 网络爬虫的原理是什么
网络爬虫的原理是什么

网络爬虫原理
网络爬虫指按照一定的规则(模拟人工登录网页的方式),自动抓取网络上的程序。简单的说,就是讲你上网所看到页面上的内容获取下来,并进行存储。网络爬虫的爬行策略分为深度优先和广度优先。如下图是深度优先的一种遍历方式是A到B到D到E到C到F(ABDECF)而宽度优先的遍历方式ABCDEF。
网络爬虫实现原理
1、获取初始URL。初始URL地址可以有用户人为指定,也可以由用户指定的某个或某几个初始爬取网页决定。
2、根据初始的URL爬取页面并获得新的URL。获得初始的URL地址之后,首先需要爬取对应URL地址中的网页,爬取了对应的URL地址中的网页后,将网页存储到原始数据库中,并且在爬取网页的同时,发现新的URL地址,同时将已爬取的URL地址存放到一个URL列表中,用于去重及判断爬取的进程。
3、将新的URL放到URL队列中,在第二步中,获取下一个新的URL地址之后,会将新的URL地址放到URL队列中。
4、从URL队列中读取新的URL,并依据新的URL爬取网页,同时从新的网页中获取新的URL并重复上述的爬取过程。
5、满足爬虫系统设置的停止条件时,停止爬取。在编写爬虫的时候,一般会设置相应的停止条件。如果没有设置停止条件,爬虫会一直爬取下去,一直到无法获取新的URL地址为止,若设置了停止条件,爬虫则会在停止条件满足时停止爬取。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
网络爬虫
+关注
关注
1文章
52浏览量
9107 -
爬虫
+关注
关注
0文章
87浏览量
7944
发布评论请先 登录
相关推荐
热点推荐
网络接口:数字世界的“门铃”,你了解多少?
插上网线,连接Wi-Fi,可曾想过数据是如何在网络世界穿梭的?今天,让我们一起揭开网络接口的神秘面纱!
你是否曾好奇,当我们插上网线或连接Wi-Fi时,数据是如何在网络世界中穿梭的?这一切都离不开
发表于 11-26 18:53
# 深度解析:爬虫技术获取淘宝商品详情并封装为API的全流程应用
需求。本文将深入探讨如何借助爬虫技术实现淘宝商品详情的获取,并将其高效封装为API。 一、爬虫技术核心原理与工具 1.1 爬虫运行机制 网络爬虫
网络通讯的结构及地址
1. 网络地址结构
Socket通过结构体描述网络地址,最常用的是IPv4地址结构sockaddr_in(定义在):
struct sockaddr_in
发表于 11-17 07:59
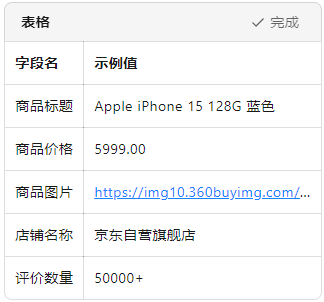
从 0 到 1:用 PHP 爬虫优雅地拿下京东商品详情
PHP 语言 实现一个 可运行的京东商品爬虫 ,不仅能抓取商品标题、价格、图片、评价数,还能应对常见的反爬策略。全文附完整代码, 复制粘贴即可运行 。 一、为什么选择 PHP 做爬虫? 虽然 Python 是爬虫界的“老大哥”
Nginx限流与防爬虫配置方案
在互联网业务快速发展的今天,网站面临着各种流量冲击和恶意爬虫的威胁。作为运维工程师,我们需要在保证正常用户访问的同时,有效防范恶意流量和爬虫攻击。本文将深入探讨基于Nginx的限流与防爬虫解决方案,从原理到实践,为大家提供一套完
稳定、高效、智能:蜂鸟IP如何为技术玩家提供可靠动态IP服务?
在当今数字化时代,网络环境的稳定性和灵活性已成为技术爱好者和专业人士关注的重点。无论是爬虫开发、网络安全测试,还是多地域网络访问需求,一个可靠的动态IP服务能显著提升工作效率,避免因I
如何用Brower Use WebUI实现网页数据智能抓取与分析?
作者:算力魔方创始人/英特尔创新大使刘力 Browser-use是一款能让AI智能体像人类一样操作网页的创新工具,与传统网络爬虫技术相比,Browser-use能模拟人浏览并操作网页,在采集网站
爬虫数据获取实战指南:从入门到高效采集
爬虫数据获取实战指南:从入门到高效采集 在数字化浪潮中,数据已成为驱动商业增长的核心引擎。无论是市场趋势洞察、竞品动态追踪,还是用户行为分析,爬虫技术都能助你快速捕获目标信息。然而,如何既
MPLS网络性能优化技巧
MPLS(多协议标签交换)网络性能优化是一个复杂的过程,涉及多个方面的技术和策略。以下是一些关键的MPLS网络性能优化技巧: 一、确保网络设备支持 设备兼容性 :确保所有网络设备(如路
hyper 网络设置,Hyper-V网络设置:高级网络配置技巧
我们在日常工作和生活中面临的管理任务多种多样,从简单的文件整理到复杂的项目调度。批量管理工具的出现,让我们能够从繁琐的管理工作中解脱出来,更加专注于核心业务的发展。今天就为大家介绍Hyper-V网络
桥接解决网络覆盖问题
随着信息技术的飞速发展,网络覆盖问题成为了制约网络通信质量的关键因素之一。桥接技术作为一种有效的网络连接手段,能够在不同网络之间建立通信桥梁,从而解决
网络协议与网关的关联
在现代通信网络中,数据的传输和接收依赖于一套复杂的规则和标准,这些规则和标准统称为网络协议。网络协议定义了数据如何在网络中传输,以及如何确保数据的完整性和可靠性。网关作为
javascript:void(0) 是否影响SEO优化
使用 javascript:void(0) 确实可能对SEO优化产生负面影响 。以下是关于 javascript:void(0) 对SEO影响的具体分析: 搜索引擎爬虫的理解问题 搜索引擎爬虫(如
IP地址数据信息和爬虫拦截的关联
IP地址数据信息和爬虫拦截的关联主要涉及到两方面的内容,也就是数据信息和爬虫。IP 地址数据信息的内容丰富,包括所属地域、所属网络运营商、访问时间序列、访问频率等。 从IP地址信息中可以窥见
mtu与网络性能的关系 mtu调整对网络的影响
在现代网络通信中,数据包的传输效率和可靠性是衡量网络性能的关键指标。MTU(最大传输单元)作为网络通信中的基本参数,对这些性能指标有着直接的影响。 MTU的定义与作用 MTU是指在不进行分片的情况下





 工商网监
工商网监
评论