 3D视觉技术内容理解领域的研究进展
3D视觉技术内容理解领域的研究进展

Facebook 的博客详细介绍了其在 3D 内容理解领域的研究进展。

要想解释现实世界,AI 系统必须理解三维视觉场景。而这需要机器人学、导航,甚至增强现实应用等等。2D 图像和视频所描述的场景和对象本身仍是三维的,而真正智能的内容理解系统必须能够从杯子的视频中识别出手柄的几何情况,或者识别出照片前景和背景中的对象。
不久之前,Facebook 发布博客介绍了多个新研究项目的详情,这些项目以不同却互补的方式推进 3D 图像理解领域的当前最优水平。相关研究已被 ICCV 2019 接收,它利用不同类型和数量的训练数据和输入,解决了大量用例和环境中的 3D 内容理解问题。
Mesh R-CNN 是一种新型的当前最优方法,可基于大量 2D 现实世界图像预测出最准确的 3D 形状。该方法利用目标实例分割任务的通用 Mask R-CNN 框架,能够检测出复杂的对象,如椅子腿或者重叠的家具。 利用 Mesh R-CNN 的替代和补充性方法 C3DPO,Facebook 通过解释三维几何,首次在三个基准数据集(涉及超过 14 种对象类别)上实现了大规模非刚性三维形状重建。而该成果的实现仅使用了 2D 关键点,未使用 3D 标注。 Facebook 提出了一种新方法来学习图像和 3D 形状之间的关联,同时大幅减少对标注训练样本的需求。这向着为更多对象类别创建 3D 表征的自监督系统迈出了一步。 Facebook 开发了一种新技术 VoteNet,可对激光雷达等传感器输出的 3D 图像执行目标检测。大部分传统的目标检测系统依赖 2D 图像信号,而 VoteNet 仅基于 3D 点云,且取得了高于之前研究的精度。
这些研究基于使用深度学习预测和定位图像中对象的近期进展,以及执行 3D 形状理解(如体素、点云和网格)的新工具和架构。计算机视觉领域覆盖大量任务,而 3D 理解将对推进 AI 系统更准确地理解、解释现实世界并在其中运行起到核心作用。
在预测无约束受遮挡对象的 3D 形状任务中达到当前最优
感知系统(如 Mask R-CNN)是理解图像的强大通用工具。但是,这些系统只能对 2D 图像执行预测,忽略了世界的 3D 结构。Facebook 利用 2D 感知领域的进展,设计了一个 3D 目标重建模型,该模型可以基于无约束现实世界图像预测 3D 对象形状,而这些图像包含大量视觉难题,如对象被遮挡、杂乱,以及多样化的拓扑结构。向对此类复杂性具备稳健性的目标检测系统添加第三个维度,需要更强大的工程能力,而目前的工程框架阻碍了该领域的进步。

Mesh R-CNN 预测输入图像中的对象实例,并推断其 3D 形状。为了捕捉几何和拓扑的多样性,Mesh R-CNN 首先预测粗糙的体素,然后细化以执行准确的网格预测。
为了解决这些挑战,Facebook 为 Mask R-CNN 的 2D 目标分割系统添加了网格预测部分,从而构建了 Torch3d。这是一个 PyTorch 库,具备高度优化的 3D 算子以实现该系统。Mesh R-CNN 使用 Mask R-CNN 来检测和分类图像中的不同对象,然后利用新的网格预测器推断对象的 3D 形状,该预测器由体素预测和网格细化两个步骤构成,这个两阶段流程可以实现优于之前细粒度 3D 结构预测研究的结果。Torch3d 保证 chamfer distance、可微网格采样和可微渲染器等复杂操作的高效、灵活和模块化实现,从而使得上述流程得以顺利进行。
Facebook 利用 Detectron2 实现 Mesh R-CNN,它使用 RGB 图像作为输入,既能检测对象,也能预测 3D 形状。与 Mask R-CNN 利用监督学习获得强大的 2D 感知能力类似,新方法 Mesh R-CNN 利用完全监督学习(即图像和网格对)学习 3D 预测。在训练阶段中,Facebook 研究人员使用 Pix3D 数据集(包含一万个图像和网格对),该数据集的规模远远小于通常包含数十万图像和对象标注的 2D 基准数据集。
Facebook 在两个数据集上评估 Mesh R-CNN 的性能,均获得了优秀的结果。在 Pix3D 数据集上,Mesh R-CNN 是首个能够同时检测出所有对象类别,并基于多样、杂乱、被遮挡的家具场景估计其完整 3D 形状的系统。之前的研究主要关注在完美剪裁、未受遮挡的图像分割部分上训练得到的模型。在 ShapeNet 数据集上,将体素预测和网格细化结合起来的 Mesh R-CNN 方法的性能比之前的研究高出 7%。

