 豆瓣电影Top250信息爬取
豆瓣电影Top250信息爬取

通过本案例[豆瓣电影Top250信息爬取]锻炼除正则表达式之外两种信息解析方式:Xpath和PyQuery。
爬取url地址:https://movie.douban.com/top250
分析:
分析url地址:每页25条数据,共计10页
第1页:https://movie.douban.com/top250?start=0
第2页:https://movie.douban.com/top250?start=25
第3页:https://movie.douban.com/top250?start=50
...
结果:
for i in range(10):
url = "https://movie.douban.com/top250?start="+str(i*25)
分析网页源代码内容:每部电影信息都是放在
...
具体实现代码如下:
from requests.exceptions import RequestException
from lxml import etree
from pyquery import PyQuery as pq
import requests
import re,time,json
def getPage(url):
'''爬取指定url页面信息'''
try:
#定义请求头信息
headers = {
'User-Agent':'User-Agent:Mozilla/5.0(WindowsNT6.1;rv:2.0.1)Gecko/20100101Firefox/4.0.1'
}
# 执行爬取
res = requests.get(url,headers=headers)
#判断响应状态,并响应爬取内容
if res.status_code == 200:
return res.text
else:
return None
except RequestException:
return None
def parsePage(content):
'''解析爬取网页中的内容,并返回字段结果'''
print(content)
# =========使用pyquery解析==================
# 解析HTML文档
doc = pq(content)
#获取网页中所有标签并遍历输出标签名
items = doc("div.item")
#遍历封装数据并返回
for item in items.items():
yield {
'index':item.find("div.pic em").text(),
'image':item.find("div.pic img").attr('src'),
'title':item.find("div.hd span.title").text(),
'actor':item.find("div.bd p:eq(0)").text(),
'score':item.find("div.bd div.star span.rating_num").text(),
}
'''
# =======使用xpath解析====================
# 解析HTML文档,返回根节点对象
html = etree.HTML(content)
#获取网页中所有标签并遍历输出标签名
items = html.xpath('//div[@class="item"]')
#遍历封装数据并返回
for item in items:
yield {
'index':item.xpath('.//div/em[@class=""]/text()')[0],
'image':item.xpath('.//img[@width="100"]/@src')[0],
'title':item.xpath('.//span[@class="title"]/text()')[0],
'actor':item.xpath('.//p[@class=""]/text()')[0],
'score':item.xpath('.//span[@class="rating_num"]/text()'),
#'time':item[4].strip()[5:],
}
'''
def writeFile(content):
'''执行文件追加写操作'''
with open("./result.txt",'a',encoding='utf-8') as f:
f.write(json.dumps(content,ensure_ascii=False) + "\n")
#json.dumps 序列化时对中文默认使用的ascii编码.想输出真正的中文需要指定ensure_ascii=False
def main(offset):
''' 主程序函数,负责调度执行爬虫处理 '''
url = 'https://movie.douban.com/top250?start=' + str(offset)
html = getPage(url)
# 判断是否爬取到数据,并调用解析函数
if html:
for item in parsePage(html):
writeFile(item)
# 判断当前执行是否为主程序运行,并遍历调用主函数爬取数据
if __name__ == '__main__':
for i in range(10):
main(offset=i*25)
time.sleep(1)
审核编辑:符乾江
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
python
+关注
关注
59文章
4892浏览量
90424 -
爬虫
+关注
关注
0文章
87浏览量
8204
发布评论请先 登录
相关推荐
热点推荐
AI算法核心知识清单(深度实战版4)
五、AI算法工程化与实践1.数据预处理全流程数据采集结构化数据:数据库查询(SQL)、Excel/CSV文件读取、API接口调用(如RESTfulAPI)非结构化数据:图像数据:爬虫爬取(如

神州信息斩获TOP级城商行对公场景大模型应用项目
AI大模型已成为金融数智化转型的核心引擎,在重构业务流程、提升服务效率和强化风险管控等方面发挥关键作用。近日,神州信息成功中标国内某TOP级城商行对公场景大模型应用项目(企业APP、掌银及数据项目),实现企业网银、企业APP的数据智能场景建设。
普强信息荣登2026语音识别技术公司TOP30榜单
近日,由 DBC 与 CIW/eNet 研究院联合发布的《2026 语音识别技术公司 TOP30》榜单正式揭晓。
鸿蒙智能体开发知识库---创建知识库
源信息,可以选择对图片智能标注;
3.导入方式-数据源:配置接口的形式导入知识数据,按提示填写相关信息;
4.导入方式-爬虫:填写爬取地址,配置
发表于 03-06 10:18
一文读懂电气间隙与爬电距离 · 来龙去脉:设计指南、影响因素、计算方法、案例说明
-关于《电气间隙与爬电距离的全面解析与设计指南》的解析-文字原创,素材来源:TI、IEC、IPC、GB、网络-「SysPro|电动汽车标准解读」专栏内容,全文13700字-本篇为节选,完整内容会在

