 利用axi_master接口指令端的几个静态参数的优化技巧
利用axi_master接口指令端的几个静态参数的优化技巧

Vitis HLS 在从Vivaido HLS的升级换代中,以axi_master接口为起点的设计正在变得更易上手,其中很重要的一点就是更多的MAXI端口设计参数可以让用户通过指令传达到。这些参数可以分为两类:
静态参数指标:这些参数会影响内存性能,可以在 C 综合期间的编译时从编译的结果中很清楚地知道,突发读写地长度、数据端口宽度加宽、对齐等。
动态参数指标:这些参数本质上是动态的,取决于系统。例如,与 DDR/HBM 的通信效率在C综合编译时是未知的。 本文给大家提供利用axi_master接口指令端的几个静态参数的优化技巧,从扩展总线接口数量,扩展总线位宽,循环展开等角度入手。最核心的优化思想就是以资源面积换取高带宽的以便并行计算。
熟记这本文几个关键的设计点,让你的HLS内核接口效率不再成为设计的瓶颈! 以上代码在进行了c综合后,我们所有的指针变量都会依据指令的设置映射到axi-master上,但是因为根据指令中所有的端口都绑定到了一条总线gmem上。所以在综合的警告里面会提示:
以上代码在进行了c综合后,我们所有的指针变量都会依据指令的设置映射到axi-master上,但是因为根据指令中所有的端口都绑定到了一条总线gmem上。所以在综合的警告里面会提示:
 当总线数量满足了我们并行读入的要求后,读取数据的位宽就成为了我们优化的方向:
因为读取的数据格式是int类型,所以这里的数据位宽就是32bit。
当总线数量满足了我们并行读入的要求后,读取数据的位宽就成为了我们优化的方向:
因为读取的数据格式是int类型,所以这里的数据位宽就是32bit。
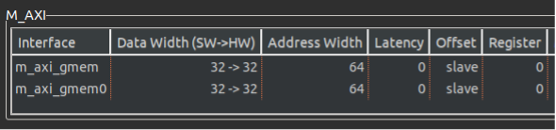 为了能够转移数据传输瓶颈,在Vitis kernel target flow中,数据位宽在512bit的时候能够达到最高的数据吞吐效率。在Vitis HLS 中的新增了 max_widen_bitwidth 选项来自动将较短的数据位宽拼接到设定的较长的数据位宽选项。在这里我们可以将位宽设置到512bit的位宽,但是同时要向编译器说明,原数据位宽和指定的扩展位宽成整数倍关系。这个操作很简单,在数据读取的循环边界上,用(size/16)*16示意编译器即可。
为了能够转移数据传输瓶颈,在Vitis kernel target flow中,数据位宽在512bit的时候能够达到最高的数据吞吐效率。在Vitis HLS 中的新增了 max_widen_bitwidth 选项来自动将较短的数据位宽拼接到设定的较长的数据位宽选项。在这里我们可以将位宽设置到512bit的位宽,但是同时要向编译器说明,原数据位宽和指定的扩展位宽成整数倍关系。这个操作很简单,在数据读取的循环边界上,用(size/16)*16示意编译器即可。
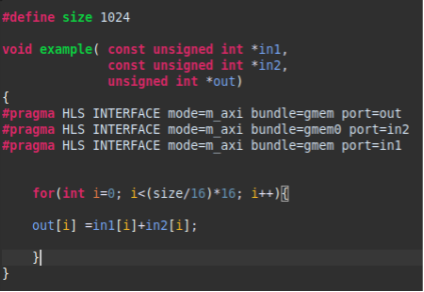 扩展位宽后的结果可以在综合报告的接口部分看到数据位宽已经从32位扩展到512位。
扩展位宽后的结果可以在综合报告的接口部分看到数据位宽已经从32位扩展到512位。
 优化到这一步我们的设计可以进行大位宽的同步读写,但是发现循环的trip count还是执行了1024次, 也就是说虽然位宽拓展到512后,还是一个循环周期计算一次32bit的累加。实际上512bit的数据位宽可以允许16个累加计算并行执行。
优化到这一步我们的设计可以进行大位宽的同步读写,但是发现循环的trip count还是执行了1024次, 也就是说虽然位宽拓展到512后,还是一个循环周期计算一次32bit的累加。实际上512bit的数据位宽可以允许16个累加计算并行执行。
