 电子发烧友App
电子发烧友App











 创作
创作 发文章
发文章 发帖
发帖  提问
提问  发资料
发资料 发视频
发视频资料介绍
描述
介绍
介绍
欢迎回到我们正在进行的微型机器学习 (TinyML) 系列!在我们之前的两个教程中已经深入研究了图像分类、运动分类和异常检测,现在我们将重点转移到声控应用领域,并通过一个使用 XIAO ESP32S3 板的关键字识别 (KWS) 项目。
关键字识别 (KWS) 是许多语音识别系统不可或缺的一部分,使设备能够响应特定的单词或短语。虽然这项技术是 Google Assistant 或 Amazon Alexa 等流行设备的基础,但它同样适用于更小的低功耗设备。本教程将指导您在 XIAO ESP32S3 微控制器板上使用 TinyML 实现 KWS 系统。
据了解,配备乐鑫 ESP32-S3 芯片的 XIAO ESP32S3 是一款紧凑而强大的微控制器,提供双核 Xtensa LX7 处理器、集成 Wi-Fi 和蓝牙功能。它在计算能力、能源效率和通用连接性之间取得平衡,使其成为 TinyML 应用程序的绝佳平台。此外,通过其扩展板,我们可以访问设备的“感知”部分,该部分具有一个 1600x1200 OV2640 摄像头、一个 SD 卡插槽和一个数字麦克风。集成麦克风和 SD 卡在该项目中必不可少。
与之前的系列教程一样,我们将利用Edge Impulse Studio ,这是一个功能强大、用户友好的平台,可简化在边缘设备上创建和部署机器学习模型的过程。我们将逐步训练 KWS 模型,对其进行优化并将其部署到 XIAO ESP32S3 Sense 上。
我们的模型旨在识别可触发设备唤醒或特定操作(在“是”的情况下)的关键字,通过语音激活命令使您的项目栩栩如生。
利用我们在之前教程中使用 TensorFlow Lite for Microcontrollers(EI Studio 中的引擎)的经验,我们将创建一个能够在设备上进行实时机器学习的 KWS 系统。
随着教程的推进,我们将分解每个过程阶段——从数据收集和准备到模型训练和部署——以提供对在微控制器上实现 KWS 系统的全面理解。
因此,让我们使用 Edge Impulse Studio 在 XIAO ESP32S3 上进行关键字识别,继续我们的 TinyML 精彩世界之旅!
语音助手如何工作?
介绍解释说,关键字识别 (KWS) 对许多语音助手至关重要,它使设备能够响应特定的单词或短语。
首先,必须认识到市场上的语音助手,如 Google Home 或 Amazon Echo-Dot,只有在人类被特定关键字“唤醒”时才会对人类做出反应,例如第一个关键字上的“Hey Google”和“ Alexa”在第二个。
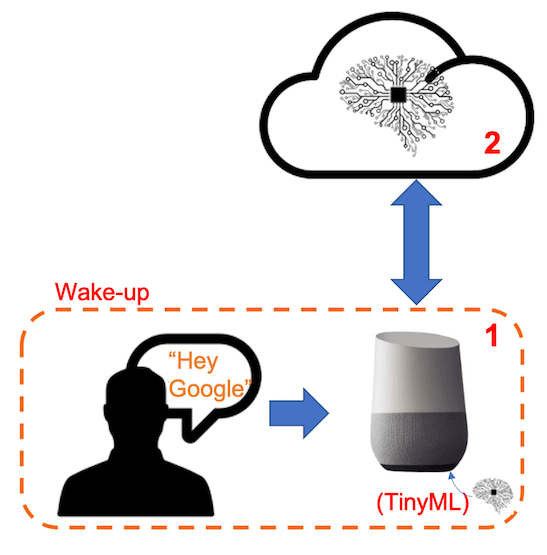
换句话说,识别语音命令是基于多阶段模型或级联检测。
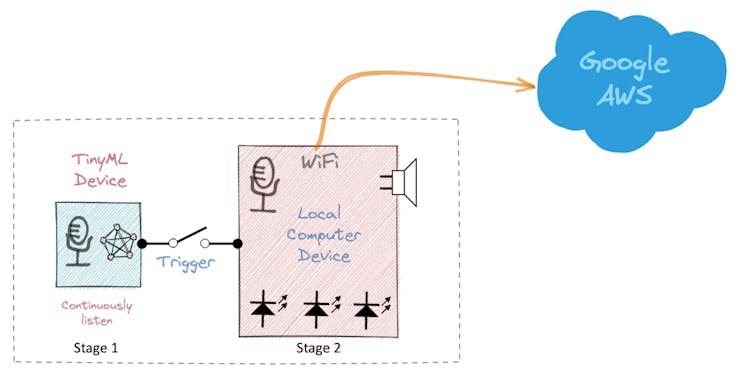
第 1 阶段:Echo Dot 或 Google Home 内的一个较小的微处理器持续收听声音,等待关键词被识别。
如果您想更深入地了解整个项目,请参阅我的教程:从头开始构建智能语音助手。
在这个项目中,我们将专注于第 1 阶段(KWS 或关键字识别),我们将在其中使用 XIAO ESP2S3 Sense,它具有一个用于识别关键字的数字麦克风。
KWS 项目
下图将给出最终 KWS 应用程序应该如何工作的想法(在推理期间):
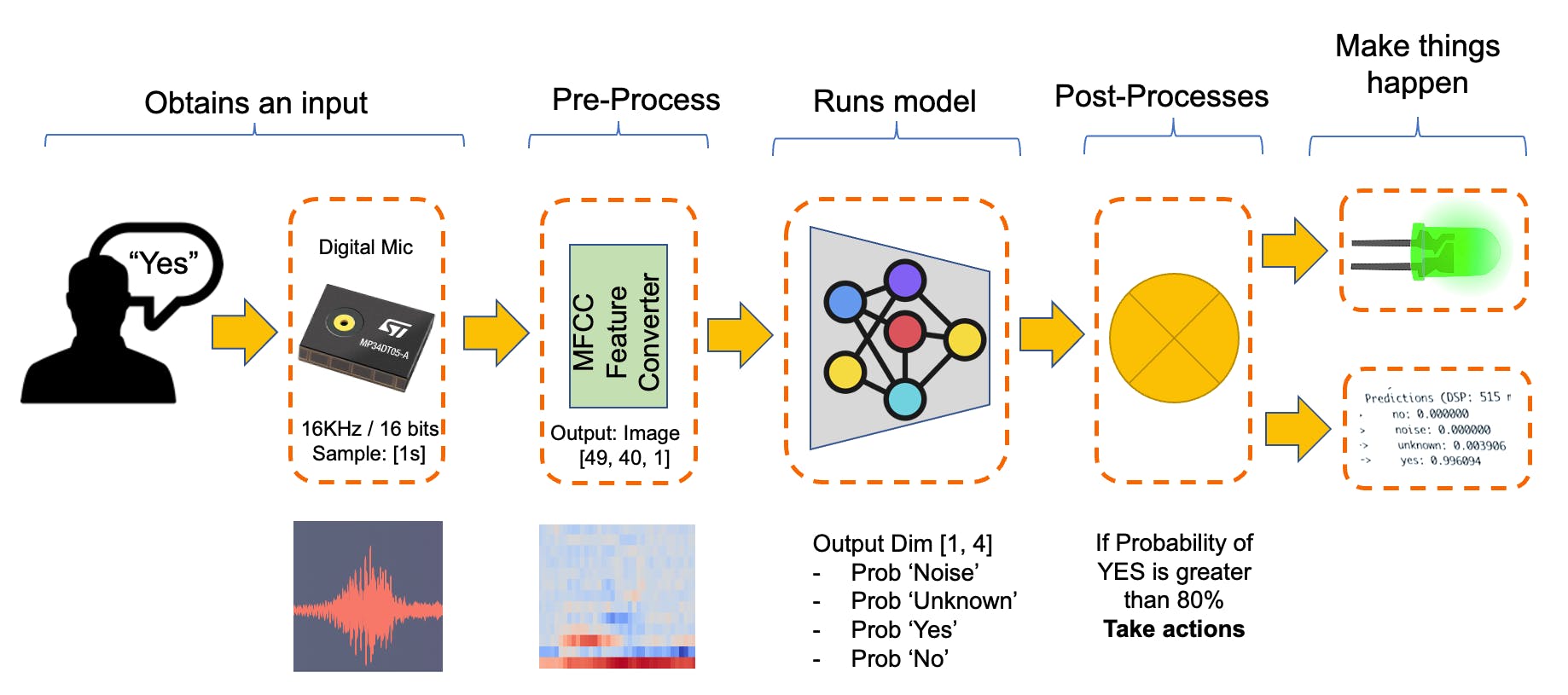
我们的 KWS 应用程序将识别四种声音:
- 是(关键字 1)
- 否(关键字 2)
- NOISE (没有说出关键词,只有背景噪音)
- UNKNOW (不同于 YES 和 NO 的混合词)
对于真实世界的项目,始终建议包含与关键字不同的词,例如“噪音”(或背景)和“未知”。
机器学习工作流程
KWS 应用程序的主要组件是它的模型。因此,我们必须使用特定的关键字、噪声和其他词(“未知”)来训练这样的模型:
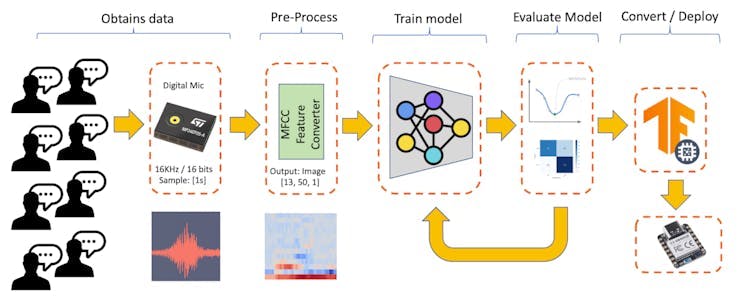
数据集
机器学习工作流的关键组成部分是数据集。一旦我们决定了特定的关键字(YES和 NO),我们就可以利用 Pete Warden 开发的数据集“语音命令:有限词汇语音识别数据集” 。这个数据集有 35 个关键字(每个关键字 +1, 000 个样本),例如 yes、no、stop 和 go。在其中一些词中,我们可以获得 1, 500 个样本,例如yes和no 。
您可以从 Edge Studio 下载一小部分数据集(关键字识别预建数据集),其中包括我们将在该项目中使用的四个类别的样本:是、否、噪声和背景。为此,请按照以下步骤操作:
- 下载关键字数据集。
- 将文件解压缩到您选择的位置。
虽然我们有很多来自 Pete 的数据集的数据,但建议收集一些我们所说的单词。在使用加速度计时,使用相同类型的传感器捕获的数据创建数据集是必不可少的。在声音的情况下,情况有所不同,因为我们要分类的实际上是音频数据。
声音和音频之间的主要区别在于它们的能量形式。声音是通过介质传播的机械波能量(纵向声波),导致介质内的压力发生变化。音频由代表声音的电能(模拟或数字信号)组成。
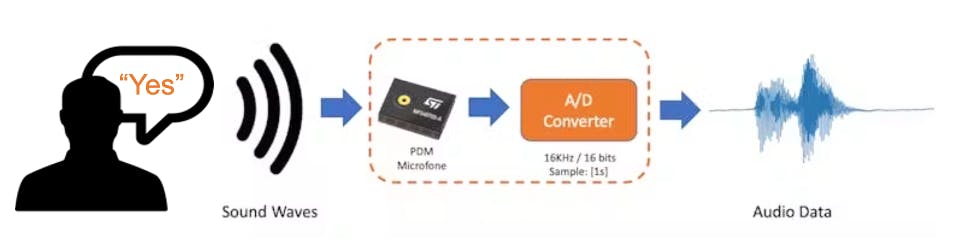
当我们说出关键词时,声波应该被转换成音频数据。转换应该通过对麦克风生成的信号进行采样来完成,频率为 16KHz,深度为 16 位。
因此,任何可以生成具有此基本规格(16Khz/16 位)的音频数据的设备都可以正常工作。作为设备,我们可以使用合适的XIAO ESP32S3 Sense,也可以是电脑,甚至手机。
使用 Edge Impulse 和智能手机捕获在线音频数据
在教程“使用新的 XIAO ESP32S3 探索机器学习”中,我们将设备直接连接到 Edge Impulse Studio 进行数据捕获(采样频率为 50Hz 至 100Hz)。对于如此低的频率,我们可以使用 EI CLI 功能数据转发器,但根据 Edge Impulse 首席技术官 Jan Jongboom 的说法,音频(在本例中为 16KHz)速度太快,数据转发器无法捕获。因此,一旦我们获得了麦克风捕获的数字数据,我们就可以将其转换为 WAV 文件,通过数据上传器发送到工作室(与我们对皮特的数据集所做的相同)。
如果我们想直接在 Studio 上收集音频数据,我们可以使用任何与其在线连接的智能手机。我们不会在这里探讨这个选项,但您可以轻松地遵循 EI文档。
使用 XIAO ESP32S3 Sense 捕获(离线)音频数据
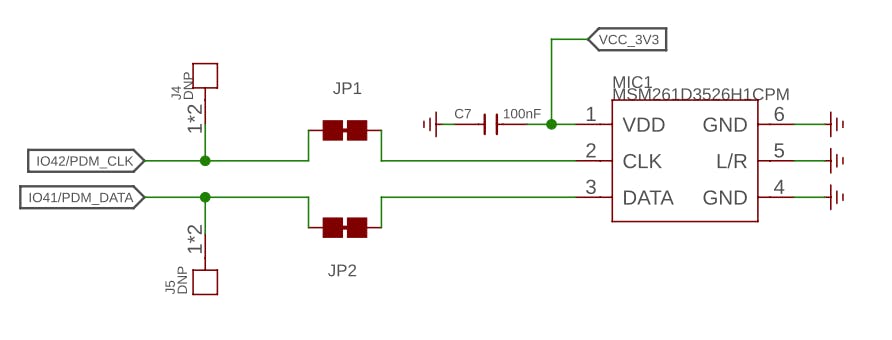
内置麦克风为MSM261D3526H1CPM ,一款具有多模式的PDM数字输出MEMS麦克风。在内部,它使用引脚 IO41(时钟)和 IO41(数据)通过 I2S 总线连接到 ESP32S3。
什么是 I2S?
