 Facebook全新开源深度学习框架Pythia,即插即用快速构建AI模型
Facebook全新开源深度学习框架Pythia,即插即用快速构建AI模型

Facebook的人工智能研究部门近期推出Pythia,一个模块化的即插即用框架。目标是使数据科学家能够快速构建、复制和基准人工智能模型,将VQA v2.0数据集模型的性能从65.67%提高到70.22%,已在Github上开源。
Facebook最近在开发者社区抛出了一系列工具。继一月份image processing library Spectrum、去年底的自然语言处理建模框架PyText和11月的人工智能增强学习平台Horizon的开源后,Facebook的人工智能研究部门又推出了Pythia,一个模块化的即插即用框架。
Pythia的目标是使数据科学家能够快速构建、复制和基准人工智能模型,已在Github上开源。
而Pythia(中文一般译作皮媞亚)这个名字的来历也很有意思。古希腊神话中,Pythia是阿波罗神的女祭司,服务于帕纳塞斯山上的德尔斐(Delphi)神庙,以传达阿波罗神的神谕而闻名,被认为能预知未来。
即插即用Pythia:让数据科学家快速构建、复制和基准AI模型
Pythia是什么?
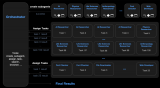
Pythia是一个深度学习框架,支持视觉和语言领域的多任务处理。基于PyTorch 框架,模块化即插即用的设计使研究人员能够快速构建、复制和基准化人工智能模型。
Pythia是为视觉和语言任务而设计的,例如回答与视觉数据相关的问题和自动生成图像注释。
Pythia能做什么?
Pythia加入了最近的人工智能竞赛(2018年VQA挑战赛和2018年Vizwiz挑战赛)中获奖作品的元素。功能包括用参考实现(reference implementations)来显示以前最先进的模型如何实现相关的基准结果,并快速衡量新模型的性能。
除了多任务处理之外,Pythia还支持分布式培训和各种数据集,以及自定义损失、度量、调度(scheduling)和优化器。
Pythia的特性
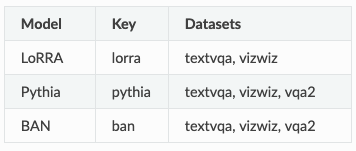
Model Zoo:艺术级的视觉和语言模型的参考实现,包括LoRRA(VQA和TextVQA上的SoTA)、Pythia模型(VQA 2018 挑战赛获胜者)和Ban。
多任务处理:支持多任务处理,允许对多个数据集进行训练。
数据集:包括对各种内置数据集的支持,包括VQA, VizWiz, TextVQA and和VisualDialog。
模块:为视觉和语言领域中的许多常用层提供实现
分布式:支持基于数据并行和分布式数据并行的分布式训练。
Unopinionated:关于基于它的数据集和模型实现是Unopinionated。
定制:定制损失、度量、调度、优化器、Tensorboard;适合用户所有的定制需求。
用户可以使用Pythia为自己下一个视觉和语言多模式研究项目进行引导。Pythia还可以作为围绕视觉和语言数据集的挑战的起始代码库(参见TextVQA挑战赛和VQA挑战赛)。
Pythia最厉害的地方是什么?
Pythia简化了进入视觉和语言发展子领域的过程,使研究人员能够专注于更快的原型制作和实验。Facebook的目标是通过增加这些模型和结果的再现性来加速进展。这将使社区更容易建立成功系统的基础和基准。
开发者还希望通过Pythia消除障碍,能够使研究人员更快地为人们和智能机器开发新的交流方式。这项工作还应该帮助研究人员开发自适应人工智能,将多种理解合成一种更基于上下文的多模式理解。除了这个开源版本,Facebook计划继续添加工具、任务、数据集和引用模型。
在上面提到的VQA 2018比赛中,Pythia v0.1出发点是自下而上、自上而下模型的模块化重新实现,最终力压群雄而胜出。
Pythia v0.1证明,通过对模型体系结构和学习速率计划进行细微但重要的更改、微调图像功能和添加数据扩充,可以显著提高VQA v2.0数据集自上而下模型的性能,从65.67%提高到70.22%。
此外,通过使用不同特征和不同数据集训练的不同模型集合,Pythia v0.1能够显著提高1.31%的“标准”集合方式(即具有不同随机种子的相同模型)。总的来说,Pythia v0.1在VQA v2.0数据集的测试标准分割上达到了72.27%。
术语和概念
Pythia经过精心设计,从一开始就是一个多任务框架。这意味着使用Pythia,可以一起训练多个任务和数据集。
但是,Pythia在其模块中抽象了许多概念,在Pythia之上进行开发,有必要理解Pythia代码库中使用的概念和术语。一旦开发人员理解了这些简单的概念,就很容易在Pythia之上进行开发。其中主要概念和术语如下:
任务和数据集
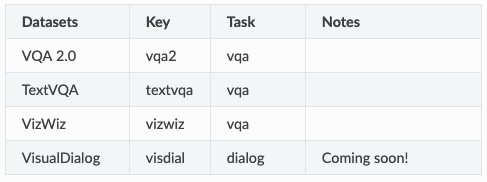
在Pythia中,数据集被划分为一组任务。因此,任务对应属于它的数据集的集合。例如,VQA 2.0,VizWiz和TextVQA都属于VQA任务。 已为每个任务和数据集分配了一个唯一key,用于在命令行参数中引用。
下表显示了任务及其数据集:

下表显示了上表的反转,数据集及其任务和key:
模型
已经包括了最先进模型的参考实施,作为研究论文复制和新研究起点的基础。Pythia曾被用于以下论文:
走向可以阅读的VQA模型(LoRRA模型)
VQA 2018挑战赛冠军
VizWiz 2018挑战赛冠军
与任务和数据集类似,每个模型都使用唯一key进行注册,以便在配置和命令行参数中轻松引用。下表显示了可以运行的每个模型的关键名称和数据集。
注册表
受到Redux全球商店的启发,Pythia生态系统所需的有用信息已在注册表中注册。可以将注册表视为框架的多个部分所需的信息的通用存储,并在需要该信息的任何地方起作用信息源。
注册表还基于如上所述的唯一密钥来注册模型、任务、数据集等。 注册表的函数可以用作需要注册的类的装饰器(例如模型等)
导入注册表对象导入:
from pythia.common.registry import registry
配置
根据研究需要,Pythia中的大多数参数/设置都是可配置的。 Pythia特定的默认值(training_parameters)存在于:
pythia/common/defaults/configs/base.yml
其中详细的注释描述了每个参数的用法。为了便于使用和模块化,每个数据集的配置分别保存在:
pythia/common/defaults/configs/tasks/[task]/[dataset].yml
可以从Tasks中的表中获取数据集的[task]值和数据集部分。模型配置也是分开的,并且是用户在创建自己的模型时需要定义的部分。
由于每个数据集的单独配置,这个概念可以扩展到执行多任务并在此包含多个数据集配置。
处理器的主要目的是使数据处理流程尽可能与不同数据集相似,并允许代码重用。
处理器接受带有与所需数据相对应key的字典,并返回带有处理数据的字典。这有助于通过修复所需的签名来使处理器独立于逻辑的其余部分。
处理器用于所有数据集以切换数据处理需求。在处理器文档中了解有关处理器的更多信息。
SampleList
SampleList受到了maskrcnn-benchmark中BBoxList的启发,但更为通用。与Pythia集成的所有数据集都需要返回一个Sample,该Sample将被整理到SampleList中。
现在,SampleList带有许多方便的功能,可以轻松地批量处理和访问事物。对于例如样本是带有一些key的字典。在SampleList中,这些key的值将根据它是张量还是列表而被巧妙地分组,并分配回该字典。
因此,终端用户可以很好地将这些key组合在一起,并可以在他们的模型中使用它们。与Pythia集成的模型接收SampleList作为参数,这再次使trainer对模型和数据集不再有任何影响。在其文档中了解有关Sample和SampleList的更多信息。
预训练模型
在Pythia中使用预训练模型进行推理很容易。从下表中选取一个预训练模型,并按照步骤进行推理或生成预测让EvalAI评估。(注意,这部分内容需要先安装教程中介绍的数据,教程链接在文末)

