 从8小时到80秒,NVIDIA如何实现AI训练用时大突破?
从8小时到80秒,NVIDIA如何实现AI训练用时大突破?

“天下武功,唯快不破”,你需要以“快”制胜。
如今,全球顶级公司的研究人员和数据科学家团队们都在致力于创建更为复杂的AI模型。但是,AI模型的创建工作不仅仅是设计模型,还需要对模型进行快速地训练。
这就是为什么说,如果想在AI领域保持领导力,就首先需要有赖于AI基础设施的领导力。而这也正解释了为什么MLPerf AI训练结果如此之重要。
通过完成全部6项MLPerf基准测试,NVIDIA展现出了全球一流的性能表现和多功能性。NVIDIA AI平台在训练性能方面创下了八项记录,其中包括三项大规模整体性能纪录和五项基于每个加速器的性能纪录。
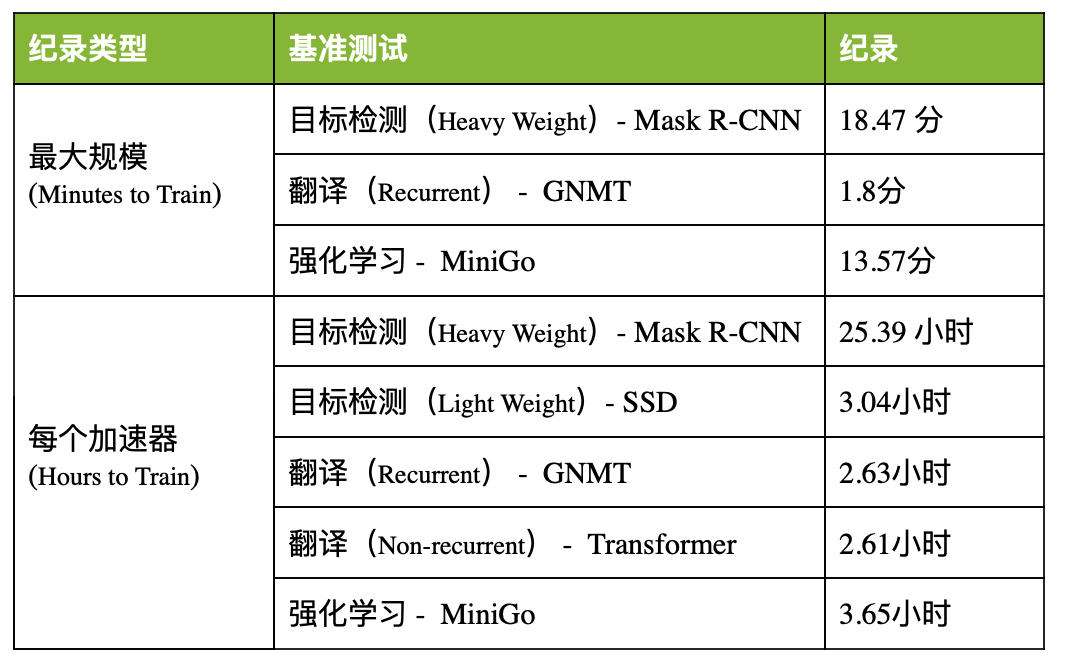
表1:NVIDIA MLPerf AI纪录
每个加速器的比较基于早前报告的基于单一NVIDIA DGX-2H(16个V100 GPU)、与其他同规模相比较的MLPerf 0.6的性能(除MiniGo采用的是基于8个V100 GPU的NVIDIA DGX-1)|最大规模MLPerf ID:Mask R-CNN:0.6-23,GNMT:0.6-26,MiniGo:0.6-11 |每加速器MLPerf ID:Mask R-CNN,SSD,GNMT,Transformer:全部使用0.6-20,MiniGo:0.6-10
以上测试结果数据由谷歌、英特尔、百度、NVIDIA、以及创建MLPerf AI基准测试的其他数十家顶级技术公司和大学提供背书,能够转化为具有重要意义的创新。
简而言之,NVIDIA的AI平台如今能够在不到两分钟的时间内完成此前需要一个工作日才能完成的模型训练。
各公司都知道,释放生产力是一件重中之重的要务。超级计算机如今已经成为了AI的必备工具,树立AI领域的领导力首先需要强大的AI计算基础设施支持。
NVIDIA最新的MLPerf结果很好地展示了将NVIDIA V100 Tensor核心GPU应用于超算级基础设施中所能带来的益处。
在2017年春季的时候,使用搭载了V100 GPU的NVIDIA DGX-1系统训练图像识别模型ResNet-50,需要花费整整一个工作日(8小时)的时间。
而如今,同样的任务,NVIDIA DGX SuperPOD使用相同的V100 GPU,采用Mellanox InfiniBand进行互联,并借助可用于分布式AI训练的最新NVIDIA优化型AI软件,仅需80秒即可完成。
80秒的时间,甚至都不够用来冲一杯咖啡。
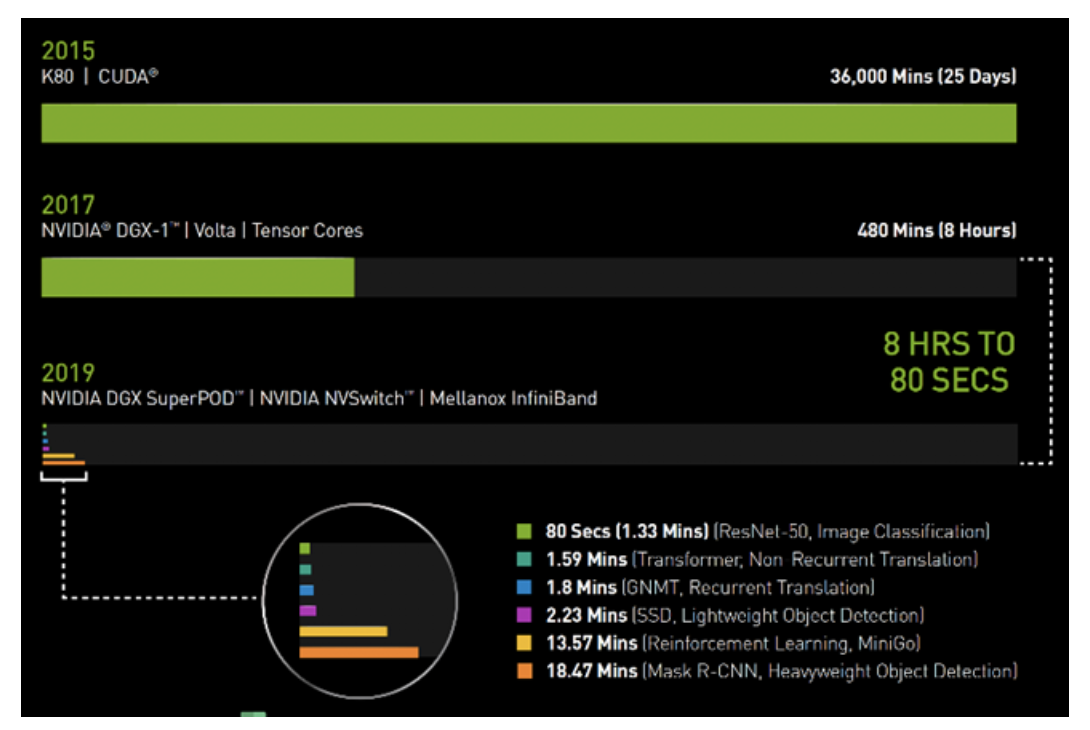
图1:AI时间机器
