 干货 | 机器学习加持,基于FPGA的高性能视觉应用方案设计
干货 | 机器学习加持,基于FPGA的高性能视觉应用方案设计

随着摄像头和其他设备产生的数据在快速增长,促使人们运用机器学习从汽车、安防和其他应用产生的影像中提取更多有用的信息。专用器件有望在嵌入式视觉应用中实现高性能机器学习 (ML) 推理。但是此类器件大都处于早期开发阶段,因为设计人员正在努力寻找最有效的算法,甚至人工智能 (AI) 研究人员也在迅速推演新方法。
目前,开发人员一般使用针对 ML 的可用 FPGA 平台来构建嵌入式视觉系统,以期满足更高的性能要求。与此同时,他们可以保持所需的灵活性,以跟上机器学习发展的步伐。
本文将介绍 ML 处理的要求,以及为何 FPGA 能解决许多性能问题。然后,将介绍一个合适的基于 FPGA 的 ML 平台及其使用方法。
机器学习算法和推理引擎
在 ML 算法中,卷积神经网络 (CNN) 已成为图像分类的首选解决方案。其图像识别的准确率非常高,因而得以广泛应用于多种应用,跨越不同的平台,例如智能手机、安防系统和汽车驾驶员辅助系统。作为一种深度神经网络 (DNN),CNN 使用的神经网络架构由专用层构成。在对标注图像进行训练期间,它会从图像中提取特征,并使用这些特征给图像分类(参见“利用现成的软硬件启动机器学习”)。
CNN 开发人员通常在高性能系统或云平台上进行训练,使用图形处理单元 (GPU) 加速在标注图像数据集(通常数以百万计)上训练模型所需的巨量矩阵计算。训练完成之后,训练好的模型用在推理应用中,对视频流中的新图像或帧进行分类。推理部署完成后,训练好的模型仍然需要执行同样的矩阵计算,但由于输入量要少很多,开发人员可以将 CNN 用于在通用硬件上运行的普通机器学习应用(参见“利用 Raspberry Pi 构建机器学习应用”)。
然而,对于许多应用而言,通用平台缺乏在 CNN 推理中同时实现高准确率和高性能所需的性能。优化技术和替代 CNN 架构(如 MobileNet 或 SqueezeNet)有助于降低平台要求,但通常会牺牲准确率并增加推理延时,而这可能与应用要求相冲突。
与此同时,快速发展的算法使得机器学习 IC 的设计工作变得复杂,因为需要机器学习 IC 既要足够专门化以加速推理,又要足够通用化以支持新算法。FPGA 多年来一直扮演着这一特定角色,提供加速关键算法所需的性能和灵活性,解决了通用处理器性能不足或没有专用器件可用的问题。
FPGA 作为机器学习平台
对于机器学习而言,GPU 仍然是标杆——这是早期的 FPGA 根本无法企及的。最近出现的一些器件,如 Intel Arria 10 GX FPGA 和 Lattice Semiconductor ECP5 FPGA,大大缩小了先进 FPGA 和 GPU 之间的差距。对于某些使用紧凑的整数数据类型的 DNN 架构来说,此类 FPGA 的性能/功耗比甚至高于主流 GPU。
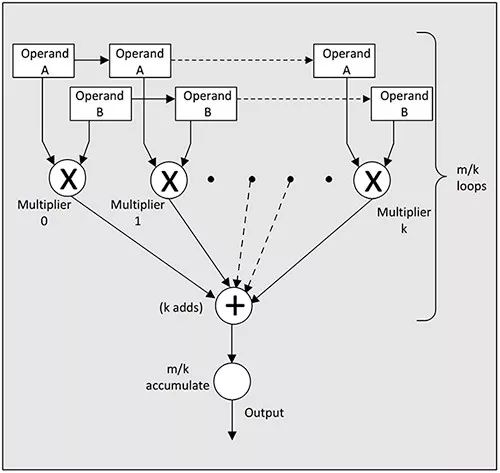
高级 FPGA 组合了嵌入式存储器和数字信号处理 (DSP) 资源,对于一般矩阵乘法 (GEMM) 运算能够实现很高的性能。其嵌入式存储器靠近计算引擎,从而缓解了 CPU 存储器瓶颈,而这种瓶颈通常会限制通用处理器上机器学习算法的性能。反之,相比于典型 DSP 器件(图 1),FPGA 上的嵌入式 DSP 计算引擎提供了更多的并行乘法器资源。FPGA 厂商在交付专门用于机器学习的 FPGA 开发平台时充分利用了这些特性。
