 使用NVIDIA VPI降低图像的时间噪声
使用NVIDIA VPI降低图像的时间噪声

在本文中,我们将向您展示如何在 Jetson 产品系列上运行时间降噪( TNR )示例应用程序。
在 Jetson 设备上设置 VPI
通过 SDK 管理器设置 Jetson 设备时,请确保选中 Jetson SDK 组件框。然后在设备闪存时安装 VPI 。
安装完成后,可以在以下路径下找到 VPI :
/opt/nvidia/vpi1/
要验证环境设置是否正确,请将 VPI 示例应用程序复制到主目录中,然后构建 TNR 示例。
$ vpi1_install_samples.sh $HOME $ cd $HOME/NVIDIA_VPI–samples/09-tnr $ cmake . $ make
VPI 在运行离散 GPU 的 x86 机器上也受支持。有关更多信息,请参阅 VPI – Vision 编程接口文档中的 Installation 。
TNR 示例应用程序
VPI 提供了一组 CV 算法,这些算法利用多个后端高效地使用设备的可用计算资源。 TNR 是在 Jetson 设备上运行的计算机视觉应用程序中常用的一种降噪方法。本文使用 TNR 示例应用程序来演示如何使用 VPI 中的一些关键概念和组件来实现自己的应用程序。
我们将在本帖中介绍以下主题:
创建构建 VPI 管道所需的元素
了解如何与 OpenCV 进行互操作
向流提交处理任务
同步流中的任务
锁定图像缓冲区以便可以从 CPU 访问
TNR 样本可在以下路径中找到:
$HOME/NVIDIA_VPI–samples/09-tnr/main.cpp
有关示例应用程序和算法的更多信息,请参阅以下参考资料:
时间降噪示例应用程序
时域降噪算法
算法版本和后端支持
硬件引擎在 VPI 中被命名为 backends 。通过使用 Jetson 设备固有的可用系统级并行性,这些后端使您能够卸载可并行处理阶段并加速应用程序。后端是 CPU 、 CUDA ( GPU )、 PVA 和 VIC 。特定后端引擎的确切可用性取决于应用程序部署到的 Jetson 平台。有关特定平台上可用算法、后端支持和后端可用性的更多信息,请参阅 Algorithms 。
VPI 目前为 TNR 提供了两种不同的实现,每种实现都适合不同的场景和需求。这些版本采用双边滤波平滑平坦区域,同时保留边缘,和时间无限脉冲响应( IIR )滤波与运动检测器的结合,以处理跨帧的时间噪声。
VPI_TNR_V2 – 与 VPI_TNR_V3 相比,该版本提供了更轻的噪音降低,并且具有一定程度的可配置性,即可以调整照明条件以更好地适应给定场景。这个版本有一个减少的计算需求,这转化为速度。它适用于执行时间比降噪质量更重要的用例。
VPI_TNR_V3 —用于需要更好质量的降噪的用例。与 VPI_TNR_V2 相比,使用这个变体,您应该期望计算需求会增加。除此之外,还进一步扩展了可配置性。建议用于具有挑战性的弱光场景。
VPI_TNR_DEFAULT – 您可以使用默认值,而不是指定确切的版本,该值选择给定后端支持的噪声抑制最强的版本。
在决定哪个算法版本适合您的用例时,需要考虑的另一个标准是它对不同后端和设备的支持。下表总结了 TNR 支持。
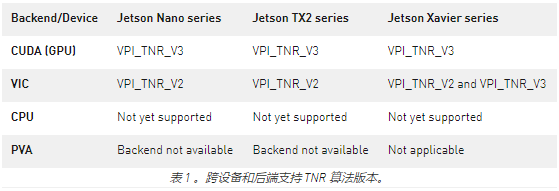
VPI_TNR_V2 和 VPI_TNR_V3 都允许显式设置要捕获的场景的照明条件,从而启用调整。这在低光场景或以高增益捕获的流的上下文中是重要的,所述低光场景或流可能包含更高的噪声级,并且因此要求更高的噪声降低水平。
较高的强度级别可能会影响帧的纹理区域中的细节数量,从而使其平滑。另一个副作用是在有快速移动物体的场景中重影。支持的场景照明条件在类型(室内、室外)和强度(低、中、高)方面有所不同,如下表所示。