Mesh R-CNN 系统概览。研究人员用 3D 形状推断增强了 Mask R-CNN。
在现实世界中准确预测和重建无约束场景的形状是提升新体验的重要一步,如虚拟现实以及其他形式的远程呈现。不过,收集标注 3D 图像数据要比 2D 图像更加复杂、耗时,这也是 3D 形状预测数据集落后于 2D 数据集的原因。因而,Facebook 探索了不同的方法,尝试利用监督和自监督学习重建 3D 对象。
Mesh R-CNN 相关论文,参见:https://arxiv.org/abs/1906.02739
利用 2D 关键点重建 3D 对象类别
当训练过程中无法获得网格及其对应图像时,对静态对象或场景执行完整重建则无必要,而 Facebook 开发出一种替代方法——C3DPO 系统(Canonical 3D Pose Networks)。该系统构建 3D 关键点模型重建,重建结果堪比使用充足 2D 关键点监督信号获得的当前最优结果。C3DPO 帮助我们用弱监督的方式理解 3D 几何,该系统适合大规模部署。

对于广泛的对象类别,C3DPO 能够基于检测出的 2D 关键点生成 3D 关键点,并准确区分视角变化和形状变化。
2D 关键点追踪对象类别的特定部分(如人体关节或鸟类翅膀),为对象几何及其变形或视角变化提供完整的线索。得到的 3D 关键点很有用,比如可用于建模 3D 人脸和全身网格,以输出更逼真的 VR 头像图。与 Mesh R-CNN 类似,C3DPO 使用具备遮挡和缺失值的无约束图像重建 3D 对象。
C3DPO 是首个利用数千个 2D 关键点,重建包含数十万图像的数据集的方法。该模型在三个数据集(超过 14 种不同非刚性对象类别)上获得了当前最优的重建准确率。
代码地址:https://github.com/facebookresearch/c3dpo_nrsfm
该模型有两个重要创新。首先,给定一组单目 2D 关键点,C3DPO 可以预测对应摄像机视角的参数,以及 3D 关键点的标准位置。其次,Facebook 提出了一种新型正则化技术 canonicalization,它包含一个辅助深度网络,可以与 3D 重建网络一道学习。该技术解决了对 3D 视角和形状执行因式分解导致的模糊性。这两个创新促使更优秀数据统计模型的诞生。
以前,这样的 3D 重建是不可实现的,原因在于之前基于矩阵分解的方法会带来内存限制。与深度网络不同,之前方法无法以「minibatch」机制运行。之前方法在建模变形时利用了多个同步图像,并构建图像与即时 3D 重建结果之间的对应关系,这对硬件有很高要求,此类硬件通常出现在特殊实验室中。而 C3DPO 使得在无法部署 3D 捕捉硬件时也能实现 3D 重建。
C3DPO 相关论文,参见:https://research.fb.com/publications/c3dpo-canonical-3d-pose-networks-for-non-rigid-structure-from-motion/
从图像集中学习像素-表面映射(pixel-to-surface mapping)