爬壁机器人磁铁的一些常见问题
爬壁机器人近几年比较火,它是一类能够在垂直墙面、天花板、倾斜表面上移动和作业的特种机器人,今天我们不聊其它,只聊下关于磁吸附应用中的磁铁,以下是小编整理的关于爬壁机器人中磁铁的一些常见问题。

2026 开工大吉 | 电源互连技术白皮书:爬电距离与电气间隙解析
——该标准会根据 材料等级、工作电压以及污染等级 ,明确规定 爬电距离与电气间隙 的具体数值。无论系统设计方案如何,爬电距离和电气间隙都关乎产品安全,是必须满足的合规指标。 近期Samtec发布了一份技术白皮书,旨在阐释 爬电

京东关键词搜索商品列表的Python爬虫实战
!) 京东拥有商品数据的版权,爬虫仅可用于 个人学习、研究 ,禁止用于商业用途、批量爬取造成京东服务器压力。 遵守京东《用户协议》和robots.txt协议(京东https://www.jd.com/robots.txt明确限制了部分爬虫行为)。 本实战仅演示基础爬虫思路
潇湘电影集团与洲明集团达成战略合作
12月10日,潇湘电影集团与洲明集团战略合作签约仪式圆满举行。此次合作双方将在LED电影屏、光显系统及国产电影拍摄器材等核心领域展开深度合作,共同推动影视产业与光显科技的融合创新。
第七届海南岛国际电影节联想AI电影季开幕
12月7日,由海南岛国际电影节组委会指导,今日美术馆AI艺术创新联盟(AIAIA)、联想集团主办的“第七届海南岛国际电影节·联想AI电影季”在海南三亚开幕。本届AI电影季共吸引全球56
一文读懂 · 电气间隙与爬电距离 · 来龙去脉:设计指南、影响因素、计算方法、案例说明
-关于《电气间隙与爬电距离的全面解析与设计指南》的解析-文字原创,素材来源:TI、IEC、IPC、GB、网络-「SysPro|电动汽车标准解读」专栏内容,全文13700字-本篇为节选,完整内容会在

POE取电保护
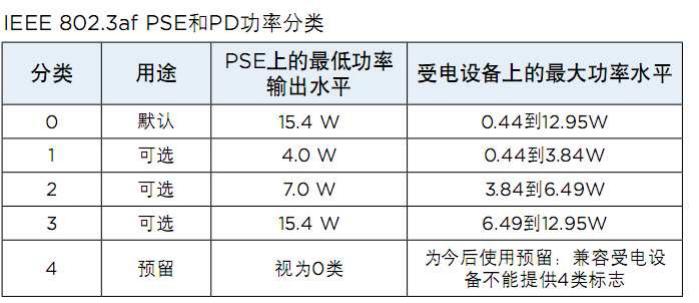
防雷 / 过电压 / 电流 / ESD 电子电路保护器件专业提供商 针对POE取电, 国际IEEE 802.3标准说明 及两种取电方式 www.yint.com.cn 本文为音特公司技术人员
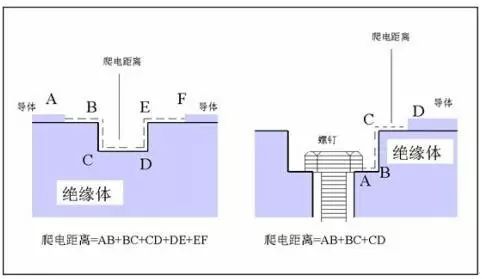
“爬电距离”与“电气间隙”是怎样计算的?
大家好,分享一篇优秀文章,欢迎转载共同学习。 做高压产品,经常会涉及到爬电距离和电气间隙,今天来看看这2个参数是由什么决定的? 爬电距离 沿绝缘表面测得的两个导电零部件之间或导电零部件与设备防护界面
电气间隙与爬电距离的相关设计
众所周知,48V相较12V电压上升,因此需要更大的爬电距离(安全绝缘路径)和电气间隙(安全绝缘间距)。这意味着部分连接器需要重新设计。
FLIR ONE Edge Pro红外热像仪在爬宠饲养中的应用
在爬宠饲养中,温度控制是决定宠物健康与幸福的关键因素。无论是巴西龟、蜥蜴还是蛇类,它们依赖外部热源调节体温,稍有不慎就可能导致健康问题。今天,我们就通过一位爬宠主人的真实案例,看看FLIR ONE Edge Pro智能红外热像仪如何帮助他精准掌控饲养环境,让爱宠舒适生活。



评论