使用不同的版本和相关的照明条件预设,您可以根据用例的具体情况调整 TNR 算法。这可以通过所谓的强度系数进一步定制。它是一个浮动参数,范围从 0 到 1 ,其中较大的值对应于增加的去噪强度。
VPI 应用程序
VPI 的一个关键方面是如何管理和协调在不同后端之间运行应用程序所需的资源。使用 VPI ,可以避免在处理阶段之间浪费内存拷贝。 VPI 为实现高效的内存管理而实施的另一种机制是在其接口处进行内存包装。
利用 VPI 的所有内存管理特性取决于代码的结构。最佳实践是将代码视为三阶段工作流:
Initialization
处理回路
Cleanup
大部分内存分配应该在初始化阶段进行。对于在可用资源受限的设备上运行的嵌入式应用程序,这一点尤为重要。除此之外,还可以更有效、更谨慎地进行内存管理,以避免可能的内存泄漏。
VPI 中的一个好做法是指定使用内存的后端。在这点上,只将 VPI 对象订阅到所需的后端集可以保证在管道在这些后端之间流动时获得最有效的内存路径。
处理循环是执行处理管道的地方。想象一下,一个应用程序在一个包含数百个单独帧的视频文件上迭代。主循环将主要负责对像素信息执行所需的变换,以实现给定计算机视觉任务的预期结果。
最后,清理阶段处理在任务执行期间使用的资源的所有必要释放和释放。坚持这种模式可以使 VPI 尽可能使用最有效的处理管道,并帮助您坚持良好的编码实践。
与 OpenCV 接口
VPI 与 OpenCV 的互操作性是该库的一个显著特征。如果您熟悉 OpenCV ,您可以轻松地将 VPI 与工作流集成,或者扩展现有的数据管道,以便更好地使用 VPI 提供的硬件加速。
TNR 示例中通过以下实用函数演示了这一点,该函数将使用 OpenCV 捕获的输入视频帧包装到 VPI 图像对象中。
69 // Utility function to wrap a cv::Mat into a VPIImage 70 static VPIImage ToVPIImage(VPIImage image, const cv::Mat &frame) 71 { 72 if (image == nullptr) 73 { 74 // Create a VPIImage that wraps the frame 75 CHECK_STATUS(vpiImageCreateOpenCVMatWrapper(frame, 0, &image)); 76 } 77 else 78 { 79 // reuse existing VPIImage wrapper to wrap the new frame. 80 CHECK_STATUS(vpiImageSetWrappedOpenCVMat(image, frame)); 81 } 82 return image; 83 }
从更深入地研究前面描述的函数开始。它意味着将 OpenCV 矩阵( cv::Mat )对象包装到 VPI 图像对象( VPIImage )。要上下文化, VPI 图像基本上是任何可以用宽度、高度和格式来描述的 2D 数据结构。尽管将图像数据视为 VPIImage 对象是直观的,但它的用法也可以扩展到其他类型的数据,例如二维向量场和热图。
The utility wrapping function invokes two other functions that pertain to the VPI OpenCVInterop.hpp module, which aims to provide useful infrastructure to integrate OpenCV-based code with VPI.
vpiImageCreateOpenCVMatWrapper —一个重载函数,它以两种不同的方式将 cv:Mat 对象包装到 VPIImage 中。第一种方法尝试直接从输入类型推断格式(遵循特定的规则),而第二种方法将显式格式作为其参数之一。
vpiImageSetWrappedOpenCVMat – 重用为特定 cv::Mat 对象定义的包装器来包装新的传入 cv::Mat 对象。这里的重点是避免在第一时间创建包装时产生的内存分配,这样效率更高。传入的 cv::Mat 对象必须呈现与创建时使用的原始对象相同的特征(格式和尺寸)。
流创建
