引言 目前,大多数自由文本搜索技术采用类似于Lucene的策略,通过解析搜索文本为各个组成部分来定位关键词。这种方法在处理少量关键词时表现良好。但当搜索的关键词数量达到10万个或更多时,这种方法
2024-08-26 15:55:47 1795
1795 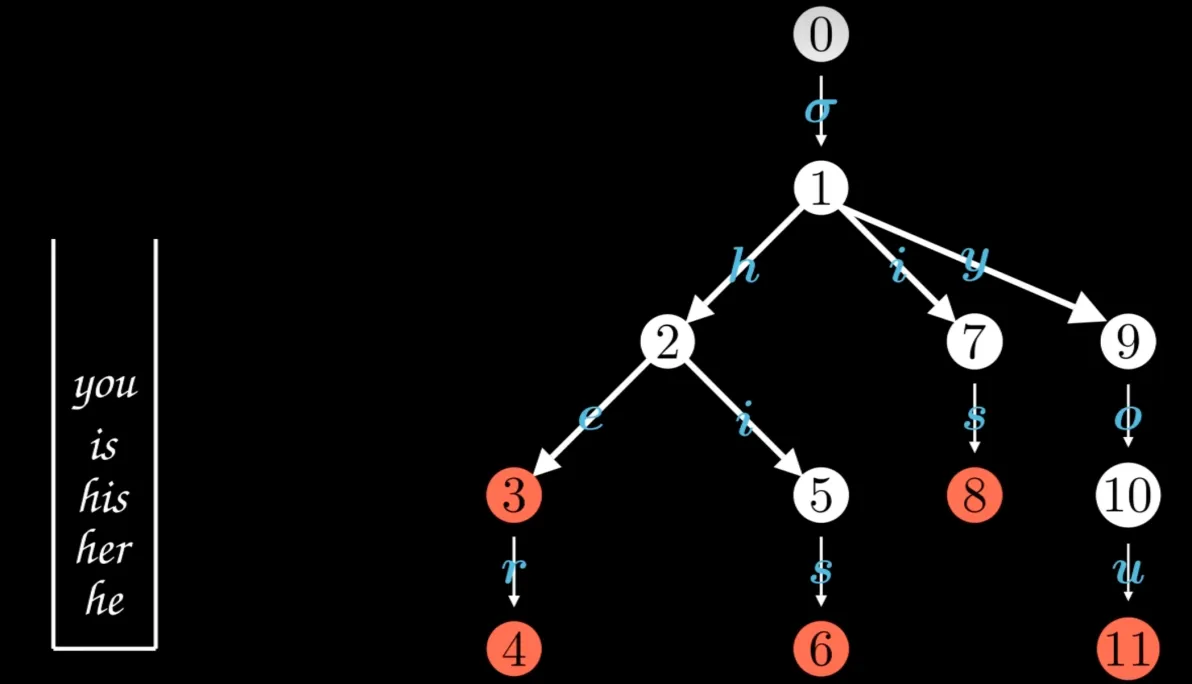
FPGA 年度关键词,我的想法是“标准化”;今年的工作中遇到了不少同事的issues,本身都是小问题或者很细节的东西但是却反复出现问题,目前想到的最好的办法是做好设计规则的标准化才能避免,不知道大家有没有更好的建议?
