容,希望你能对回溯思路和分解问题的思路有更深刻的理解。
审核编辑 :李倩
-
代码
+关注
关注
30文章
4977浏览量
74403 -
二叉树
+关注
关注
0文章
74浏览量
13007 -
回溯算法
+关注
关注
0文章
10浏览量
6758
原文标题:高频面试系列:单词拆分问题
文章出处:【微信号:TheAlgorithm,微信公众号:算法与数据结构】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
使用 RT1060 离线学习单词有可能吗
风华叠层片式铁氧体高频磁珠CBF系列在高频段具有优异的EMI抑制效果

高频芯片衰减器 ATS 系列:特性、规格与应用解析
高频芯片衰减器 ATS 系列:特性、应用与电气规格解析
高频芯片衰减器ATS系列:设计与应用详解
高频芯片衰减器 ATS 系列:设计与应用详解
高频芯片衰减器——ATS系列的特性与应用解析
高频芯片衰减器 ATS 系列:特性、规格与应用全解析
高频芯片衰减器 ATS 系列:特性、规格与应用解析
高频芯片衰减器 ATS 系列:特性、规格与应用详解
高频芯片衰减器ATS系列:特性、规格与应用解析
开发者必备,10 分钟搞定 RK3588 PCIE 拆分!

国巨CQ0201系列高频电容:高频电路的小型化高稳定性解决方案

英语单词学习页面+单词朗读实现 -- 【1】页面实现 ##HarmonyOS SDK AI##
Nginx架构拆分集群详解



评论