main 函数捕获设置 VPI 管道以完成工作的相关步骤。管道的定义很简单,也很直观。在 VPI 中,管道是一个或多个数据流的组合,这些数据流流经不同的处理阶段。
图 1 以一种通用的方式显示了管道及其构建块(流、缓冲区、算法等)。为了简单起见,省略了一些组件。
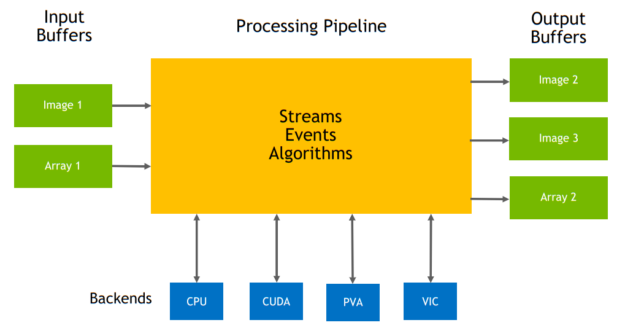
图 1 通用 VPI 管道。
流的目的是强制执行一个排队的步骤序列,数据需要通过该序列来完成特定的计算机视觉任务。这些步骤可能包括数据的预处理或后处理,甚至包括 TNR 之类的成熟算法。图 2 显示了 VPIStream 对象的示例。
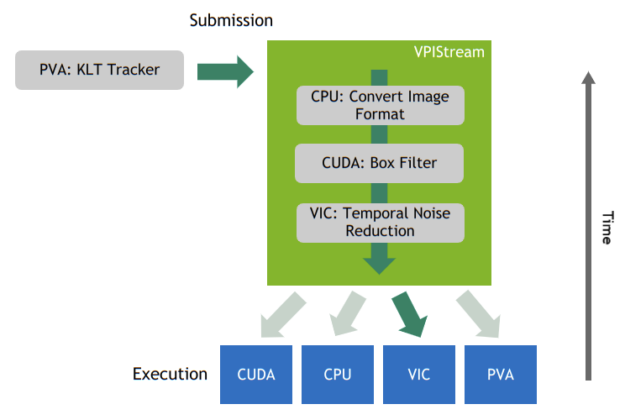
图 2 VPIStream 对象。
VPI 可适应各种不同的管道复杂性。您可以用一个流实现一个简单的管道,或者用几个不同阶段的并行流实现一个更复杂的实现,并将这些并行流卸载到不同的计算后端。这是 API 的一个强大功能,因为它使您能够获得对 Jetson 设备提供的系统级并行性的更多控制。
下面的代码示例演示如何在 TNR 示例中创建流。
143 VPIStream stream; 144 // PVA backend doesn't have currently Convert Image Format algorithm. 145 // Use the CUDA backend to do that. 146 CHECK_STATUS(vpiStreamCreate(VPI_BACKEND_CUDA | backend, &stream));
选择的后端正在传递到流中。这是一个可选步骤。使用零值将启用所有可用的后端。但是,分配一组特定的后端是推荐的做法,因为它有助于优化内存分配。
TNR 有效载荷
有效负载基本上是管道执行期间所需的临时资源。例如,有效负载可以是中间内存缓冲区,用于存储流的后续阶段之间交换的数据。包括 TNR 在内的许多算法都需要显式地创建有效负载,具体实现如下。
172 // Create a TNR payload configured to process NV12 173 // frames under outdoor low-light scenarios. 174 VPIPayload tnr; 175 CHECK_STATUS(vpiCreateTemporalNoiseReduction(backend, w, h, VPI_IMAGE_FORMAT_NV12_ER, VPI_TNR_DEFAULT, 176 VPI_TNR_PRESET_INDOOR_LOW_LIGHT, 1, &tnr));
对于 TNR 有效负载,请提供以下参数:
图像尺寸(宽度和高度)
Backend
图像数据格式(目前仅支持 NV12 )
TNR 算法版本
照明条件
降噪强度
对算法有效负载的引用
最终,该函数创建一个有效负载并将其绑定到指定的后端。
图像缓冲区
除了创建流和有效负载外,还必须创建 VPI 算法所需的图像缓冲区。在 TNR 中,使用双边和 IIR 滤波器的组合,因此需要三个不同的缓冲器,即当前和先前的图像输入和图像输出。
可以按如下方式创建图像缓冲区:
167 VPIImage imgPrevious, imgCurrent, imgOutput; 168 CHECK_STATUS(vpiImageCreate(w, h,VPI_IMAGE_FORMAT_NV12_ER, 0, &imgPrevious)); 169 CHECK_STATUS(vpiImageCreate(w, h,VPI_IMAGE_FORMAT_NV12_ER, 0, &imgCurrent)); 170 CHECK_STATUS(vpiImageCreate(w, h,VPI_IMAGE_FORMAT_NV12_ER, 0, &imgOutput));
这将创建具有以下指定特征的空缓冲区:
图像尺寸(宽度和高度)
格式(根据算法要求)
图像标志(当前用于分配后端)
指向返回所创建映像的 VPIImage 句柄的变量的指针
流处理
在构建块已经就位的情况下,您可以转到主处理循环,在那里执行降噪算法。在 TNR 样本上,循环迭代来自视频文件的每个单独帧,并执行必要的连续步骤以获得所需的结果。
