 什么情况下需要布隆过滤器
什么情况下需要布隆过滤器

什么情况下需要布隆过滤器?
先来看几个比较常见的例子
字处理软件中,需要检查一个英语单词是否拼写正确
在 FBI,一个嫌疑人的名字是否已经在嫌疑名单上
在网络爬虫里,一个网址是否被访问过
yahoo, gmail等邮箱垃圾邮件过滤功能
这几个例子有一个共同的特点:如何判断一个元素是否存在一个集合中?
常规思路
数组
链表
树、平衡二叉树、Trie
Map (红黑树)
哈希表
虽然上面描述的这几种数据结构配合常见的排序、二分搜索可以快速高效的处理绝大部分判断元素是否存在集合中的需求。但是当集合里面的元素数量足够大,如果有500万条记录甚至1亿条记录呢?这个时候常规的数据结构的问题就凸显出来了。数组、链表、树等数据结构会存储元素的内容,一旦数据量过大,消耗的内存也会呈现线性增长,最终达到瓶颈。有的同学可能会问,哈希表不是效率很高吗?查询效率可以达到O(1)。但是哈希表需要消耗的内存依然很高。使用哈希表存储一亿 个垃圾 email 地址的消耗?哈希表的做法:首先,哈希函数将一个email地址映射成8字节信息指纹;考虑到哈希表存储效率通常小于50%(哈希冲突);因此消耗的内存:8 * 2 * 1亿 字节 = 1.6G 内存,普通计算机是无法提供如此大的内存。这个时候,布隆过滤器(Bloom Filter)就应运而生。在继续介绍布隆过滤器的原理时,先讲解下关于哈希函数的预备知识。
哈希函数
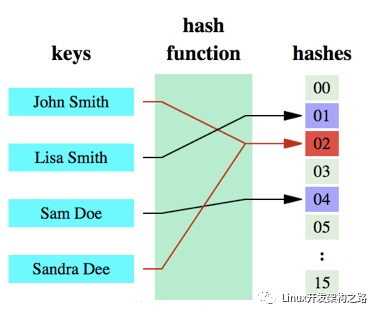
哈希函数的概念是:将任意大小的数据转换成特定大小的数据的函数,转换后的数据称为哈希值或哈希编码。下面是一幅示意图:
什么是布隆过滤器?本质上布隆过滤器( BloomFilter )是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
相比于传统的 Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
布隆过滤器原理
布隆过滤器内部维护一个bitArray(位数组), 开始所有数据全部置 0 。当一个元素过来时,能过多个哈希函数(hash1,hash2,hash3…)计算不同的在哈希值,并通过哈希值找到对应的bitArray下标处,将里面的值 0 置为 1 。需要说明的是,布隆过滤器有一个误判率的概念,误判率越低,则数组越长,所占空间越大。误判率越高则数组越小,所占的空间越小。
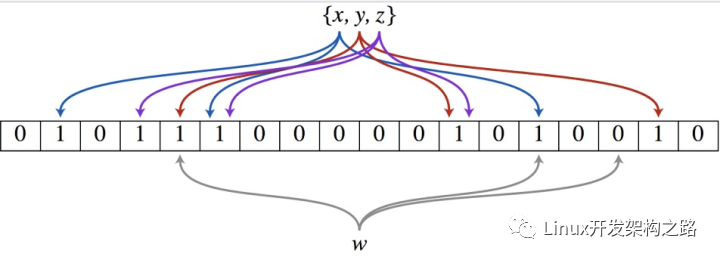
以上图为例,具体的操作流程:假设集合里面有3个元素{x, y, z},哈希函数的个数为3。首先将位数组进行初始化,将里面每个位都设置位0。对于集合里面的每一个元素,将元素依次通过3个哈希函数进行映射,每次映射都会产生一个哈希值,这个值对应位数组上面的一个点,然后将位数组对应的位置标记为1。查询W元素是否存在集合中的时候,同样的方法将W通过哈希映射到位数组上的3个点。如果3个点的其中有一个点不为1,则可以判断该元素一定不存在集合中。反之,如果3个点都为1,则该元素可能存在集合中。注意:此处不能判断该元素是否一定存在集合中,可能存在一定的误判率。可以从图中可以看到:假设某个元素通过映射对应下标为4,5,6这3个点。虽然这3个点都为1,但是很明显这3个点是不同元素经过哈希得到的位置,因此这种情况说明元素虽然不在集合中,也可能对应的都是1,这是误判率存在的原因。## 为什么不直接使用hashtable
Hash table的存储效率一般只有50%,为了避免碰撞的问题,一般哈希存储到一半的时候都采取内存翻倍或者其他措施,所以很耗费内存。
Hash面临的问题就是冲突。假设 Hash 函数是良好的,如果我们的位阵列长度为 m个点,那么如果我们想将冲突率降低到例如 1%, 这个散列表就只能容纳 m/100 个元素。解决方法较简单, 使用k>1的布隆过滤器,即k个函数将每个元素改为对应于k个bits,因为误判度会降低很多,并且如果参数k和m选取得好,一半的m可被置为1。
布隆过滤器的设计一般会由用户决定增加元素的个数n和误差率p,后面的所有参数都由系统来设计。
1.首先根据传入的n和p计算需要的内存大小m bits:

2.再由m,n得到hash function个数k:

布隆过滤器添加元素
将要添加的元素给k个哈希函数
得到对应于位数组上的k个位置
将这k个位置设为1
布隆过滤器查询元素
将要查询的元素给k个哈希函数
得到对应于位数组上的k个位置
如果k个位置有一个为0,则肯定不在集合中
如果k个位置全部为1,则可能在集合中
下图是Bloomfilter误判率表:

为每个URL分配两个字节就可以达到千分之几的冲突。比较保守的实现是,为每个URL分配4个字节,项目和位数比是1∶32,误判率是0.00000021167340。对于5000万数量级的URL,布隆过滤器只占用200MB的空间。
c++代码:
定义布隆滤波器的结构体
uint8_t cInitFlag; //初始化标志
uint8_t cResv[3];
uint32_t dwMaxItems; //n - BloomFilter中最大元素个数 (输入量)
double dProbFalse; //p - 假阳概率(误判率) (输入量,比如万分之一:0.00001)
uint32_t dwFilterBits; //m = ceil((n * log(p)) / log(1.0 / (pow(2.0, log(2.0))))); - BloomFilter的比特数
uint32_t dwHashFuncs; // k = round(log(2.0) * m / n); - 哈希函数个数
uint32_t dwSeed; // MurmurHash的种子偏移量
uint32_t dwCount; // Add()的计数,超过MAX_BLOOMFILTER_N则返回失败
uint32_t dwFilterSize; // dwFilterBits / BYTE_BITS
unsigned char *pstFilter; // BloomFilter存储指针,使用malloc分配
uint32_t *pdwHashPos; // 存储上次hash得到的K个bit位置数组(由bloom_hash填充)
}BaseBloomFilter;
定义写入文件的结构体
uint32_t dwMagicCode; // 文件头部标识,填充 __MGAIC_CODE__
uint32_t dwSeed;
uint32_t dwCount;
uint32_t dwMaxItems; // n - BloomFilter中最大元素个数 (输入量)
double dProbFalse; // p - 假阳概率 (输入量,比如万分之一:0.00001)