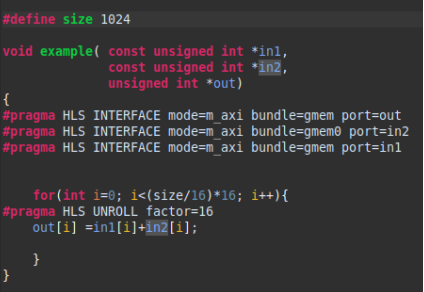
 为了完成并行度的优化,我们需要在循环中添加系数为16的unroll 指令,这样就可以生成16个并行执行累加计算的硬件模块以及线程。
为了完成并行度的优化,我们需要在循环中添加系数为16的unroll 指令,这样就可以生成16个并行执行累加计算的硬件模块以及线程。
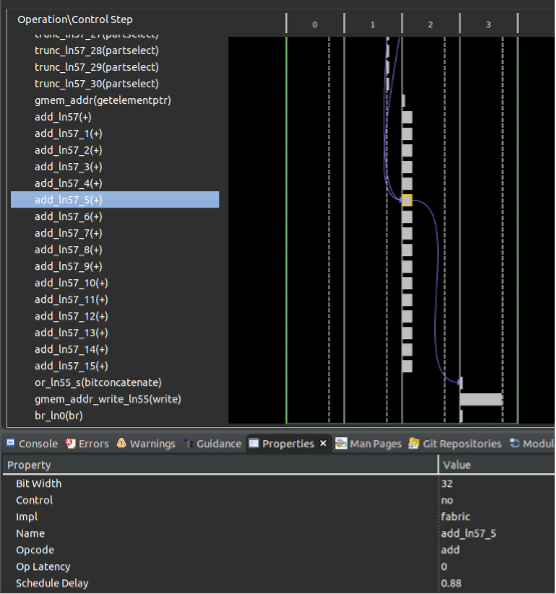
 在循环中并行执行的累加操作,我们可以从schedule viewer中观察到并行度,可以从bind_op窗口中观察到operation实现所使用的硬件资源,可以从循环的trip_count 降低到了1024/16=64个周期,以及大大缩小的模块的整个latency中得以证明。
在循环中并行执行的累加操作,我们可以从schedule viewer中观察到并行度,可以从bind_op窗口中观察到operation实现所使用的硬件资源,可以从循环的trip_count 降低到了1024/16=64个周期,以及大大缩小的模块的整个latency中得以证明。
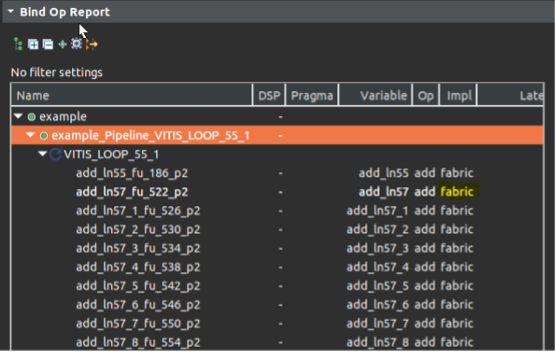 最后我们比较了一下并行执行16个累加计算前后的综合结果,可以发现由于有数据的按位读写拆分拼接等操作,整个模块的延迟虽然没有缩短为16分之一,但是缩短为5分之一也是性能的极大提升了。
最后我们比较了一下并行执行16个累加计算前后的综合结果,可以发现由于有数据的按位读写拆分拼接等操作,整个模块的延迟虽然没有缩短为16分之一,但是缩短为5分之一也是性能的极大提升了。
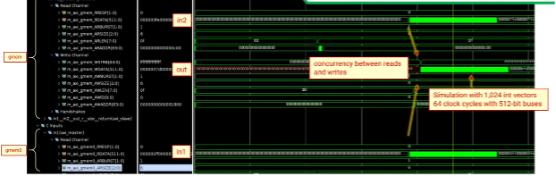
 最后的最后,RTL级别的co-sim仿真才让我们更加确信了数据的从两个并行读写,循环执行的周期减小至了64个时钟周期。
最后的最后,RTL级别的co-sim仿真才让我们更加确信了数据的从两个并行读写,循环执行的周期减小至了64个时钟周期。
 以上内容是设计者在AXI总线接口中使用传统的数据类型时,提升数据传输效率和带宽的一揽子有效方法:
第一,扩展总线接口数量,以便并行读写。第二,扩展总线位宽,增加读写带宽。第三,循环展开,例化更多计算资源以便并行计算。
本文的优化方式还是基于内核设计本身的,下一篇文章,我们将使用Alveo板卡做一些突发传输的实验,深度定制传输需求,以真实仿真波形和测得的传输速度,从系统级别强化我们对于突发读写效率的认知。
审核编辑 :李倩
以上内容是设计者在AXI总线接口中使用传统的数据类型时,提升数据传输效率和带宽的一揽子有效方法:
第一,扩展总线接口数量,以便并行读写。第二,扩展总线位宽,增加读写带宽。第三,循环展开,例化更多计算资源以便并行计算。
本文的优化方式还是基于内核设计本身的,下一篇文章,我们将使用Alveo板卡做一些突发传输的实验,深度定制传输需求,以真实仿真波形和测得的传输速度,从系统级别强化我们对于突发读写效率的认知。
审核编辑 :李倩
动态参数指标:这些参数本质上是动态的,取决于系统。例如,与 DDR/HBM 的通信效率在C综合编译时是未知的。 本文给大家提供利用axi_master接口指令端的几个静态参数的优化技巧,从扩展总线接口数量,扩展总线位宽,循环展开等角度入手。最核心的优化思想就是以资源面积换取高带宽的以便并行计算。
熟记这本文几个关键的设计点,让你的HLS内核接口效率不再成为设计的瓶颈!
以上代码在进行了c综合后,我们所有的指针变量都会依据指令的设置映射到axi-master上,但是因为根据指令中所有的端口都绑定到了一条总线gmem上。所以在综合的警告里面会提示:
WARNING: [HLS 200-885] The II Violation in module 'example_Pipeline_VITIS_LOOP_55_1' (loop 'VITIS_LOOP_55_1'):Unable to schedule bus request operation ('gmem_load_1_req', example.cpp:56) on port 'gmem' (example.cpp:56) due to limited memory ports(II = 1). Please consider using a memory core with more ports or partitioning the array.
因为在axi-master总线上最高只能支持一个读入和一个写出同时进行,如果绑定到一条总线则无法同时从总线读入两个数据,所以最终的循环的II=2。解决这个问题的方法就是用面积换速度,我们实例化两条axi总线gmem和gmem0,最终达到II=1。
当总线数量满足了我们并行读入的要求后,读取数据的位宽就成为了我们优化的方向:
因为读取的数据格式是int类型,所以这里的数据位宽就是32bit。
为了能够转移数据传输瓶颈,在Vitis kernel target flow中,数据位宽在512bit的时候能够达到最高的数据吞吐效率。在Vitis HLS 中的新增了 max_widen_bitwidth 选项来自动将较短的数据位宽拼接到设定的较长的数据位宽选项。在这里我们可以将位宽设置到512bit的位宽,但是同时要向编译器说明,原数据位宽和指定的扩展位宽成整数倍关系。这个操作很简单,在数据读取的循环边界上,用(size/16)*16示意编译器即可。
扩展位宽后的结果可以在综合报告的接口部分看到数据位宽已经从32位扩展到512位。
优化到这一步我们的设计可以进行大位宽的同步读写,但是发现循环的trip count还是执行了1024次, 也就是说虽然位宽拓展到512后,还是一个循环周期计算一次32bit的累加。实际上512bit的数据位宽可以允许16个累加计算并行执行。
为了完成并行度的优化,我们需要在循环中添加系数为16的unroll 指令,这样就可以生成16个并行执行累加计算的硬件模块以及线程。
在循环中并行执行的累加操作,我们可以从schedule viewer中观察到并行度,可以从bind_op窗口中观察到operation实现所使用的硬件资源,可以从循环的trip_count 降低到了1024/16=64个周期,以及大大缩小的模块的整个latency中得以证明。
最后我们比较了一下并行执行16个累加计算前后的综合结果,可以发现由于有数据的按位读写拆分拼接等操作,整个模块的延迟虽然没有缩短为16分之一,但是缩短为5分之一也是性能的极大提升了。
最后的最后,RTL级别的co-sim仿真才让我们更加确信了数据的从两个并行读写,循环执行的周期减小至了64个时钟周期。
以上内容是设计者在AXI总线接口中使用传统的数据类型时,提升数据传输效率和带宽的一揽子有效方法:
第一,扩展总线接口数量,以便并行读写。第二,扩展总线位宽,增加读写带宽。第三,循环展开,例化更多计算资源以便并行计算。
本文的优化方式还是基于内核设计本身的,下一篇文章,我们将使用Alveo板卡做一些突发传输的实验,深度定制传输需求,以真实仿真波形和测得的传输速度,从系统级别强化我们对于突发读写效率的认知。
审核编辑 :李倩
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
接口
+关注
关注
33文章
9601浏览量
157628 -
静态
+关注
关注
1文章
30浏览量
14862 -
代码
+关注
关注
30文章
4976浏览量
74386
