 NVMe IP高速传输却不依赖XDMA设计之二:PCIe读写逻辑
NVMe IP高速传输却不依赖XDMA设计之二:PCIe读写逻辑

NVMe IP放弃XDMA原因
选用XDMA做NVMe IP的关键传输模块,可以加速IP的设计,但是XDMA对于开发者来说,还是不方便,原因是它就象一个黑匣子,调试也非一番周折,尤其是后面PCIe4.0升级。因此决定直接采用PCIe设计,虽然要费一番周折,但是目前看,还是值得的,我们uvm验证也更清晰。
PCIe 写应答模块设计
应答模块的具体任务是接收来自PCIe链路上的设备的TLP请求,并响应请求。由于基于PCIe协议的NVMe数据传输只使用PCIe协议的存储器读请求TLP和存储器写请求TLP,应答模块分别针对两种TLP设置处理引擎来提高并行性和处理速度。
对于存储器写请求TLP,该类型的TLP使用Posted方式传输,即不需要返回完成报文,因此只需要接收并做处理,这一过程由写处理模块来执行,写处理模块的结构如图1所示。

图1 TLP写处理结构
当axis_cq 总线中出现数据流传输时,应答模块首先对传输的TLP报头的类型字段进行解析,如果为存储器写请求则由写处理模块进一步解析。写处理模块提取出TLP 报头的地址字段、长度字段等,然后将数据字段写入数据缓存中。提取出的地址字段用于进行地址映射,在NVMe协议中,设备端的请求写分为两种,分别是写完
成队列和写数据,因此地址映射的定向对应为队列管理模块的完成条目处理单元和数据传输AXI总线的写通道。完成条目的字段长度为128比特,因此无需进行数据缓存,跟随地址映射发送到队列管理模块。AXIMaster驱动负责将解析的字段与缓存的数据组成AXI写传输事务发送到AXI写通道,实现数据的写传输。
PCIe 读应答模块设计
对于存储器读请求TLP,使用Non-Posted方式传输,即在接收到读请求后,不仅要进行处理,还需要通过axis_cc总线返回CplD,这一过程由读处理模块执行,读处理模块的结构如图2所示。