当从视频中收集帧时,第一步是使用前面描述的实用程序函数将其包装成 VPIImage 对象。
186 frameBGR = ToVPIImage(frameBGR, cvFrame);
包装完成后, VPI 现在可以对 VPIImage 对象中的像素数据进行操作。因为 TNR 要求帧是 NV12 格式,所以需要一个转换步骤。
188 // First convert it to NV12 189 CHECK_STATUS(vpiSubmitConvertImageFormat(stream,VPI_BACKEND_CUDA, frameBGR, imgCurrent, NULL));
在此阶段,转换图像的特定任务与先前实例化的流相关联。除此之外,任务被设置为在 GPU 上执行。输入帧的图像缓冲区以及刚刚从cv::Mat对象包装的数据都用于此目的。
格式转换完成后,可以将输入缓冲区传递给 TNR 算法进行处理。
191 // Apply TNR 192 // For first frame, you must pass nullptr as the previous frame, this resets the internal 193 // state. 194 CHECK_STATUS(vpiSubmitTemporalNoiseReduction(stream, 0, tnr, curFrame == 1 ? nullptr : imgPrevious, 195 imgCurrent, imgOutput)); 196
要调用 TNR 算法,请设置以下参数:
- 与算法关联的流
- 后端
- 算法有效负载,如前面实例化的一样
- 图像缓冲区:以前和当前的输入和输出
在第一次迭代(curFrame == 1)时,缓冲区上没有有效的前一个映像,而是传递一个空指针。对于下面的迭代,缓冲区将相应地填充。在执行 TNR 算法之后,输出缓冲区可以从 NV12 转换回以前的 BGR 格式。
197 // Convert output back to BGR 198 CHECK_STATUS(vpiSubmitConvertImageFormat(stream,VPI_BACKEND_CUDA, imgOutput, frameBGR, NULL));
在这一点上,必须提到 VPI 对流阶段实施了非阻塞异步范例。这对于作为后端分布在不同协处理器之间的工作负载的平滑和高效的编排是必不可少的。对于进一步的步骤,请确保在继续之前已完成向流发出的所有活动。这时同步功能就派上用场了。
199 CHECK_STATUS(vpiStreamSync(stream));
VPI 现在确保与流相关的所有正在进行的活动在进入管道的下一个阶段之前都已完成。同步完成后,帧就可以在连接到指定后端的输出缓冲区中使用了。为了能够将其写入输出视频流(在这种情况下是一个文件),必须锁定图像,以便 CPU 可以使用缓冲区。
这就解释了为什么在锁定帧之前进行同步是避免处理问题的关键步骤。因为 VPI 是异步操作的,所以在没有同步的情况下,缓冲区会在前一阶段完成之前被锁定。结果是不可预测的。
201 // Now add it to the output video stream 202 VPIImageData imgdata; 203 CHECK_STATUS(vpiImageLock(frameBGR,VPI_LOCK_READ, &imgdata)); 204 205 cv::Mat outFrame; 206 CHECK_STATUS(vpiImageDataExportOpenCVMat(imgdata, &outFrame)); 207 outVideo << outFrame; 208 209 CHECK_STATUS(vpiImageUnlock(frameBGR));
如您所见,锁定的缓冲区由 CPU 处理,以供进一步使用。锁被设置为只读,然后图像缓冲区被映射到 CPU 。锁定时, VPI 无法在缓冲区上工作。在 CPU 将输出帧提供给视频编码器后,缓冲区可以被解锁并被 VPI 进一步使用。
VPI 数据流
TNR 示例应用程序可以概括为以下数据流。其他的小步骤也是应用程序不可分割的一部分,但是为了简单起见,图 3 中只包含了宏步骤。