2023-12-06 20:31:23
·支持中文分词(N-最短路分词、CRF分词、索引分词、用户自定义词典、词性标注),命名实体识别(中国人名、音译人名、日本人名、地名、实体机构名识别),关键词提取,自动摘要,短语提取,拼音转换
2019-04-24 10:05:03
TextRank算法的具体细节,在实际应用中可能不合理。因为会存在:现有统计信息不足以让TextRank支持 某个词 的重要性,算法有局限性。可见:TextRank提取关键词是受到分词结果的影响的;其次
2018-11-05 10:41:25
。一篇文本中不是所有词都很重要,我们只需找出起到关键作用、决定文本主要内容的词进行分析即可。目前几大主流的分词技术可移步到这篇博客中:中文分词技术小结、几大分词引擎的介绍与比较笔者采用的是HanLP分词
2019-01-11 14:32:15
如何在一段文本之中提取出相应的关键词呢? 之前我有想过用机器学习的方法来进行词法分析,但是在项目中测试时正确率不够。于是这时候便有了 HanLP-汉语言处理包 来进行提取关键词的想法。下载:.jar
2018-11-09 14:54:48
的过程HanLP参考博客:词性标注层叠HMM-Viterbi角色标注模型下的机构名识别分词在HMM与分词、词性标注、命名实体识别中说:分词:给定一个字的序列,找出最可能的标签序列(断句符号:[词尾或[非
2018-12-05 10:52:43
的过程HanLP参考博客:词性标注层叠HMM-Viterbi角色标注模型下的机构名识别分词在HMM与分词、词性标注、命名实体识别中说:分词:给定一个字的序列,找出最可能的标签序列(断句符号:[词尾]或
2018-10-29 11:35:41
与DoubleArrayTrie或BinTrie中的自定义词进行合并,最终返回输出结果HanLP作者在HanLP issue783:上面说:词典不等于分词、分词不等于自然语言处理;推荐使用语料而不是词典去修正
2018-11-02 11:05:07
HanLP是由一系列模型与算法组成的Java工具包,目标是促进自然语言处理在生产环境中的应用。HanLP具备功能完善、性能高效、架构清晰、语料时新、可自定义的特点。HanLP能提供以下功能:关键词
2018-11-07 09:21:44
= 4c396f3039230ddfcef20865264512b1Portable 版同步升级到 v1.7.0HanLP v1.7.1 更新内容:新增可自定义用户词典的维特比分词器 @AnyListen利用
2019-03-22 09:56:52
。昨天正好看到的这篇关于关于1.7.0版本hanlp分词在spark中的使用介绍的文章,顺便分享给大家一起学习一下!以下为分享的文章内容:HanLP分词,如README中所说,如果没有特殊需求,可以通过
2019-03-11 15:38:38
CRFLexicalAnalyzer的构造函数即可创建分词器,同时HanLP会自动创建二进制缓存.txt.bin,下次加载耗时将控制在数百毫秒内。预测可通过如下方式加载:CRFSegmenter segmenter
2019-02-18 15:28:50
。为了缩短时间,首先进行分词,一个词输出为一行方便统计,分词工具选择的是HanLp。然后,将一个领域的文档合并到一个文件中,并用“$$”标识符分割,方便记录文档数。下面是选择的领域语料(PATH目录
2018-11-14 10:03:44
双数组Trie树(DoubleArrayTrie)储存,得到了一个高性能的中文分词器。开源项目本文代码已集成到HanLP中开源CRF简介CRF是序列标注场景中常用的模型,比HMM能利用更多的特征,比
2018-10-19 11:46:21
;关键字提取:");28getMainIdea();29System.out.println("\n");3031 System.out.println("自动摘要
2018-11-30 13:11:16
分词器Jcseg 是基于 mmseg 算法的一个轻量级中文分词器,同时集成了关键字提取,关键短语提取,关键句子提取和文章自动摘要等功能,并且提供了一个基于 Jetty 的 web 服务器,方便各大语言
2018-10-12 11:23:25
本篇分享一个hanlp分词工具应用的案例,简单来说就是做一图库,让商家轻松方便的配置商品的图片,最好是可以一键完成配置的。先看一下效果图吧: 商品单个推荐效果:匹配度高的放在最前面这个想法很好,那
2019-08-07 11:47:57
。接下来验证一下,分词器的宣传语是否得当吧。jieba 中文分词thulac 中文分词fool 中文分词HanLP 中文分词中科院分词 nlpir哈工大ltp 分词以上可以看出分词的时间,为了方便比较进行