该系统学得一个参数化卷积神经网络(CNN),该网络以图像作为输入,并预测像素级标准表面图(per-pixel canonical surface map,表示像素在模板形状上的对应位置点)。2D 图像和 3D 形状之间的标准表面图中的类似颜色表示对应关系。
Facebook 进一步减少了开发通用对象类别 3D 理解系统所需的监督信号。研究人员提出一种利用无标注图像集的方法,这些图像仅具备恰当的自动实例分割。他们没有显式地预测图像的底层 3D 结构,转而处理一个补充性任务:将图像中的像素映射至类别级 3D 形状模板的表面。
该映射不仅可以帮助我们在类别级 3D 形状背景下理解图像,还提供泛化同类对象之间对应关系的能力。例如,人们在看到下图左侧突出显示的鸟喙时,可以很轻松地在右图中找出对应点的位置。

这是因为我们直观上理解这些实例之间的共享 3D 结构。Facebook 提出的将图像像素映射至标准 3D 表面的新方法帮助学得系统也具备这种能力。对该方法在不同实例上迁移对应关系的效果进行评估后,研究人员发现其准确率是之前未利用图像底层 3D 结构的自监督方法的 2 倍。
使得模型在监督信号大量减少的情况下还能学习的关键要素是:从像素到 3D 表面的映射,辅以从 3D 表面到像素的逆运算,可形成一个完整循环。Facebook 提出的新方法使这一关键要素得以运行,且学习过程中仅需使用免费无标注、具备恰当实例分割结果的公共图像集。得到的系统还可即拿即用,与其他自上而下的 3D 预测方法一道应用,提供像素级 3D 理解。
代码地址:https://github.com/nileshkulkarni/csm/
上述视频中移动车辆的颜色是一致的,这表面该系统对正在移动和旋转的对象生成不变的像素级嵌入。这种一致性可扩展到特定实例,也可用于需要理解不同对象共性的场景中。
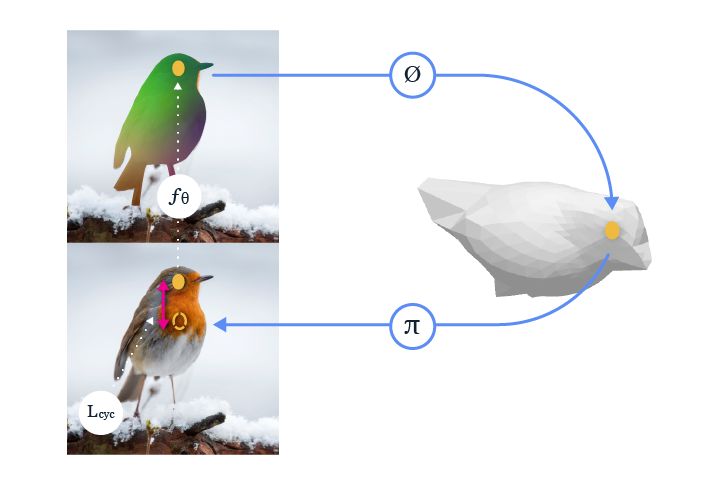
Facebook 提出的方法没有直接学习两张图像之间的 2D 对应关系,而是学习 2D 到 3D 的对应,并确保 3D 到 2D 重新投影的一致性,这种一致性循环可作为学习 2D 到 3D 对应关系的监督信号。
