 大模型时代的深度学习框架
大模型时代的深度学习框架

作者:算力魔方创始人/英特尔创新大使刘力
在CNN时代,AI模型的参数规模都在百万级别,仅需在单张消费类显卡上即可完成训练。例如,以业界知名的CNN模型:ResNet50为例,模型参数量是约为 25.63M,在ImageNet1K数据集上,使用单张消费类显卡RTX-4090只需大约35~40个小时,即可完成ResNet50模型的预训练。在大模型时代,由于大模型参数规模庞大,无法跟CNN时代的小模型一样在单张显卡上完成训练,需要构建多张AI加速卡的集群才能完成AI大模型的预训练。例如:DeepSeek-V3在其技术报告中介绍,DeepSeek-V3的模型参数量为671B,需要278万8千个H800 GPU小时才能完成预训练,换句话说,在有1万张H800的GPU集群上,需要训练278.8个小时。

包含1万张H800的AI数据中心包括:带H800的服务器节点、网络、存储、电源、散热等,一般来说,总建设预算在15亿美金左右。以从AWS上租用1万张H800为例,每小时的租金大约为12.3万美金/小时。以训练DeepSeek-V3为例,
训练效率每提升1%,相当于节约278.8*1%*12.3=34.3万美金,
即240万人民币的租金。所以,在大模型时代,如何充分利用分布式的GPU集群算力,是深度学习框架首先需要考虑的点。
要充分利用分布式的GPU集群算力,就需要充分使用复杂的并行策略,
包括数据并行、张量并行、参数分片并行、流水线并行、序列并行、专家并行等;并且还要提升GPU与GPU,服务器节点与服务器节点间的通讯效率;除此之外,还要考虑AI数据中心不同算力芯片的适配;前沿模型快速发展时,对新型模型的支持等等...若要求AI模型科学家既要
熟知模型结构,还要深入了解芯片特点、硬件架构、并行策略、调度逻辑等等
,这会使得大模型的开发和性能优化的
技术门槛变得非常高
,大大制约了大模型的开发和训练效率。针对上述需求和痛点,
飞桨新一代框架3.0
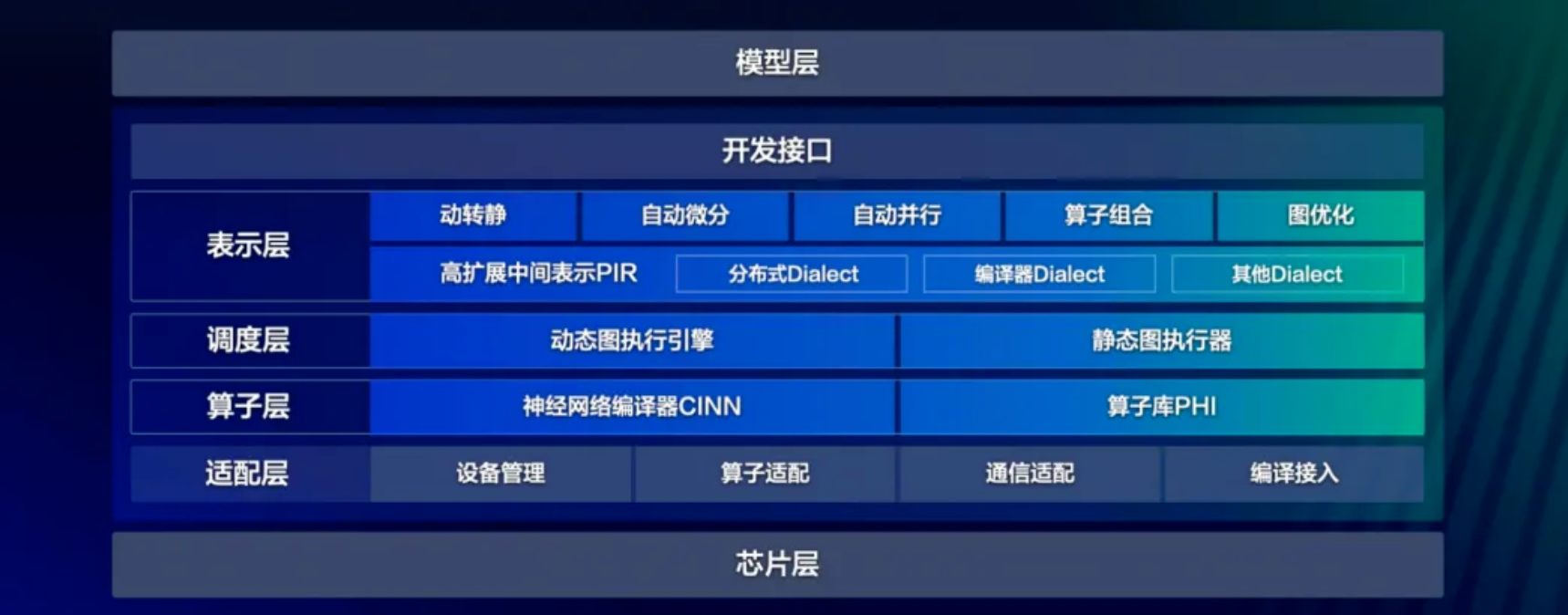
应运而生,该版本提供了丰富的深度学习相关的各种开发接口:
表示层:专注于计算图的表达与转换,通过高可扩展中间表示PIR,实现动转静、自动微分、自动并行、算子组合以及计算图优化等核心功能;
调度层:负责对代码或计算图进行智能编排与高效调度,支持动态图和静态图两种不同的执行模式;
算子层:由神经网络编译器CINN和算子库PHI共同构成,涵盖了张量定义、算子定义、算子自动融合和算子内核实现等关键功能;
适配层:则用于实现与底层芯片适配,包括设备管理、算子适配、通信适配以及编译接入等功能。
飞桨框架3.0凭借强大的功能和优化的设计,
并实现产业应用。以百度文心大模型为例,飞桨框架3.0在训练、推理等方面为文心大模型提供端到端优化,训练方面重点提升训练吞吐、训练有效率和收敛效率,集群训练有效率超过98%;推理部署方面通过注意力机制量化推理、通用投机解码等技术提升推理吞吐和效率;全面支持文心4.5、文心X1等大模型的技术创新和产业应用。
飞桨框架3.0 Github仓:https://github.com/PaddlePaddle/Paddle。
如果你有更好的文章,欢迎投稿!
稿件接收邮箱:nami.liu@pasuntech.com
更多精彩内容请关注“算力魔方®”!
审核编辑 黄宇
-
深度学习
+关注
关注
73文章
5614浏览量
124759 -
大模型
+关注
关注
2文章
3864浏览量
5299 -
DeepSeek
+关注
关注
2文章
861浏览量
3475
发布评论请先 登录
深度学习为什么还是无法处理边缘场景?

人工智能-Python深度学习进阶与应用技术:工程师高培解读

人工智能多模态与视觉大模型开发实战 - 2026必会
机器学习和深度学习中需避免的 7 个常见错误与局限性

【团购】独家全套珍藏!龙哥LabVIEW视觉深度学习实战课(11大系列课程,共5000+分钟)
【团购】独家全套珍藏!龙哥LabVIEW视觉深度学习实战课程(11大系列课程,共5000+分钟)
自动驾驶中Transformer大模型会取代深度学习吗?




评论