 神经网络图需要图流处理器
神经网络图需要图流处理器

随着技术的发展,神经网络处理仍处于起步阶段。因此,仍有一些高层次的问题需要回答。例如,“你如何实际执行神经网络图?”
有几种可能的方法,但是神经网络(都是图)的出现揭示了传统处理器架构中的一些缺陷,这些缺陷并不是为了执行它们而设计的。例如,CPU 和 DSP 按顺序执行工作负载,这意味着必须将 AI 和机器学习工作负载重复写入不可缓存的中间 DRAM。
这种串行处理方法,其中一个任务(或任务的一部分)必须在下一个任务开始之前完成,这会影响延迟、功耗等。而不是一个好办法。图 1 显示了如何在这些传统处理器上执行图形工作负载。
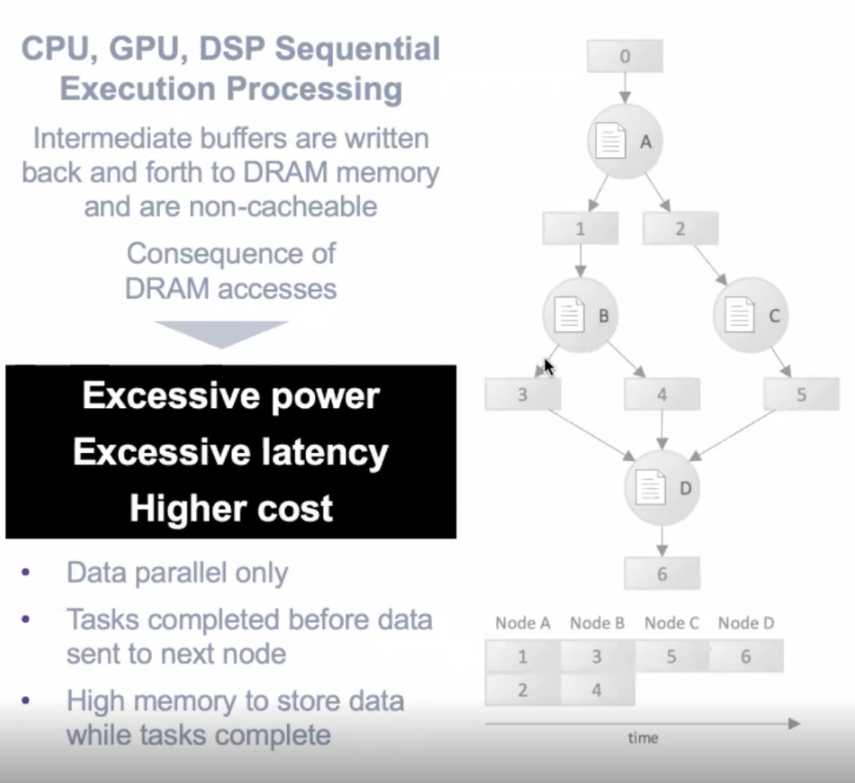
图 1. 神经网络图的串行执行导致高功耗、延迟和整体系统成本。
图中,气泡节点 A、B、C 和 D 代表功函数,而矩形显示每个节点生成的中间结果。Blaize(前身为 ThinCi)战略业务发展副总裁 Richard Terrill 解释了以这种方式处理神经网络图的影响。
“这些中间结果通常非常庞大,将它们存储在芯片上可能非常昂贵,”Terrel 解释说。“你要么做一个非常大的筹码。或者,更常见的是,您将其发送到芯片外,等待它完成。完成后,您可以加载下一个节点并运行它。
“但是发生的情况是,必须在 B 加载并运行后将结果带回芯片上,然后在 C 加载并运行后将两个结果带回芯片上。这里发生了很多片外、片上、片外、片上交易。”
面向图表
随着神经网络技术的使用和应用的增长,最先进的技术必须改变。Blaize 正在开发一种图形流处理器 (GSP) 架构,它认为该架构可以与未来的人工智能和机器学习工作负载一起扩展。
该公司的“完全可编程”芯片包含一系列指令可编程处理器、专用数据缓存和专有硬件调度程序,可为神经网络图带来任务级并行性。如图 2 所示,该架构有助于减少外部存储器访问,而集成 GSP 和专用数学处理器的运行频率仅为数百兆赫以节省电力。
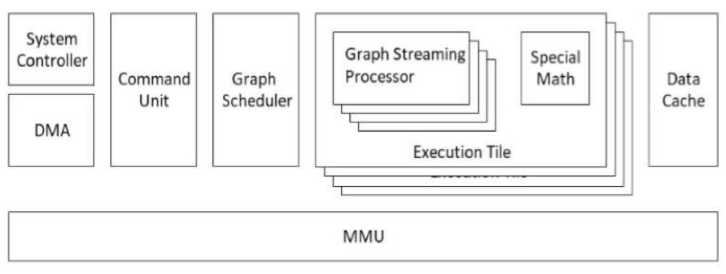
虽然 Blaize 仍然对其 GSP 架构的细节保持不变,但从高层次来看,该技术似乎可以解决当今的许多图形处理挑战。
“机器是底层的核心技术,它旨在高效地实施和运行数据流图,”Terrill 说。“这是一种抽象,但它代表了当今许多非常有趣的问题,要求你能够对其进行不同类型的运算,不同的计算、算术和控制、不同精度的算术、不同运算符的算术、专用数学功能等。