例如,如果我们训练一个系统去学习坐在椅子上的正确位置或者握杯子的合适位置,则学到的表征应在系统理解坐在另外一把椅子的合适位置或如何握住另一只杯子的时候依然有用。此类任务不仅能够深化对传统 2D 图像和视频内容的理解,还可以通过迁移对象表征提升 AR/VR 体验。关于标准表面映射的更多信息,参见:https://research.fb.com/publications/canonical-surface-mapping-via-geometric-cycle-consistency/
在目前的 3D 系统中,改进目标检测的基础要素
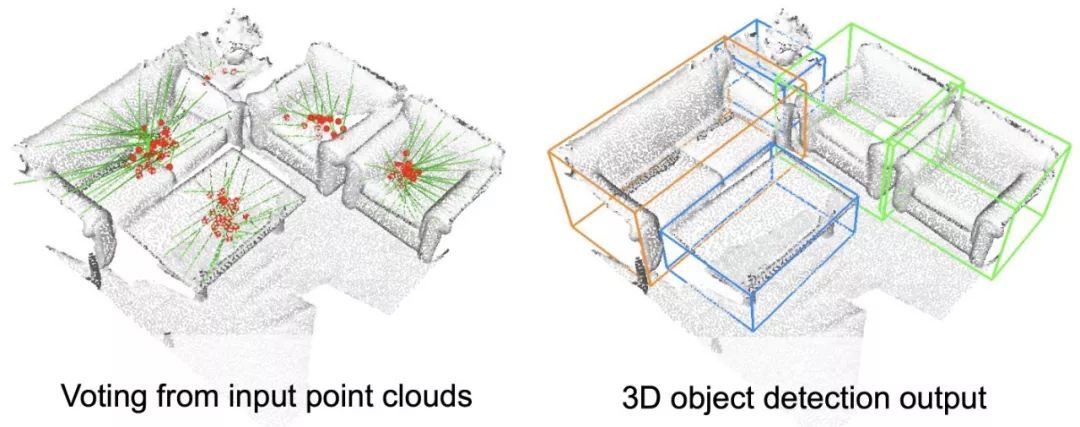
随着前沿技术(如扫描 3D 空间的自动智能体和系统)的发展,我们需要推进针对 3D 数据的目标检测机制。在这些案例中,3D 场景理解系统需要了解场景中有哪些对象以及它们的位置,以支持导航等高级任务。Facebook 对已有系统进行了改进,提出了高度准确的端到端 3D 目标检测网络 VoteNet,该网络专为点云设计,相关论文《Deep Hough Voting for 3D Object Detection in Point Clouds》获得了 ICCV 2019 最佳论文提名。与依赖 2D 图像信号的传统系统不同,VoteNet 是首批仅依赖 3D 点云数据的系统。该方法比之前研究更加高效,识别准确率也更高。
VoteNet 开源地址:https://github.com/facebookresearch/votenet
VoteNet 在 3D 目标检测任务上的性能超过了之前所有方法,获得了当前最优 3D 检测结果,在 SUN RGB-D 和 ScanNet 数据集上的性能较之之前方法至少提升了 3.7 和 18.4 mAP。VoteNet 优于之前方法的原因是:仅使用几何信息,不依赖标准彩色图像。
VoteNet 设计简单,模型紧凑,效率高,对全景图像的处理速度约为 100 毫秒,内存占用也比之前方法小。该方法以深度相机获得的 3D 点云作为输入,返回对象的 3D 边界框,且标明对象的语义类别。
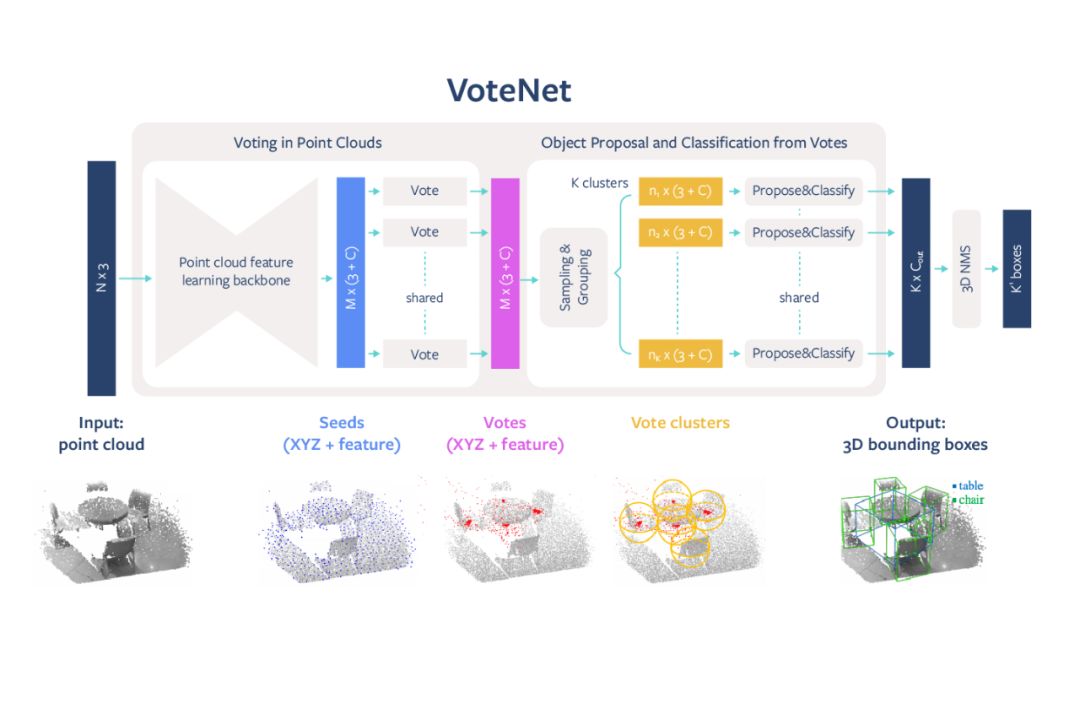