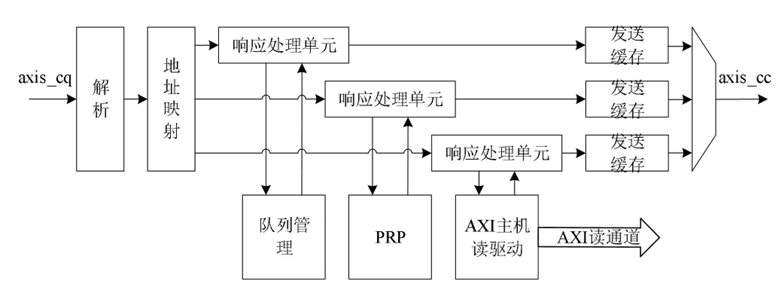
图2 TLP读处理模块结构
当axis_cq 总线接收到存储器读请求时,数据流被转发到读处理模块。读请求TLP只包含128比特的请求报头,而axis总线位宽也是128比特,因此在短时间内可能接收到多个读请求,为了应对这种情况,读处理模块采用了带有outstanding能力和事务并行处理的结构设计,能够有效提高读请求事务处理效率和数据传输吞吐量。
首先当读请求数据流到达读处理模块时,经过解析和地址映射的两级流水后,放入响应处理单元outstanding 缓存中,响应处理单元从缓存中获取事务一一处理,将读取的数据打包成CplD,并将CplD放置到发送缓存中等待axis_cc总线的发送。根据地址的不同,读请求事务被分为三类,分别是读队列请求,读PRP请求和读数据请求,每种请求对应一个响应处理单元。
在实际应用环境中,由于队列、PRP、数据的存储往往在不同的位置,因此完成读取过程的延迟也不同,在本课题中,将队列管理与PRP都放置在了近PCIe端存储,因此读取队列与PRP的延迟远远小于读取数据的延迟。并且当大量不同的读请求交叉处理时,读处理模块的并行处理结构更能够充分利用PCIe的乱序传输能力来提高
吞吐量。为了清晰的说明读处理模块对吞吐量的提升,设置如图3所示的简单时序样例,样例中PCIeTLP的tag最大为3。
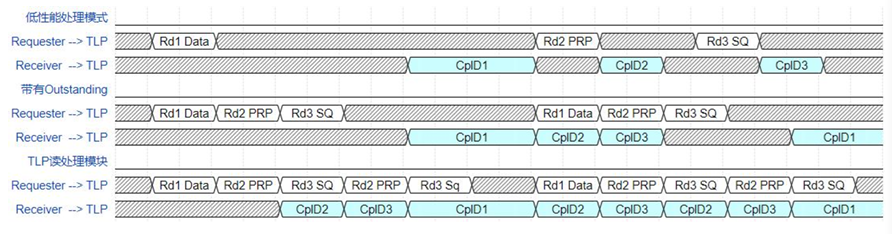
图3 TLP 读处理时序图
在对应图3中第1、2行时序的低性能处理模式下,同一时间只能处理一个读事务,并且不带有outstanding能力,此时从接收到读请求到成功响应所经历的延迟将会累积,造成axis_cq 请求总线的阻塞。在对应图中第3、4行时序的仅带有outstanding 能力的处理模式下,虽然可以连续接收多个读请求处理,但同一时间内只能处理一个事务,仍会由于较大的处理延迟导致axis总线存在较多的空闲周期,实际的数据传输效率并不高。在对应图中第5、6行时序的读处理模块处理模式下,利用多个响应处理单元的并行处理能力和发送缓存,先行处理完成的CplD可以优先发送,紧接着可以处理下一事务,使总线的传输效率和吞吐量明显提高。