图 3 TNR 示例应用程序中的数据流。
从视频流或文件中收集输入帧。 OpenCV 已用于此目的。
必要的 VPI 元素被实例化:单个流、 TNR 算法负载以及用于先前和当前输入和输出图像的图像缓冲区。
输入帧被包装到 VPIImage 缓冲区中。
缓冲区上的像素数据被转换成 NV12 ,以便 TNR 算法可以处理它。当算法完成执行时,它会恢复到原始格式。
图像缓冲区被锁定,以便 CPU 可以访问数据。将图像提供给视频输出后,可以解锁缓冲区, VPI 可以进一步处理它。
概括
在本文中,我们向您展示了如何在 Jetson 产品系列上运行 TNR 示例应用程序。
关于作者
Maycon da Silva Carvalho 是 Jetson 的现场应用工程师。他负责与部署基于 Jetson 的应用程序的不同行业的客户进行多学科技术合作。
Rodolfo Schulz de Lima 是 VPI 的首席工程师。他拥有 UFRJ 里约热内卢联邦大学电子工程学士学位,并在巴西里约热内卢的 IMPA (纯数学和应用数学研究所)学习计算机图形学。
审核编辑:郭婷
-
嵌入式
+关注
关注
5209文章
20645浏览量
336910 -
gpu
+关注
关注
28文章
5271浏览量
136059 -
SDK
+关注
关注
3文章
1111浏览量
52003
发布评论请先 登录
Sony FCB-ES8230 低噪声图像系统中的线束优化

NVIDIA cuDF和cuVS获全球领先数据平台采用
使用LDO的VIOC特性降低输出噪声并提高热效率

NVIDIA在CES 2026发布新一代Rubin AI平台

降低LDO功耗延长运行时间
基于FPGA的CLAHE图像增强算法设计

物流机器人“货架识别”错误:图像传感器供电电容噪声抑制

如何降低视频占用空间?
O-CS8系列表贴式(SMD)超高稳、超低相位噪声SC-cut OCXO
降低adc在不同PCB上的噪声,如何做到接近AD4134验证板噪声水平?
NVIDIA RTX AI加速FLUX.1 Kontext现已开放下载
NVIDIA Isaac Sim与NVIDIA Isaac Lab的更新
思特威SC301HIOT物联网3MP高性能图像传感器 搭载SmartAOV™和超低噪声外围读取电路




评论