“在里面,如果我们把它打开,我们专有的 SoC 有一系列专有处理器。它们是一个级别的一类 CPU,但它们是由我们的编译器用二进制文件编程的,以便在其中运行,”他补充道。
图 3 显示了如何使用该机器有效地执行图形流处理。如图所示,标记为 0、1、2、3、4、5 和 6 的矩形表示任务平行。数据从第一个并行发送到标记为“A”的气泡节点。从气泡中,它通过一个严重截断的中间缓冲区,允许任务继续执行而不必离开芯片。
从理论上讲,这意味着更低的能耗、更高的性能以及所需内存带宽的大幅减少。所有这些都可以转化为更低的系统成本。
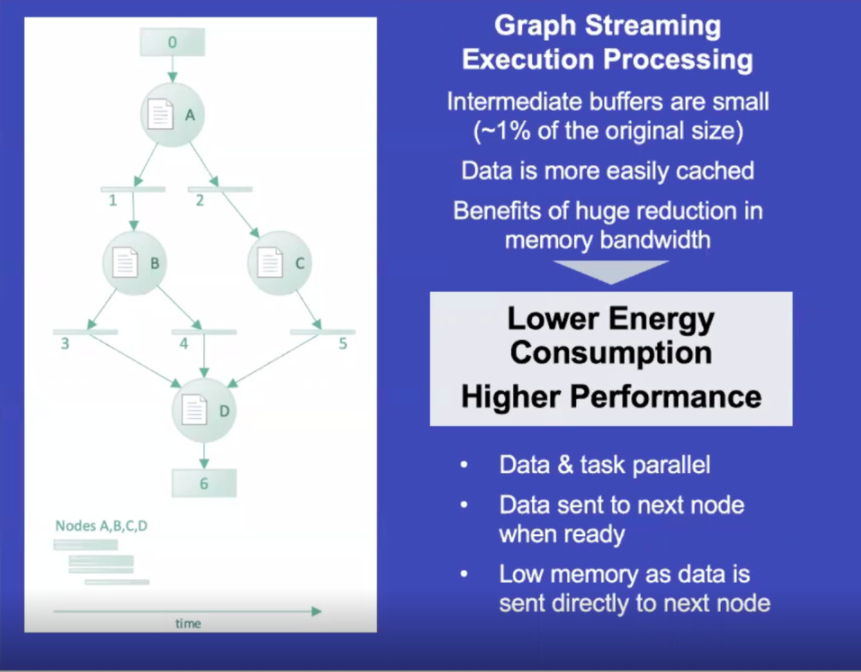
与 Blaize 的 GSP 技术配合使用的专用硬件调度程序允许开发人员利用这种性能,而无需了解目标架构的低级细节,Terrill 指出这是关键,因为没有人可以真正处理这些类型的任务调度。工作量。事实上,调度程序非常高效,它可以在单个时钟周期内基于上下文切换对内核进行重新编程。
调度程序能够通过与实际工作负载执行并行运行流程图的映射来实现这一点
“它可以对传入数据的单个周期以及何时何地运行的中间结果做出决策,”特里尔说。“它不仅是可编程的,它是单周期可重新编程的,并且有很大的不同。您无法使用已修复的内容或使用程序计数器来跟踪正在完成的工作来执行此类工作。对 FPGA 重新编程非常困难。这需要半秒钟,你会失去所有的状态。它永远跟不上人们希望完成事情的这种速度。”
该公司的测试芯片是基于 28 纳米工艺技术开发的。然而,有趣的是,Blaize 计划通过一系列行业标准模块、电路板和系统来生产这项技术。
GSP 的软件方面
图形原生处理器架构当然需要图形原生软件开发工具。在这里,Blaize“毕加索”开发平台允许用户高效地迭代和改变神经网络;量化、修剪和压缩它们;如果需要,甚至可以创建自定义网络层(图 4)。
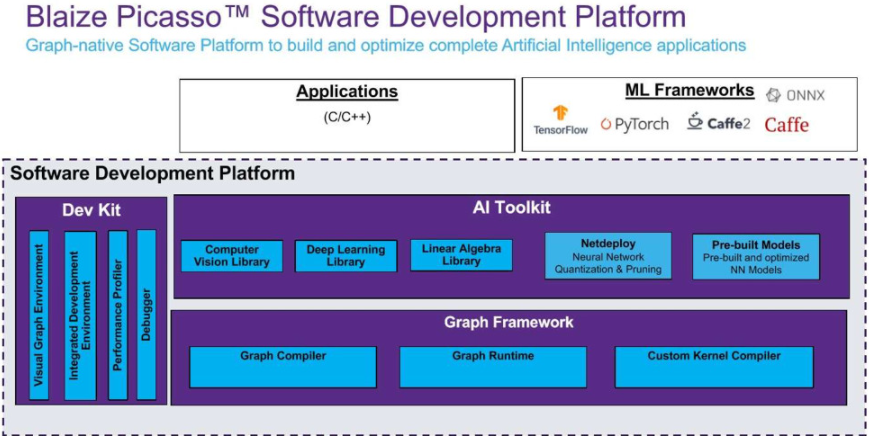
Picaso 支持 ONNX、TensorFlow、PyTorch 和 Caffe 等 ML 框架,基于 OpenVX 并采用类似 C++ 的语言,简化了将应用程序的神经网络部分集成到软件堆栈中的其他组件的过程。图 4 显示了 Picaso 的主要元素——一个帮助开发预处理和后处理指令的 AI 工具包和一个处理编译的图形框架。