2019-02-26 15:00:18
),命名实体识别(中国人民、音译人民、日本人民,地名,实体机构名识别),关键词提取,自动摘要,短语提取,拼音转换,简繁转换,文本推荐,依存句法分析(MaxEnt依存句法分析、神经网络依存句法分析)。提供
2019-01-02 14:43:15
矩阵模型,以一个词的起始位置作为行,终止位置作为列,可以得到一个二维矩阵。例如:“他说的确实在理”这句话 图词的存储方法:一种是的DynamicArray法,一种是快速offset法。Hanlp代码中
2018-11-07 10:56:12
),也就是说,lsi+tfidf模型对词细粒度大、分词少的分词器不友好,所以最后hanlp出错率更大。jieba与hanlp都是很不错的分词器,结巴使用更方便。hanlp准确度要高一些(感觉),而且
2019-02-18 10:29:06
的方法,都是需要我们慢慢的去挖掘在已有的基础上面去拓展思维。东莞seo博客总结,我们想要做好关键词优化排名,那么我们需要对于关键词进行合理的布局和思考,运用以上为大家介绍的一些方法去实时的操作,还需要再
2019-08-11 01:19:18
IOException速度目前感知机分词是所有“由字构词”的分词器实现中最快的,比自己写的CRF解码快1倍。新版CRF词法分析器框架复用了感知机的维特比解码算法,所以速度持平。l 测试时需关闭词法分析器
2019-04-03 11:28:47
`功能介绍1、图片列表展示2、输入文本3、分词4、通用文字识别5、结果展示效果演示使用说明在"请输入关键词"下面的输入框中输入需要分词的关键词,点击【开始通用文字
2021-04-14 22:38:35
功能介绍1、图片列表展示2、输入文本3、分词4、通用文字识别5、结果展示效果演示使用说明在"请输入关键词"下面的输入框中输入需要分词的关键词,点击【开始通用文字识别】按钮进行关键词搜索图片,您将会在"搜索结果"下方看到包含关键词的图片。
2021-04-14 22:35:43
从零学Elasticsearch系列——集成中文分词器IK
2020-03-10 11:07:25
了System.out.println("标准分词:");System.out.println(HanLP.segment("你好,欢迎使用HanLP!"
2018-11-08 15:39:04
allWords是上一步中得到的所有的词,sentWords是第一步中对单个句子的分词结果:4、计算相似度(两个向量的余弦值):以上所有方法的完整代码如下
2019-02-23 10:27:38
, 可以作为分词标注器的用户词典导入,从而使分词结果更加准确。(2)关键词提取 关键词提取能够对单篇文章或文章集合,提取出若干个代表文章中心思想的 词汇或短语,可用于精化阅读、语义查询和快速匹配等
2019-11-14 17:04:43
,lsi+tfidf模型对词细粒度大、分词少的分词器不友好,所以最后hanlp出错率更大。jieba与hanlp都是很不错的分词器,结巴使用更方便。hanlp准确度要高一些(感觉),而且与文中提到的词向量相匹配
2018-11-14 11:07:19
表示,对一些取用水项目进行区域的限批," \66."严格地进行水资源论证和取水许可的批准。"67. print("="*30+"关键词提取
2018-10-31 11:05:07
, 技术/n, 博客/n, !每个词段后的 /nx,/w之类的是 HanLP定义的词性,可以去看 HanLP的接口来获取详情· 文本推荐 三个关键字的语句推荐结果为:机器学习→[人工智能如今是非常火热的一门
2018-11-21 11:38:50
停用词的移除、大小写字母转化和词干提取。4)获取查询。获取单词权重,对于可疑文档利用TF-IDF获得关键词,并排序得到相应的关键词列表。排在前n个的关键词组成一个查询,以此类推,本试验中n=5。5)检索
2016-01-26 10:38:19
提高网站关键词排名的28个SEO小技巧关键词位置、密度、处理 URL中出现关键词(英文) 网页标题中出现关键词(1-3个) 关键词标签中出现关键词(1-3个) 描述标签中出现关键词(主关键词重复2次
2010-12-01 17:08:20
仿造example/speech_recognition/asr样例写了一个关键词识别程序,识别到关键词后,就播放提示音。目前关键词可以正确识别,就是播放提示音的时候就报错,报错信息如下,请各位帮忙
2023-03-10 06:18:08
('com.hankcs.hanlp.tokenizer.NLPTokenizer')print(NLPTokenizer.segment('中国科学院计算技术研究所的宗成庆教授正在教授自然语言处理课程'))# 关键词提取document = "水利部水资源司