uint32_t dwFilterBits; // m = ceil((n * log(p)) / log(1.0 / (pow(2.0, log(2.0))))); - BloomFilter的比特数
uint32_t dwHashFuncs; // k = round(log(2.0) * m / n); - 哈希函数个数
uint32_t dwResv[6];
uint32_t dwFileCrc; // (未使用)整个文件的校验和
uint32_t dwFilterSize; // 后面Filter的Buffer长度
}BloomFileHead;
根据传入的元素个数n和误差率p, 计算布隆滤波器的内存大小m bits和hash function个数k:
/**
* n - Number of items in the filter
* p - Probability of false positives, float between 0 and 1 or a number indicating 1-in-p
* m - Number of bits in the filter
* k - Number of hash functions
*
* f = ln(2) × ln(1/2) × m / n = (0.6185) ^ (m/n)
* m = -1*n*ln(p)/((ln(2))^2) = -1*n*ln(p)/(ln(2)*ln(2)) = -1*n*ln(p)/(0.69314718055995*0.69314718055995))
* = -1*n*ln(p)/0.4804530139182079271955440025
* k = ln(2)*m/n
**/
uint32_t m, k, m2;
m =(uint32_t) ceil(-1.0 * n * log(p) / 0.480453);
m = (m - m % 64) + 64; // 8字节对齐
double double_k = (0.69314 *m /n);
k = round(double_k);
*pm = m;
*pk = k;
return;
}
初始化bloomfilter, 根据size分配内存:
* @brief 初始化布隆过滤器
* @param pstBloomfilter 布隆过滤器实例
* @param dwSeed hash种子
* @param dwMaxItems 存储容量
* @param dProbFalse 允许的误判率
* @return 返回值
* -1 传入的布隆过滤器为空
* -2 hash种子错误或误差>=1
*/
inline int InitBloomFilter(BaseBloomFilter *pstBloomfilter, uint32_t dwSeed, uint32_t dwMaxItems, double dProbFalse){
if(pstBloomfilter == NULL)
return -1;
if(dProbFalse <=0 || dProbFalse >= 1)
return -2;
//检查是否重复Init, 释放内存
if(pstBloomfilter->pstFilter != NULL)
free(pstBloomfilter->pstFilter);
if(pstBloomfilter->pdwHashPos != NULL)
free(pstBloomfilter->pdwHashPos);
memset(pstBloomfilter, 0, sizeof(pstBloomfilter));
//初始化内存结构,并计算BloomFilter需要的空间
pstBloomfilter->dwMaxItems = dwMaxItems;
pstBloomfilter->dProbFalse = dProbFalse;
pstBloomfilter->dwSeed = dwSeed;
//计算 m, k
_CalcBloomFilterParam(pstBloomfilter->dwMaxItems, pstBloomfilter->dProbFalse,
&pstBloomfilter->dwFilterBits, &pstBloomfilter->dwHashFuncs);
//分配BloomFilter的存储空间
pstBloomfilter->dwFilterSize = pstBloomfilter->dwFilterBits / BYTE_BITS;
pstBloomfilter->pstFilter = (unsigned char *)malloc(pstBloomfilter->dwFilterSize);
if(NULL == pstBloomfilter->pstFilter)
return -100;
//哈希结果数组,每个哈希函数一个
pstBloomfilter->pdwHashPos = (uint32_t*)malloc(pstBloomfilter->dwHashFuncs * sizeof(uint32_t));
if(NULL == pstBloomfilter->pdwHashPos)
return -200;
printf("Init BloomFilter(n=%u, p=%e, m=%u, k=%d), malloc() size=%.6fMB, items:bits=1:%0.1lfn",
pstBloomfilter->dwMaxItems, pstBloomfilter->dProbFalse, pstBloomfilter->dwFilterBits,
pstBloomfilter->dwHashFuncs, (double)pstBloomfilter->dwFilterSize/1024/1024,
pstBloomfilter->dwFilterBits*1.0/pstBloomfilter->dwMaxItems);
// 初始化BloomFilter的内存
memset(pstBloomfilter->pstFilter, 0, pstBloomfilter->dwFilterSize);
pstBloomfilter->cInitFlag = 1;
return 0;
}
释放内存:
inline int FreeBloomFilter(BaseBloomFilter * pstBloomfilter){
if(pstBloomfilter == NULL)
return -1;
pstBloomfilter->cInitFlag = 0;
pstBloomfilter->dwCount=0;
free(pstBloomfilter->pstFilter);
pstBloomfilter->pstFilter = NULL;
free(pstBloomfilter->pdwHashPos);
