 Vokenization是一种比GPT-3更智能的视觉语言模型
Vokenization是一种比GPT-3更智能的视觉语言模型

学习人工智能,最好的办法就是先考上大学,学好计算机和数学,其次就是生个孩子。这可不是一个段子。有了孩子之后,你会能更好理解人工智能到底是如何发生的。看着一个牙牙学语的小婴儿开始对这个世界发生好奇,终于有一天开始指着一个毛茸茸的东西叫出“猫咪”的时候,你可能就会理解教会一个孩子说话并不比教会人工智能认出一只猫更容易。
人工智能靠大量的算力和数据,而人类靠着五感,还有我们那个低功率的大脑。不过,很快你就会对小孩子的学习能力惊讶不已,他会指着各种他不认识的东西问你“这是什么”,直到你不胜其烦。等到再长大一些,小孩子就不会满足于仅仅知道这些东西的名字,开始想你发问“为什么会这样”,再次把你问到山穷水尽。
我们知道,现在人工智能领域,图像识别和自然语言处理(NLP)正处在如日中天的发展阶段。在众多单项上面,图像识别的能力要远远高于普通人,甚至比专家还好,NLP的翻译、听读、写作能力更是与专业人士不相上下,特别今年推出的GPT-3,更是以超大参数规模这种氪金方式来实现逆天的写作能力。
但这又怎样?尽管GPT-3可以编造出一大段看起来很真实的假新闻,但它仍然是靠着过去的文本经验来认知世界的,它会在很多常识性的问题上犯下低级错误,比如在回答“太阳有几只眼睛”的反常识问题上,GPT-3照样一本正经的给出“太阳有一只眼睛”的答案。如果是一个人第一次碰到这种问题,它往往并不是从文本里找答案,而是真的会去看一眼太阳的。而这正是我们人类掌握语言、传递信息最常见的一种方式。
受此启发,最近北卡罗来纳大学教堂山分校的研究人员设计了一种新的AI模型来改变GPT-3的这种缺陷,他们把这一技术称之为“Vokenization”,可以赋予像GPT-3这样的语言模型以“看”的能力。这个思路很好理解,我们从来不是靠一种方式来认识世界的,而把语言处理和机器视觉联系起来,才能更好地让人工智能来接近人的认识能力。那么这种“Voken”技术到底好不好用,正是本文要重点介绍的。
无所不能的GPT-3,却“不知道自己在说什么”
今年5月份正式出道的GPT-3,一度成为“无所不能”的代名词,OpenAI推出的这个第三代NLP语言模型,包含1750亿个参数,采用了英文维基百科、数字化图书、互联网网页等超大规模语料进行训练,是现有的规模最大、也最复杂的语言模型。从GPT-3对外API接口开放之后,研究者就从GPT03的强大文本生成能力中挖掘出层出不穷的应用,从答题、写小说、编新闻到写代码、做图表等等。但GPT-3也印证了“出道即巅峰”这句话,也是从一开始就争议不断。人们对其实际的应用前景表示极大的怀疑。
我们复习下GPT-3的作用原理。GPT-3采用的是少示例(Few-shot)学习的方式,对于一个特定的语言任务,只需要给定任务描述,并给出几个从输入到输出的映射示例,甚至只是给出一个开头的文本,GPT-3就可以根据前景预设自动生成相关下文,以此来完成对话、答题、翻译和简单的数学计算等任务。GPT-3的优势就在于预训练模型不需要使用大量标记的训练数据进行微调,这种便利性为普通人进行相关语言任务的使用上消除了障碍。
尽管GPT-3在很多领域的表现都令人折服,文本的质量高到能骗过大多数人类(无法分辨到底是机器写的还是人类写的),但是GPT-3本身的缺陷仍然非常明显。事实上,GPT-3的训练方式决定了它并不是真正理解“语义”,而是能够基于庞大的语料数据,进行海量搜索,匹配相应的答案。在这一过程中,GPT-3只是通过纯粹统计学的方法“建立起联系”,但是并没有真正理解语义。比如在一个帮助患者减轻焦虑情绪的问答中,“患者”表示感觉很糟,想要自杀的时候,GPT-3直接回复了“你可以”。
