 21个Transformer面试题的简单回答
21个Transformer面试题的简单回答

1.Transformer为何使用多头注意力机制?(为什么不使用一个头)
答:多头可以使参数矩阵形成多个子空间,矩阵整体的size不变,只是改变了每个head对应的维度大小,这样做使矩阵对多方面信息进行学习,但是计算量和单个head差不多。
2.Transformer为什么Q和K使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘?
答:请求和键值初始为不同的权重是为了解决可能输入句长与输出句长不一致的问题。并且假如QK维度一致,如果不用Q,直接拿K和K点乘的话,你会发现attention score 矩阵是一个对称矩阵。因为是同样一个矩阵,都投影到了同样一个空间,所以泛化能力很差。
3.Transformer计算attention的时候为何选择点乘而不是加法?两者计算复杂度和效果上有什么区别?
答:K和Q的点乘是为了得到一个attention score 矩阵,用来对V进行提纯。K和Q使用了不同的W_k, W_Q来计算,可以理解为是在不同空间上的投影。正因为 有了这种不同空间的投影,增加了表达能力,这样计算得到的attention score矩阵的泛化能力更高。
4.为什么在进行softmax之前需要对attention进行scaled(为什么除以dk的平方根),并使用公式推导进行讲解
答:假设 Q 和 K 的均值为0,方差为1。它们的矩阵乘积将有均值为0,方差为dk,因此使用dk的平方根被用于缩放,因为,Q 和 K 的矩阵乘积的均值本应该为 0,方差本应该为1,这样可以获得更平缓的softmax。当维度很大时,点积结果会很大,会导致softmax的梯度很小。为了减轻这个影响,对点积进行缩放。
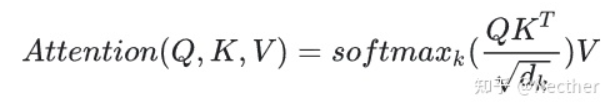
5.在计算attention score的时候如何对padding做mask操作?
答:对需要mask的位置设为负无穷,再对attention score进行相加
6.为什么在进行多头注意力的时候需要对每个head进行降维?
答:将原有的高维空间转化为多个低维空间并再最后进行拼接,形成同样维度的输出,借此丰富特性信息,降低了计算量
7.大概讲一下Transformer的Encoder模块?
答:输入嵌入-加上位置编码-多个编码器层(每个编码器层包含全连接层,多头注意力层和点式前馈网络层(包含激活函数层))
8.为何在获取输入词向量之后需要对矩阵乘以embedding size的开方?
embedding matrix的初始化方式是xavier init,这种方式的方差是1/embedding size,因此乘以embedding size的开方使得embedding matrix的方差是1,在这个scale下可能更有利于embedding matrix的收敛。
9.简单介绍一下Transformer的位置编码?有什么意义和优缺点?
答:因为self-attention是位置无关的,无论句子的顺序是什么样的,通过self-attention计算的token的hidden embedding都是一样的,这显然不符合人类的思维。因此要有一个办法能够在模型中表达出一个token的位置信息,transformer使用了固定的positional encoding来表示token在句子中的绝对位置信息。
10.你还了解哪些关于位置编码的技术,各自的优缺点是什么?
答:相对位置编码(RPE)1.在计算attention score和weighted value时各加入一个可训练的表示相对位置的参数。2.在生成多头注意力时,把对key来说将绝对位置转换为相对query的位置3.复数域函数,已知一个词在某个位置的词向量表示,可以计算出它在任何位置的词向量表示。前两个方法是词向量+位置编码,属于亡羊补牢,复数域是生成词向量的时候即生成对应的位置信息。
11.简单讲一下Transformer中的残差结构以及意义。
答:encoder和decoder的self-attention层和ffn层都有残差连接。反向传播的时候不会造成梯度消失。
12.为什么transformer块使用LayerNorm而不是BatchNorm?LayerNorm 在Transformer的位置是哪里?