2019-01-08 16:26:14
本篇分享一个使用hanlp分词的操作小案例,即在spark集群中使用hanlp完成分布式分词的操作,文章整理自【qq_33872191】的博客,感谢分享!以下为全文: 分两步:第一步:实现
2019-01-21 10:45:23
(NLPTokenizer.segment('中国科学院计算技术研究所的宗成庆教授正在教授自然语言处理课程'))# 关键词提取document = "水利部水资源司司长陈明忠9月29日在
2018-12-14 10:23:25
☑网站建设 ☑网站推广 ☑关键词优化 ☑百度地标 ☑欢迎咨询QQ:2991704102
2014-03-15 16:13:23
,相比英文分词,中文分词实现难度更高。NLPIR实验室总结了几项中文分词难点。中文分词概念分词技术就是搜索引擎针对用户提交查询的关键词串进行的查询处理后根据用户的关键词串用各种匹配方法进行的一种技术。当然
2019-09-04 17:39:58
矩阵模型,以一个词的起始位置作为行,终止位置作为列,可以得到一个二维矩阵。例如:“他说的确实在理”这句话图词的存储方法:一种是的DynamicArray法,一种是快速offset法。Hanlp代码中采用
2019-03-13 13:27:44
、转化率,且与自己产品相关的关键词,单独拿出来放进 search term 里面进行优化 listing 的操作。2.自己利用一些工具去筛选出一些买家搜索词,然后根据自己对产品的理解,买家的搜索习惯,适当
2017-06-05 15:41:28
我们可以对神经网络架构进行优化,使之适配微控制器的内存和计算限制范围,并且不会影响精度。我们将在本文中解释和探讨深度可分离卷积神经网络在 Cortex-M 处理器上实现关键词识别的潜力。关键词识别
2021-07-26 09:46:37
`在使用Hanlp词典进行分词的时候,会出现分词不准的情况,原因是内置词典中并没有收录当前这个词,也就是我们所说的未登录词,只要把这个词加入到内置词典中就可以解决类似问题,如何操作呢,下面我们来看
2019-01-25 11:06:13
、用户自定义词典、词性标注),命名实体识别(中国人名、音译人名、日本人名、地名、实体机构名识别),关键词提取,自动摘要,短语提取,拼音转换,简繁转换,文本推荐,依存句法分析(MaxEnt依存句法分析
2018-12-12 16:27:49
路径;A、B、C 对应的是 ES 版本号。使用自定义词典默认词典是精简版的词典,能够满足基本需求,但是无法使用感知机和 CRF 等基于模型的分词器。HanLP 提供了更加完整的词典,请按需下载。词典
2019-04-22 15:53:33
,组织机构名等来切分词Elasticsearch默认分词 输出: IK分词 输出: hanlp分词 输出: ik分词没有根据句子的含义来分词,hanlp能根据语义正确的切分出词安装步骤: 1
2019-07-01 11:34:33
我们可以对神经网络架构进行优化,使之适配微控制器的内存和计算限制范围,并且不会影响精度。我们将在本文中解释和探讨深度可分离卷积神经网络在 Cortex-M 处理器上实现关键词识别的潜力。关键词识别
2019-07-23 06:59:07
的讲义《The Structured Perceptron》。 本文实现的AP分词器预测是整个句子的BMES标注序列,当然属于结构化预测问题了。感知机二分类感知机的基础形式如《统计学习方法》所述,是定义在
2019-01-14 11:15:41
我们在使用hanlp词典进行分词的时候,难免会出现分词不准确的情况,原因是由于内置词典中并没有收录当前的这个词,也就是我们所说的未登录词,只要把这个词加入到内置词典中就可以解决类似问题,如何操作
2019-03-18 15:25:42
如何在 Cortex-M 处理器上实现高精度关键词识别
2021-02-05 07:14:00
仅作为学习记录,大佬请跳过。这些东西都是存储器关键词:RAM和ROM两大类ROM——PROM、EPROM、E2PROM、FLASH1、RAM、ROM对电脑来说,RAM是内存,ROM是硬盘2、PROM
2021-12-10 06:46:06
模型是上述一般文本信息抽取的具体实现。 NLPIR大数据语义智能分析平台在文本信息提取介绍方面,能够实现新词提取和关键词提取。 新词发现能从文本中挖掘出具有内涵的新词、新概念,用户可以用于专业词典
2019-09-16 15:03:58
一夜之间关键词排名掉完了,没有被K,也没有出现违规操作,这是怎么回事呢?