GPT-3的问题就像是上世纪80年代John Searle提出的“中文屋实验”里的那个并不懂中文的翻译者,GPT-3也只是手握着一本“无所不知”的百科全书,但是它并不清楚这个世界运行的真实逻辑,更无法解决具体场景下的具体情况。之前,纽约大学的两位教授就联名指出人们对GPT-3作用的高估,在《傲慢自大的 GPT-3:自己都不知道自己在说什么》里提到,它(GPT-3)本身并不具有 “革命性” 的变化,也不能真正理解语义,如果某项工作的 “结果” 非常重要,那么你不能完全信任人工智能。
简单来说就是,人工智能如果想要突破文本的统计意义而理解语义,那就必须要将文本和现实世界建立起联系。显然,这一点GPT-3还不能做到。为了能够让语言文本和实际的世界建立起联系,研究人员决定将语言模型和机器视觉结合起来,研究者们需要用一个包含文本和图像的数据集从头开始训练一个新模型,这就是被称作“Vokenization”的视觉语言数据集模型。
Vokenization:如何成为既好用又够用的数据集
我们首先如何来理解这两种模型的差异呢?如果你问一下GPT-3这样一个问题,“绵羊是什么颜色?”它的回答中出现“黑色”的可能和“白色”一样多,因为它能在大量文本中看到“Black Sheep”(害群之马)这个词。而如果你问一个图像识别模型,它就不会从抽象的文本中学习,而是更直接从现实的图像中学习,指出“这是一只白色绵羊”,而“这是一只黑色绵羊”。
我们既需要一个知识特别丰富的机器人,也需要一个能够看懂现实状况的机器人,只有把二者结合起来,才是人工智能更接近和人类交流合作的样子。但这个过程并不那么容易实现。实际上,我们常用的图像描述是不适用的。比如下面这张图,通常的描述,只能识别出物体“猫”,或者和猫常常一起出现的局部事物“水杯、毛线球、盒子和猫爪”,并没有描述出这只猫的状态和相互关系。
相比单纯的对象标注,Vokenization视觉语言数据集就需要对图像进行一组带有描述性标题的编辑。例如,下图的标题会是“一只坐在正在打包的行李箱中的橙色的猫”,这和典型的图像数据集不同,它不仅是用一个名词(例如:猫)来标记主要对象,而是给AI模型标注出了如何使用动词和介词的相互关联和作用。
但是这类视觉语言数据集的缺陷在于其数量实在太少,数据的生成和管理过程太久,相比较维基百科这种纯文本包含近30亿个单词,这仅仅只占GPT-3数据集的0.6%的这样的规模相比,像微软的MS COCO(上下文通用对象)这样的可视化语言数据集才包含700万个数据,对于训练一个成熟的AI模型来说显然是不够的。
“Vokenization”的出现就是要解决这个问题。像GPT-3是通过无监督学习来训练的,这不需要手动标记数据,才使它极易去扩展规模。Vokenization也采用了无监督的学习方法,将MS COCO中的小数据量增加到英文维基百科的级别。解决了数据源的数量差异问题,Vokenination还要面临第二个挑战,就是解决视觉监督和自然语言文本之间的联接问题。
Voken代替Token:让文本“看懂”世界
一般来看,自然语言中的词汇中很大一部分是没有视觉特征的,这为视觉监督提出了主要的挑战。我们知道,在AI训练语言模型中的单词被称之为Token(标记),而研究人员则把视觉语言模型中与每个Token相关的图像称之为Voken。而Vokenizer就代表为一个Token寻找一个Voken的算法,Vokenization就代表整个算法模型实现的过程。
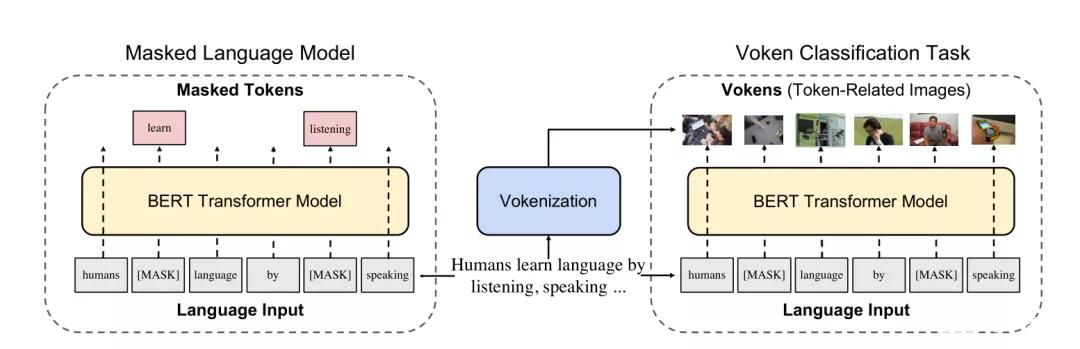
Vokenization的过程,就不是从图像数据集开始为图像标注标题,而是从一个语言数据集开始,采用无监督学习的方式,将每个单词与图像进行匹配,实现一个高扩展性,这就是解决第一个挑战的具体思路。与此同时,研究者还要解决第二个挑战的单词和图像的关联性问题。
GPT-3使用的是“单词嵌入”的方式,基于上下文来创建每个单词的数学表示,然后依赖这些嵌入把单词变成句子,把句子组合成段落。Vokenization采取了一种并行的嵌入技术用于扫描图像的视觉模式。研究者举的一个案例是,将猫出现在床上的频率和出现在树上的频率绘制成一个表格,并用这些信息创建一只“猫”的Voken。
