 crawlerdetect:Python 三行代码检测爬虫
crawlerdetect:Python 三行代码检测爬虫

是否担心高频率爬虫导致网站瘫痪?
别担心,现在有一个Python写的神器——crawlerdetect,帮助你检测爬虫,保障网站的正常运转。
1.准备
开始之前,你要确保Python和pip已经成功安装在电脑上噢,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。如果你用Python的目的是数据分析,可以直接安装Anaconda:Python数据分析与挖掘好帮手—Anaconda
Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal),准备开始输入命令安装依赖。
当然,我更推荐大家用VSCode编辑器,把本文代码Copy下来,在编辑器下方的终端运行命令安装依赖模块,多舒服的一件事啊:Python 编程的最好搭档—VSCode 详细指南。
在终端输入以下命令安装我们所需要的依赖模块:
pip install crawlerdetect
看到 Successfully installed xxx 则说明安装成功。
2.使用方法
它可以通过user-agent、headers等请求头识别爬虫或机器人。
因此,你可以传递两种参数。第一种,使用user-agent检测机器人:
from crawlerdetect import CrawlerDetect
crawler_detect = CrawlerDetect(user_agent='Mozilla/5.0 (iPhone; CPU iPhone OS 7_1 like Mac OS X) AppleWebKit (KHTML, like Gecko) Mobile (compatible; Yahoo Ad monitoring; https://help.yahoo.com/kb/yahoo-ad-monitoring-SLN24857.html)')
crawler_detect.isCrawler()
# 如果是机器人,这条语句返回True
第二种识别方式会用上全部headers参数,这种方式比单纯用user-agent精准,因为它判断的依据更加全面。
from crawlerdetect import CrawlerDetect
crawler_detect = CrawlerDetect(headers={'DOCUMENT_ROOT': '/home/test/public_html', 'GATEWAY_INTERFACE': 'CGI/1.1', 'HTTP_ACCEPT': '*/*', 'HTTP_ACCEPT_ENCODING': 'gzip, deflate', 'HTTP_CACHE_CONTROL': 'no-cache', 'HTTP_CONNECTION': 'Keep-Alive', 'HTTP_FROM': 'googlebot(at)googlebot.com', 'HTTP_HOST': 'www.test.com', 'HTTP_PRAGMA': 'no-cache', 'HTTP_USER_AGENT': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1500.71 Safari/537.36', 'PATH': '/bin:/usr/bin', 'QUERY_STRING': 'order=closingDate', 'REDIRECT_STATUS': '200', 'REMOTE_ADDR': '127.0.0.1', 'REMOTE_PORT': '3360', 'REQUEST_METHOD': 'GET', 'REQUEST_URI': '/?test=testing', 'SCRIPT_FILENAME': '/home/test/public_html/index.php', 'SCRIPT_NAME': '/index.php', 'SERVER_ADDR': '127.0.0.1', 'SERVER_ADMIN': 'webmaster@test.com', 'SERVER_NAME': 'www.test.com', 'SERVER_PORT': '80', 'SERVER_PROTOCOL': 'HTTP/1.1', 'SERVER_SIGNATURE': '', 'SERVER_SOFTWARE': 'Apache', 'UNIQUE_ID': 'Vx6MENRxerBUSDEQgFLAAAAAS', 'PHP_SELF': '/index.php', 'REQUEST_TIME_FLOAT': 1461619728.0705, 'REQUEST_TIME': 1461619728})
crawler_detect.isCrawler()
# 如果是机器人,这条语句返回True
你还可以识别相应爬虫的名字(如果有的话),通过这种方式,你能给一些著名的爬虫(如baiduspider、googlebot)添加白名单,不进行拦截。
from crawlerdetect import CrawlerDetect
crawler_detect = CrawlerDetect()
crawler_detect.isCrawler('Mozilla/5.0 (compatible; Sosospider/2.0; +http://help.soso.com/webspider.htm)')
# 如果是机器人,这条语句返回True
crawler_detect.getMatches()
# Sosospider
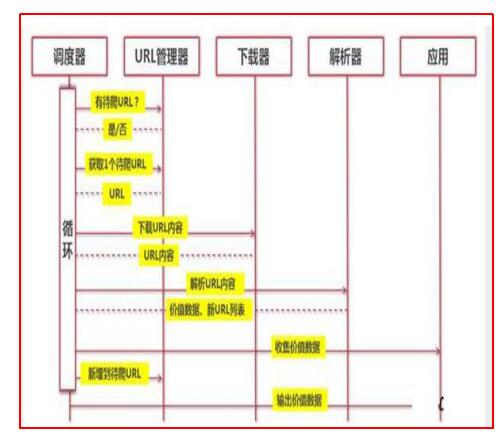
有了这个工具,我们就可以实现实时的爬虫封禁:
**1. **实时监控网站上的http请求,检测其对应的headers.
**2. **如果识别到该请求是机器人(爬虫)发出的,就可将其IP记录下来。
**3. ** 将IP加入到Nginx或Apache的动态黑名单中,实现实时的爬虫封禁。
这一套流程我还没有试验过,大家有兴趣可以试试,理论上可行。
-
代码
+关注
关注
30文章
4983浏览量
74534 -
编辑器
+关注
关注
1文章
833浏览量
33133 -
python
+关注
关注
59文章
4892浏览量
90419 -
爬虫
+关注
关注
0文章
87浏览量
8203
发布评论请先 登录
Python数据爬虫学习内容
请问前三行是什么意思?
请问这三行代码是固定这样写的吗?
三行搞定独立按键
Python爬虫简介与软件配置
什么是三行按键?有什么用