2019年MLPerf ID(按图表从上到下的顺序):ResNet-50:0.6-30 | Transformer:0.6-28 | GNMT:0.6-14 | SSD:0.6-27 | MiniGo:0.6-11 | Mask R-CNN:0
AI的必备工具:DGX SuperPOD能够更快速地完成工作负载
仔细观察今日的MLPerf结果,会发现NVIDIA DGX SuperPOD是唯一在所有六个MLPerf类别中耗时都少于20分钟的AI平台: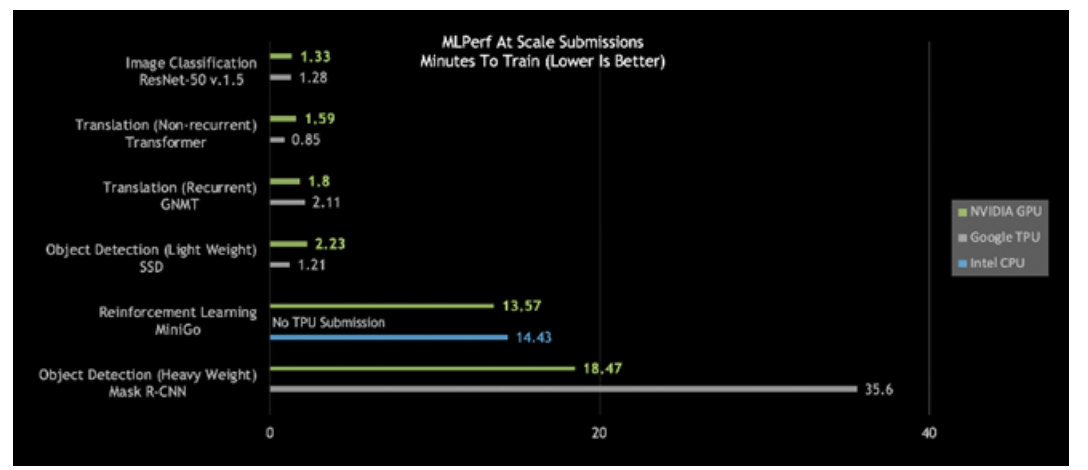
图2:DGX SuperPOD打破大规模AI纪录
大规模MLPerf 0.6性能|大规模MLPerf ID:RN50 v1.5:0.6-30,0.6-6 | Transformer:0.6-28,0.6-6 | GNMT:0.6-26,0.6-5 | SSD:0.6-27,0.6-6 | MiniGo:0.6-11,0.6-7 | Mask R-CNN:0.6-23,0.6-3
更进一步观察会发现,针对重量级目标检测和强化学习,这些最困难的AI问题,NVIDIA AI平台在总体训练时间方面脱颖而出。
使用Mask R-CNN深度神经网络的重量级目标检测可为用户提供高级实例分割。其用途包括将其与多个数据源(摄像头、传感器、激光雷达、超声波等)相结合,以精确识别并定位特定目标。
这类AI工作负载有助于训练自动驾驶汽车,为其提供行人和其他目标的精确位置。另外,在医疗健康领域,它能够帮助医生在医疗扫描中查找并识别肿瘤。其意义的重要性非同小可。
NVIDIA的“重量级目标检测”用时不到19分钟,性能几乎是第二名的两倍。
强化学习是另一有难度的类别。这种AI方法能够用于训练工厂车间机器人,以简化生产。城市也可以用这种方式来控制交通灯,以减少拥堵。NVIDIA采用NVIDIA DGX SuperPOD,在创纪录的13.57分钟内完成了对MiniGo AI强化训练模型的训练。
咖啡还没好,任务已完成:即时AI基础设施提供全球领先性能
打破基准测试纪录不是目的,加速创新才是目标。这就是为什么NVIDIA构建的DGX SuperPOD不仅性能强大,而且易于部署。DGX SuperPOD全面配置了可通过NGC容器注册表免费获取的优化型CUDA-X AI软件,可提供开箱即用的全球领先AI性能。
在这个由130多万名CUDA开发者组成的生态系统中,NVIDIA与开发者们合作,致力于为所有AI框架和开发环境提供有力支持。
我们已经助力优化了数百万行代码,让我们的客户能够将其AI项目落地,无论您身在何处都可以找到NVIDIA GPU,无论是在云端,还是在数据中心,亦或是边缘。
AI基础设施如今有够快,未来会更快
