 PWIL:不依赖对抗性的新型模拟学习
PWIL:不依赖对抗性的新型模拟学习

强化学习 (Reinforcement Learning,RL) 是一种通过反复试验训练智能体 (Agent) 在复杂环境中有序决策的范式,在游戏、机器人操作和芯片设计等众多领域都取得了巨大成功。智能体的目标通常是最大化在环境中收集的总奖励 (Reward),这可以基于速度、好奇心、美学等各种参数。然而,由于 RL 奖励函数难以指定或过于稀疏,想要设计具体的 RL 奖励函数并非易事。
游戏
https://ai.googleblog.com/2019/06/introducing-google-research-football.html
这种情况下,模仿学习(Imitation Learning,IL) 方法便派上了用场,因为这种方法通过专家演示而不是精心设计的奖励函数来学习如何完成任务。然而,最前沿 (SOTA) 的 IL 方法均依赖于对抗训练,这种训练使用最小化/最大化优化过程,但在算法上不稳定并且难以部署。
在“原始 Wasserstein 模仿学习”(Primal Wasserstein Imitation Learning,PWIL) 中,我们基于 Wasserstein 距离(也称为推土机距离)的原始形式引入了一种新的 IL 方法,这种方法不依赖对抗训练。借助 MuJoCo 任务套件,我们通过有限数量的演示(甚至是单个示例)以及与环境的有限交互来模仿模拟专家,以此证明 PWIL 方法的有效性。
原始 Wasserstein 模仿学习
https://arxiv.org/pdf/2006.04678.pdf
MuJoCo 任务套件
https://gym.openai.com/envs/#mujoco

左图:使用任务的真实奖励(与速度有关)训练的算法类人机器人“专家”;右图:使用 PWIL 基于专家演示训练的智能体
对抗模仿学习
最前沿的对抗 IL 方法的运作方式与生成对抗网络 (GAN) 类似:训练生成器(策略)以最大化判别器(奖励)的混淆度,以便判别器本身被训练来区分智能体的状态-动作对和专家的状态-动作对。对抗 IL 方法可以归结为分布匹配问题,即最小化度量空间中概率分布之间距离的问题。不过,就像 GAN 一样,对抗 IL 方法也依赖于最小化/最大化优化问题,因此在训练稳定性方面面临诸多挑战。
训练稳定性方面面临诸多挑战
https://developers.google.com/machine-learning/gan/problems
模仿学习归结为分步匹配
PWIL 方法的原理是将 IL 表示为分布匹配问题(在本例中为 Wasserstein 距离)。第一步为从演示中推断出专家的状态-动作分布:即专家采取的动作与相应环境状态之间的关系的集合。接下来的目标是通过与环境的交互来最大程度地减少智能体的状态-动作分布与专家的状态-动作分布之间的距离。相比之下,PWIL 是一种非对抗方法,因此可绕过最小化/最大化优化问题,直接最小化智能体的状态-动作对分布与专家的状态-动作对分布之间的 Wasserstein 距离。
PWIL 方法
计算精确的 Wasserstein 距离会受到限制(智能体轨迹结束时才能计算出),这意味着只有在智能体与环境交互完成后才能计算奖励。为了规避这种限制,我们为距离设置了上限,可以据此定义使用 RL 优化的奖励。
结果表明,通过这种方式,我们确实可以还原专家的行为,并在 MuJoCo 模拟器的许多运动任务中最小化智能体与专家之间的 Wasserstein 距离。对抗 IL 方法使用来自神经网络的奖励函数,因此,当智能体与环境交互时,必须不断对函数进行优化和重新估计,而 PWIL 根据专家演示离线定义一个不变的奖励函数,并且它所需的超参数量远远低于基于对抗的 IL 方法。
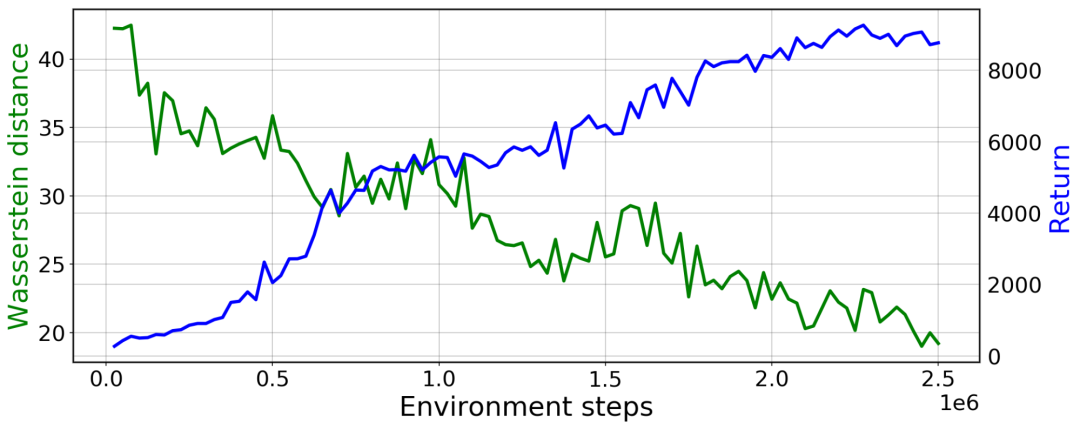
PWIL 在类人机器人上的训练曲线:绿色表示与专家状态-动作分布的 Wasserstein 距离;蓝色表示智能体的回报(所收集奖励的总和)
类人机器人
https://gym.openai.com/envs/Humanoid-v2/
衡量真实模仿学习环境的相似度
与 ML 领域的众多挑战类似,许多 IL 方法都在合成任务上进行评估,其中通常有一种方法可以使用任务的底层奖励函数,并且可以根据性能(即预期的奖励总和)来衡量专家行为与智能体行为之间的相似度。
PWIL 过程中会创建一个指标,该指标可以针对任何 IL 方法。这种方法能将专家行为与智能体行为进行比较,而无需获得真正的任务奖励。从这个意义上讲,我们可以在真正的 IL 环境中使用 Wasserstein 距离,而不仅限于合成任务。
结论
在交互成本较高的环境(例如,真实的机器人或复杂的模拟器)中,PWIL 可以作为首选方案,不仅因为它可以还原专家的行为,还因为它所定义的奖励函数易于调整,且无需与环境交互即可定义。
这为未来的探索提供了许多机会,包括部署到实际系统、将 PWIL 扩展到只能使用演示状态(而不是状态和动作)的设置,以及最终将 PWIL 应用于基于视觉的观察。
责任编辑:lq
-
模拟器
+关注
关注
2文章
992浏览量
45381 -
智能体
+关注
关注
1文章
387浏览量
11520 -
强化学习
+关注
关注
4文章
269浏览量
11903
原文标题:PWIL:不依赖对抗性的新型模拟学习
文章出处:【微信号:tensorflowers,微信公众号:Tensorflowers】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
储能类电池管理系统BMS HiL解决方案