I2S 或 Inter-IC Sound 是一种标准协议,用于将数字音频从一个设备传输到另一个设备。它最初由飞利浦半导体(现为恩智浦半导体)开发。它通常用于音频设备,例如数字信号处理器、数字音频处理器,以及最近具有数字音频功能的微控制器(我们这里的案例)。
I2S协议至少由三行组成:
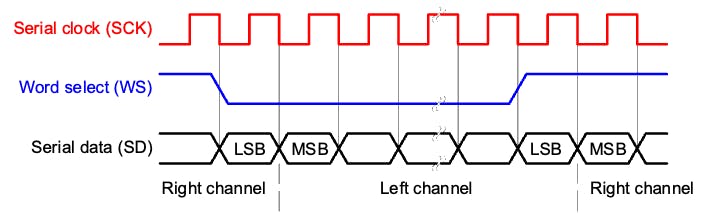
1. 位(或串行)时钟线(BCLK 或 CLK):该线切换以指示新数据位的开始(引脚 IO42)。
2. 单词选择线 (WS) :此行切换以指示新单词的开始(左声道或右声道)。字选择时钟的频率定义了采样率。在我们的例子中,麦克风上的 L/R 设置为接地,这意味着我们将仅使用左声道(单声道)。
3.数据线(SD):此线承载音频数据(引脚IO41)
在 I2S 数据流中,数据作为帧序列发送,每个帧包含一个左声道字和一个右声道字。这使得 I2S 特别适合传输立体声音频数据。但是,它也可以用于带有附加数据线的单声道或多声道音频。
让我们开始了解如何使用麦克风捕获原始数据。转到GitHub 项目并下载草图:XIAOEsp2s3_Mic_Test :
/*
XIAO ESP32S3 Simple Mic Test
*/
#include
void setup() {
Serial.begin(115200);
while (!Serial) {
}
// start I2S at 16 kHz with 16-bits per sample
I2S.setAllPins(-1, 42, 41, -1, -1);
if (!I2S.begin(PDM_MONO_MODE, 16000, 16)) {
Serial.println("Failed to initialize I2S!");
while (1); // do nothing
}
}
void loop() {
// read a sample
int sample = I2S.read();
if (sample && sample != -1 && sample != 1) {
Serial.println(sample);
}
}
此代码是使用 I2S(Inter-IC Sound)接口对 XIAO ESP32S3 进行的简单麦克风测试。它设置 I2S 接口以 16 kHz 的采样率捕获音频数据,每个样本 16 位,然后连续从麦克风读取样本并将它们打印到串行监视器。
让我们深入研究代码的主要部分:
-
Include the I2S library:此库提供配置和使用I2S 接口的功能,这是连接数字音频设备的标准。 -
I2S.setAllPins(-1, 42, 41, -1, -1):这会设置 I2S 引脚。参数为(-1,42,41,-1,-1),其中第二个参数(42)为I2S时钟(CLK)的PIN,第三个参数(41)为I2S数据的PIN (数据)线。其他参数设置为 -1,表示未使用这些引脚。 -
I2S.begin(PDM_MONO_MODE, 16000, 16):这会在脉冲密度调制 (PDM) 单声道模式下初始化 I2S 接口,采样率为 16 kHz,每个样本 16 位。如果初始化失败,则会打印一条错误消息,并且程序会停止。 -
int sample = I2S.read():这从 I2S 接口读取音频样本。
如果样本有效,它会打印在串行监视器和绘图仪上。
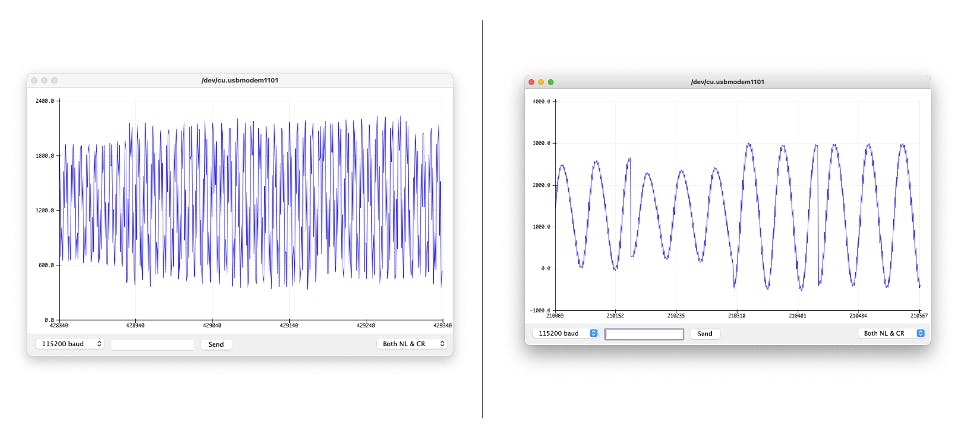
下面是用两种不同音调“耳语”的测试。
将录制的声音样本(数据集)作为.wav 音频文件保存到 microSD 卡中。
让我们使用板载SD卡读卡器来保存.wav音频文件;我们需要先修复 XIAO PSRAM。
ESP32-S3 在 MCU 芯片上只有几百 KB 的内部 RAM。对于某些用途,ESP32-S3 可以使用与 SPI 闪存芯片并联的最多 16 MB 的外部 PSRAM(伪静态 RAM)可能不够。外部存储器包含在存储器映射中,并且在某些限制下,可以像内部数据 RAM 一样使用。
首先,如下图所示将 SD 卡插入 XIAO(SD 卡应格式化为 FAT32)。

开启ESP-32芯片的PSRAM功能(Arduino IDE):Tools>PSRAM: "OPI PSRAM”>OPI PSRAM
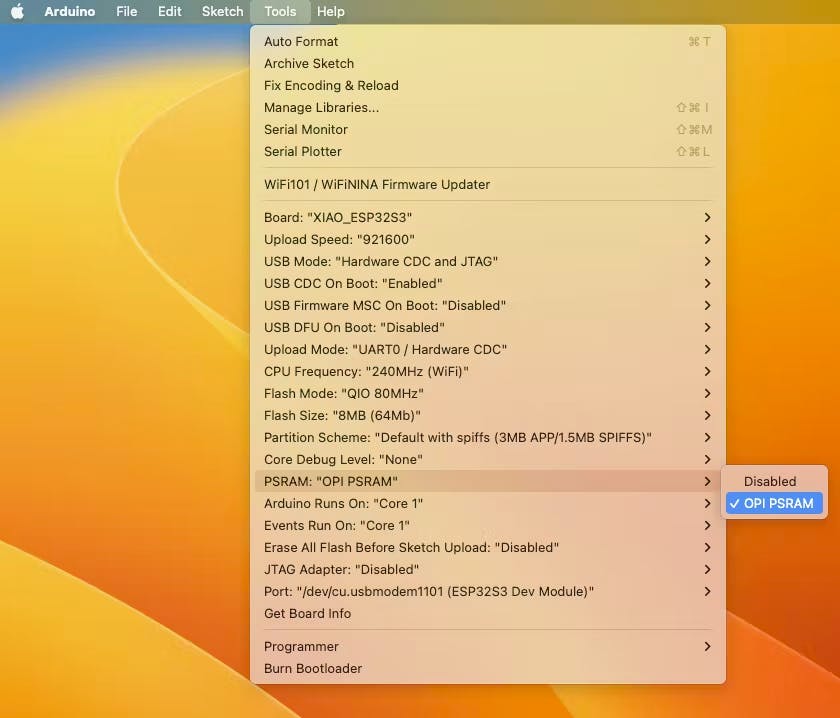
- 下载可以在项目的 GitHub 上找到的草图Wav_Record_dataset 。
此代码使用 Seeed XIAO ESP32S3 Sense 板的 I2S 接口录制音频,将录音保存为 SD 卡上的 a.wav 文件,并允许通过串行监视器发送的命令控制录音过程。音频文件的名称是可自定义的(它应该是用于培训的班级标签),并且可以制作多个录音,每个录音都保存在一个新文件中。该代码还包括增加录音音量的功能。
让我们分解其中最重要的部分:
#include
#include "FS.h"
#include "SD.h"
#include "SPI.h"
这些是该程序必需的库。I2S.h允许音频输入,FS.h提供文件系统处理能力,SD.h允许程序与 SD 卡交互,并SPI.h处理与 SD 卡的 SPI 通信。
#define RECORD_TIME 10
#define SAMPLE_RATE 16000U
#define SAMPLE_BITS 16
#define WAV_HEADER_SIZE 44
#define VOLUME_GAIN 2
这里,为程序定义了各种常量。
-
RECORD_TIME以秒为单位指定录音的长度。 -
SAMPLE_RATE并SAMPLE_BITS定义录音的音频质量。 -
WAV_HEADER_SIZE指定 .wav 文件头的大小。 -
VOLUME_GAIN用于增加录音的音量。
int fileNumber = 1;
String baseFileName;
bool isRecording = false;
这些变量跟踪当前文件号(以创建唯一文件名)、基本文件名以及系统当前是否正在记录。
void setup() {
Serial.begin(115200);
while (!Serial);
I2S.setAllPins(-1, 42, 41, -1, -1);
if (!I2S.begin(PDM_MONO_MODE, SAMPLE_RATE, SAMPLE_BITS)) {
Serial.println("Failed to initialize I2S!");
while (1);
}
if(!SD.begin(21)){
Serial.println("Failed to mount SD Card!");
while (1);
}
Serial.printf("Enter with the label name\n");
}
该setup函数初始化串行通信、用于音频输入的 I2S 接口和 SD 卡接口。如果 I2S 没有初始化或者 SD 卡挂载失败,它会打印错误信息并停止执行。
void loop() {
if (Serial.available() > 0) {
String command = Serial.readStringUntil('\n');
command.trim();
if (command == "rec") {
isRecording = true;
} else {
baseFileName = command;
fileNumber = 1; //reset file number each time a new basefile name is set
Serial.printf("Send rec for starting recording label \n");
}
}
if (isRecording && baseFileName != "") {
String fileName = "/" + baseFileName + "." + String(fileNumber) + ".wav";
fileNumber++;
record_wav(fileName);
delay(1000); // delay to avoid recording multiple files at once
isRecording = false;
}
}
在主循环中,程序等待来自串行监视器的命令。如果命令是rec,则程序开始录制。否则,该命令被假定为.wav 文件的基本名称。如果它当前正在录制并且设置了基本文件名,它会录制音频并将其保存为.wav 文件。文件名是通过将文件编号附加到基本文件名生成的。
void record_wav(String fileName)
{
...
File file = SD.open(fileName.c_str(), FILE_WRITE);
...
rec_buffer = (uint8_t *)ps_malloc(record_size);
...
esp_i2s::i2s_read(esp_i2s::I2S_NUM_0, rec_buffer, record_size, &sample_size, portMAX_DELAY);
...
}
此函数录制音频并将其保存为具有给定名称的.wav 文件。它首先初始化sample_size和record_size变量。record_size根据采样率、大小和所需的记录时间计算。让我们深入研究重要部分;
File file = SD.open(fileName.c_str(), FILE_WRITE);
// Write the header to the WAV file
uint8_t wav_header[WAV_HEADER_SIZE];
generate_wav_header(wav_header, record_size, SAMPLE_RATE);
file.write(wav_header, WAV_HEADER_SIZE);
这段代码打开SD卡上的文件进行写入,然后使用函数生成.wav文件头generate_wav_header。然后它将标头写入文件。
// PSRAM malloc for recording
rec_buffer = (uint8_t *)ps_malloc(record_size);
if (rec_buffer == NULL) {
Serial.printf("malloc failed!\n");
while(1) ;
}
Serial.printf("Buffer: %d bytes\n", ESP.getPsramSize() - ESP.getFreePsram());
该ps_malloc函数在 PSRAM 中为记录分配内存。如果分配失败(即为rec_bufferNULL),它会打印一条错误消息并停止执行。
// Start recording
esp_i2s::i2s_read(esp_i2s::I2S_NUM_0, rec_buffer, record_size, &sample_size, portMAX_DELAY);
if (sample_size == 0) {
Serial.printf("Record Failed!\n");
} else {
Serial.printf("Record %d bytes\n", sample_size);
}
该i2s_read函数从麦克风读取音频数据到rec_buffer. 如果没有读取数据(sample_size 为 0),它会打印一条错误消息。
// Increase volume
for (uint32_t i = 0; i < sample_size; i += SAMPLE_BITS/8) {
(*(uint16_t *)(rec_buffer+i)) <<= VOLUME_GAIN;
}
这部分代码通过将样本值移动 . 来增加录音音量VOLUME_GAIN。
// Write data to the WAV file
Serial.printf("Writing to the file ...\n");
if (file.write(rec_buffer, record_size) != record_size)
Serial.printf("Write file Failed!\n");
free(rec_buffer);
file.close();
Serial.printf("Recording complete: \n");
Serial.printf("Send rec for a new sample or enter a new label\n\n");
最后将音频数据写入.wav文件。如果写入操作失败,它会打印一条错误消息。写入后,分配给的内存rec_buffer被释放,文件被关闭。该函数通过打印完成消息并提示用户发送新命令来结束。
void generate_wav_header(uint8_t *wav_header, uint32_t wav_size, uint32_t sample_rate)
{
...