2021-01-27 11:01:21
:Java网址:hankcs/HanLP开发机构:大快搜索协议:Apache-2.0功能:非常多,主要有中文分词,词性标注,命名实体识别,关键词提取,自动摘要,短语提取,拼音转换,简繁转换,文本推荐,依存
2018-11-26 10:31:45
网站定位之关键词的选取 策划网站首先需要策划的是我们网站的主题,而一份网站的主题是用关键字息息相关的,怎么策划和选择关键字以及如何在关键字巧妙的使用长尾以及百度分词,才能够最大化的利用标题
2011-04-19 15:03:12
)、基于 CRF 模型的分词、N- 最短路径分词等。实现了不少经典分词方法。Hanlp 的部分模块做了重要优化,比如双数组,匹配速度很快,可以直接拿过来使用。Hanlp 做了不少重现经典算法的工作,可以去
2018-10-26 13:48:43
`自然语言处理工具hanlp关键词提取图解TextRank算法 看一个博主(亚当-adam)的关于hanlp关键词提取算法TextRank的文章,还是非常好的一篇实操经验分享,分享一下给各位需要
2019-02-20 11:06:29
data版和ptotable版,对于一般的分词而言,protable完全就可以满足要求。另外还有一些其他的操作,例如词性识别,也是实际应用中比较多的。当然其他的类似关键词提取,情感识别做个参考也就
2018-11-28 10:02:37
请问DSP里如何确定ioport关键词定义的地址对应的引脚?
2013-06-28 15:48:25
我想在在verilog文件中引入环,但是总是被quartus的综合优化掉,请问quartus有类似于vivado * ALLOW_COMBINATORIAL_LOOPS = "true"的关键词吗?
2022-01-07 11:10:24
给出一种适用于在线垃圾模型的基于动态排位信息的关键词确认方法,利用识别过程中声学得分的排位信息进行关键词确认,能在不降低检出率的同时有效降低系统的误警率,效果
2009-04-23 09:29:00 11
11 歧义词的切分是中文分词要面对的数个难题之一,解决好了这个问题就能够有力提升中文分词的正确率。对此,本文简要介绍了汉语分词的概况,并具体分析了当前中文分词技术
2010-01-15 16:09:4118 2009年中国照明行业十大关键词
一、节能推广
关键词:节能推广
事
2009-12-15 10:24:05838 文本的关键词识别是文本挖掘中的基本问题之一。在研究现有基于复杂网络的关键词识别方法的基础上,从整个复杂网络拓扑结构特征的信息缺失角度来考察各节点的重要程度。提出强度熵测度来量化评估各节点重要程度,用于解决中文关键词识别问题。实验结果表明,该评估方法简单有效,特别适用于带权复杂网络的节点重要性评估。
2017-11-24 09:54:287 为改进基于关键词的最优路径查询算法,在大规模图以及多查询关键词下复杂度过高与可扩展性不足的缺陷,依据查询关键词序列构建候选路径的策略提出一种高效查询算法。该算法在路径构建过程中优先满足查询关键词的全
2017-12-06 11:28:210 人员参考。文中根据世界知识或分类体系计算词语语义距离后转化为词语相似度的方法,将词语间距离依据词频、词权重等因子加工计算出关键词集合间相似度矩阵后,用欧式距离表示其关键字集的相似度;之后聚类算法利用现有R软件中开
2017-12-13 10:15:500 在云计算中,用户在计算过程中的数据安全问题已经成为制约云计算发展的一个瓶颈。本文针对云计算中的加密搜索问题,提出一个有效的加密搜索方案。在搜索过程中,为保证用户的数据安全,用户需要隐藏搜索的关键词
2017-12-14 14:14:350 在TF-IDF算法基础上,提出新的基于词频统计的关键词提取方法。利用段落标注技术,对处于不同位置的词语给予不同的位置权重,对分词结果中词频较高的同词性词语进行词语相似度计算,合并相似度较高的词语