-
FPGA
+关注
关注
1664文章
22502浏览量
639128 -
PCIe
+关注
关注
16文章
1477浏览量
88914 -
高速传输
+关注
关注
0文章
45浏览量
9319 -
nvme
+关注
关注
0文章
300浏览量
23909
发布评论请先 登录
Xilinx FPGA NVMe Host Controller IP,NVMe主机控制器
NVMe IP高速传输却不依赖便利的XDMA设计之三:系统架构
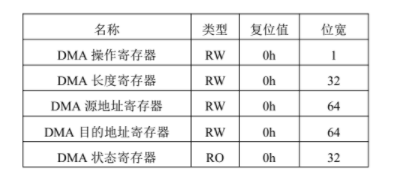
NVMe IP高速传输却不依赖XDMA设计之五:DMA 控制单元设计
NVMe高速传输之摆脱XDMA设计18:UVM验证平台
NVMe高速传输之摆脱XDMA设计43:如何上板验证?
ZYNQ调用XDMA PCIE IP同时读写PS DDR,导致蓝屏问题。
NVMe IP over PCIe 4.0:摆脱XDMA,实现超高速!
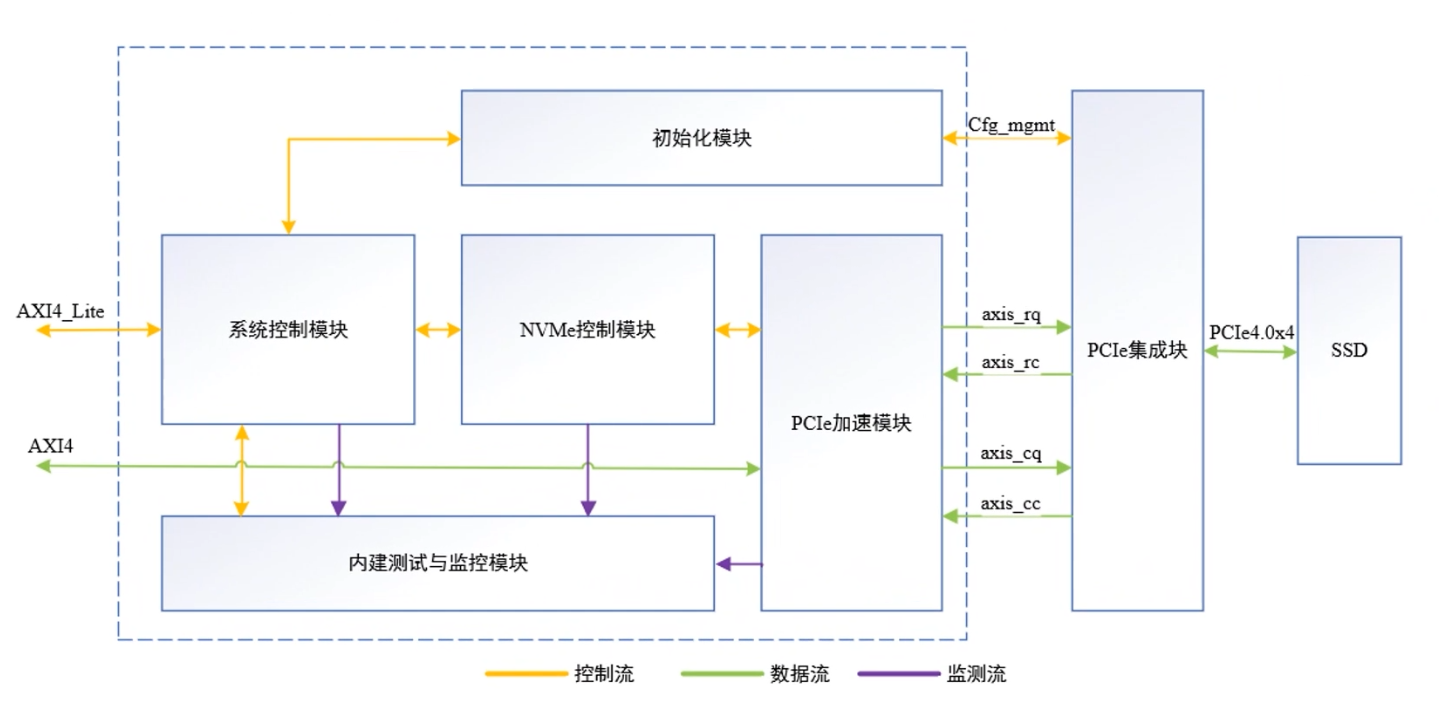
NVMe IP高速传输却不依赖XDMA设计之三:系统架构
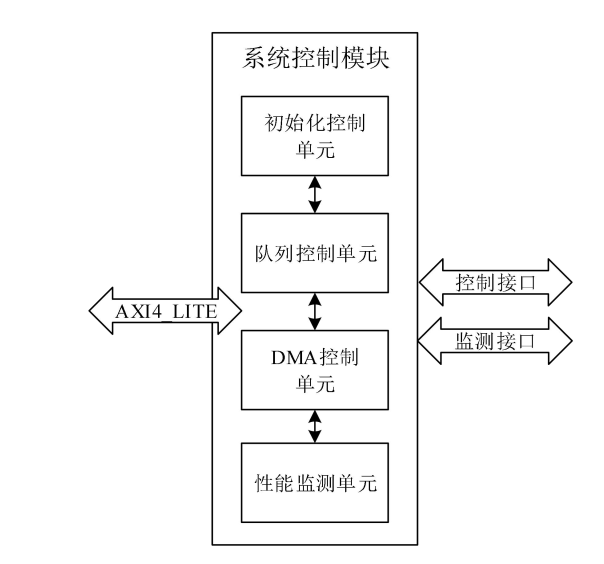
NVMe IP高速传输却不依赖XDMA设计之四:系统控制模块
NVMe IP高速传输却不依赖XDMA设计之五:DMA 控制单元设计
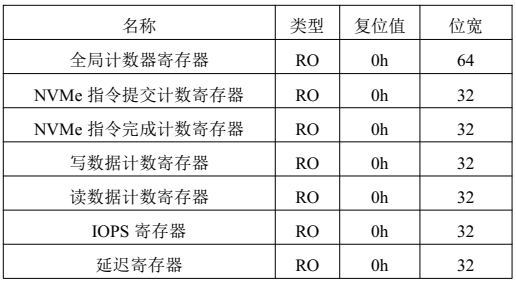
NVMe IP高速传输却不依赖XDMA设计之六:性能监测单元设计
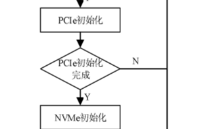
NVMe IP高速传输却不依赖XDMA设计之八:系统初始化
NVMe IP高速传输却不依赖XDMA设计之九:队列管理模块(上)



评论