memcpy(wav_header, set_wav_header, sizeof(set_wav_header));
}
该generate_wav_header函数根据参数 (wav_size和sample_rate) 创建一个.wav 文件头。它根据 .wav 文件格式生成一个字节数组,其中包括文件大小、音频格式、通道数、采样率、字节率、块对齐、每个样本的位数和数据大小的字段。然后将生成的标头复制到wav_header传递给函数的数组中。
现在,将代码上传到 XIAO 并从关键字(是和否)中获取样本。您还可以捕捉噪音和其他词语。
串口监视器将提示您接收要记录的标签。
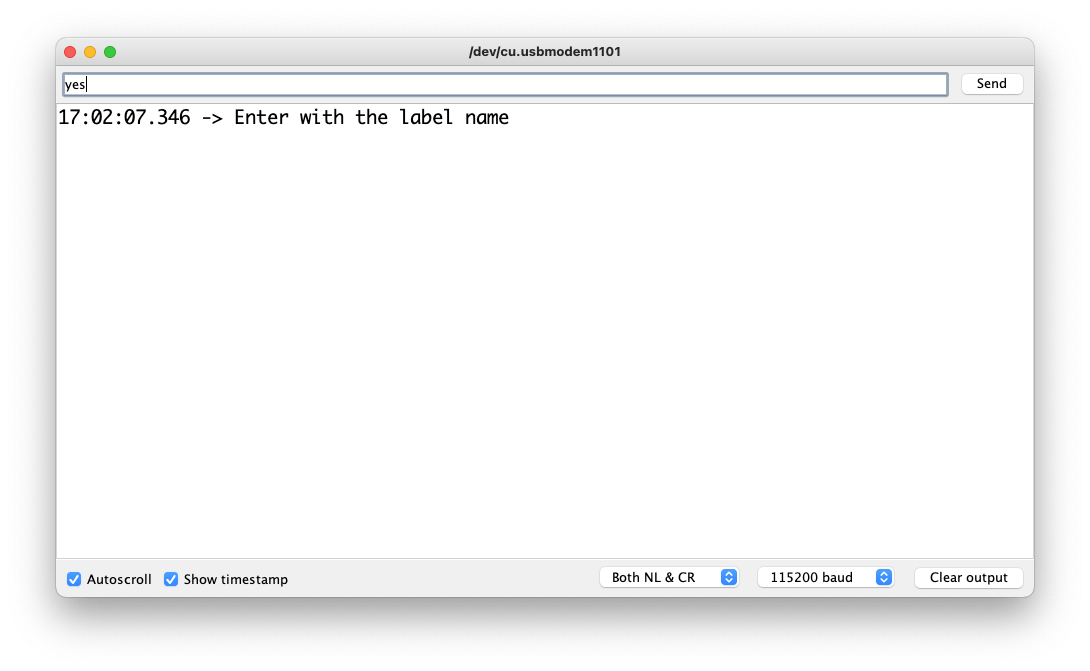
发送标签(例如,是)。该程序将等待另一个命令:rec
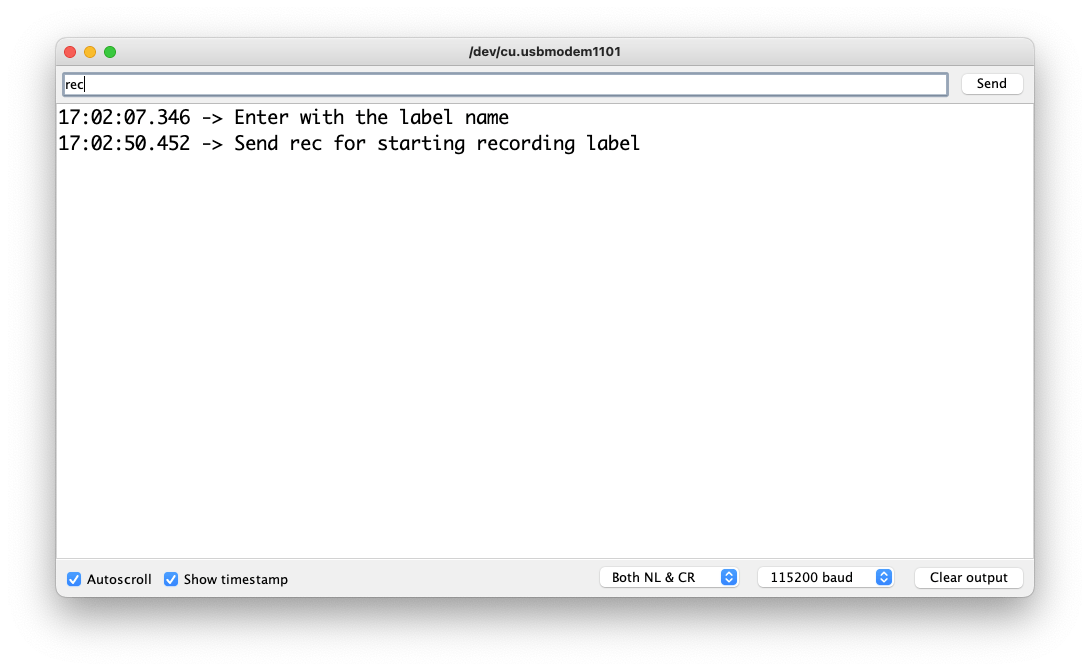
每次发送命令 rec 时,程序都会开始记录新样本。文件将保存为 yes.1.wav、yes.2.wav、yes.3.wav 等,直到发送新标签(例如,no)。在这种情况下,您应该为每个新样本发送命令 rec,它将被保存为 no.1.wav、no.2.wav、no.3.wav 等。
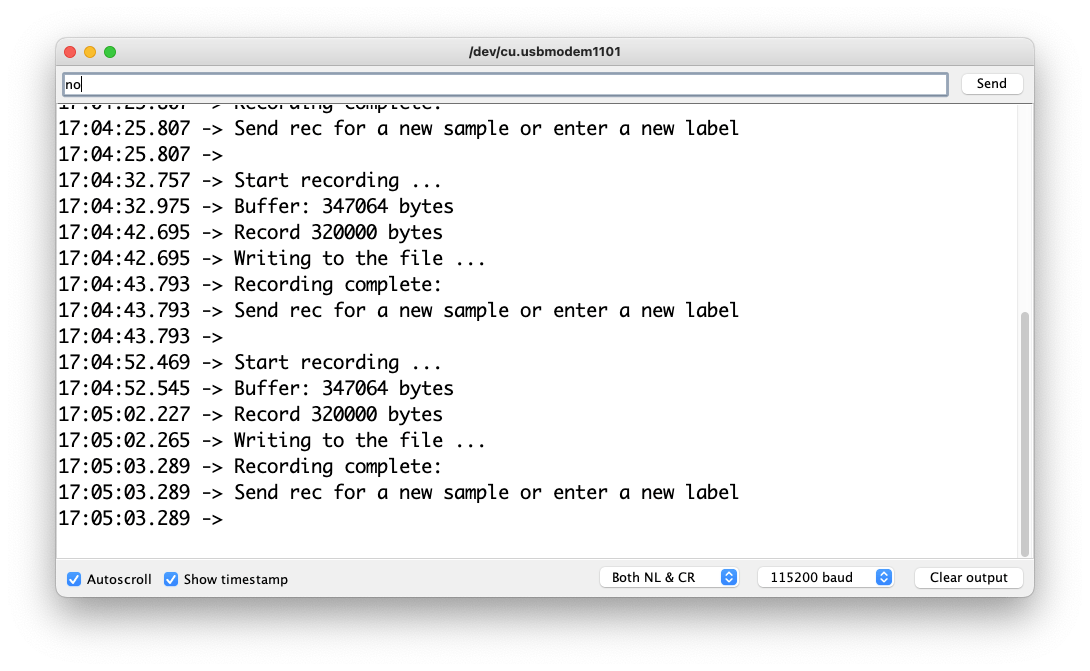
最终,我们将得到保存在 SD 卡上的文件。
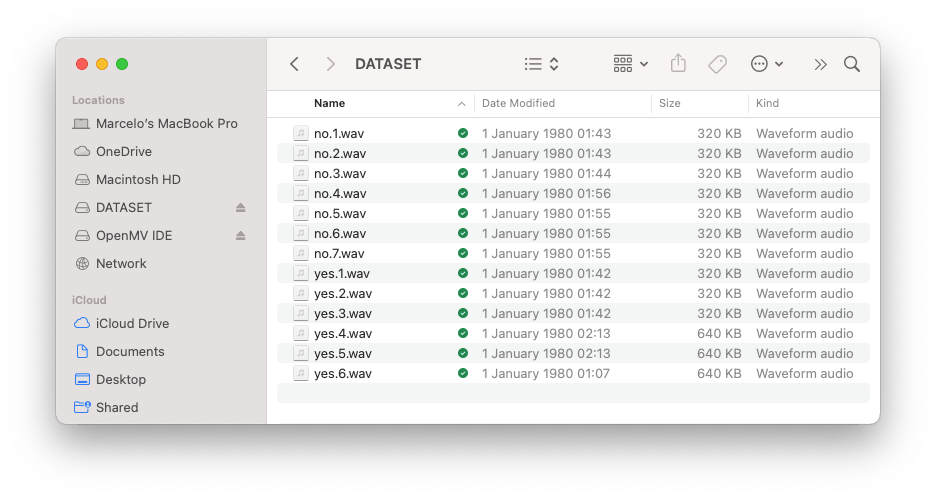
文件已准备好上传到 Edge Impulse Studio
使用智能手机或 PC 捕获(离线)音频数据
或者,您可以使用 PC 或智能手机以 16KHz 的采样频率和 16 位的位深度捕获音频数据。一个很好的应用程序是Voice Recorder Pro ( IOS)。您应该将您的记录保存为.wav 文件并将它们发送到您的计算机。
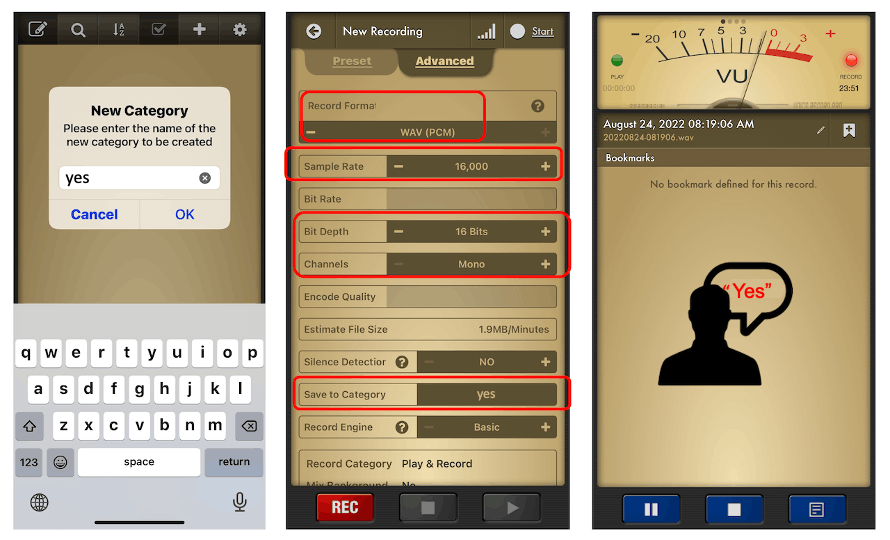
请注意,任何智能手机应用程序(例如Audacity )都可用于录音甚至您的计算机。