答:多头注意力层和激活函数层之间。CV使用BN是认为channel维度的信息对cv方面有重要意义,如果对channel维度也归一化会造成不同通道信息一定的损失。而同理nlp领域认为句子长度不一致,并且各个batch的信息没什么关系,因此只考虑句子内信息的归一化,也就是LN。
13.简答讲一下BatchNorm技术,以及它的优缺点。
答:批归一化是对每一批的数据在进入激活函数前进行归一化,可以提高收敛速度,防止过拟合,防止梯度消失,增加网络对数据的敏感度。
14.简单描述一下Transformer中的前馈神经网络?使用了什么激活函数?相关优缺点?
答:输入嵌入-加上位置编码-多个编码器层(每个编码器层包含全连接层,多头注意力层和点式前馈网络层(包含激活函数层))-多个解码器层(每个编码器层包含全连接层,多头注意力层和点式前馈网络层)-全连接层,使用了relu激活函数
15.Encoder端和Decoder端是如何进行交互的?
答:通过转置encoder_ouput的seq_len维与depth维,进行矩阵两次乘法,即q*kT*v输出即可得到target_len维度的输出
16.Decoder阶段的多头自注意力和encoder的多头自注意力有什么区别?
答:Decoder有两层mha,encoder有一层mha,Decoder的第二层mha是为了转化输入与输出句长,Decoder的请求q与键k和数值v的倒数第二个维度可以不一样,但是encoder的qkv维度一样。
17.Transformer的并行化提现在哪个地方?
答:Transformer的并行化主要体现在self-attention模块,在Encoder端Transformer可以并行处理整个序列,并得到整个输入序列经过Encoder端的输出,但是rnn只能从前到后的执行
18.Decoder端可以做并行化吗?
训练的时候可以,但是交互的时候不可以
19.简单描述一下wordpiece model 和 byte pair encoding,有实际应用过吗?
答“传统词表示方法无法很好的处理未知或罕见的词汇(OOV问题)
传统词tokenization方法不利于模型学习词缀之间的关系”BPE(字节对编码)或二元编码是一种简单的数据压缩形式,其中最常见的一对连续字节数据被替换为该数据中不存在的字节。后期使用时需要一个替换表来重建原始数据。优点:可以有效地平衡词汇表大小和步数(编码句子所需的token次数)。
缺点:基于贪婪和确定的符号替换,不能提供带概率的多个分片结果。
20.Transformer训练的时候学习率是如何设定的?Dropout是如何设定的,位置在哪里?Dropout 在测试的需要有什么需要注意的吗?
LN是为了解决梯度消失的问题,dropout是为了解决过拟合的问题。在embedding后面加LN有利于embedding matrix的收敛。
21.bert的mask为何不学习transformer在attention处进行屏蔽score的技巧?
答:BERT和transformer的目标不一致,bert是语言的预训练模型,需要充分考虑上下文的关系,而transformer主要考虑句子中第i个元素与前i-1个元素的关系。
责任编辑:lq
-
编码器
+关注
关注
45文章
4011浏览量
143361 -
矩阵
+关注
关注
1文章
450浏览量
36263 -
Transformer
+关注
关注
0文章
156浏览量
6961
原文标题:21个Transformer面试题的简单回答
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
AI面试的真与假,不在报告是否漂亮,而在评分是否可追溯

TCP三次握手与四次挥手的详细过程
Transformer 入门:从零理解 AI 大模型的核心原理
面试必看!排队自旋锁32位变量的域划分与核心作用

Transformer如何让自动驾驶大模型获得思考能力?
Transformer如何让自动驾驶变得更聪明?
人工智能工程师高频面试题汇总:循环神经网络篇(题目+答案)
用30道电子工程师面试题来拷问堕落的你...

每周推荐!硬件设计指南+无刷电机原理图大全+工程师面试题库汇总
硬件工程师或研发类笔试面试题库汇总
最全的硬件工程师笔试试题集
Transformer架构中编码器的工作流程

Transformer架构概述

【硬件方向】名企面试笔试真题:大疆创新校园招聘笔试题
硬件工程师面试/笔试经典 100 题




评论