例如,Intel 最近推出的支持 FPGA 的 OPENVINO™ 扩展了该平台将推理模型部署到不同类型设备(包括 GPU、CPU 和 FPGA)的能力。在该平台上,开发人员可使用 Intel 的深度学习推理引擎工作流程,其中整合了 Intel 深度学习部署工具包和在 Intel OPENVINO 工具包中提供的 Intel 计算机视觉软件开发套件 (SDK)。开发人员使用 SDK 的应用编程接口 (API) 构建模型,并且可利用 Intel 的运行模型优化器针对不同硬件平台进行优化。
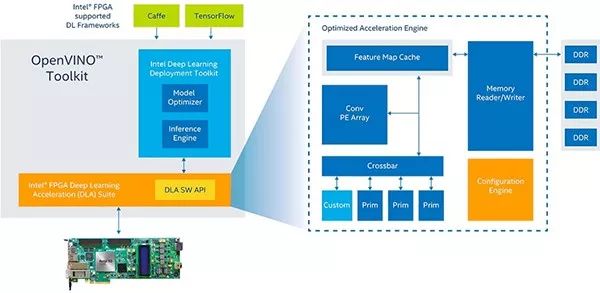
深度学习部署工具包旨在与 Intel DK-DEV-10AX115S-A Arria 10 GX FPGA 开发套件配合使用,让开发人员能从领先的 ML 框架(包括 Caffe 和 TensorFlow)导入训练好的模型(图 2)。在诸如 Arria 10 GX FPGA 开发套件之类目标平台或使用 Arria 10 GX FPGA 器件的定制设计上,工具包中的模型优化器和推理引擎分别处理模型转换和部署。
为了迁移预训练模型,开发人员使用基于 Python 的模型优化器生成了一个中间表示 (IR),该表示包含在一个提供网络拓扑的 xml 文件和一个以二进制值提供模型参数的 bin 文件中。除了生成 IR 之外,模型优化器还会执行一项关键功能——移除模型中用于训练但对推理毫无作用的层。此外,该工具会在可能的情况下将每个提供独立数学运算的层合并到一个组合层中。
通过这种网络修剪和合并,模型变得更紧凑,进而加快推理时间并减少对目标平台的存储器需求。
Intel 推理引擎是一个 C++ 库,其中包含一组 C++ 类。这些类对于受支持的目标硬件平台来说是通用的,因此可以在各个平台上实现推理。对于推理应用而言,开发人员使用像 CNNNetReader 这样的类来读取 xml 文件 (ReadNetwork) 中包含的 CNN 拓扑以及 bin 文件 (ReadWeights) 中包含的模型参数。模型加载完成后,调用类方法 Infer() 执行阻塞推理,同时调用类方法 StartAsync() 执行异步推理,当推理完成时使用等待或完成例程处理结果。
Intel 在 OPENVINO 环境提供的多个示例应用程序中演示了完整的工作流程和详细的推理引擎 API 调用。例如,安全屏障摄像机示例应用程序展示了使用推理模型流水线,以首先确定车辆边界框(图 3)。流水线中的下一个模型检查了边界框中的内容,识别车辆类别、颜色和车牌位置等车辆属性。
流水线中的最后一个模型使用这些车辆属性从车牌中提取字符。
-
FPGA
+关注
关注
1664文章
22502浏览量
639189 -
机器学习
+关注
关注
67文章
8564浏览量
137221
原文标题:机器学习加持,基于FPGA的高性能视觉应用方案设计
文章出处:【微信号:cirmall,微信公众号:电路设计技能】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
京微齐力推出全新高性能AI视觉处理FPGA芯片产品
深度解析瑞芯微RK182X系列:一款为AI机器视觉而生的高性能协处理器
机器视觉网卡与普通网卡的5点关键不同

国产高性能ONFI IP解决方案全解析
FPGA+GPU异构混合部署方案设计
机器视觉的核心技术和应用场景
AMD UltraScale架构:高性能FPGA与SoC的技术剖析
Valens与 Imavix 联手推出业界首款基于MIPI A-PHY 的机器视觉平台,CIS 同步发布首款符合A-PHY标准的摄像头
【团购】独家全套珍藏!龙哥LabVIEW视觉深度学习实战课程(11大系列课程,共5000+分钟)
高精度机器人控制的核心——基于 MYD-LT536 开发板的精密运动控制方案
机器视觉检测PIN针
如何在机器视觉中部署深度学习神经网络




评论