python爬虫入门教程之python爬虫视频教程分布式爬虫打造搜索引擎
python为什么叫爬虫
如何实现计算机视觉的目标检测10行Python代码帮你实现
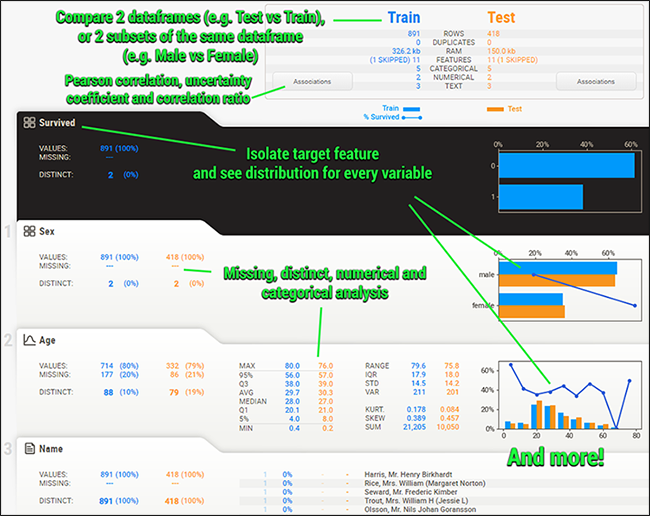
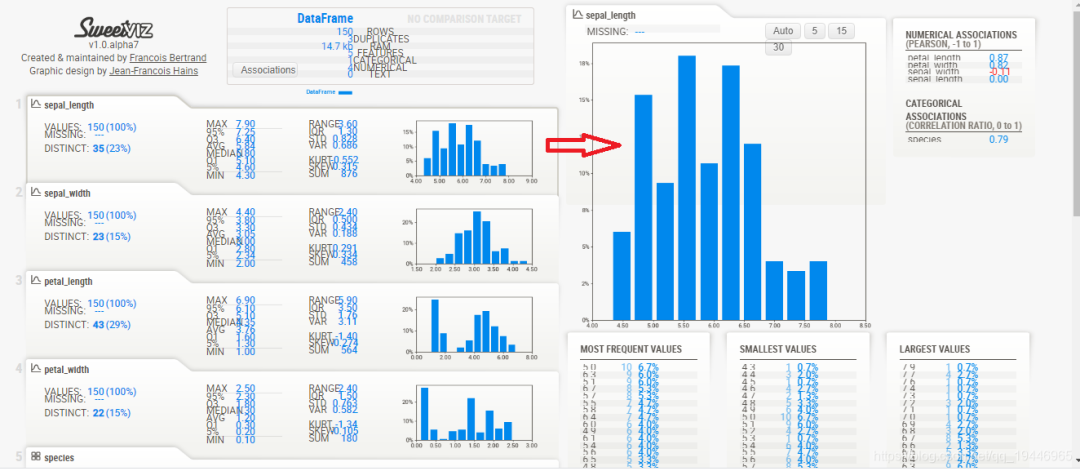
Sweetviz让你三行代码实现探索性数据分析
来看看他们用代码写的“三行诗”

Sweetviz: 让你三行代码实现探索性数据分析



评论