 如何解决Python爬虫中文乱码问题?Python爬虫中文乱码的解决方法
如何解决Python爬虫中文乱码问题?Python爬虫中文乱码的解决方法

如何解决Python爬虫中文乱码问题?Python爬虫中文乱码的解决方法
在Python爬虫过程中,遇到中文乱码问题是常见的情况。乱码问题主要是由于编码不一致所导致的,下面我将详细介绍如何解决Python爬虫中文乱码问题。
一、了解字符编码
在解决乱码问题之前,我们首先需要了解一些基本的字符编码知识。常见的字符编码有ASCII、UTF-8和GBK等。
1. ASCII:是一种用于表示英文字母、数字和常用符号的字符编码,它使用一个字节(8位)来表示一个字符。
2. UTF-8:是一种可变长度的字符编码,它使用1至4个字节来表示一个字符,并支持全球范围内的所有字符。
3. GBK:是一种针对汉字的字符编码标准,它采用双字节来表示一个汉字。
二、网页编码判断
在爬取网页内容时,我们需要确定网页使用的字符编码,以便正确解析其中的中文内容。
1. 查看HTTP响应头部信息
爬虫通常使用HTTP协议请求网页内容,网页的字符编码信息一般会在响应头部的Content-Type字段中指定。我们可以通过检查响应头部的Content-Type字段来获取网页的字符编码。
示例代码如下:
```python
import requests
url = "http://www.example.com"
response = requests.get(url)
content_type = response.headers['Content-Type']
print(content_type)
```
2. 使用chardet库自动检测编码
有些网页的响应头部并没有明确指定字符编码,这时我们可以使用chardet库来自动检测网页的编码方式。
示例代码如下:
```python
import requests
import chardet
url = "http://www.example.com"
response = requests.get(url)
encoding = chardet.detect(response.content)['encoding']
print(encoding)
```
3. 多种方式组合判断
有些网站采用了一些特殊的方式来指定字符编码,但是chardet库无法检测到。这时我们可以根据网页内容的一些特征进行判断,然后再使用chardet库进行编码检测。
示例代码如下:
```python
import requests
import chardet
url = "http://www.example.com"
response = requests.get(url)
content = response.content
# 根据网页内容特征判断编码方式
if "charset=gb2312" in content.lower() or "charset=gbk" in content.lower():
encoding = 'gbk'
elif "charset=utf-8" in content.lower():
encoding = 'utf-8'
else:
encoding = chardet.detect(content)['encoding']
print(encoding)
```
三、解码网页内容
当我们获得网页的正确编码后,就需要将网页内容进行解码,以得到正确的中文字符。
1. 使用requests库自动解码
requests库在获取网页内容时,会根据响应头部的Content-Type字段自动解码网页内容。
示例代码如下:
```python
import requests
url = "http://www.example.com"
response = requests.get(url)
content = response.text
print(content)
```
2. 使用指定编码进行手动解码
如果requests库无法正确解码网页内容,我们可以手动指定网页内容的编码方式进行解码。
示例代码如下:
```python
import requests
import chardet
url = "http://www.example.com"
response = requests.get(url)
encoding = 'utf-8' # 假设网页内容使用utf-8编码
content = response.content.decode(encoding)
print(content)
```
四、编码问题修复
在将爬取到的中文内容存储或处理时,仍然可能会遇到编码问题。下面介绍解决编码问题的几种常见方法。
1. 使用正确的编码方式进行存储
当将爬取到的中文内容存储到数据库或文件中时,需要确保使用正确的编码方式进行存储。通常情况下,使用UTF-8编码是一个可以接受的选择。
示例代码如下:
```python
import requests
import chardet
url = "http://www.example.com"
response = requests.get(url)
encoding = 'utf-8' # 假设网页内容使用utf-8编码
content = response.content.decode(encoding)
# 将内容存储到文件
with open("output.txt", "w", encoding='utf-8') as file:
file.write(content)
```
2. 使用encode()方法进行编码转换
当需要将爬取到的中文内容传递给其他模块或函数时,可能需要进行编码转换。可以使用字符串的encode()方法将其转换为字节类型,然后再进行传递。
示例代码如下:
```python
import requests
import chardet
url = "http://www.example.com"
response = requests.get(url)
encoding = 'utf-8' # 假设网页内容使用utf-8编码
content = response.content.decode(encoding)
# 将内容传递给其他模块或函数
content_bytes = content.encode(encoding)
other_module.process(content_bytes)
```
3. 使用第三方库进行编码修复
如果以上方法都无法解决编码问题,可以考虑使用第三方库来修复编码问题。例如,可以使用ftfy(fixes text for you)库来修复文本中的乱码问题。
示例代码如下:
```python
import requests
import chardet
import ftfy
url = "http://www.example.com"
response = requests.get(url)
encoding = 'utf-8' # 假设网页内容使用utf-8编码
content = response.content.decode(encoding)
# 使用ftfy库修复编码问题
fixed_content = ftfy.fix_text(content)
print(fixed_content)
```
综上所述,解决Python爬虫中文乱码问题的方法包括:了解字符编码、网页编码判断、解码网页内容以及编码问题修复等。在实际爬虫过程中,我们根据具体情况选择最合适的方法来解决乱码问题,以确保爬取到的中文内容正常显示和处理。
-
python
+关注
关注
58文章
4885浏览量
90307 -
HTTP协议
+关注
关注
0文章
68浏览量
10704
发布评论请先 登录
Python全栈一课通(470集)(12.96 GB)-网盘资源下载
使用PYTHON进行的跨平台仿真
[VirtualLab] 使用Python运行VirtualLab Fusion光学仿真
11.0592MHz晶振换成12MHz后单片机串口通讯乱码的原因分析

浅谈京东关键词
京东关键词搜索商品列表的Python爬虫实战
# 深度解析:爬虫技术获取淘宝商品详情并封装为API的全流程应用
用 Python 给 Amazon 做“全身 CT”——可量产、可扩展的商品详情爬虫实战
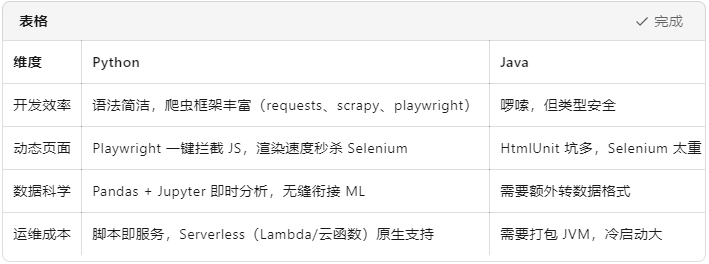
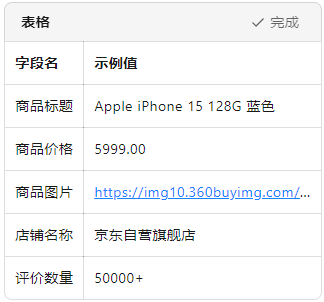
从 0 到 1:用 PHP 爬虫优雅地拿下京东商品详情



评论