pstBloomfilter->pdwHashPos = NULL;
return 0;
}
ResetBloom filter:
inline int RealResetBloomFilter(BaseBloomFilter *pstBloomfilter){
if (pstBloomfilter == NULL)
return -1;
memset(pstBloomfilter->pstFilter, 0, pstBloomfilter->dwFilterSize);
pstBloomfilter->cInitFlag = 1;
pstBloomfilter->dwCount = 0;
return 0;
}
计算hash函数,这里使用的是MurmurHash2:
{
const uint64_t m = 0xc6a4a7935bd1e995;
const int r = 47;
uint64_t h = seed ^ (len * m);
const uint64_t * data = (const uint64_t *)key;
const uint64_t * end = data + (len/8);
while(data != end)
{
uint64_t k = *data++;
k *= m;
k ^= k >> r;
k *= m;
h ^= k;
h *= m;
}
const uint8_t * data2 = (const uint8_t*)data;
switch(len & 7)
{
case 7: h ^= ((uint64_t)data2[6]) << 48;
case 6: h ^= ((uint64_t)data2[5]) << 40;
case 5: h ^= ((uint64_t)data2[4]) << 32;
case 4: h ^= ((uint64_t)data2[3]) << 24;
case 3: h ^= ((uint64_t)data2[2]) << 16;
case 2: h ^= ((uint64_t)data2[1]) << 8;
case 1: h ^= ((uint64_t)data2[0]);
h *= m;
};
h ^= h >> r;
h *= m;
h ^= h >> r;
return h;
}
计算多少个hash函数:
FORCE_INLINE void bloom_hash(BaseBloomFilter *pstBloomfilter, const void * key, int len){
int i;
uint32_t dwFilterBits = pstBloomfilter->dwFilterBits;
uint64_t hash1 = MurmurHash2_x64(key, len, pstBloomfilter->dwSeed);
uint64_t hash2 = MurmurHash2_x64(key, len, MIX_UINT64(hash1));
for (i = 0; i < (int)pstBloomfilter->dwHashFuncs; i++)
{
pstBloomfilter->pdwHashPos[i] = (hash1 + i*hash2) % dwFilterBits;
}
return;
}
向Bloomfilter新增元素:
// 成功返回0,当添加数据超过限制值时返回1提示用户
FORCE_INLINE int BloomFilter_Add(BaseBloomFilter *pstBloomfilter, const void * key, int len){
if((pstBloomfilter == NULL) || (key == NULL) || (len<=0))
return -1;
int i;
if(pstBloomfilter->cInitFlag != 1){
memset(pstBloomfilter->pstFilter,0 , pstBloomfilter->dwFilterSize);
pstBloomfilter->cInitFlag =1;
}
bloom_hash(pstBloomfilter, key, len);
for(i=0;i<(int)pstBloomfilter->dwHashFuncs; ++i){
SETBIT(pstBloomfilter, pstBloomfilter->pdwHashPos[i]);
}
pstBloomfilter->dwCount++;
if(pstBloomfilter->dwCount <= pstBloomfilter->dwMaxItems)
return 0;
else
return 1;
}
查询元素:
if((pstBloomfilter == NULL) || (key == NULL) || (len<=0))
return -1;
int i;
bloom_hash(pstBloomfilter, key, len);
for (i = 0; i < (int)pstBloomfilter->dwHashFuncs; i++)
{
// 如果有任意bit不为1,说明key不在bloomfilter中
// 注意: GETBIT()返回不是0|1,高位可能出现128之类的情况
if (GETBIT(pstBloomfilter, pstBloomfilter->pdwHashPos[i]) == 0)
return 1;
}
return 0;
}
把bloomfilter保存在文件里:
if ((pstBloomfilter == NULL) || (szFileName == NULL))
return -1;
int iRet;
FILE *pFile;
static BloomFileHead stFileHeader = {0};
pFile = fopen(szFileName, "wb");
if (pFile == NULL)
{
perror("fopen");
return -11;
}
// 先写入文件头
stFileHeader.dwMagicCode = __MGAIC_CODE__;
stFileHeader.dwSeed = pstBloomfilter->dwSeed;
stFileHeader.dwCount = pstBloomfilter->dwCount;
stFileHeader.dwMaxItems = pstBloomfilter->dwMaxItems;
stFileHeader.dProbFalse = pstBloomfilter->dProbFalse;
stFileHeader.dwFilterBits = pstBloomfilter->dwFilterBits;
stFileHeader.dwHashFuncs = pstBloomfilter->dwHashFuncs;