VoteNet 架构图示。
受经典 Hough voting 算法启发,Facebook 提出了一种投票机制。利用该机制可生成紧邻对象中心的新点,将这些点分组并聚合以生成边界框候选。使用通过深度神经网络学得的投票基本思路,一组 3D 种子点投票竞争对象中心,以恢复对象的位置和类别。
随着 3D 扫描仪在现实中的使用,尤其是在自动驾驶汽车、生物医学等领域的普遍应用,通过定位和分类 3D 场景中的对象来实现对 3D 内容的语义理解变得尤为重要。向 2D 摄像头补充一些更先进的深度相机传感器以方便 3D 识别,这可以帮助我们捕捉到任意给定场景的更稳健视图。使用 VoteNet,系统可以更好地识别出场景中的主要对象,并支持放置虚拟对象、导航和 LiveMap 构建等任务。
开发对现实世界具备更多了解的系统
3D 计算机视觉领域存在很多开放性研究问题,Facebook 正在试验多个问题陈述、技术和监督方法,正如过去探索推动 2D 理解的最佳方式一样。随着数字世界更多地使用 3D 图像和浸入式 AR/VR 体验等产品,我们需要持续推进更准确理解视觉场景并与其中对象互动的复杂系统的开发。 当 AI 系统与其他感官结合起来时,如触觉和自然语言理解,这些系统(如虚拟助手)可以更加无缝地发挥作用。这一前沿研究帮助我们向着构建和人类一样更直观理解三维世界的 AI 系统更进了一步。
本文介绍的研究论文已被 ICCV 2019 接收,还有一些新的计算机视觉工作,包括:
SlowFast:使用不同帧率的输入从视频中提取信息的方法。
TensorMask:使用密集的滑动窗口技术执行目标分割的方法。
审核编辑 :李倩
-
Facebook
+关注
关注
3文章
1432浏览量
59348 -
计算机视觉
+关注
关注
9文章
1715浏览量
47712 -
3D视觉
+关注
关注
4文章
490浏览量
29309
原文标题:一文看尽 Facebook 3D视觉技术研究进展
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
奥比中光3D视觉产品助力北美智慧物流应用落地
友思特技术 | 智能iToF技术:开启高性价比3D视觉新纪元