更好的一点在于,这一平台的速度一直在提升。NVIDIA每月都会发布CUDA-X AI软件的新优化和性能改进,集成型软件堆栈可在NGC容器注册表中免费下载,包括容器化的框架、预先训练好的模型和脚本。借助在CUDA-X AI软件堆栈上的创新,NVIDIA DGX-2H服务器的MLPerf 0.6吞吐量比NVIDIA七个月前发布的结果提升了80%。
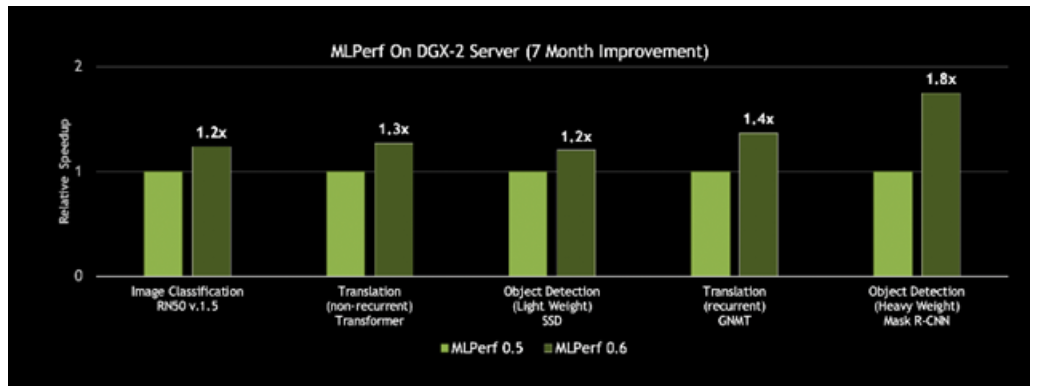
图3:基于同一服务器,性能提升高达80%
对单个历元上单一DGX-2H服务器的吞吐量进行比较(数据集单次通过神经网络)| MLPerf ID 0.5 / 0.6比较:ResNet-50 v1.5: 0.5-20/0.6-30 | Transformer: 0.5-21/0.6-20 | SSD: 0.5-21/0.6-20 | GNMT: 0.5-19/0.6-20 | Mask R-CNN: 0.5-21/0.6-20
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
AI
+关注
关注
91文章
41976浏览量
303077 -
MLPerf基准测试
+关注
关注
0文章
2浏览量
1193 -
模型训练
+关注
关注
0文章
21浏览量
1565
发布评论请先 登录
相关推荐
热点推荐
AI Ceph 分布式存储教程资料大模型学习资料2026
。如何构建高性能、高吞吐、高可扩展的 AI 分布式存储系统,已成为解锁大模型基建能力的核心科技命题。这不仅关乎数据存得下、读得快,更直接决定了 GPU 集群的利用率与模型训练的最终效率。
一、 突破 I/O
发表于 05-01 17:35
[完结15章]Java转 AI高薪领域必备-从0到1打通生产级AI Agent开发
能力进行深度融合,完成从“业务代码实现者”向“AI系统工程架构师”的硬核转型。(搜星 课it。top)
一、 破除语言迷思:以Java生态构建AI基础设施
许多Java开发者的转型误区
发表于 04-30 13:46
NVIDIA重点展示推动AI走向物理世界的关键突破
在今年的全美机器人周 (National Robotics Week),NVIDIA 重点展示了推动 AI 走向物理世界的关键突破,以及正在重塑农业、制造业、能源等多个行业的机器人发展浪潮。
NVIDIA加速计算平台助力从地球到太空的AI应用
NVIDIA 今日宣布,其最新一代加速计算平台正在开启太空创新的新时代,将为轨道数据中心 (ODC)、地理空间信息收集以及自主太空运行提供 AI 算力。
如何突破AI存储墙?深度解析ONFI 6.0高速接口与Chiplet解耦架构
1. 行业核心痛点:AI“存储墙”危机在大模型训练与推理场景中,算力演进速度远超存储带宽,计算与存储之间的性能鸿沟(存储墙)已成为限制系统能效的关键瓶颈。• Scale-up需求:单节点内需要极高
