 AMD刚刚发布7nm CDNA架构的MI100加速卡
AMD刚刚发布7nm CDNA架构的MI100加速卡

今晚AMD刚刚发布了7nm CDNA架构的MI100加速卡,NVIDIA这边就推出了A100 80GB加速卡。虽然AMD把性能夺回去了,但是A100 80GB的HBM2e显存也是史无前例了。
NVIDIA今年3月份发布了安培架构的A100加速卡(名字中没有Tesla了),升级了7nm工艺和Ampere安培架构,集成542亿晶体管,826mm2核心面积,使用了40GB HBM2显存,带宽1.6TB/s。
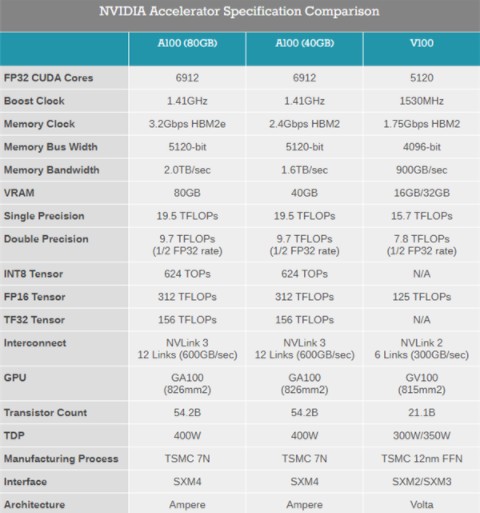
现在的A100 80GB加速卡在GPU芯片上没变化,依然是A100核心,6912个CUDA核心,加速频率1.41GHz,FP32性能19.5TFLOPS,FP64性能9.7TFLOPS,INT8性能624TOPS,TDP 400W。
变化的主要是显存,之前是40GB,HBM2规格的,带宽1.6TB/s,现在升级到了80GB,显存类型也变成了更先进的HBM2e,频率从2.4Gbps提升到3.2Gbps,使得带宽从1.6TB/s提升到2TB/s。
对游戏卡来说,这样的显存容量肯定是浪费了,但是在高性能计算、AI等领域,显存很容易成为瓶颈,所以翻倍到80GB之后,A100 80GB显卡可以提供更高的性能,NVIDIA官方信息称它的性能少则提升25%,多则提升200%,特别是在AI训练中,同时能效也提升了25%。
在A100 80GB加速卡发布之后,现在的A100 40GB版依然会继续销售。
责任编辑:pj
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
amd
+关注
关注
25文章
5717浏览量
140572 -
NVIDIA
+关注
关注
14文章
5714浏览量
110194 -
带宽
+关注
关注
3文章
1054浏览量
43633
发布评论请先 登录
相关推荐
热点推荐
AMD正式推出Instinct MI350P PCIe GPU加速卡
AMD于2026年5月8日正式推出Instinct MI350P PCIe GPU加速卡,作为四年来首款面向企业级市场的PCIe接口Instinct系列产品,其以“精简架构+极致能效”
瀚博半导体载天VA16加速卡成功适配DeepSeek-V4大模型
4月24日,深度求索正式开源全新系列模型DeepSeek-V4。瀚博半导体第一时间完成载天VA16加速卡的FP4+FP8 混合精度适配,加速大模型高并发、低成本落地。
选择AMD Alveo V80加速卡的五大理由
V80 是一款用途高度多样化的加速卡,业已应用于高性能计算、金融科技、数据分析、传感器处理、网络、存储等众多市场,能利用 AMD Versal 自适应 SoC 架构提供高效的量产路径。
AMD Alveo MA35D媒体加速卡的AMA SDK 1.4.0版本发布
我们非常高兴地宣布,面向 AMD Alveo MA35D 媒体加速卡的最新 AMA SDK 1.4.0 版本现已发布。该版本旨在为要求严苛的媒体工作负载提供坚如磐石的稳定性和性能提升。此次更新体现了我们致力于优化平台以适应生产环
FPGA硬件加速卡设计原理图:1-基于Xilinx XCKU115的半高PCIe x8 硬件加速卡 PCIe半高 XCKU115-3-FLVF1924-E芯片
FPGA硬件加速, PCIe半高卡, XCKU115, 光纤采集卡, 信号计算板, 硬件加速卡

新品 | LLM-8850 Kit,高性能AI加速卡套件 DinMeter v1.1,1/32DIN标准嵌入式开发板
LLM-8850KitLLM-8850Kit是一款面向边缘AI与嵌入式计算场景的高性能AI加速卡套件,由LLM-8850CardAI加速卡与LLM-8850PiHat转接板组成。核心加速卡

高速信号处理设计方案:413-基于双XCVU9P+C6678的100G光纤加速卡
C6678, XCVU9P, ZU19EG开发板,, 高速信号处理, 光纤加速卡, XCVU9P光纤加速卡
昆仑芯R200 AI加速卡技术规格解析
昆仑芯R200加速卡基于7nm XPU-R架构,在150W功耗下提供256 TOPS INT8算力,侧重高性能推理。配备最高32GB GDDR6内存(512GB/s带宽)及108路视频解码能力,支持

迈向云端算力巅峰:昆仑芯K200 AI加速卡全面解读
昆仑芯K200作为云端AI加速卡,在K100架构基础上全面升级。其INT8算力达256 TOPS,配备16GB HBM内存与512GB/s带宽,专为千亿参数大模型训练与高并发推理优化。采用全高全长双

专为边缘而生:深度解析昆仑芯K100 AI加速卡,释放128 TOPS极致能效
昆仑芯K100边缘AI加速卡以75W超低功耗实现128 TOPS的INT8算力,重新定义边缘推理能效标准。其半高半长设计搭载8GB HBM内存与256GB/s带宽,支持INT8至FP32多精度计算

深圳光量子工厂启示:PCI 加速卡为何偏向 25MHz 2016 有源晶振?
在 PCI 加速卡项目中,工程师使用SJK 2016 系列有源晶振 25MHZ。原因不仅仅是规格匹配,更在于系统复杂度。

算力密度翻倍!江原D20加速卡发布,一卡双芯重构AI推理标杆
的关键技术瓶颈。 在此背景下,江原科技推出采用自研AI芯片的AI加速卡江原D10,并在今年5月实现量产交付。在大算力AI芯片全流程国产化产业链实现首次突破后,11月11日,江原科技再次发布新一代全国产AI加速卡——江原D20

虚拟电厂加速卡不是噱头!万点规模VPP的性能分水岭
。 此时仅靠边缘MPU/CPU的通用算力,可能无法及时处理数据清洗、异常检测、指令下发校验等任务,而加速卡(如 GPU、FPGA 加速卡)的并行计算能力可快速消化数据洪流,避免“小包风暴”导致的系统卡顿。 虚拟电厂对AG
AMD 7nm Versal系列器件NoC的使用及注意事项
AMD 7nm Versal系列器件引入了可编程片上网络(NoC, Network on Chip),这是一个硬化的、高带宽、低延迟互连结构,旨在实现可编程逻辑(PL)、处理系统(PS)、AI引擎(AIE)、DDR控制器(DDRMC)、CPM(PCIe/CXL)等模块之间
智算加速卡是什么东西?它真能在AI战场上干掉GPU和TPU!
随着AI技术火得一塌糊涂,大家都在谈"大模型"、"AI加速"、"智能计算",可真到了落地环节,算力才是硬通货。你有没有发现,现在越来越多的AI企业不光用GPU,也不怎么迷信TPU了?他们嘴里多了一个新词儿——智算加速卡。




评论