使用 Edge Impulse Studio 训练模型
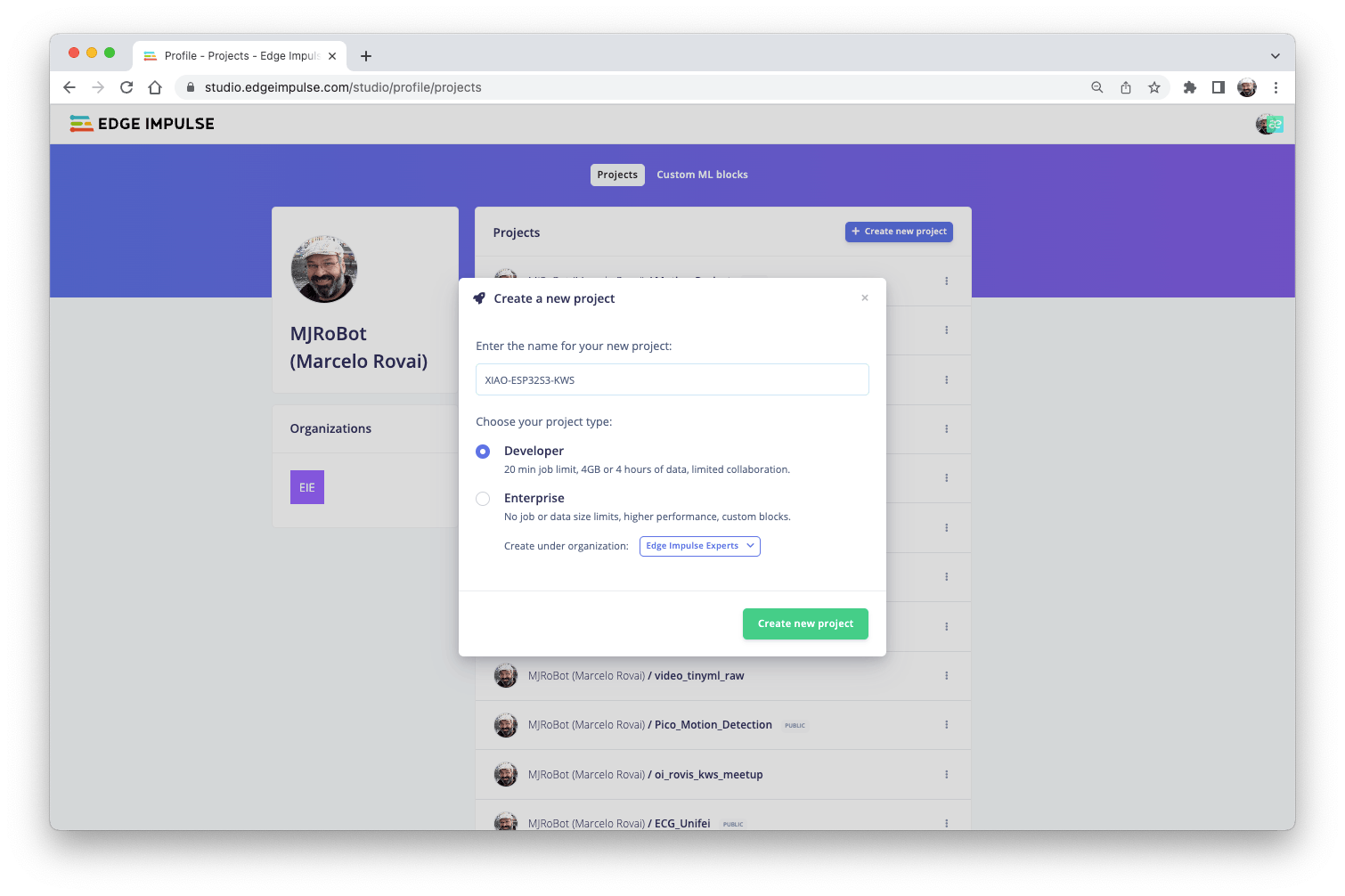
定义和收集原始数据集(Pete 的数据集 + 记录的关键字)后,我们应该在 Edge Impulse Studio 启动一个新项目:
创建项目后,选择Upload Existing Data该Data Acquisition部分中的工具。选择要上传的文件:
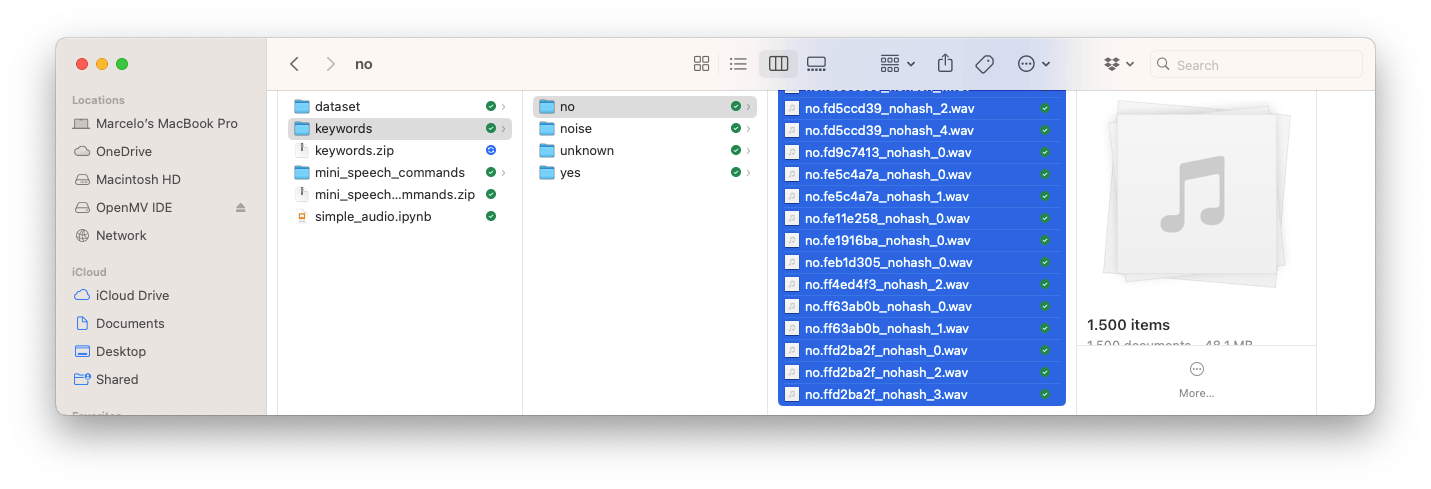
并将它们上传到工作室(您可以在训练/测试中自动拆分数据)。重复所有类和所有原始数据。
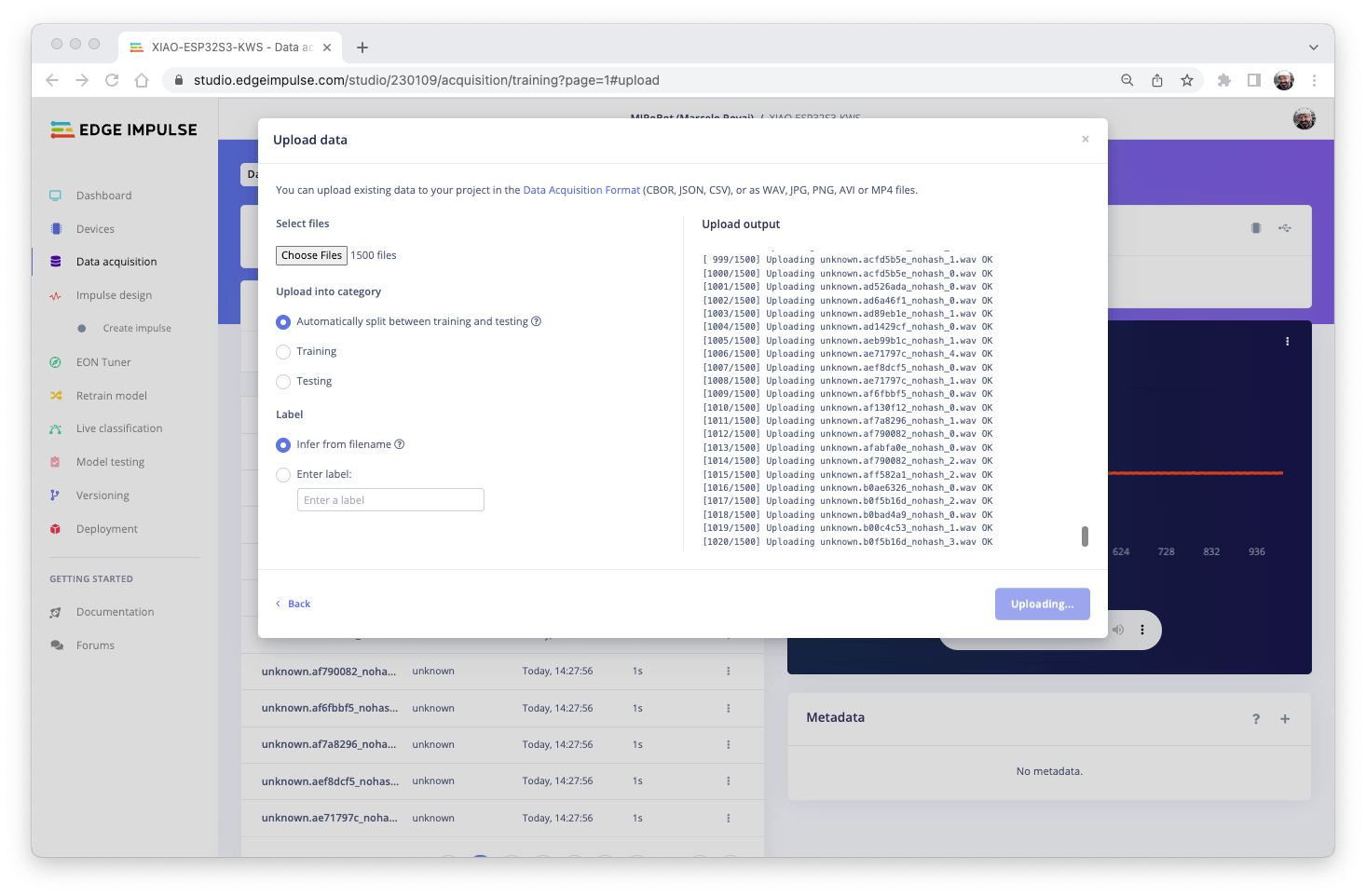
示例现在将出现在该Data acquisition部分中。
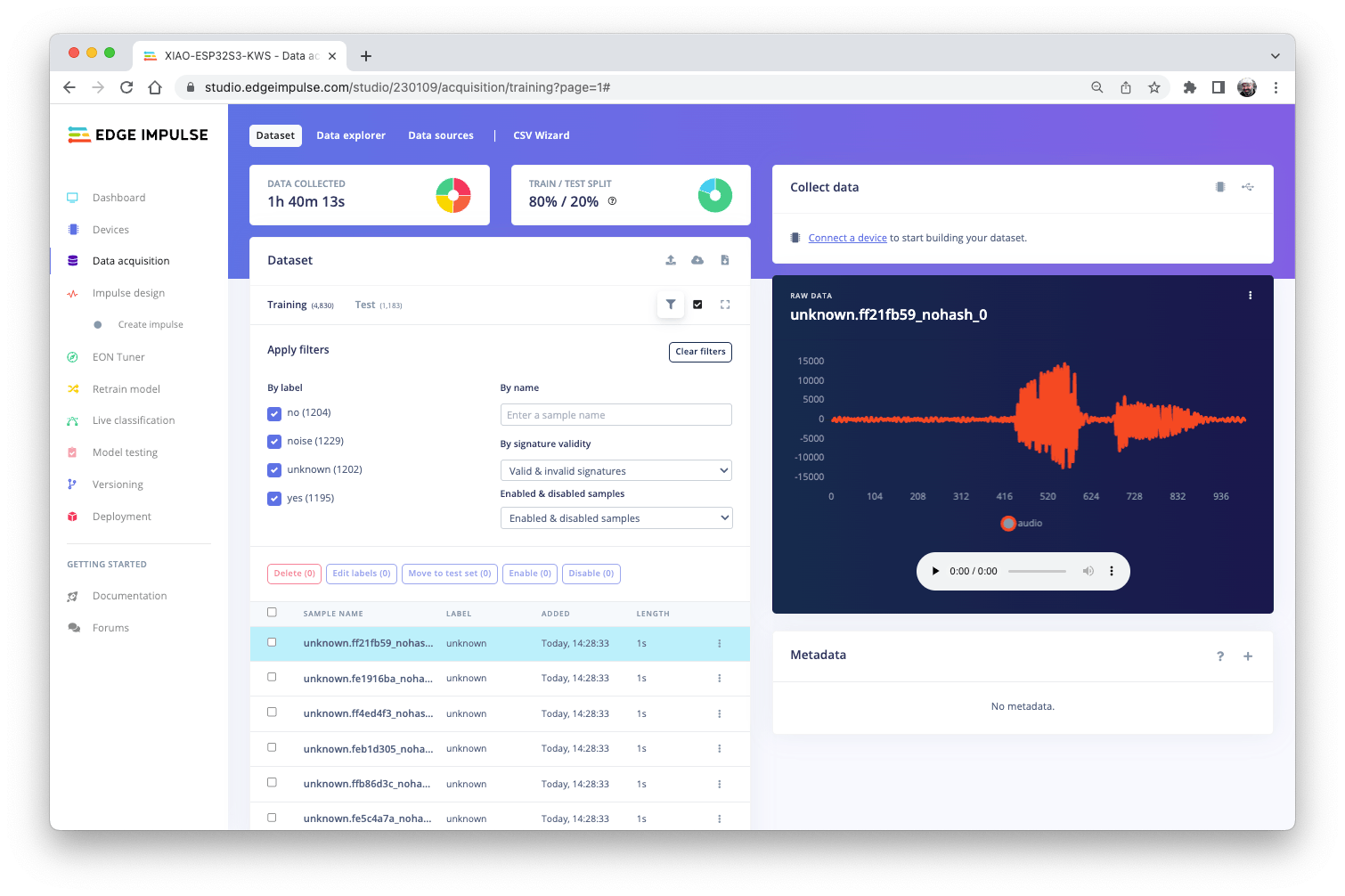
Pete的数据集上所有数据的长度都是1s,但是上一节记录的样本长度是10s,必须拆分成1s的样本才能兼容。
单击示例名称后的三个点并选择Split sample。
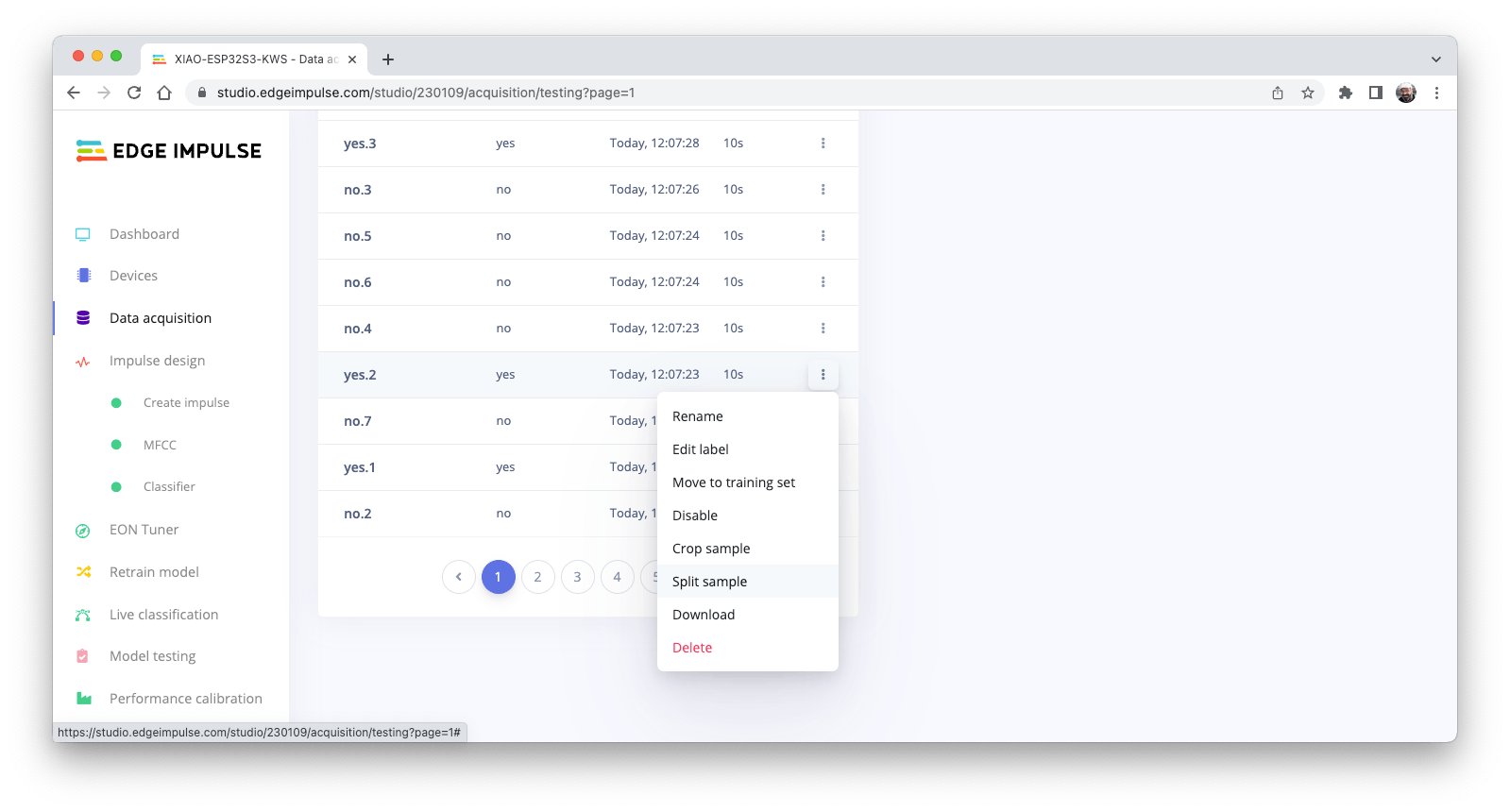
一旦进入 de 工具,将数据拆分为 1 秒记录。如有必要,添加或删除段:
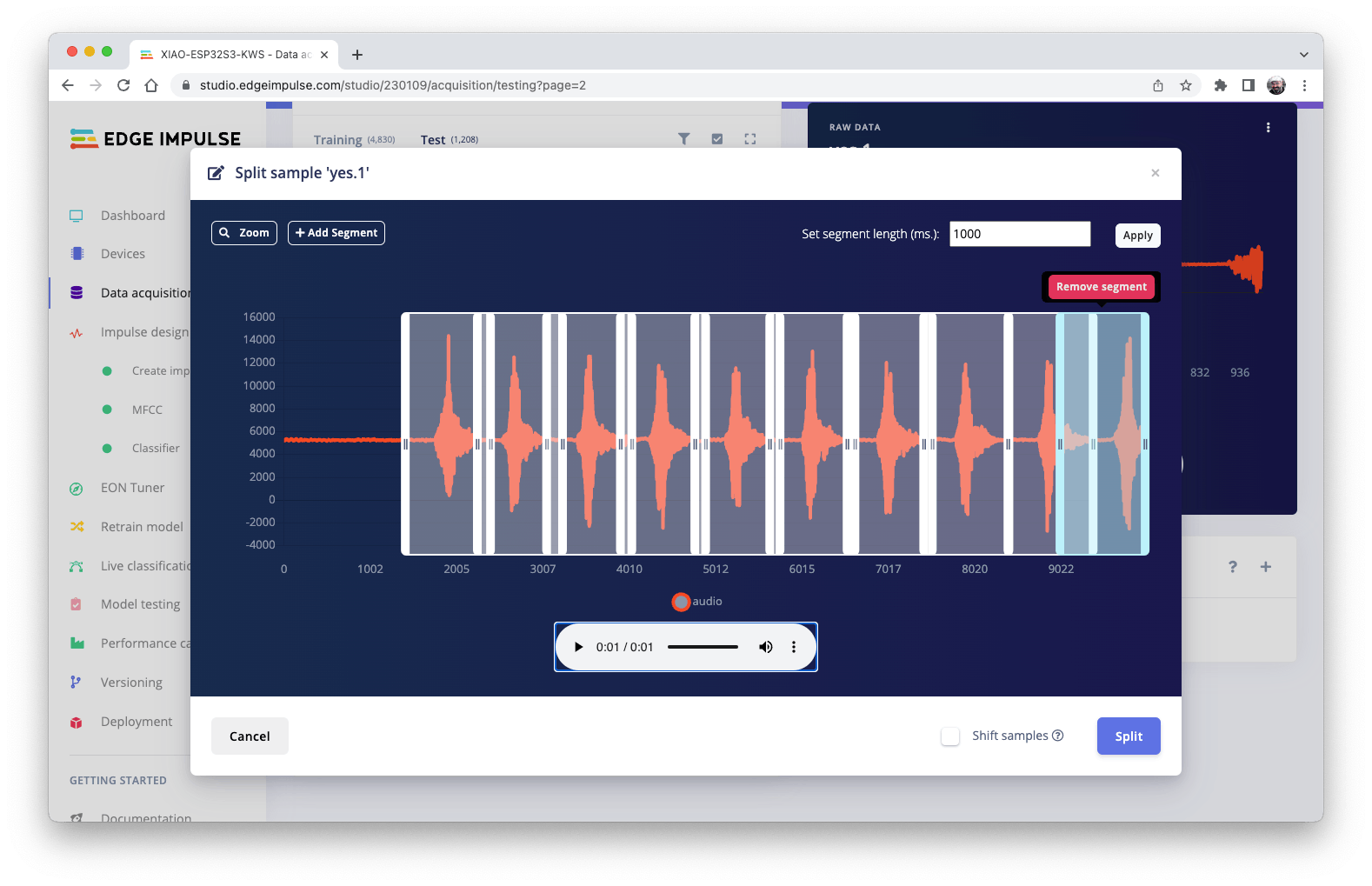
应对所有样品重复此过程。
注意:对于较长的音频文件(分钟),首先,拆分为 10 秒的片段,然后再次使用该工具获得最后的 1 秒拆分。
假设我们在上传期间不在训练/测试中自动拆分数据。在这种情况下,我们可以手动完成(使用三点菜单,单独移动样本)或使用Perform Train / Test Spliton Dashboard - Danger Zone。
我们可以选择使用选项卡检查所有数据集Data Explorer。
创造冲动(预处理/模型定义)
脉冲获取原始数据,使用信号处理来提取特征,然后使用学习块对新数据进行分类。
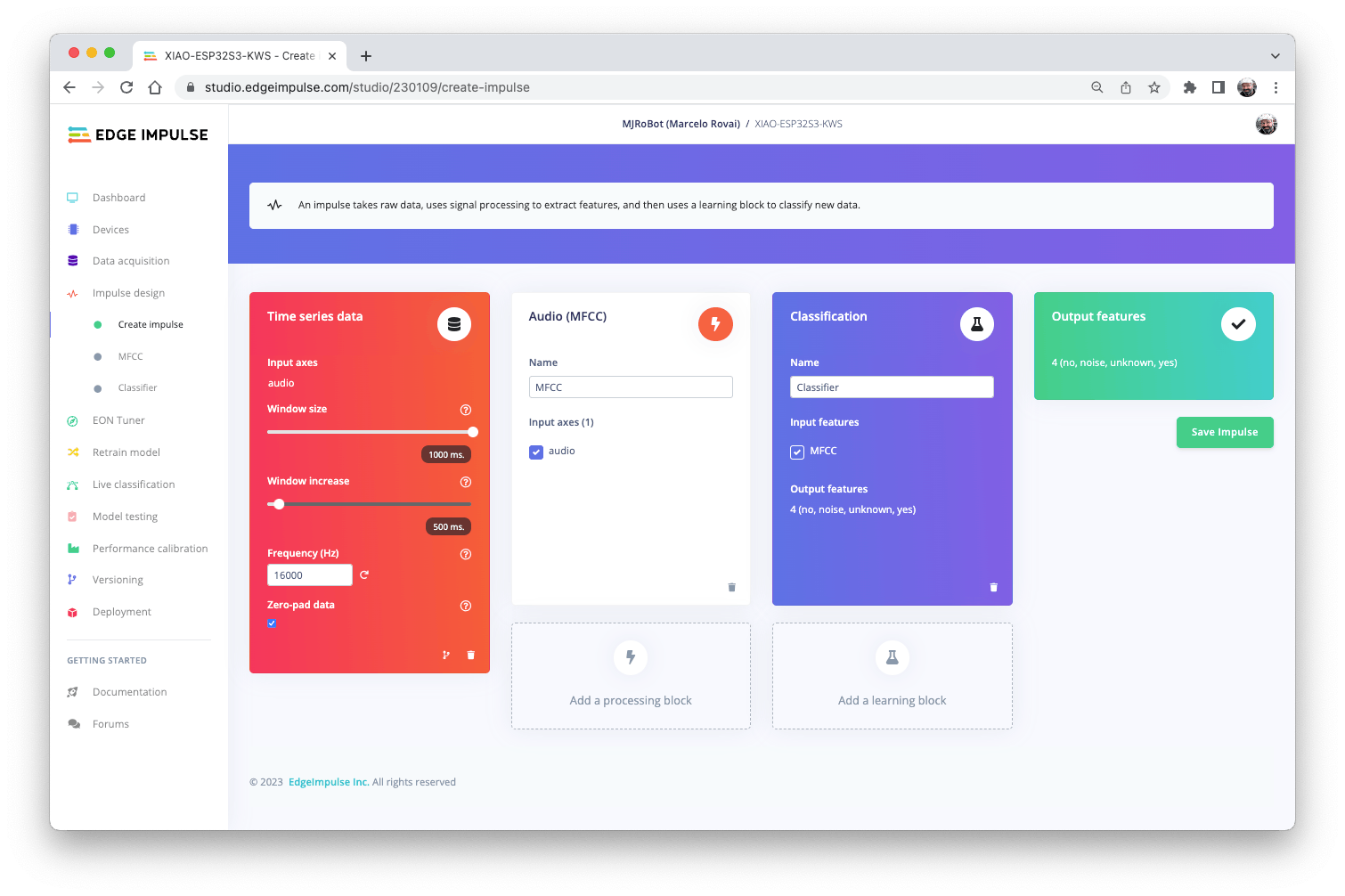