发表于 01-29 17:32
NVIDIA DGX SuperPOD为Rubin平台横向扩展提供蓝图
NVIDIA DGX Rubin 系统整合了 NVIDIA 在计算、网络和软件领域的最新突破,将推理 token 成本降至 NVIDIA Blackwell 平台的十分之一,可加速
RA8P1部署ai模型指南:从训练模型到部署 | 本周六
在嵌入式边缘AI中,如何把“训练好的模型”稳定地“跑在板子上”,决定了项目能否落地。我们带你基于RA8P1平台,跑通从数据准备、模型训练、量

NVIDIA CEO黄仁勋畅谈AI时代最新蓝图
在主题演讲中,NVIDIA 创始人兼首席执行官黄仁勋勾勒出了 AI 时代的最新蓝图。从大规模 GPU 部署和量子技术突破,到
【「AI芯片:科技探索与AGI愿景」阅读体验】+AI芯片到AGI芯片
、分布式群体智能
1)物联网AGI系统
优势:
组成部分:
2)分布式AI训练
7、发展重点:基于强化学习的后训练与推理
8、超越大模型:神经符号计算
三、AGI芯片的
发表于 09-18 15:31
【「AI芯片:科技探索与AGI愿景」阅读体验】+可期之变:从AI硬件到AI湿件
,又分为真菌计算和基于DNA的计算。
图4 基本的真菌计算机结构
在用化学和生物方法实现AI功能的过程中,要经历5个阶段,见图5所示。
图5 以化学和生物方法实现AI功能各阶段
期待
发表于 09-06 19:12
NVIDIA助力枢途科技突破视频提取具身数据技术鸿沟
技术,加速了从互联网视频提取具身智能模型训练数据,实现了从视频三维大世界重建、任务语义信息理解、物体细节及轨迹提取、多模态数据采集、具身智能算法训练
睿海光电以高效交付与广泛兼容助力AI数据中心800G光模块升级
NVIDIA Quantum-2交换机等主流设备。
平滑扩展:与现有400G/100G设备无缝互通,降低数据中心升级成本。
多场景覆盖:从AI训练集群的“大象流”
发表于 08-13 19:01
加速AI未来,睿海光电800G OSFP光模块重构数据中心互联标准
800Gbps,完美适配大模型训练等高带宽场景
广泛兼容 :通过NVIDIA Quantum-2交换机、Spectrum-4以太网设备的严格兼容性测试
稳定可靠 :平均无故障时间(MTBF)突破300万
发表于 08-13 16:38
NVIDIA AI助力科学研究领域持续突破
随着 AI 技术的广泛应用,AI 正在成为科学研究的引擎。NVIDIA 作为重要的技术推手,持续驱动着 AI 系统解锁更多领域的科学突破。
NVIDIA携手微软加速代理式AI发展
代理式 AI 正在重新定义科学探索,推动各行各业的研究突破和创新发展。NVIDIA 和微软正通过深化合作提供先进的技术,从云到 PC 加速代



评论