 新一代AI/ML加速器新型内存解决方案——HBM2E内存接口
新一代AI/ML加速器新型内存解决方案——HBM2E内存接口

近年来,随着内存带宽逐渐成为影响人工智能持续增长的关键焦点领域之一,以高带宽内存(HBM、HBM2、HBM2E)和GDDR开始逐渐显露头角,成为搭配新一代AI/ML加速器和专用芯片的新型内存解决方案。
人工智能/机器学习(AI/ML)在全球范围内的迅速兴起,正推动着制造业、交通、医疗、教育和金融等各个领域的惊人发展。从2012年到2019年,人工智能训练能力增长了30万倍,平均每3.43个月翻一番,就是最有力的证明。支持这一发展速度需要的远不止摩尔定律,人工智能计算机硬件和软件的各个方面都需要不断的快速改进。
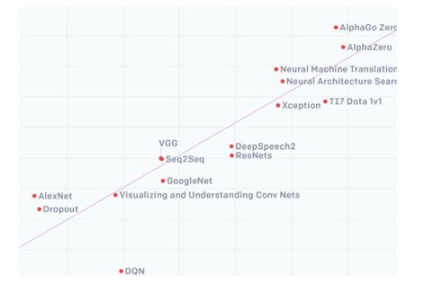
2012-2019年,人工智能训练能力增长30万倍(图片来源:openai.com)
而中国作为全球人工智能发展最快的国家之一,正备受瞩目。根据德勤最新发布的统计预测数据显示,2020年全球人工智能市场规模将达到6800亿元人民币,复合增长率(CAGR)达26%。而中国人工智能市场的表现尤为突出,2019年末已经达到了510亿元人民币的市场规模,人工智能企业超过2600家。预计到2020年,中国AI市场规模将达到710亿元人民币,五年间(2015-2020)的复合增长率高达44.5%。
近年来,中国正在积极推动人工智能与实体经济的融合,从而实现产业的优化升级。2017年7月,国务院印发了《新一代人工智能发展规划》,这一规划与2015年5月发布的《中国制造2025》共同构成了中国人工智能战略的核心。这份具有里程碑意义的规划,对人工智能发展进行了战略性部署,力争到2030年把中国建设成为世界主要人工智能创新中心。此外,2020年还是中国的新基建元年,而人工智能作为一大重点板块,势必成为新基建的核心支撑。
内存带宽将是影响AI发展的关键因素
“内存带宽将成为人工智能持续增长的关键焦点领域之一。”Rambus IP核产品营销高级总监 Frank Ferro日前在接受《电子工程专辑》采访时表示,以先进的驾驶员辅助系统(ADAS)为例,L3级及更高级别系统的复杂数据处理需要超过200GB/s的内存带宽。这些高带宽是复杂AI/ML算法的基本需求,自驾过程中需要这些算法快速执行大量计算并安全地执行实时决策。而在L5级,如果车辆要能够独立地对交通标志和信号的动态环境做出反应,以便准确地预测汽车、卡车、自行车和行人的移动,将需要超过500GB/s的内存带宽。

不同ADAS级别对存储带宽的要求(图片来源:anandtech.com)
鉴于此,高带宽内存(HBM、HBM2、HBM2E)和GDDR开始逐渐显露头角,成为搭配新一代AI/ML加速器和专用芯片的新型内存解决方案。他说过去几年内,HBM、HMC、PAM4等标准在市场上展开了激烈的竞争,但从目前的发展态势来看,还是HBM占据了更多的市场份额。不过他同时也坦承,由于汽车安全等级要求很高,考虑到HBM本身采用的是复杂的2.5D架构,再结合DRAM设备,所以目前为止在汽车市场上并没有得到突破性的应用,相比之下,GDDR反而会是比较好的解决方案。
高带宽内存(HBM)于2013年推出,是一种高性能3D堆栈SDRAM构架。与前一代产品一样,HBM2为每个堆栈包含最多8个内存芯片,同时将管脚传输速率翻倍,达到2Gbps。HBM2实现每个封装256GB/s的内存带宽(DRAM堆栈),采用HBM2规格,每个封装支持高达8GB的容量。
2018年末,JEDEC宣布推出HBM2E规范,以支持增加的带宽和容量。当传输速率上升到每管脚3.6Gbps时,HBM2E可以实现每堆栈461GB/s的内存带宽。此外,HBM2E支持12个DRAM的堆栈,内存容量高达每堆栈24GB。