首先,我们将使用 1 秒窗口获取数据点,增加数据,每 500 毫秒滑动该窗口。请注意,该选项zero-pad data已设置。这对于填充小于 1 秒的零样本很重要(在某些情况下,我减少了 1000 毫秒的窗口以split tool避免噪音和尖峰)。
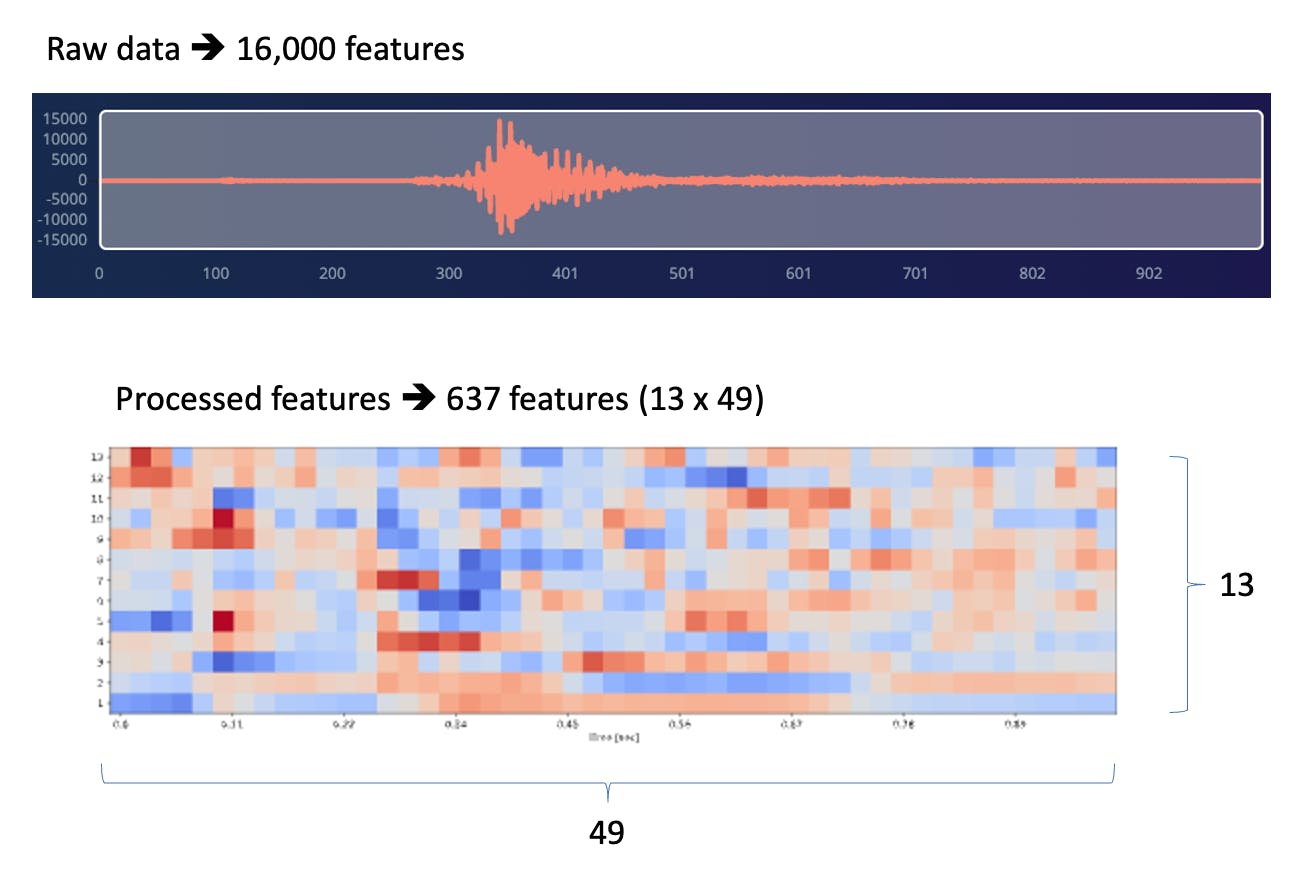
每个 1 秒的音频样本都应进行预处理并转换为图像(例如,13 x 49 x 1)。我们将使用 MFCC,它使用梅尔频率倒谱系数从音频信号中提取特征,这对人声非常有用。
接下来,我们KERAS通过使用卷积神经网络进行图像分类来选择从头开始构建模型的分类。
预处理 (MFCC)
下一步是创建要在下一阶段训练的图像:
我们可以保留默认参数值或利用 DSPAutotuneparameters选项,我们将这样做。
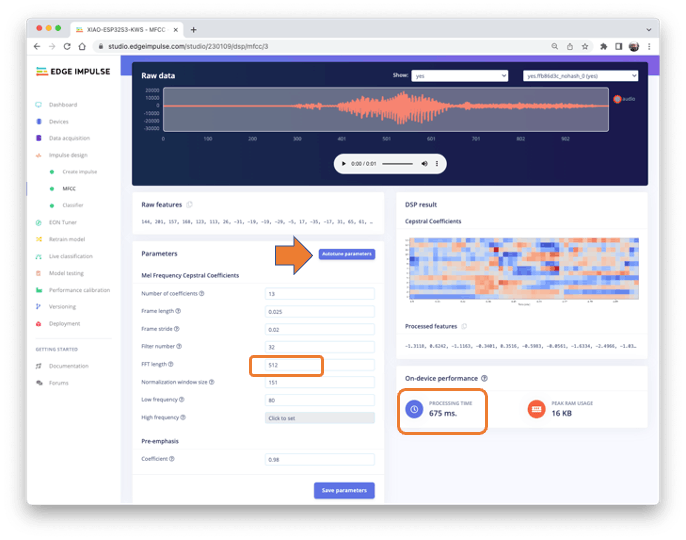
结果不会花费太多内存来预处理数据(仅 16KB)。尽管如此,Espressif ESP-EYE 的估计处理时间仍然很高,为 675 毫秒(最接近的可用参考),时钟频率为 240KHz(与我们的设备相同),但 CPU 更小(XTensa LX6,与 ESP32S 上的 LX7 相比) ). 真正的推理时间应该更小。
假设我们以后需要减少推理时间。在这种情况下,我们应该返回到预处理阶段,例如减少到FFT length、256更改Number of coefficients或其他参数。
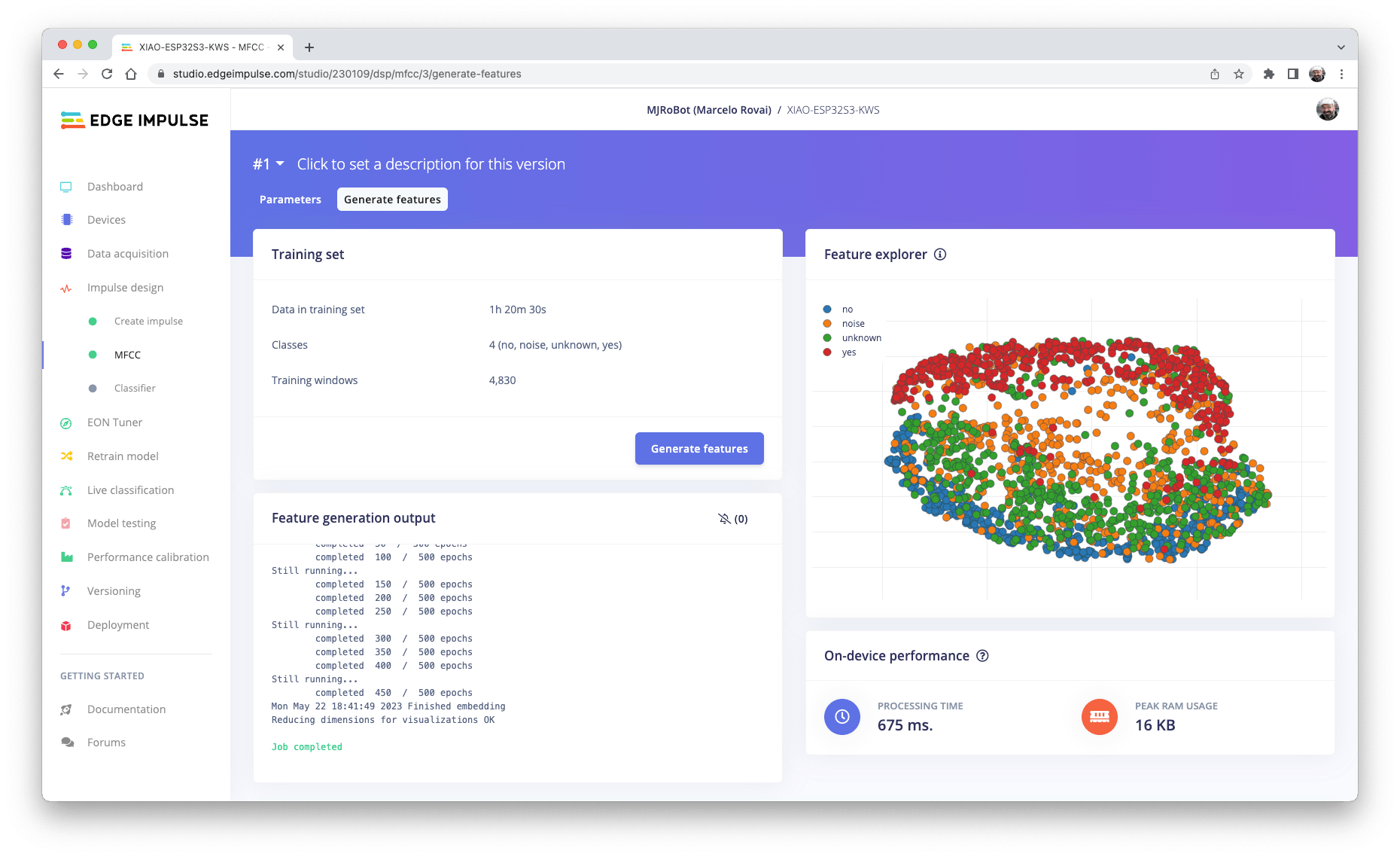
现在,让我们保留工具定义的参数Autotuning。Save parameters并生成特征。
如果您想进一步使用 FFT、频谱图等将时间序列数据转换为图像,您可以使用这个 CoLab:IESTI01_Audio_Raw_Data_Analisys.ipynb。
模型设计与训练
我们将使用卷积神经网络 (CNN) 模型。基本架构由两个 Conv1D + MaxPooling 块(分别具有 8 个和 16 个神经元)和 0.25 Dropout 定义。在最后一层,在 Flattening 四个神经元之后,每个类一个:
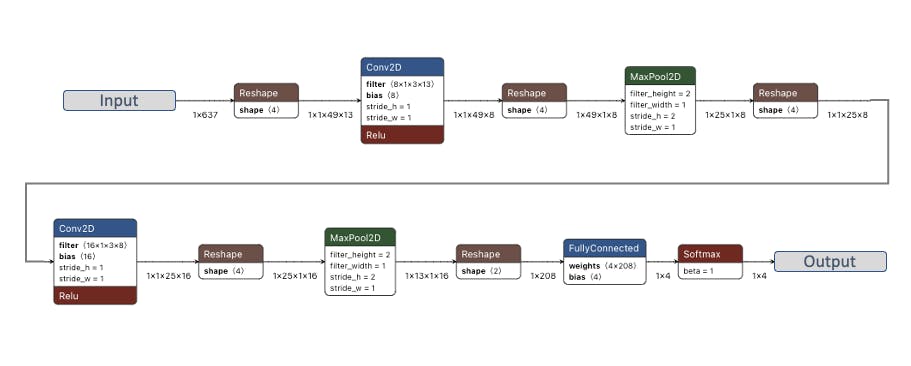
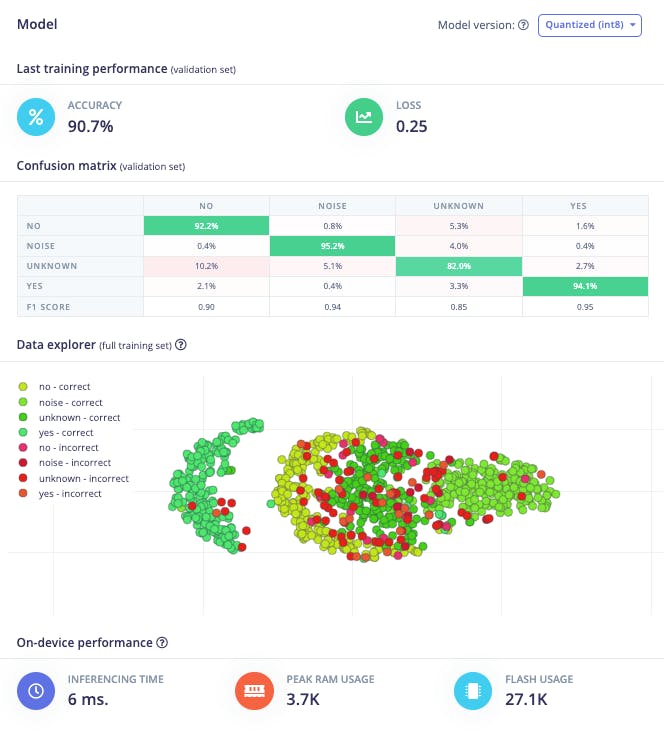
作为超参数,我们将有一个学习率0.005和一个将由100epochs 训练的模型。我们还将包括数据增强,作为一些噪音。结果似乎没问题:
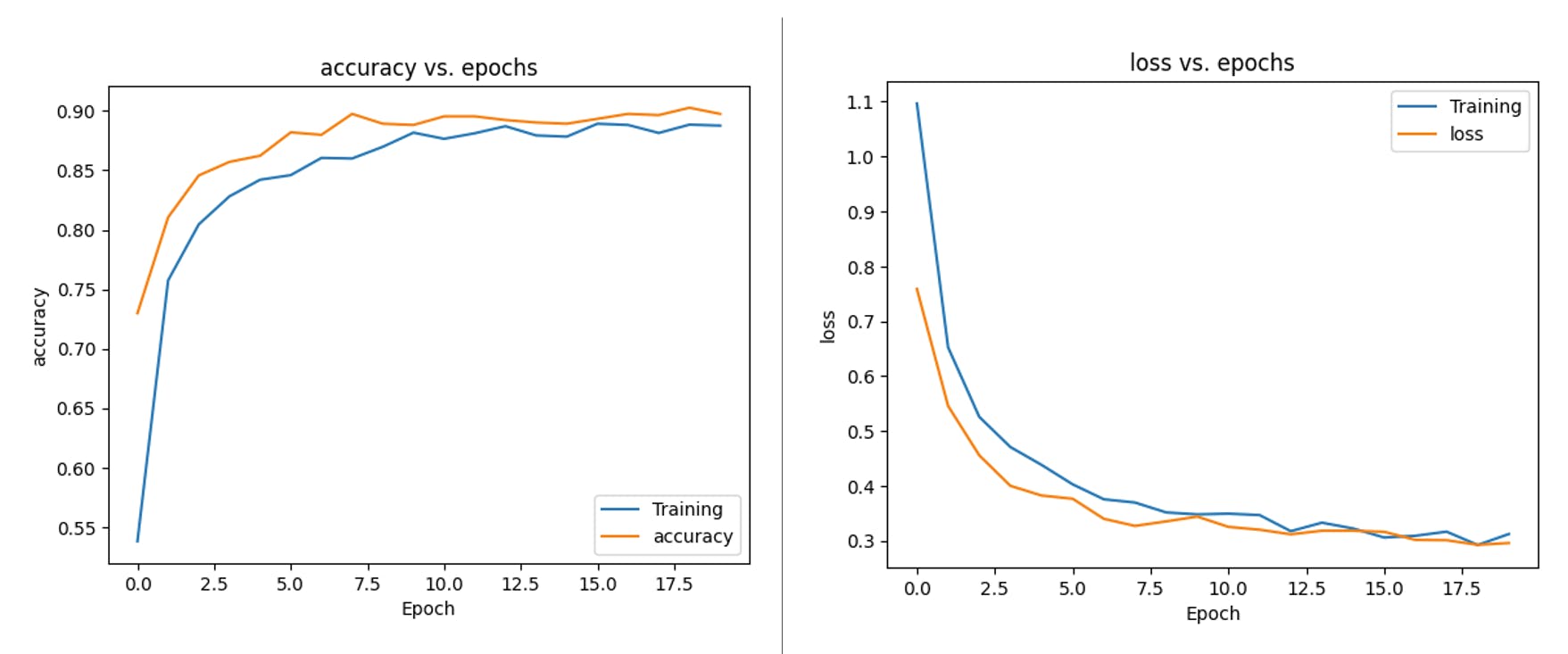
如果您想了解“幕后”发生的事情,您可以下载数据集并运行 Jupyter Notebook 来处理代码。例如,您可以按每个时期分析准确性:
这个 CoLab Notebook 可以解释你如何才能走得更远:KWS 分类器项目 - 看“引擎盖下”。
测试
使用训练前分开的数据(测试数据)测试模型,我们得到了大约 87% 的准确率。
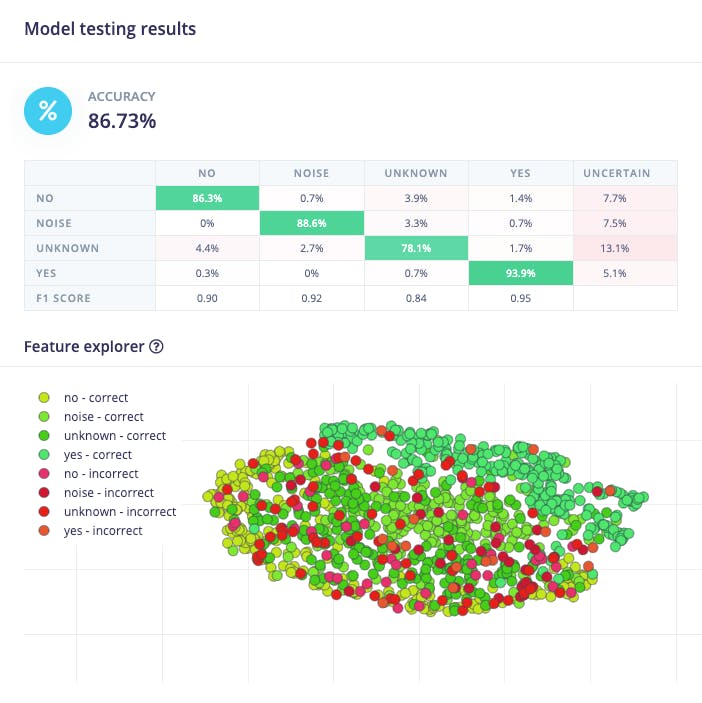
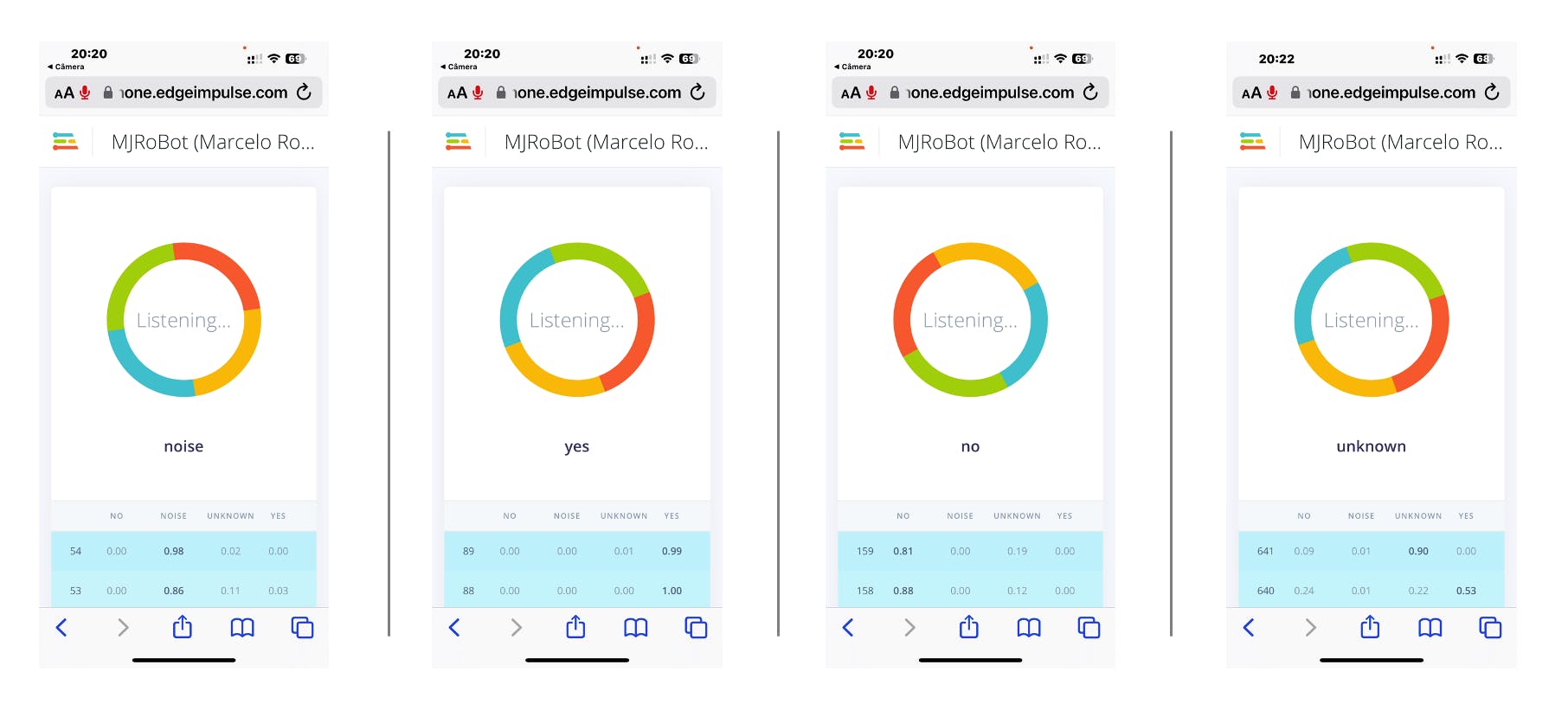
检查 F1 分数,我们可以看到 YES。一旦我们使用此关键字“触发”我们的后处理阶段(打开内置 LED),我们得到了 0.95,这是一个很好的结果。即使是 NO,我们也得到 0.90。最坏的结果是未知,什么都可以。
我们可以继续该项目,但在我们的设备上部署之前,可以使用智能手机执行实时分类。转到该Live Classification部分并单击Connect a Development board:
将您的手机指向条形码并选择链接。
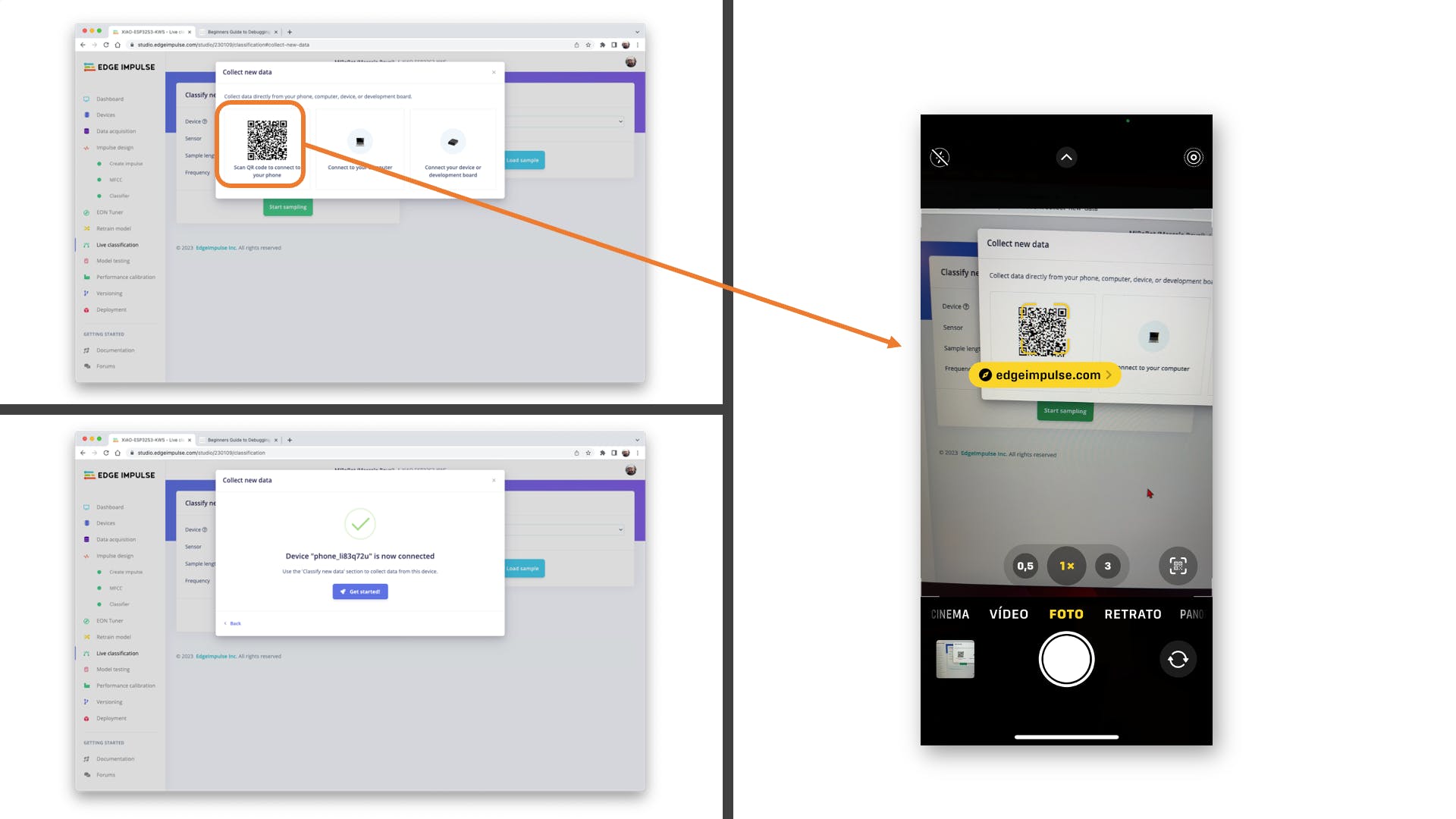
您的手机将连接到 Studio。选择应用程序上的选项Classification,当它运行时,开始测试您的关键字,确认模型正在使用实时和真实数据:
部署和推理
Studio 将打包所有需要的库、预处理函数和经过训练的模型,并将它们下载到您的计算机上。您应该选择该选项Arduino Library,然后在底部选择Quantized (Int8)并按下按钮Build。