stFileHeader.dwFilterSize = pstBloomfilter->dwFilterSize;
iRet = fwrite((const void*)&stFileHeader, sizeof(stFileHeader), 1, pFile);
if (iRet != 1)
{
perror("fwrite(head)");
return -21;
}
// 接着写入BloomFilter的内容
iRet = fwrite(pstBloomfilter->pstFilter, 1, pstBloomfilter->dwFilterSize, pFile);
if ((uint32_t)iRet != pstBloomfilter->dwFilterSize)
{
perror("fwrite(data)");
return -31;
}
fclose(pFile);
return 0;
}
读取文件的bloomfilter:
inline int LoadBloomFilterFromFile(BaseBloomFilter *pstBloomfilter, char *szFileName)
{
if ((pstBloomfilter == NULL) || (szFileName == NULL))
return -1;
int iRet;
FILE *pFile;
static BloomFileHead stFileHeader = {0};
if (pstBloomfilter->pstFilter != NULL)
free(pstBloomfilter->pstFilter);
if (pstBloomfilter->pdwHashPos != NULL)
free(pstBloomfilter->pdwHashPos);
//
pFile = fopen(szFileName, "rb");
if (pFile == NULL)
{
perror("fopen");
return -11;
}
// 读取并检查文件头
iRet = fread((void*)&stFileHeader, sizeof(stFileHeader), 1, pFile);
if (iRet != 1)
{
perror("fread(head)");
return -21;
}
if ((stFileHeader.dwMagicCode != __MGAIC_CODE__)
|| (stFileHeader.dwFilterBits != stFileHeader.dwFilterSize*BYTE_BITS))
return -50;
// 初始化传入的 BaseBloomFilter 结构
pstBloomfilter->dwMaxItems = stFileHeader.dwMaxItems;
pstBloomfilter->dProbFalse = stFileHeader.dProbFalse;
pstBloomfilter->dwFilterBits = stFileHeader.dwFilterBits;
pstBloomfilter->dwHashFuncs = stFileHeader.dwHashFuncs;
pstBloomfilter->dwSeed = stFileHeader.dwSeed;
pstBloomfilter->dwCount = stFileHeader.dwCount;
pstBloomfilter->dwFilterSize = stFileHeader.dwFilterSize;
pstBloomfilter->pstFilter = (unsigned char *) malloc(pstBloomfilter->dwFilterSize);
if (NULL == pstBloomfilter->pstFilter)
return -100;
pstBloomfilter->pdwHashPos = (uint32_t*) malloc(pstBloomfilter->dwHashFuncs * sizeof(uint32_t));
if (NULL == pstBloomfilter->pdwHashPos)
return -200;
// 将后面的Data部分读入 pstFilter
iRet = fread((void*)(pstBloomfilter->pstFilter), 1, pstBloomfilter->dwFilterSize, pFile);
if ((uint32_t)iRet != pstBloomfilter->dwFilterSize)
{
perror("fread(data)");
return -31;
}
pstBloomfilter->cInitFlag = 1;
printf("Load BloomFilter(n=%u, p=%f, m=%u, k=%d), malloc() size=%.2fMBn",
pstBloomfilter->dwMaxItems, pstBloomfilter->dProbFalse, pstBloomfilter->dwFilterBits,
pstBloomfilter->dwHashFuncs, (double)pstBloomfilter->dwFilterSize/1024/1024);
fclose(pFile);
return 0;
}
完整的代码:
#include
#include
#include
#include
#include
#define MAX_ITEMS 6000000 // 设置最大元素个数
#define ADD_ITEMS 10000 // 添加测试元素
#define P_ERROR 0.0001// 设置误差
#define __BLOOMFILTER_VERSION__ "1.1"
#define __MGAIC_CODE__ (0x01464C42)
/**
* BloomFilter使用例子:
* static BaseBloomFilter stBloomFilter = {0};
*
* 初始化BloomFilter(最大100000元素,不超过0.00001的错误率):
* InitBloomFilter(&stBloomFilter, 0, 100000, 0.00001);
* 重置BloomFilter:
* ResetBloomFilter(&stBloomFilter);
* 释放BloomFilter:
* FreeBloomFilter(&stBloomFilter);
*
* 向BloomFilter中新增一个数值(0-正常,1-加入数值过多):
* uint32_t dwValue;
