 什么是BERT?为何选择BERT?
什么是BERT?为何选择BERT?

BERT 是由 Google 开发的自然语言处理模型,可学习文本的双向表示,显著提升在情境中理解许多不同任务中的无标记文本的能力。
BERT 是整个类 BERT 模型(例如 RoBERTa、ALBERT 和 DistilBERT)系列的基础。
什么是 BERT?
基于 Transformer (变换器)的双向编码器表示 (BERT) 技术由 Google 开发,通过在所有层中共同调整左右情境,利用无标记文本预先训练深度双向表示。该技术于 2018 年以开源许可的形式发布。Google 称 BERT 为“第一个深度双向、无监督式语言表示,仅使用纯文本语料库预先进行了训练”(Devlin et al. 2018)。
双向模型在自然语言处理 (NLP) 领域早已有应用。这些模型涉及从左到右以及从右到左两种文本查看顺序。BERT 的创新之处在于借助 Transformer 学习双向表示,Transformer 是一种深度学习组件,不同于递归神经网络 (RNN) 对顺序的依赖性,它能够并行处理整个序列。因此可以分析规模更大的数据集,并加快模型训练速度。Transformer 能够使用注意力机制收集词语相关情境的信息,并以表示该情境的丰富向量进行编码,从而同时处理(而非单独处理)与句中所有其他词语相关的词语。该模型能够学习如何从句段中的每个其他词语衍生出给定词语的含义。
之前的词嵌入技术(如 GloVe 和 Word2vec)在没有情境的情况下运行,生成序列中各个词语的表示。例如,无论是指运动装备还是夜行动物,“bat”一词都会以同样的方式表示。ELMo 通过双向长短期记忆模型 (LSTM),对句中的每个词语引入了基于句中其他词语的深度情景化表示。但 ELMo 与 BERT 不同,它单独考虑从左到右和从右到左的路径,而不是将其视为整个情境的单一统一视图。
由于绝大多数 BERT 参数专门用于创建高质量情境化词嵌入,因此该框架非常适用于迁移学习。通过使用语言建模等自我监督任务(不需要人工标注的任务)训练 BERT,可以利用 WikiText 和 BookCorpus 等大型无标记数据集,这些数据集包含超过 33 亿个词语。要学习其他任务(如问答),可以使用适合相应任务的内容替换并微调最后一层。
下图中的箭头表示三个不同 NLP 模型中从一层到下一层的信息流。
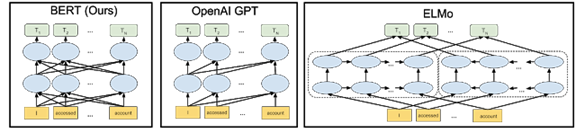
BERT 模型能够更精细地理解表达的细微差别。例如,处理序列“Bob 需要一些药。他的胃不舒服,可以给他拿一些抗酸药吗?” BERT 能更好地理解 “Bob”、“他的”和“他”都是指同一个人。以前,在“如何填写 Bob 的处方”这一查询中,模型可能无法理解第二句话引用的人是 Bob。应用 BERT 模型后,该模型能够理解所有这些关联点之间的关系。
双向训练很难实现,因为默认情况下,在前一个词语和下一个词语的基础上调节每个词都包括多层模型中预测的词语。BERT 的开发者通过遮蔽语料库中的预测词语和其他随机词语解决了这个问题。BERT 还使用一种简单的训练技术,尝试预测给定的两个句子 A 和 B:B 和 A 是先后还是随机关系。
为何选择 BERT?
自然语言处理是当今许多商业人工智能研究的中心。例如,除搜索引擎外,NLP 还用在了数字助手、自动电话响应和车辆导航领域。BERT 是一项颠覆性技术,它提供基于大型数据集训练的单一模型,而且已经证实该模型能够在各种 NLP 任务中取得突破性成果。
BERT 的开发者表示,模型应用范围很广(包括解答问题和语言推理),而且无需对任务所需的具体架构做出大量修改。BERT 不需要使用标记好的数据预先进行训练,因此可以使用任何纯文本进行学习。
主要优势(用例)
BERT 可以针对许多 NLP 任务进行微调。它是翻译、问答、情感分析和句子分类等语言理解任务的理想之选。
目标式搜索
虽然如今的搜索引擎能够非常出色地理解人们要寻找的内容(在人们使用正确查询格式的前提下),但仍可以通过很多方式改善搜索体验。对于语法能力差或不懂得搜索引擎提供商所用语言的人员而言,体验可能令人不快。搜索引擎还经常需要用户尝试同一查询的不同变体,才能查询到理想结果。
用户每天在 Google 上执行 35 亿次搜索,搜索体验改进后,一天就可以减少 10% 的搜索量,长期累积下来将大幅节省时间、带宽和服务器资源。从业务角度来看,它还使搜索提供商能够更好地了解用户行为,并投放更具针对性的广告。
通过帮助非技术用户更准确地检索信息,并减少因查询格式错误带来的错误,可以更好地理解自然语言,从而提高数据分析和商业智能工具的效果。
辅助性导航