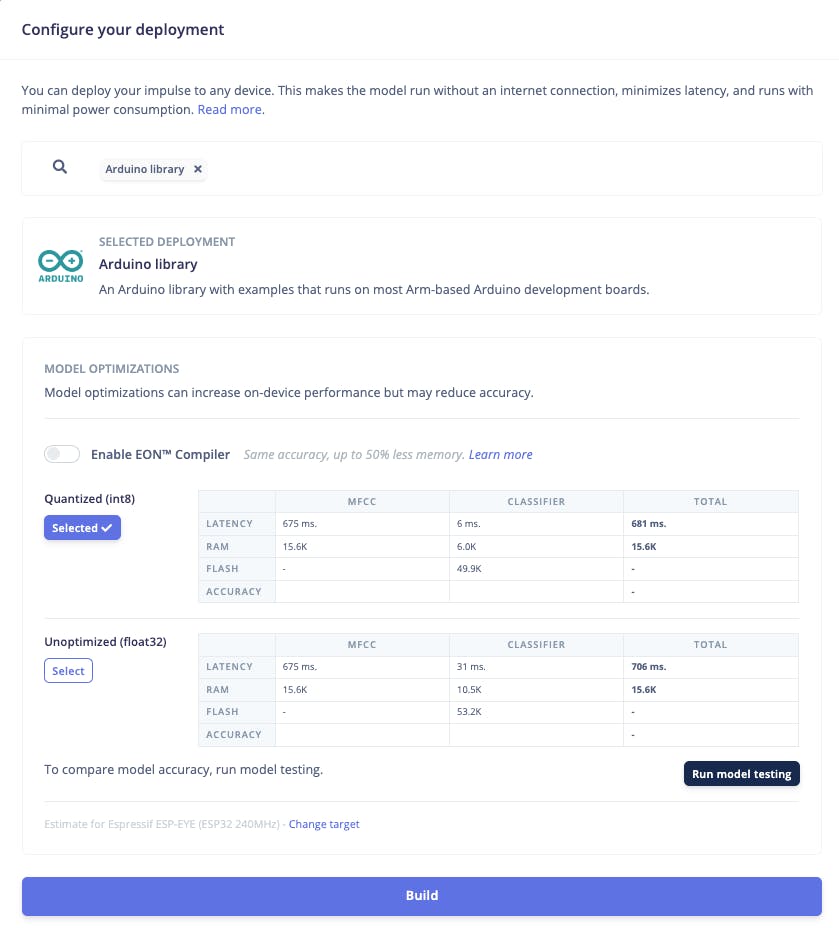
尽管 Edge Impulse 尚未发布其使用 ESP NN 加速器的 ESP32S3 SDK,但感谢Dmitry Maslov,我们可以为 ESP32-S3 恢复和修复其装配优化。这个解决方案还不是官方的,一旦他们解决了与其他板卡的冲突,EI 将把它包含在 EI SDK 中。
目前,这仅适用于非 EON 版本。因此,您还应该保留未选中的选项Enable EON Compiler。
选择构建按钮后,将创建一个 Zip 文件并将其下载到您的计算机。在您的 Arduino IDE 上,转到 Sketch 选项卡并选择选项Add .ZIP Library,然后选择 Studio 下载的 .zip 文件:

在我们使用下载的库之前,我们需要启用 ESP NN 加速器。为此,您可以从项目 GitHub 下载一个初步版本,解压缩,然后用它替换 ESP NN 文件夹:src/edge-impulse-sdk/porting/espressif/ESP-NN,在您的 Arduino 库文件夹中。
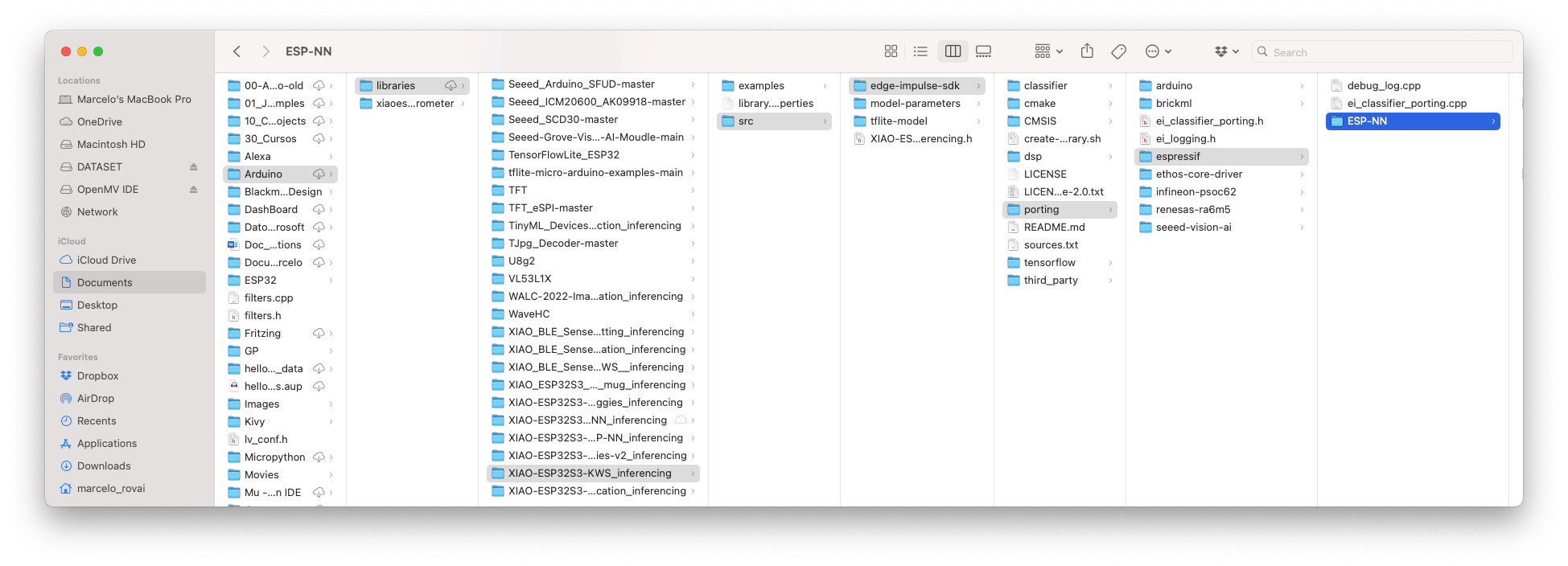
现在是真正测试的时候了。我们将做出与工作室完全脱节的推论。让我们更改部署 Arduino 库时创建的 ESP32 代码示例之一。
在您的 Arduino IDE 中,转到File/Examples选项卡并查找您的项目,然后选择esp32/esp32_microphone:
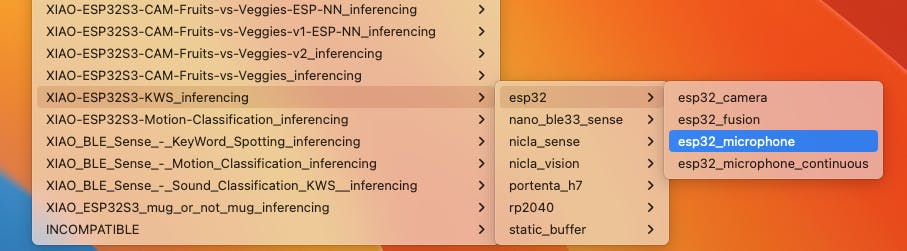
此代码是为 ESP-EYE 内置麦克风创建的,应该适用于我们的设备。
开始更改库以处理 I2S 总线:

经过:
#include
#define SAMPLE_RATE 16000U
#define SAMPLE_BITS 16
在 setup() 中初始化 IS2 麦克风,包括以下行:
void setup()
{
...