请问OTA是否一定依赖于ymodem协议?
太阳光模拟器 | 光辐射测量的基础知识

NVMe IP高速传输却不依赖XDMA设计之九:队列管理模块(上)
NVMe IP高速传输却不依赖XDMA设计之八:系统初始化
NVMe IP高速传输却不依赖XDMA设计之六:性能监测单元设计
NVMe IP高速传输却不依赖XDMA设计之五:DMA 控制单元设计
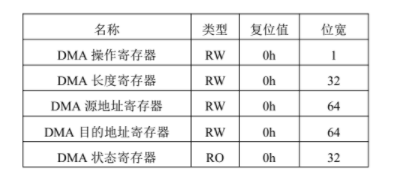
NVMe IP高速传输却不依赖XDMA设计之五:DMA 控制单元设计
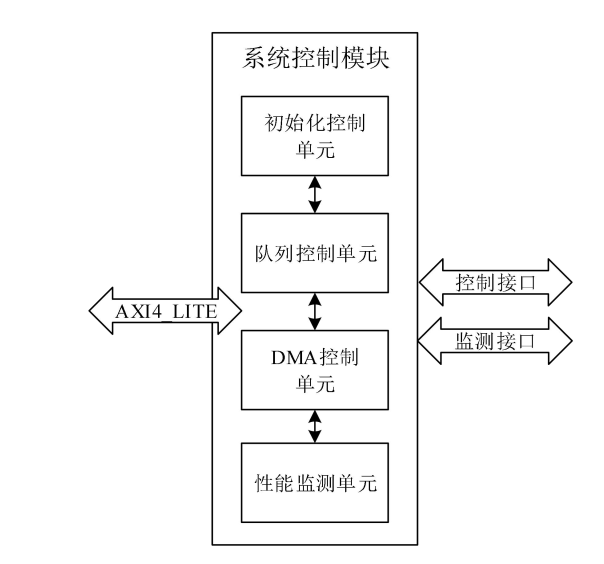
NVMe IP高速传输却不依赖XDMA设计之四:系统控制模块
NVMe IP高速传输却不依赖XDMA设计之三:系统架构
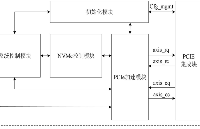
NVMe IP高速传输却不依赖便利的XDMA设计之三:系统架构
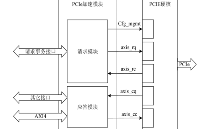
NVMe IP高速传输却不依赖XDMA设计之二:PCIe读写逻辑
GPS对时设备,不依赖互联网的"独立时钟"






 工商网监
工商网监
评论