有趣的是,在生成可执行文件后,编译器在运行时一直保留数据流图,这允许硬件调度程序执行上述单周期上下文切换。它还自动将工作负载定位到芯片上最高效的内核,以最大限度地提高性能和节能。
但是在上图中更仔细地放大,我们会遇到“NetDeploy”。这是 Blaize 开发的一项技术,用于自动优化现有模型以部署在边缘设备中。
在修剪、压缩和拉出东西的第一遍过程中,它最终成为一个非常循环的问题,”特里尔说。“准确性通常会下降,它会回到训练阶段说,‘好吧,像这样训练它,然后这样做,看看会发生什么。’”
“这不是一个非常确定的过程。这需要很多周期。”
与 OpenVINO 等工具类似,NetDeploy 允许用户指定所需的精度和准确度,并在将模型优化为将在边缘运行的算法时保留这些特征。据 Terrill 称,一位在 GPU 上进行培训并在 FPGA 上进行部署的客户使用 NetDeploy 将模型移植时间从数周缩短到几分钟,同时保持准确性并满足内存占用目标。
描绘未来
在过去的 24 个月中,随着人工智能工作负载变得越来越普遍,并且缩小硅几何尺寸的能力停滞不前,我们看到了许多新颖的架构出现。
Blaize 通过其图形流处理 (GSP) 解决方案提供了一种独特的方法,该解决方案涵盖了计算、人工智能开发和移植软件,很快,甚至可以轻松集成到设计中的硬件。这可能使公司的技术比其他新兴替代品更快地被采用。
审核编辑:郭婷
-
神经网络
+关注
关注
42文章
4842浏览量
108178 -
gpu
+关注
关注
28文章
5271浏览量
136070 -
人工智能
+关注
关注
1820文章
50325浏览量
266959
发布评论请先 登录
为什么 VisionFive V1 板上的 JH7100 中并存 NVDLA 引擎和神经网络引擎?
神经网络的初步认识

自动驾驶中常提的卷积神经网络是个啥?

CNN卷积神经网络设计原理及在MCU200T上仿真测试
NMSIS神经网络库使用介绍
构建CNN网络模型并优化的一般化建议
在Ubuntu20.04系统中训练神经网络模型的一些经验
液态神经网络(LNN):时间连续性与动态适应性的神经网络
神经网络的并行计算与加速技术
无刷电机小波神经网络转子位置检测方法的研究
神经网络专家系统在电机故障诊断中的应用
神经网络RAS在异步电机转速估计中的仿真研究
基于FPGA搭建神经网络的步骤解析




评论