* iRet = BloomFilter_Add(&stBloomFilter, &dwValue, sizeof(uint32_t));
* 检查数值是否在BloomFilter内(0-存在,1-不存在):
* iRet = BloomFilter_Check(&stBloomFilter, &dwValue, sizeof(uint32_t));
*
* (1.1新增) 将生成好的BloomFilter写入文件:
* iRet = SaveBloomFilterToFile(&stBloomFilter, "dump.bin")
* (1.1新增) 从文件读取生成好的BloomFilter:
* iRet = LoadBloomFilterFromFile(&stBloomFilter, "dump.bin")
**/
#define FORCE_INLINE __attribute__((always_inline))
#define BYTE_BITS (8)
#define MIX_UINT64(v) ((uint32_t)((v>>32)^(v)))
#define SETBIT(filter, n) (filter->pstFilter[n/BYTE_BITS] |= (1<<(n%BYTE_BITS)))
#define GETBIT(filter, n) (filter->pstFilter[n/BYTE_BITS] &= (1<<(n%BYTE_BITS)))
using namespace std;
#pragma pack(1)
typedef struct{
uint8_t cInitFlag; //初始化标志
uint8_t cResv[3];
uint32_t dwMaxItems; //n - BloomFilter中最大元素个数 (输入量)
double dProbFalse; //p - 假阳概率(误判率) (输入量,比如万分之一:0.00001)
uint32_t dwFilterBits; //m = ceil((n * log(p)) / log(1.0 / (pow(2.0, log(2.0))))); - BloomFilter的比特数
uint32_t dwHashFuncs; // k = round(log(2.0) * m / n); - 哈希函数个数
uint32_t dwSeed; // MurmurHash的种子偏移量
uint32_t dwCount; // Add()的计数,超过MAX_BLOOMFILTER_N则返回失败
uint32_t dwFilterSize; // dwFilterBits / BYTE_BITS
unsigned char *pstFilter; // BloomFilter存储指针,使用malloc分配
uint32_t *pdwHashPos; // 存储上次hash得到的K个bit位置数组(由bloom_hash填充)
}BaseBloomFilter;
//BloomFilter 文件头部定义
typedef struct{
uint32_t dwMagicCode; // 文件头部标识,填充 __MGAIC_CODE__
uint32_t dwSeed;
uint32_t dwCount;
uint32_t dwMaxItems; // n - BloomFilter中最大元素个数 (输入量)
double dProbFalse; // p - 假阳概率 (输入量,比如万分之一:0.00001)
uint32_t dwFilterBits; // m = ceil((n * log(p)) / log(1.0 / (pow(2.0, log(2.0))))); - BloomFilter的比特数
uint32_t dwHashFuncs; // k = round(log(2.0) * m / n); - 哈希函数个数
uint32_t dwResv[6];
uint32_t dwFileCrc; // (未使用)整个文件的校验和
uint32_t dwFilterSize; // 后面Filter的Buffer长度
}BloomFileHead;
#pragma pack()
// 计算BloomFilter的参数m,k
static inline void _CalcBloomFilterParam(uint32_t n, double p, uint32_t *pm, uint32_t *pk){
/**
* n - Number of items in the filter
* p - Probability of false positives, float between 0 and 1 or a number indicating 1-in-p
* m - Number of bits in the filter
* k - Number of hash functions
*
* f = ln(2) × ln(1/2) × m / n = (0.6185) ^ (m/n)
* m = -1*n*ln(p)/((ln(2))^2) = -1*n*ln(p)/(ln(2)*ln(2)) = -1*n*ln(p)/(0.69314718055995*0.69314718055995))
* = -1*n*ln(p)/0.4804530139182079271955440025
* k = ln(2)*m/n
**/
uint32_t m, k, m2;
m =(uint32_t) ceil(-1.0 * n * log(p) / 0.480453);
m = (m - m % 64) + 64; // 8字节对齐
double double_k = (0.69314 *m /n);
k = round(double_k);
*pm = m;
*pk = k;
return;
}
// 根据目标精度和数据个数,初始化BloomFilter结构
/**
* @brief 初始化布隆过滤器
* @param pstBloomfilter 布隆过滤器实例
* @param dwSeed hash种子
* @param dwMaxItems 存储容量
* @param dProbFalse 允许的误判率
* @return 返回值
* -1 传入的布隆过滤器为空
* -2 hash种子错误或误差>=1
*/
inline int InitBloomFilter(BaseBloomFilter *pstBloomfilter, uint32_t dwSeed, uint32_t dwMaxItems, double dProbFalse){
if(pstBloomfilter == NULL)
return -1;
if(dProbFalse <=0 || dProbFalse >= 1)
return -2;
//检查是否重复Init, 释放内存