单一DRAM堆栈的HBM2E内存系统(图片来源:Rambus)
HBM2E提供了达成巨大内存带宽的能力。连接到一个处理器的四块HBM2E内存堆栈将提供超过1.8TB/s的带宽。通过3D堆叠内存,可以以极小的空间实现高带宽和高容量需求。进一步,通过保持相对较低的数据传输速率,并使内存靠近处理器,总体系统功率得以维持在较低水位。
坦率的说,采用HBM的设计的代价是增加复杂性和成本,因此Frank Ferro并不建议在人工智能推理应用中使用HBM技术。然而,对于人工智能训练应用,HBM2E的优点使其成为一个更好的选择。它的性能非常出色,所增加的采用和制造成本可以透过节省的电路板空间和电力相互的缓解。在物理空间日益受限的数据中心环境中,HBM2E紧凑的体系结构提供了切实的好处。它的低功率意味着它的热负荷较低,在这种环境中,冷却成本通常是几个最大的运营成本之一。官方数据显示,Rambus IP系统以及IP产品在实验室经过了非常严苛的环境测试,确保从零下50到125摄氏度范围内均能够正常运行。
同时,Frank Ferro也不认为在芯片上采取分布式内存的方法会给HBM2E和GDDR长期的发展带来影响。原因在于尽管SRAM的速度和延迟性都高于DRAM,但在固定的芯片面积上能安装的SRAM数量却非常少,很多情况下为了满足人工智能训练的需求,一部分SRAM设备不得不装在芯片之外,这就是问题所在。但总体来说,这两种方案属于从不同角度出发解决同一个问题,两者之间是互补而非相互阻碍。
创纪录的性能
针对高带宽和低延迟进行了优化,Rambus HBM2E内存接口解决方案实现了创纪录的4Gbps性能。该解决方案由完全集成且经过验证的PHY和内存控制器IP组成,搭配SK Hynix 3.6Gbps运行速度的HBM2E DRAM,在物理层面实现了完整的集成互联,可以从单个HBM2E设备提供460GB/s的带宽,这也被Frank Ferro视作其HBM2E 产品的核心差异化优势之一。这意味着,除了提供完整的内存子系统、硬核PHY和时序收敛外,用户额外需要的系统级支持、工具套件和技术服务也都包含在内,集成难度和设计时间得以大幅度下降。
Rambus HBM2E 4Gbps发送端眼图(图片来源:Rambus)
从2017年正式投产HBM解决方案以来,Rambus目前已经拥有第三代PHY和第二代内存控制器IP,全球范围内的成功案例项目超过50个。除了4Gbps HBM2E外,Rambus在其他不同工艺节点的产品还包括采用Global Foundries 12nm/14nm工艺的HBM2,速度为2.0 Gbps/s;采用Global Foundries 12LP+和三星14nm/11nm工艺的HBM2E产品。
不可否认,4.0Gbps是一个全新的行业标杆。在这一过程中,Rambus与SK hynix和Alchip展开了合作,采用台积电N7工艺和CoWoS®先进封装技术,实现了HBM2E 2.5D系统在硅中验证Rambus HBM2E PHY和内存控制器IP。Alchip与Rambus的工程团队共同设计,负责中介层和封装基板的设计。
“在我们提供的完整参考设计框架中,最重要的一点就是如何更好地对中介层进行完整的设计和表征化处理,以确保信号完整性。此外,我们还协助用户对每个信号通道进行仿真分析,通过Lab Station工具对内存子系统进行最优化设计,并提供在SI高速信号完整性和电源完整性方面的经验等等。”Frank Ferro说Rambus的初衷,不仅仅只是扮演IP供应商的角色,更是希望在系统层面降低用户设计难度。
信号完整性之所以如此重要,是因为HBM作为高速内存接口,在与中介层互联的过程中包括至少上千条不同的数据链路,必须要确保所有链路的物理空间得到良好的控制,整个信号的完整性也必须得到验证。因此,Rambus的做法如果从表征化层面来讲,不但需要对整个中介层的材料做出非常精细的选择,还要考虑渐进层的厚度以及整个电磁反射相关的物理参数,并在此基础上进行完整的分析和仿真,以实现信号一致性的处理。
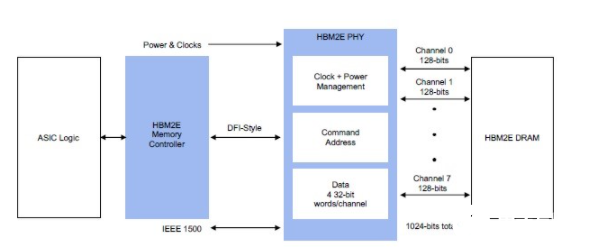
HBM2E内存接口子系统示例
燧原科技是Frank Ferro在发布会上提及的中国合作伙伴。在此次合作中,燧原科技为自己下一代人工智能训练芯片选择了Rambus HBM2 PHY和内存控制器IP,可实现2Tb/s的性能。而在今年4月和5月,长鑫存储、兆易创新两家公司还分别和Rambus签署了DRAM(动态随机存取存储)与RRAM(电阻式随机存取存储器,也可写作ReRAM)技术专利授权。
Rambus大中华区总经理 Raymond Su表示,通过对IP控制器公司Northwest Logic和Verimatrix安全IP业务部门的收购,Rambus实现了在内存IP层面提供一站式采购和“turn key”服务的目标。接下来,在中国市场,公司将紧密地与云厂商、OEM和ODM合作,推动整个内存产业生态系统的建设。
编辑:hfy
-
DRAM
+关注
关注
41文章
2409浏览量
189771 -
信号完整性
+关注
关注
68文章
1506浏览量
98358 -
AI
+关注
关注
91文章
42141浏览量
303134 -
人工智能
+关注
关注
1821文章
50540浏览量
267860 -
adas
+关注
关注
311文章
2362浏览量
212253
发布评论请先 登录
AI加速器需求倒逼HBM4量产加速,三家国际存储巨头亮出进度表

ICSSSTUF32866E:DDR2内存模块的理想配置缓冲器
德明利推出CKD DDR5内存条 为AI PC提供稳定高频内存解决方案

华为发布新一代绿色AI站点和GW级AIDC解决方案
不同于HBM垂直堆叠,英特尔新型内存ZAM技术采用交错互连拓扑结构

AI大算力的存储技术, HBM 4E转向定制化

工业级-专业液晶图形显示加速器RA8889ML3N简介+显示方案选型参考表
你相信光吗?| Samtec助力AI/ML系统拓扑中的光连接

华邦电子重新定义AI内存:为新一代运算打造高带宽、低延迟解决方案
英特尔Gaudi 2E AI加速器为DeepSeek-V3.1提供加速支持




评论