I2S.setAllPins(-1, 42, 41, -1, -1);
if (!I2S.begin(PDM_MONO_MODE, SAMPLE_RATE, SAMPLE_BITS)) {
Serial.println("Failed to initialize I2S!");
while (1) ;
...
}
在static void capture_samples(void* arg)函数上,替换从 I2S mic 读取数据的第 153 行:

经过:
/* read data at once from i2s */
esp_i2s::i2s_read(esp_i2s::I2S_NUM_0, (void*)sampleBuffer, i2s_bytes_to_read, &bytes_read, 100);
在 function 上static bool microphone_inference_start(uint32_t n_samples),我们应该注释或删除第 198 到 200 行,其中调用了麦克风初始化函数。这不是必需的,因为 I2S 麦克风在 ) 期间已经初始化setup(。

最后,在static void microphone_inference_end(void)功能上,替换第 243 行:

经过:
static void microphone_inference_end(void)
{
free(sampleBuffer);
ei_free(inference.buffer);
}
您可以在项目的 GitHub上找到完整的代码。将草图上传到您的电路板并测试一些真实的推论:
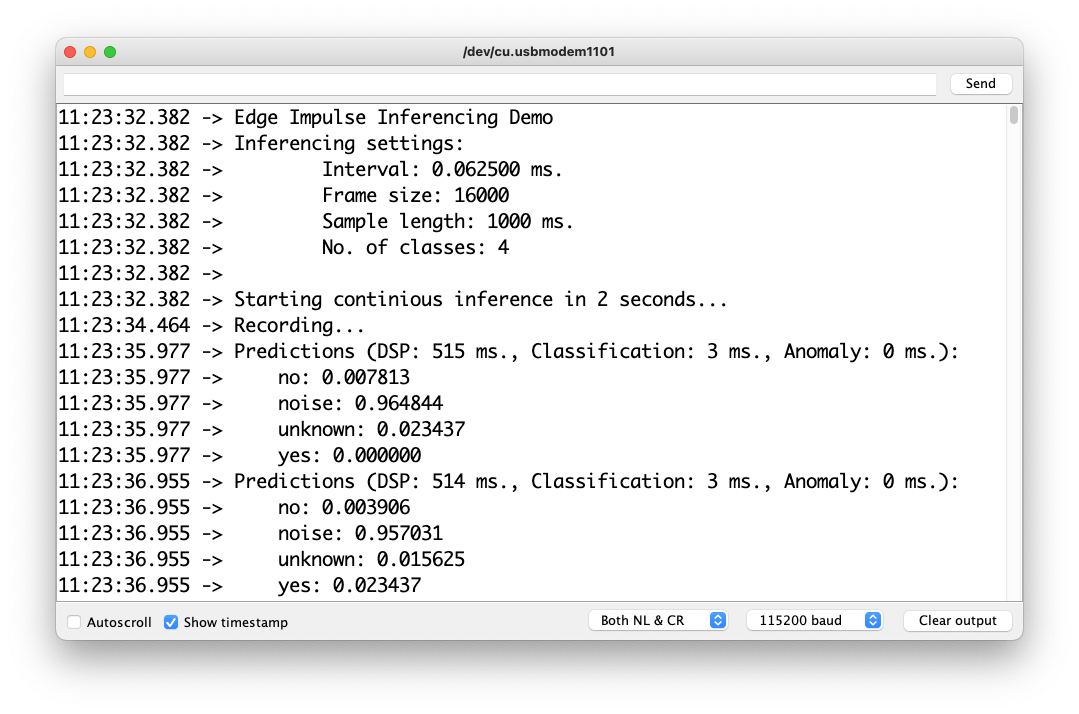
后期处理
现在我们知道模型通过检测我们的关键字工作,让我们修改代码以查看每次检测到 YES 时内部 LED 亮起。
您应该初始化 LED:
#define LED_BUILT_IN 21
...
void setup()
{
...
pinMode(LED_BUILT_IN, OUTPUT); // Set the pin as output
digitalWrite(LED_BUILT_IN, HIGH); //Turn off
...
}
并更改// print the predictions 先前代码的部分(在loop():
int pred_index = 0; // Initialize pred_index
float pred_value = 0; // Initialize pred_value
// print the predictions
ei_printf("Predictions ");
ei_printf("(DSP: %d ms., Classification: %d ms., Anomaly: %d ms.)",
result.timing.dsp, result.timing.classification, result.timing.anomaly);
ei_printf(": \n");
for (size_t ix = 0; ix < EI_CLASSIFIER_LABEL_COUNT; ix++) {
ei_printf(" %s: ", result.classification[ix].label);
ei_printf_float(result.classification[ix].value);
ei_printf("\n");
if (result.classification[ix].value > pred_value){
pred_index = ix;
pred_value = result.classification[ix].value;
}
}
// show the inference result on LED
if (pred_index == 3){
digitalWrite(LED_BUILT_IN, LOW); //Turn on
}
else{
digitalWrite(LED_BUILT_IN, HIGH); //Turn off
}
您可以在项目的 GitHub 上找到完整的代码。将草图上传到您的电路板并测试一些真实的推论:
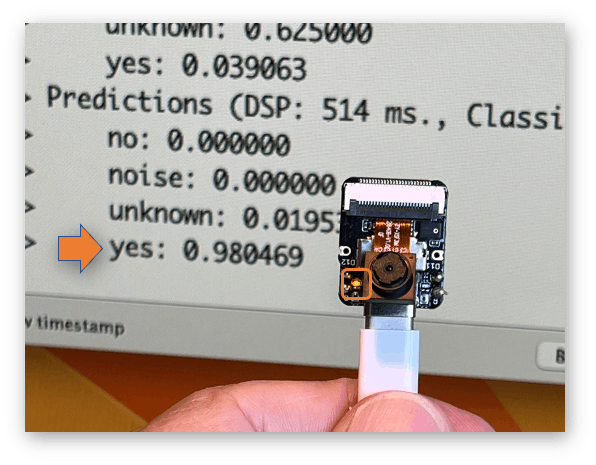
这个想法是,只要检测到关键字 YES,LED 就会亮起。同样,这不是打开 LED,而是外部设备的“触发器”,正如我们在介绍中看到的那样。
结论
Seeed XIAO ESP32S3 Sense 是一个巨大的微型设备!然而,它功能强大、值得信赖、价格不贵、功耗低,并且具有适用于最常见的嵌入式机器学习应用(如视觉和声音)的传感器。尽管 Edge Impulse 并未正式支持 XIAO ESP32S3 Sense(目前!),但我们意识到使用 Studio 进行训练和部署非常简单。
在我的GitHub 存储库中,您将找到该项目中使用的所有代码的最新版本以及 XIAO ESP32S3 系列的先前版本。
在我们结束之前,请考虑声音分类不仅仅是语音。例如,您可以在多个领域围绕声音开发 TinyML 项目,例如:
- 安全(碎玻璃检测)
- 工业(异常检测)
- 医疗(打鼾、辗转反侧、肺部疾病)
- 自然(蜂箱控制、昆虫声音)
了解更多
如果您想了解有关嵌入式机器学习 (TinyML) 的更多信息,请参阅以下参考资料:
- “ TinyML - 嵌入设备的机器学习” - UNIFEI
- “微型机器学习专业证书 (TinyML)” – edX/Harvard
- 《嵌入式机器学习入门》- Coursera/Edge Impulse
- “带有嵌入式机器学习的计算机视觉” - Coursera/Edge Impulse
- François Chollet 的“ Deep Learning with Python”
- Pete Warden 和 Daniel Situnayake 的“ TinyML”
- Gian Marco Iodice 的“ TinyML Cookbook”
- Daniel Situnayake 和 Jenny Plunkett 的“ AI at the Edge”
在TinyML4D 网站上,您可以找到很多关于 TinyML 的教育资料。它们都是免费和开源的,用于教育用途——我们要求如果您使用这些材料,请引用它们!TinyML4D 是一项旨在让全球所有人都能获得 TinyML 教育的倡议。
- TinyML变得简单:图像分类
- TinyML课程#7变得更小
- 语音识别_ML-KWS-for-MCU_资料整理
- 云服务器中同态加密关键词检索方案分析 5次下载
- 基于关键词的GCC抽象语法树消除冗余算法 210次下载
- 一种基于位置信息的关键词自动化提取算法 3次下载
- 一种基于词和文档嵌入的关键词抽取方法 4次下载
- 结合通配符模式与随机游走算法的关键词提取方法 14次下载
- 融合BERT词向量与TextRank的关键词抽取方法 18次下载
- 支持检索关键词语义扩展的可排序密文检索方案详细资料说明 15次下载
- 实现支持检索关键词语义扩展的可排序密文检索的方案详细说明 10次下载
- 对加密电子医疗记录的关键词的搜索 0次下载
- 基于关键词相似度的用户挖掘研究 0次下载
- 基于强度熵解决中文关键词识别 7次下载
- 基于动态排位信息的语音关键词确认方法
- 气密性检测干货!150个核心关键词,一文看懂 91次阅读
- 如何在雅特力AT32 MCU上实现关键词语音识别(KWS) 967次阅读
- 基于SensiML平台开发语音关键词识别 570次阅读
- 在MAX78000上开发功耗优化应用 862次阅读
- 如何使用TinyML在内存受限的设备上部署ML模型呢 1176次阅读
- 如何才能自己做词云图 8343次阅读
- 如何在 MCU 上快速部署 TinyML 1886次阅读
- 如何利用TinyML实现语音识别机器人车的设计 2326次阅读
- dfrobot语音识别控制板 介绍 3202次阅读
- Python数据挖掘:WordCloud词云配置过程及词频分析 3977次阅读
- 一种改变标准的谷歌关键词搜索的新方式 6823次阅读
- 基于Cortex-M处理器上实现高精度关键词语音识别 1993次阅读
- 自然语言处理技术入门之基于关键词生成文本的技术实现过程 1w次阅读
- 如何让光伏逆变器效率测量变得更简单 1552次阅读
- 科普:12大关键词让你了解机器学习 1893次阅读

 上传资料赚积分
上传资料赚积分下载排行
本周
- 1山景DSP芯片AP8248A2数据手册
- 1.06 MB | 532次下载 | 免费
- 2RK3399完整板原理图(支持平板,盒子VR)
- 3.28 MB | 339次下载 | 免费
- 3TC358743XBG评估板参考手册
- 1.36 MB | 330次下载 | 免费
- 4DFM软件使用教程
- 0.84 MB | 295次下载 | 免费
- 5元宇宙深度解析—未来的未来-风口还是泡沫
- 6.40 MB | 227次下载 | 免费
- 6迪文DGUS开发指南
- 31.67 MB | 194次下载 | 免费
- 7元宇宙底层硬件系列报告
- 13.42 MB | 182次下载 | 免费
- 8FP5207XR-G1中文应用手册
- 1.09 MB | 178次下载 | 免费
本月
- 1OrCAD10.5下载OrCAD10.5中文版软件
- 0.00 MB | 234315次下载 | 免费
- 2555集成电路应用800例(新编版)
- 0.00 MB | 33566次下载 | 免费
- 3接口电路图大全
- 未知 | 30323次下载 | 免费
- 4开关电源设计实例指南
- 未知 | 21549次下载 | 免费
- 5电气工程师手册免费下载(新编第二版pdf电子书)
- 0.00 MB | 15349次下载 | 免费
- 6数字电路基础pdf(下载)
- 未知 | 13750次下载 | 免费
- 7电子制作实例集锦 下载
- 未知 | 8113次下载 | 免费
- 8《LED驱动电路设计》 温德尔著
- 0.00 MB | 6656次下载 | 免费
总榜
- 1matlab软件下载入口
- 未知 | 935054次下载 | 免费
- 2protel99se软件下载(可英文版转中文版)
- 78.1 MB | 537798次下载 | 免费
- 3MATLAB 7.1 下载 (含软件介绍)
- 未知 | 420027次下载 | 免费
- 4OrCAD10.5下载OrCAD10.5中文版软件
- 0.00 MB | 234315次下载 | 免费
- 5Altium DXP2002下载入口
- 未知 | 233046次下载 | 免费
- 6电路仿真软件multisim 10.0免费下载
- 340992 | 191187次下载 | 免费
- 7十天学会AVR单片机与C语言视频教程 下载
- 158M | 183279次下载 | 免费
- 8proe5.0野火版下载(中文版免费下载)
- 未知 | 138040次下载 | 免费





 工商网监
工商网监
评论