if(pstBloomfilter->pstFilter != NULL)
free(pstBloomfilter->pstFilter);
if(pstBloomfilter->pdwHashPos != NULL)
free(pstBloomfilter->pdwHashPos);
memset(pstBloomfilter, 0, sizeof(pstBloomfilter));
//初始化内存结构,并计算BloomFilter需要的空间
pstBloomfilter->dwMaxItems = dwMaxItems;
pstBloomfilter->dProbFalse = dProbFalse;
pstBloomfilter->dwSeed = dwSeed;
//计算 m, k
_CalcBloomFilterParam(pstBloomfilter->dwMaxItems, pstBloomfilter->dProbFalse,
&pstBloomfilter->dwFilterBits, &pstBloomfilter->dwHashFuncs);
//分配BloomFilter的存储空间
pstBloomfilter->dwFilterSize = pstBloomfilter->dwFilterBits / BYTE_BITS;
pstBloomfilter->pstFilter = (unsigned char *)malloc(pstBloomfilter->dwFilterSize);
if(NULL == pstBloomfilter->pstFilter)
return -100;
//哈希结果数组,每个哈希函数一个
pstBloomfilter->pdwHashPos = (uint32_t*)malloc(pstBloomfilter->dwHashFuncs * sizeof(uint32_t));
if(NULL == pstBloomfilter->pdwHashPos)
return -200;
printf("Init BloomFilter(n=%u, p=%e, m=%u, k=%d), malloc() size=%.6fMB, items:bits=1:%0.1lfn",
pstBloomfilter->dwMaxItems, pstBloomfilter->dProbFalse, pstBloomfilter->dwFilterBits,
pstBloomfilter->dwHashFuncs, (double)pstBloomfilter->dwFilterSize/1024/1024,
pstBloomfilter->dwFilterBits*1.0/pstBloomfilter->dwMaxItems);
// 初始化BloomFilter的内存
memset(pstBloomfilter->pstFilter, 0, pstBloomfilter->dwFilterSize);
pstBloomfilter->cInitFlag = 1;
return 0;
}
//释放bloomfilter
inline int FreeBloomFilter(BaseBloomFilter * pstBloomfilter){
if(pstBloomfilter == NULL)
return -1;
pstBloomfilter->cInitFlag = 0;
pstBloomfilter->dwCount=0;
free(pstBloomfilter->pstFilter);
pstBloomfilter->pstFilter = NULL;
free(pstBloomfilter->pdwHashPos);
pstBloomfilter->pdwHashPos = NULL;
return 0;
}
//重置bloomfilter
inline int ResetBloomFilter(BaseBloomFilter *pstBloomfilter){
if(pstBloomfilter == NULL)
return -1;
pstBloomfilter->cInitFlag =0;
pstBloomfilter->dwCount =0;
return 0;
}
inline int RealResetBloomFilter(BaseBloomFilter *pstBloomfilter){
if (pstBloomfilter == NULL)
return -1;
memset(pstBloomfilter->pstFilter, 0, pstBloomfilter->dwFilterSize);
pstBloomfilter->cInitFlag = 1;
pstBloomfilter->dwCount = 0;
return 0;
}
FORCE_INLINE uint64_t MurmurHash2_x64 ( const void * key, int len, uint32_t seed )
{
const uint64_t m = 0xc6a4a7935bd1e995;
const int r = 47;
uint64_t h = seed ^ (len * m);
const uint64_t * data = (const uint64_t *)key;
const uint64_t * end = data + (len/8);
while(data != end)
{
uint64_t k = *data++;
k *= m;
k ^= k >> r;
k *= m;
h ^= k;
h *= m;
}
const uint8_t * data2 = (const uint8_t*)data;
switch(len & 7)
{
case 7: h ^= ((uint64_t)data2[6]) << 48;
case 6: h ^= ((uint64_t)data2[5]) << 40;
case 5: h ^= ((uint64_t)data2[4]) << 32;
case 4: h ^= ((uint64_t)data2[3]) << 24;
case 3: h ^= ((uint64_t)data2[2]) << 16;
case 2: h ^= ((uint64_t)data2[1]) << 8;
case 1: h ^= ((uint64_t)data2[0]);
h *= m;
};
h ^= h >> r;
h *= m;
h ^= h >> r;
return h;
}
// 双重散列封装,k个函数函数, 比如要20个
FORCE_INLINE void bloom_hash(BaseBloomFilter *pstBloomfilter, const void * key, int len){
int i;