2017-12-15 15:29:1413 科学、心理学和社会科学等多个方面研究了自动关键词抽取的理论基础.从宏观、中观和微观角度,回顾和分析了自动关键词抽取的发展、技术和方法.针对目前广泛应用的自动关键词抽取方法,包括统计法、基于主题的方法、基于网络图
2017-12-26 16:47:352 本章第一节就介绍基于关键词生成一段文本的一些处理技术。其主要是应用关键词提取、同义词识别等技术来实现的。下面就对实现过程进行说明和介绍。
2017-12-26 18:12:4011481 
。 HanLP能提供以下功能:关键词提取、短语提取、繁体转简体、简体转繁体、分词、词性标注、拼音转换、自动摘要、命名实体识别(地名、机构名等)、文本推荐等功能,详细请参见以下链接:http
2018-10-16 09:31:04622 的。elasticsearch-hanlpHanLPHanLP 是一款使用 Java 实现的优秀的,具有如下功能:中文分词词性标注命名实体识别关键词提取自动摘要短语提取拼音转换简繁转换文本推荐依存句法分析语料库工具安装
2018-10-17 15:11:50540 HanLP介绍:http://hanlp.linrunsoft.com/ github地址:https://github.com/hankcs/HanLP 说明:使用hanlp实现分词、智能
2018-10-17 15:13:201323 ),而且与文中提到的词向量相匹配。(我免贵姓AI,jieba:我免/贵姓/AI,hanlp:我/免/贵姓/AI,实际:我/免贵/姓AI)参考资料:自然语言处理 中文分词 词性标注 命名实体识别 依存句法分析 关键词提取 新词发现 短语提取 自动摘要 文本分类 拼音简繁文章来源于gladosAI的博客
2018-10-17 16:08:29350 System.out.println("标准分词:"); System.out.println(HanLP.segment("你好,欢迎使用HanLP
2018-10-17 17:26:30447 实体识别,她用了一个很有意思的方法,自己改了HanLP的词典,手动加了好多词,而且后期版本迭代中还有可能继续改。。。。改了HanLP的词典就意味着不能用maven直接导入仓库里的包了,只能直接将修改后
2018-10-18 14:33:32247 模型,以一个词的起始位置作为行,终止位置作为列,可以得到一个二维矩阵。例如:“他说的确实在理”这句话图词的存储方法:一种是的DynamicArray法,一种是快速offset法。Hanlp代码中采用
2018-10-18 14:40:52398 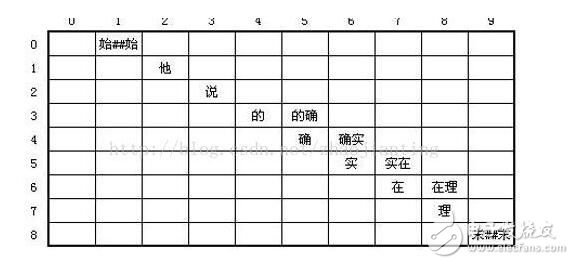
版本还是发现没有client文件夹,放弃在python中调用java包Hanlp,直接在java程序中使用hanlp。11大Java开源中文分词器的使用方法和分词效果对比:http
2018-10-18 14:53:19339 前言 以前,我对大部分的处理中文分词都是使用python的结巴分词工具,该分词工具是在线调用API, 关于这个的分词工具的原理介绍,我推荐一个好的博客: http://blog.csdn.net
2018-10-18 15:05:46318 = fs.create(new Path(path)); return out; } }3.设置IoAdapter,创建分词器:private static
2018-11-07 09:33:31528 阅读目录手记实用系列文章:代码封装类:运行效果:手记实用系列文章:1 结巴分词和自然语言处理HanLP处理手记2 Python中文语料批量预处理手记3 自然语言处理手记4 Python中调用自然语言