研究者就在MS COCO数据集上同时采用了两种嵌入技术,把图像转换成视觉嵌入,把字幕转换成文字嵌入。这样做的优势之处在于,这两种嵌入可以在一个三维空间中绘制出来,并看到文字嵌入和视觉嵌入在图形中的相互关联,一只“猫”的视觉嵌入应该会和文本中的“猫”的嵌入相重叠。这能够解决什么问题呢?这给文本Token提供了一种图像化的Voken匹配,使得它能够有更加情景化的表示,对于一个抽象的词来说,也可以根据不同的上下文情境,具有了完全不同的意思。
比如,“Contact”这个词,在下图左侧的Voken的匹配下,它就代表“联系信息”的意思,在下图右侧的Voken的匹配下,就代表了“抚摸一只猫”的意思。说到这里,我们大概就能理解Voken的作用。当GPT-3模型对于一些文本概念无法准确理解其语境和相应语义的时候,它就容易开始自我发挥,胡言乱语,而一旦通过给这个Token找到图像化的Voken实例,就可以真正理解这个词的实际涵义。
现在,研究人员通过在MS COCO中创建的视觉和单词嵌入方法来训练Vokenizer算法,在英语维基百科中已经为40%的Token找到了Voken,尽管不到一半,但至少是30亿单词的数据集中的40%。基于这一数据集,研究人员重新训练了谷歌开发的BERT模型,并且在6种不同的语言理解的测试中测试了这一新模型,结果显示改进后的BERT在几个测试方面都表现良好。
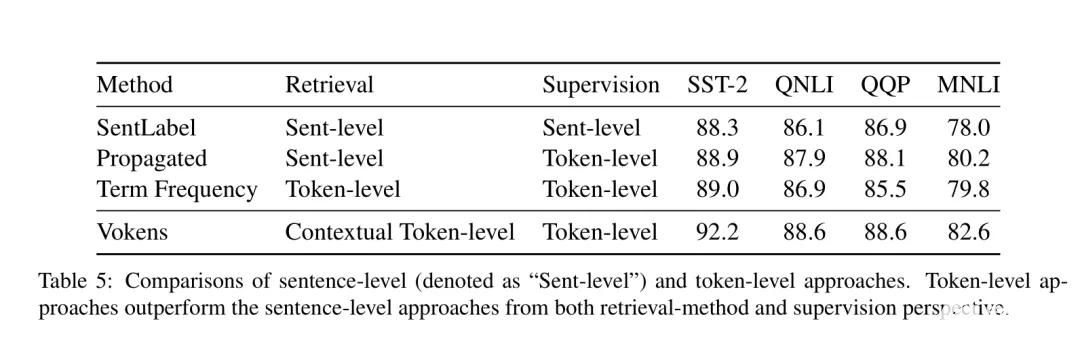
Vokenization现在还只是处在研究阶段,我们也只能从其论文的结果中窥探这一模型的效果,至于这项新的视觉语言化技术的应用和展示,还有待后面我们进一步追踪观察。不敢怎样,在无监督学习帮助下的视觉语言模型,成为NLP领域刚刚闪现的一朵火花,为自然语言处理打开了新的思路,使得纯粹的文本训练开始和图像识别联系起来。这就像让一个博闻强记的机器人从“自顾自说话”,变得可以听见和看见外界的真实状况,能够成为那个“睁开眼睛看世界”的人工智能。
最后,让我们重温一个经典的场景,在海伦凯勒的自传中,她描述了自己如何学会“Water”这个单词的含义。又盲又聋的海伦总是搞混“杯子”和“水”的指代,直到她的老师沙利文女士带着她来到喷池边,一边感受着清凉的泉水,一边感受着沙利文在她手心写下的“Water”,她这才终于明白了“水”的真实指代和含义。用她的话说“不知怎么回事,语言的秘密突然被揭开了,我终于知道水就是流过我手心的一种物质。这个叫“水”的字唤醒了我的灵魂……”
幸好,人类在失去光明和听觉之后,仅能通过触觉还能理解语言的奥秘,那么对于人工智能来说,拥有了强大的图像识别能力,又有近乎无限的文本知识,那么,未来AI将能否通向一条具有像人类在日常经验中学习的常识之路吗?
fqj
-
人工智能
+关注
关注
1813文章
49782浏览量
261863 -
nlp
+关注
关注
1文章
491浏览量
23203
发布评论请先 登录
GPT-5震撼发布:AI领域的重大飞跃

GPT-5.1发布 OpenAI开始拼情商
【HZ-T536开发板免费体验】3 - Cangjie Magic调用视觉语言大模型(VLM)真香,是不是可以没有YOLO和OCR了?
多智能体仿真中的统一混合模型框架研究

移远通信智能模组全面接入多模态AI大模型,重塑智能交互新体验


一种基于正交与缩放变换的大模型量化方法

马斯克发布Grok 3大模型,超越GPT-4o
OpenAI即将推出GPT-5模型

OpenAI将发布更智能GPT模型及AI智能体工具
OpenAI:GPT-4o及4o-mini模型性能下降,正展开调查
一种新的通用视觉主干模型Vision Mamba






 工商网监
工商网监
评论