在美国,超过八分之一的人有残疾,而且许多人在物理和网络空间中导航的能力受到了限制。对于必须使用语音来控制轮椅、与网站交互和操作周围设备的人员而言,自然语言处理是生活必需品。通过提高对语音命令的响应能力,BERT 等技术可以提高生活质量,甚至可以在需要快速响应环境的情况下提高人身安全。
BERT 的重要意义
机器学习研究人员
BERT 在自然语言处理方面引发的变革等同于计算机视觉领域的 AlexNet,在该领域具有显著的革命性意义。仅需替换网络的最后一层,便可针对一些新任务定制网络,这项功能意味着用户可轻松将其应用于任何感兴趣的研究领域。无论用户的目标是翻译、情感分析还是执行一些尚未提出的新任务,都可以快速配置网络以进行尝试。截至目前,有关该模型的引文超过 8000 篇,其衍生用例不断证明该模型在处理语言任务方面的先进水平。
软件开发者
由于针对大型数据集预先训练过的模型的广泛可用性,BERT 大大减少了先进模型在投入生产时受到的计算限制。此外,将 BERT 及其衍生项纳入知名库(如 Hugging Face)意味着,机器学习专家不需要启动和运行基础模型了。
BERT 在自然语言解读方面达到了新的里程碑,与其他模型相比展现了更强大的功能,能够理解更复杂的人类语音并能更精确地回答问题。
BERT 为何可在 GPU 上表现更突出
对话式 AI 是人类与智能机器和应用程序(从机器人和汽车到家庭助手和移动应用)互动的基础构建块。让计算机理解人类语言及所有细微差别,并做出适当的反应,这是 AI 研究人员长期以来的追求。但是,在采用加速计算的现代 AI 技术出现之前,构建具有真正自然语言处理 (NLP) 功能的系统是无法实现的。
BERT 在采用 NVIDIA GPU 的超级计算机上运行,以训练其庞大的神经网络并实现超高的 NLP 准确性,从而影响已知的人类语言理解领域。虽然目前有许多自然语言处理方法,但让 AI 具有类似人类的语言能力仍然是难以实现的目标。随着 BERT 等基于 Transformer 的大规模语言模型的出现,以及 GPU 成为这些先进模型的基础设施平台,我们看到困难的语言理解任务快速取得了进展。数十年来,这种 AI 一直备受期待。有了 BERT,这一刻终于到来了。
模型复杂性提升了 NLP 准确性,而规模更大的语言模型可显著提升问答、对话系统、总结和文章完结等自然语言处理 (NLP) 应用程序的技术水平。BERT-Base 使用 1.1 亿个参数创建而成,而扩展的 BERT-Large 模型涉及 3.4 亿个参数。训练高度并行化,因此可以有效利用 GPU 上的分布式处理。BERT 模型已证明能够有效扩展为 39 亿个参数的 Megatron-BERT 等大规模模型。
BERT 的复杂性以及训练大量数据集方面的需求对性能提出了很高的要求。这种组合需要可靠的计算平台来处理所有必要的计算,以实现快速执行并提高准确性。这些模型可以处理大量无标记数据集,因此成为了现代 NLP 的创新中心,另外在很多用例中,对于即将推出的采用对话式 AI 应用程序的智能助手而言,这些模型都是上佳之选。
NVIDIA 平台提供可编程性,可以加速各种不同的现代 AI,包括基于 Transformer 的模型。此外,数据中心扩展设计加上软件库,以及对先进 AI 框架的直接支持,为承担艰巨 NLP 任务的开发者提供无缝的端到端平台。
在使用 NVIDIA 的 DGX SuperPOD 系统(基于连接了 HDR InfiniBand 的大规模 DGX A100 GPU 服务器集群)进行的一项测试中,NVIDIA 使用 MLPerf Training v0.7 基准实现了 0.81 分钟的 BERT 训练时间,创造了记录。相比之下,Google 的 TPUv3 在同一测试中所用时间超过了 56 分钟。
审核编辑 :李倩
-
编码器
+关注
关注
45文章
4033浏览量
144005 -
数据中心
+关注
关注
18文章
5907浏览量
75300 -
自然语言处理
+关注
关注
1文章
630浏览量
14795
原文标题:NVIDIA 大讲堂 | 什么是 BERT ?
文章出处:【微信号:NVIDIA_China,微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
“618”智能消费释放在即,全屋智能为何今年将成为爆发元年?

为何选择客定芯片?当标准品遇上独特需求的终极解决方案

ADI-BERT:高速串行接口测试的理想解决方案
误码仪高速射频接头的使用和维护卡片

LM358为何未被淘汰:电源鲁棒性、库存可用性与设计简洁度

为何选择单相双级电源滤波器?


为何智能加湿器睡眠仪都选择这款语音芯片?揭秘无缝循环播放背后的黑科技

算法工程师需要具备哪些技能?
电源测试为何弃用实际负载?模拟负载才是高效选择

比特误码率测试仪接收端受限眼图自动校准最佳实践




评论