原文标题:开发者分享 | HLS, 巧用AXI_master总线接口指令的定制并提升数据带宽-面积换速度
文章出处:【微信号:Open_FPGA,微信公众号:OpenFPGA】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
热点推荐
[VirtualLab] 倾斜光栅的参数优化及公差分析
导耦合的倾斜光栅设计单入射方向光波导耦合光栅的优化参数优化文档的介绍倾斜光栅的高级配置利用界面配置光栅结构光栅级次分析器
发表于 04-22 08:18
利用开源uart2axi4实现串口访问axi总线
,可以实现跨fpga平台使用。利用uart2axi4我们可以通过python,轻松访问axi4_lite_slave寄存器,大大方便fpga工程师进行系统调试和定位bug。

利用蜂鸟E203搭建SoC【1】——AXI总线的配置与板级验证
代码中也提供了icb连接AXI从设备的示例,位于/subsys/ e203_subsys_mems.v文件中,为了避免自己连接造成的错误,可以直接使用这些转换好的AXI-MASTER信号,并将其作为
发表于 10-30 07:35
将e203 例化AXI总线接口
将系统外设总线内部axi接口引出给gpio,注意vivado中gpio地址分配应保证移植
Debug:
通过Xil_Out32函数给gpio的地址写1或者0,注意这里地址是gpio地址也就是核中给
发表于 10-29 06:08
利用拼多多 API 接口,实现拼多多店铺物流时效优化
可以自动化获取物流数据、分析时效瓶颈,并实施针对性优化策略。本文将逐步介绍如何利用这些 API 接口实现物流时效优化,确保内容真实可靠。 1. 理解拼多多 API

利用Arm i8mm指令优化llama.cpp
本文将为你介绍如何利用 Arm i8mm 指令,具体来说,是通过带符号 8 位整数矩阵乘加指令 smmla,来优化 llama.cpp 中 Q6_K 和 Q4_K 量化模型推理。

如何优化可编程电源控制环路参数?
优化可编程电源控制环路参数是提升其动态响应、稳定性和输出精度的关键步骤,需结合理论分析、仿真验证、实验调整三阶段,并重点关注补偿网络设计、参数计算、仿真优化、实验验证等核心环节。以下是
发表于 07-02 15:56

RDMA简介9之AXI 总线协议分析2
这里以功能完备的 AXI4 接口举例说明 AXI4 总线的相关特点。AXI4 总线采用读写通道分离且数据通道与控制通道分离的方式,这样的总线通道使其具有多主多从的连接特性和并行处理
发表于 06-24 18:02
RDMA简介8之AXI 总线协议分析1
AXI 总线是一种高速片内互连总线,其定义于由 ARM 公司推出的 AMBA 协议中,主要用于高性能、高带宽、低延迟、易集成的片内互连需求。AXI4 总线是第四代 AXI 总线,其定义了三种总线
发表于 06-24 18:00
NVMe IP之AXI4总线分析
时,需要通过AXI互联IP(AXI Interconnect)来实现多对多的拓扑结构 ,如图3所示。Interconnect拥有多个 Master/Slave接口,并在内部基于轮询或者
发表于 06-02 23:05
VirtualLab 应用:倾斜光栅的参数优化及公差分析
,也称为RCWA)对倾斜光栅的优化方法。优化后的光栅的衍射效率超过90%。此外,还研究了其对光栅的倾角偏差和圆角边缘的影响。
建模任务
**优化
**
为了为倾斜光栅找到一组优化的
发表于 05-22 08:52
NVMe协议简介之AXI总线
高性能、高带宽、低延时的片内互连需求。AXI4总线则是AXI总线的第四代版本,主要包含三种类型的接口,分别是面向高性能地址映射通信的AXI4接口
发表于 05-17 10:27



评论