基于3D视觉引导的移动式复合机器人设计:智能自动化革命的核心技术

2025 3D机器视觉的发展趋势

3D 视觉系统供应商全景解析:技术迭代与国产力量的崛起
奥比中光3D视觉技术赋能IROS 2025研究成果
奥比中光领跑韩国机器人3D视觉市场
索尼与MIIIX幕象科技达成3D内容合作
季丰电子邀您相约2025国际3D视觉感知与应用大会
iTOF技术,多样化的3D视觉应用
索尼与VAST达成3D业务合作
3D视觉传感器如何变革工业领域
如何提高3D成像设备的部署和设计优势
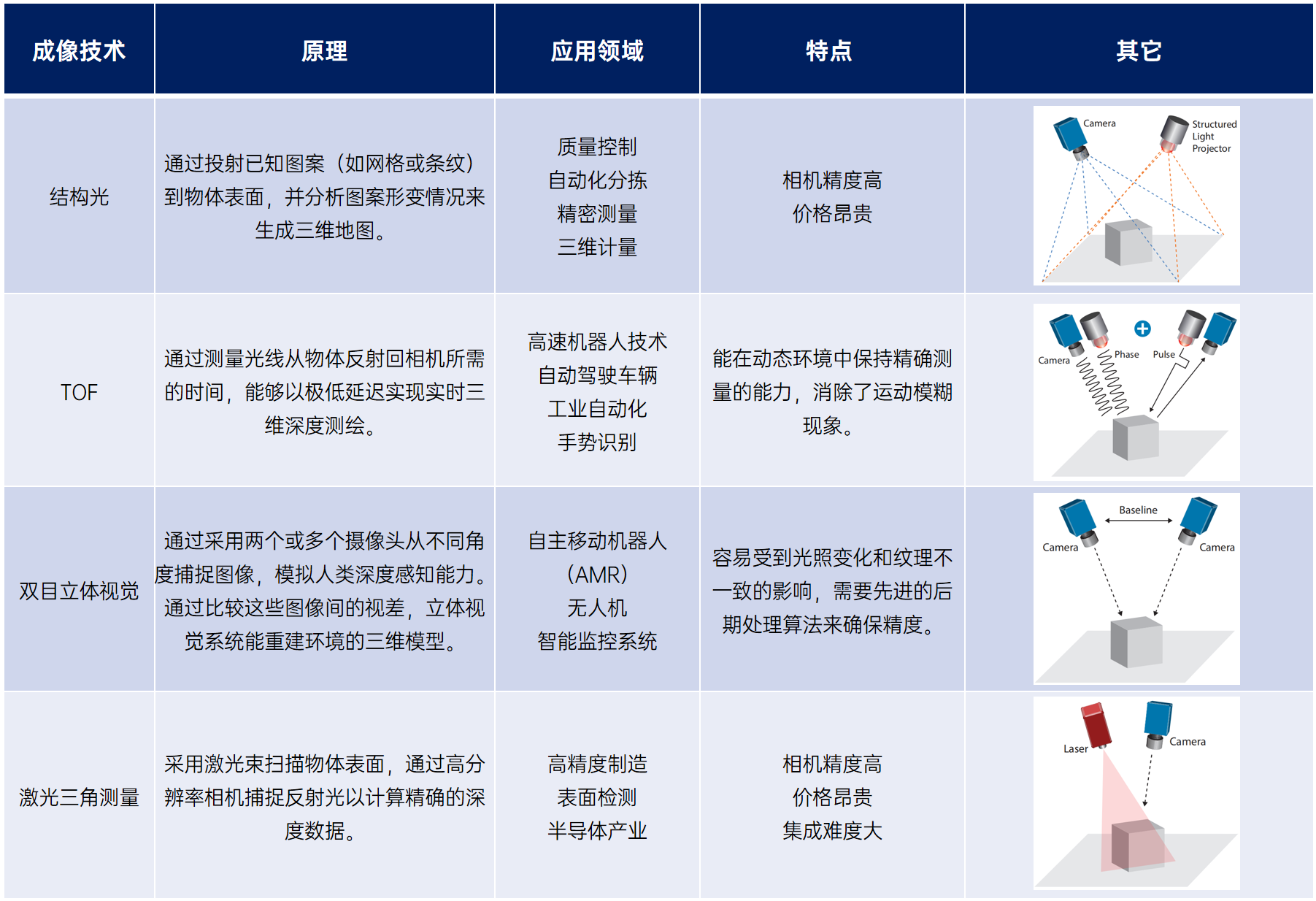
海伯森3D闪测传感器,工业检测领域的高精度利器




评论