2018-11-07 09:35:28461 最近在学习用hanlp分词做关键词提取,但是现在有一个问题,虽然hanlp中各种功能直接调用很方便了,那么如果我需要从人名识别中仅仅提取出人名怎么操作呢?我按照官方的示例代码,发现输出的list
2018-11-08 15:50:28550 8. 11. 12. 13. 14. 15. 16. 17. 18. 19. 意思是默认文本字段类型启用HanLP分词器,text_general还开启了solr默认的各种filter。solr
2018-11-29 14:36:05658 参考论文:《TextRank: Bringing Order into Texts》TextRank算法提取关键词的Java实现TextRank算法自动摘要的Java实现这篇文章中作者大概解释了一下
2018-11-29 14:44:35629 THULAC 、斯坦福分词器、Hanlp 分词器、jieba 分词、IKAnalyzer 等。这里针对 jieba 和 HanLP 分别介绍不同场景下的中文分词应用。jieba 分词jieba 安装(1
2018-11-29 14:45:451024 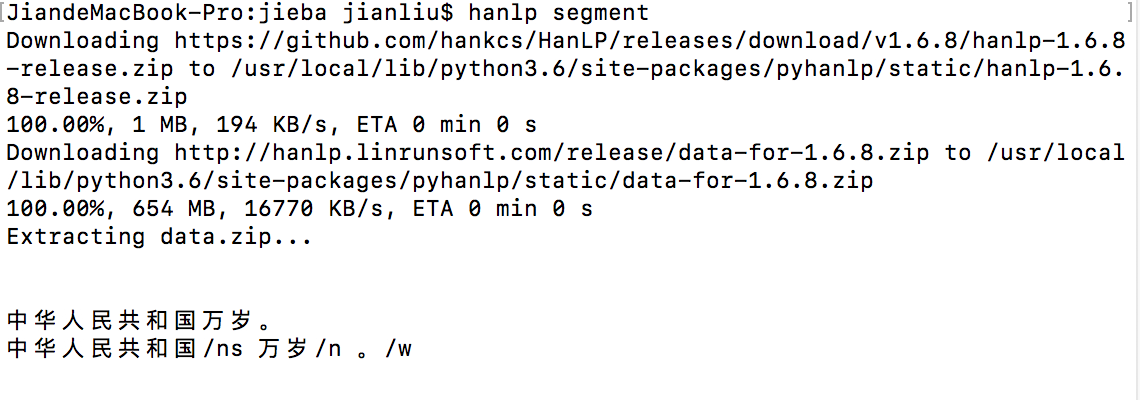
/elasticsearch-analysis-hanlpElasticsearch默认分词 输出: IK分词 输出: hanlp分词 输出: ik分词没有根据句子的含义来分词,hanlp能根据语义正确的切分出词安装步骤: 1、进入https
2018-11-29 15:01:08650 Textrank转移概率矩阵计算过程,同时通过迭代运算对文档中的词语进行综合影响力得分排序,最终提取得分最高的TopN个词语作为关键词。实验结果表明,当选取Top3、Top5、Top7和Topl0个关键词时,与基于词向量聚类质心与 Textrank加权的关键词抽取方法相比,该方法的平均F值
2021-03-21 09:55:1918 结合通配符模式与引入先验信息的随机游走算法,提出一种改进的关键词提取方法。使用通配符约束捕获词语之间的语义关系,提取满足间隙约東和一次性条件的顺序模式以计算模式支持度,并在模式支持度大于等于最小
2021-03-27 10:36:4014 各类应用领域的文本数据日益增多,如何从这些海量数据中迅速准确地提取核心内容,已成为关键词抽取的主要任务。提出一种基于词和文档嵌入的关键词抽取方法,通过计算单词与文档在同一维度上的向量表示,得出每个
2021-04-02 14:59:554 关键词提取是进行未知网络协议逆向的关键步骤。鉴于现有的关键词提取方法存在精确度不髙、需要较多先验知识、操作繁琐等问题,提出了一种基于位置信息的关键词自动化提取算法。首先,通过 Trigram分词获取
2021-04-25 13:56:353 电子发烧友网站提供《TinyML变得简单:关键词识别(KWS).zip》资料免费下载
2023-07-13 10:20:245 在电商、内容平台等应用中,用户经常通过输入关键词搜索商品并获取详情。设计一个高效、可靠的API接口是核心需求。本文将逐步介绍如何设计并实现一个“搜索关键词获取商品详情”的接口,涵盖
2025-10-20 15:37:57380 
格式的字符串)。 关键词与搜索结果的关联性 :关键词的精准度决定爬取结果的相关性,京东搜索会对关键词进行分词匹配(如 “Python 实战书籍” 会拆分匹配 “Python”、“实战”、“书籍”)。 请求参数中的关键词传递 :在之前的爬虫代码中,关键词通过
2026-01-04 10:40:5822 在电商领域,曝光率是决定商品销量的关键因素之一。淘宝作为国内领先的电商平台,提供了强大的搜索API接口,帮助开发者构建关键词优化工具,从而提升商品在搜索结果中的排名和曝光。本文将详细介绍淘宝
2026-01-05 15:38:0212
 电子发烧友App
电子发烧友App








 工商网监
工商网监
评论