uint32_t dwFilterBits = pstBloomfilter->dwFilterBits;
uint64_t hash1 = MurmurHash2_x64(key, len, pstBloomfilter->dwSeed);
uint64_t hash2 = MurmurHash2_x64(key, len, MIX_UINT64(hash1));
for (i = 0; i < (int)pstBloomfilter->dwHashFuncs; i++)
{
// k0 = (hash1 + 0*hash2) % dwFilterBits; // dwFilterBits bit向量的长度
// k1 = (hash1 + 1*hash2) % dwFilterBits;
pstBloomfilter->pdwHashPos[i] = (hash1 + i*hash2) % dwFilterBits;
}
return;
}
// 向BloomFilter中新增一个元素
// 成功返回0,当添加数据超过限制值时返回1提示用户
FORCE_INLINE int BloomFilter_Add(BaseBloomFilter *pstBloomfilter, const void * key, int len){
if((pstBloomfilter == NULL) || (key == NULL) || (len<=0))
return -1;
int i;
if(pstBloomfilter->cInitFlag != 1){
memset(pstBloomfilter->pstFilter,0 , pstBloomfilter->dwFilterSize);
pstBloomfilter->cInitFlag =1;
}
bloom_hash(pstBloomfilter, key, len);
for(i=0;i<(int)pstBloomfilter->dwHashFuncs; ++i){
SETBIT(pstBloomfilter, pstBloomfilter->pdwHashPos[i]);
}
pstBloomfilter->dwCount++;
if(pstBloomfilter->dwCount <= pstBloomfilter->dwMaxItems)
return 0;
else
return 1;
}
FORCE_INLINE int BloomFilter_Check(BaseBloomFilter *pstBloomfilter, const void * key, int len){
if((pstBloomfilter == NULL) || (key == NULL) || (len<=0))
return -1;
int i;
bloom_hash(pstBloomfilter, key, len);
for (i = 0; i < (int)pstBloomfilter->dwHashFuncs; i++)
{
// 如果有任意bit不为1,说明key不在bloomfilter中
// 注意: GETBIT()返回不是0|1,高位可能出现128之类的情况
if (GETBIT(pstBloomfilter, pstBloomfilter->pdwHashPos[i]) == 0)
return 1;
}
return 0;
}
inline int SaveBloomFilterToFile(BaseBloomFilter *pstBloomfilter, char *szFileName){
if ((pstBloomfilter == NULL) || (szFileName == NULL))
return -1;
int iRet;
FILE *pFile;
static BloomFileHead stFileHeader = {0};
pFile = fopen(szFileName, "wb");
if (pFile == NULL)
{
perror("fopen");
return -11;
}
// 先写入文件头
stFileHeader.dwMagicCode = __MGAIC_CODE__;
stFileHeader.dwSeed = pstBloomfilter->dwSeed;
stFileHeader.dwCount = pstBloomfilter->dwCount;
stFileHeader.dwMaxItems = pstBloomfilter->dwMaxItems;
stFileHeader.dProbFalse = pstBloomfilter->dProbFalse;
stFileHeader.dwFilterBits = pstBloomfilter->dwFilterBits;
stFileHeader.dwHashFuncs = pstBloomfilter->dwHashFuncs;
stFileHeader.dwFilterSize = pstBloomfilter->dwFilterSize;
iRet = fwrite((const void*)&stFileHeader, sizeof(stFileHeader), 1, pFile);
if (iRet != 1)
{
perror("fwrite(head)");
return -21;
}
// 接着写入BloomFilter的内容
iRet = fwrite(pstBloomfilter->pstFilter, 1, pstBloomfilter->dwFilterSize, pFile);
if ((uint32_t)iRet != pstBloomfilter->dwFilterSize)
{
perror("fwrite(data)");
return -31;
}
fclose(pFile);
return 0;
}
// 从文件读取生成好的BloomFilter
inline int LoadBloomFilterFromFile(BaseBloomFilter *pstBloomfilter, char *szFileName)
{
if ((pstBloomfilter == NULL) || (szFileName == NULL))
return -1;
int iRet;
FILE *pFile;
static BloomFileHead stFileHeader = {0};
if (pstBloomfilter->pstFilter != NULL)
free(pstBloomfilter->pstFilter);
if (pstBloomfilter->pdwHashPos != NULL)
free(pstBloomfilter->pdwHashPos);
//
pFile = fopen(szFileName, "rb");