现在,假设你到预培训模型model是link(从table中选择>右键单击>复制链接地址),相应的配置应该位于configs/[task]/[dataset]/[model].yml。例如,vqa2 train_and_val的配置文件应该是configs/vqa/vqa2/pythia_train_and_val.yml。现在要运行EvalAI的推断,请运行以下命令:
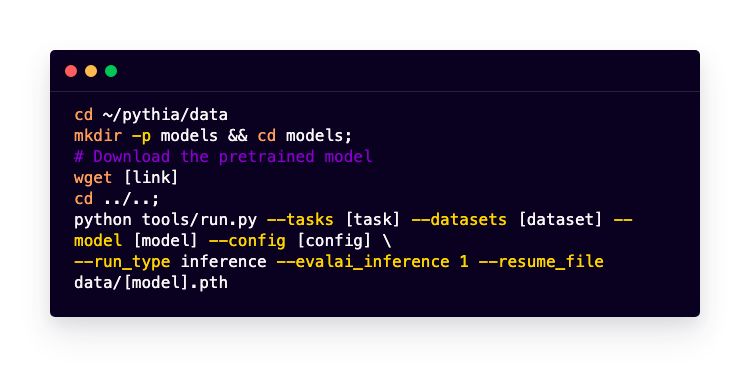
如果要在val上进行培训或评估,请相应地将run_type改为train或val。你还可以使用多个运行类型,例如进行训练、对val进行推断、还可以将--run_type设置为train+val+inference进行推断。
如果删除--evalai_inference论证,Pythia 将执行推断并直接在数据集上提供结果。请注意,对于测试集,这是不能用的,因为我们没有它们的答案/目标。因此,这对于在本地执行 val集的推理很有用。
如果删除--evalai_inference论证,Pythia 将执行推断并直接在数据集上提供结果。请注意,对于测试集,这是不能用的,因为我们没有它们的答案/目标。因此,这对于在本地执行 val集的推理很有用。
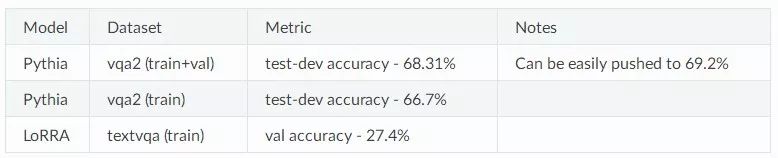
下表显示了各种预培训模型的评估指标:
Demo演示
-
Facebook
+关注
关注
3文章
1432浏览量
59352 -
深度学习
+关注
关注
73文章
5607浏览量
124625 -
pytorch
+关注
关注
2文章
813浏览量
14921
原文标题:Facebook全新开源深度学习框架Pythia,即插即用快速构建AI模型
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
天数智芯Day 0适配MiniMax最新开源M2.7大模型
NVIDIA推出代理式AI蓝图与电信推理模型
华为昇腾深度适配智谱AI全新开源模型GLM-5

月之暗面全新开源旗舰模型Kimi K2.5上线模力方舟
NVIDIA在CES 2026发布全新开放模型、数据和工具
NVIDIA携手Mistral AI发布全新开源大语言模型系列
NVIDIA推出面向语言、机器人和生物学的全新开源AI技术
NVIDIA 利用全新开源模型与仿真库加速机器人研发进程

【「AI芯片:科技探索与AGI愿景」阅读体验】+第二章 实现深度学习AI芯片的创新方法与架构
澎峰科技完成OpenAI最新开源推理模型适配
Arm率先适配腾讯混元开源模型,助力端侧AI创新开发
任正非说 AI已经确定是第四次工业革命 那么如何从容地加入进来呢?
最新人工智能硬件培训AI基础入门学习课程参考2025版(离线AI语音视觉识别篇)
大模型时代的深度学习框架




评论