if (pFile == NULL)
{
perror("fopen");
return -11;
}
// 读取并检查文件头
iRet = fread((void*)&stFileHeader, sizeof(stFileHeader), 1, pFile);
if (iRet != 1)
{
perror("fread(head)");
return -21;
}
if ((stFileHeader.dwMagicCode != __MGAIC_CODE__)
|| (stFileHeader.dwFilterBits != stFileHeader.dwFilterSize*BYTE_BITS))
return -50;
// 初始化传入的 BaseBloomFilter 结构
pstBloomfilter->dwMaxItems = stFileHeader.dwMaxItems;
pstBloomfilter->dProbFalse = stFileHeader.dProbFalse;
pstBloomfilter->dwFilterBits = stFileHeader.dwFilterBits;
pstBloomfilter->dwHashFuncs = stFileHeader.dwHashFuncs;
pstBloomfilter->dwSeed = stFileHeader.dwSeed;
pstBloomfilter->dwCount = stFileHeader.dwCount;
pstBloomfilter->dwFilterSize = stFileHeader.dwFilterSize;
pstBloomfilter->pstFilter = (unsigned char *) malloc(pstBloomfilter->dwFilterSize);
if (NULL == pstBloomfilter->pstFilter)
return -100;
pstBloomfilter->pdwHashPos = (uint32_t*) malloc(pstBloomfilter->dwHashFuncs * sizeof(uint32_t));
if (NULL == pstBloomfilter->pdwHashPos)
return -200;
// 将后面的Data部分读入 pstFilter
iRet = fread((void*)(pstBloomfilter->pstFilter), 1, pstBloomfilter->dwFilterSize, pFile);
if ((uint32_t)iRet != pstBloomfilter->dwFilterSize)
{
perror("fread(data)");
return -31;
}
pstBloomfilter->cInitFlag = 1;
printf("Load BloomFilter(n=%u, p=%f, m=%u, k=%d), malloc() size=%.2fMBn",
pstBloomfilter->dwMaxItems, pstBloomfilter->dProbFalse, pstBloomfilter->dwFilterBits,
pstBloomfilter->dwHashFuncs, (double)pstBloomfilter->dwFilterSize/1024/1024);
fclose(pFile);
return 0;
}
int main()
{
printf(" test bloomfiltern");
static BaseBloomFilter stBloomFilter = {0};
InitBloomFilter(&stBloomFilter, 0, MAX_ITEMS, P_ERROR);
char url[128] = {0};
for(int i = 0; i < ADD_ITEMS; i++){
sprintf(url, "https://0voice.com/%d.html", i);
if(0 == BloomFilter_Add(&stBloomFilter, (const void*)url, strlen(url))){
// printf("add %s success", url);
}else{
printf("add %s failed", url);
}
memset(url, 0, sizeof(url));
}
// 4. check url exist or not
char* str = "https://0voice.com/0.html";
if (0 == BloomFilter_Check(&stBloomFilter, (const void*)str, strlen(str)) ){
printf("https://0voice.com/0.html existn");
}
char* str2 = "https://0voice.com/10001.html";
if (0 != BloomFilter_Check(&stBloomFilter, (const void*)str2, strlen(str2)) ){
printf("https://0voice.com/10001.html not existn");
}
char * file = "testBloom.txt";
if(SaveBloomFilterToFile(&stBloomFilter, file) == 0)
printf("file save in %sn", file);
else
printf("file can't exitn");
//cout << "Hello world!" << endl;
if(0 == LoadBloomFilterFromFile(&stBloomFilter, file))
printf("read successn");
else
printf("read failuren");
FreeBloomFilter(&stBloomFilter);
getchar();
return 0;
}
-
函数
+关注
关注
3文章
4423浏览量
67896 -
数据结构
+关注
关注
3文章
573浏览量
41702 -
过滤器
+关注
关注
1文章
444浏览量
21058
发布评论请先 登录
一文理解布隆过滤器和布谷鸟过滤器
一种隐私保护的可逆布鲁姆过滤器PPIBF设计
过滤器的作用
如何使用计数型布隆过滤器进行可排序密文检索的方法概述
解密高效空气过滤器的性能及要求
过滤器的应用有哪些
Google在Play商店中推出搜索过滤器
丝扣Y过滤器
丝扣Y过滤器及过滤器测试原理简介
汉克森过滤器系列介绍


一文解析布隆过滤器设计原理






评论