 谷歌最便宜TPU值不值得买?TPU在执行神经网络计算方面的优势
谷歌最便宜TPU值不值得买?TPU在执行神经网络计算方面的优势

谷歌本月推出千元级搭载Edge TPU芯片的开发板,性能令人期待。本文以可视化图形的方式,对比TPU、GPU和CPU,解释了TPU在执行神经网络计算方面的优势。
谷歌最便宜 TPU 值不值得买?
谷歌 Edge TPU 在本月初终于公布价格 —— 不足 1000 元人民币,远低于 TPU。
实际上,Edge TPU 基本上就是机器学习的树莓派,它是一个用 TPU 在边缘进行推理的设备。
Edge TPU(安装在 Coral 开发板上)
云 vs 边缘
Edge TPU显然是在边缘(edge)运行的,但边缘是什么呢?为什么我们不选择在云上运行所有东西呢?
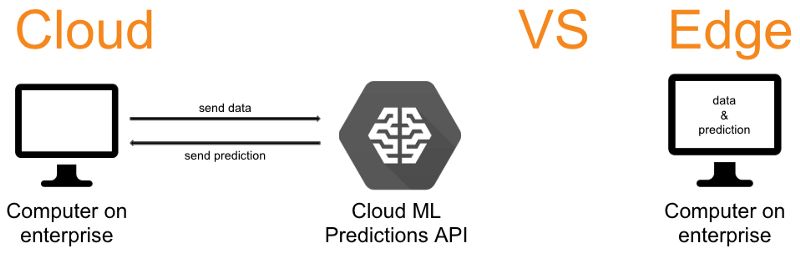
在云中运行代码意味着你使用的CPU、GPU和TPU都是通过浏览器提供的。在云中运行代码的主要优点是,你可以为特定的代码分配必要的计算能力(训练大型模型可能需要大量的计算)。
边缘与云相反,意味着你是在本地运行代码(也就是说你能够实际接触到运行代码的设备)。在边缘运行代码的主要优点是没有网络延迟。由于物联网设备通常要频繁地生成数据,因此运行在边缘上的代码非常适合基于物联网的解决方案。
对比 CPU、GPU,深度剖析 TPU
TPU(Tensor Processing Unit, 张量处理器)是类似于CPU或GPU的一种处理器。不过,它们之间存在很大的差异。最大的区别是TPU是ASIC,即专用集成电路。ASIC经过优化,可以执行特定类型的应用程序。对于TPU来说,它的特定任务就是执行神经网络中常用的乘积累加运算。CPU和GPU并未针对特定类型的应用程序进行优化,因此它们不是ASIC。
下面我们分别看看 CPU、GPU 和 TPU 如何使用各自的架构执行累积乘加运算:
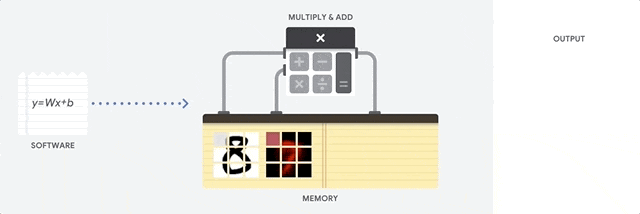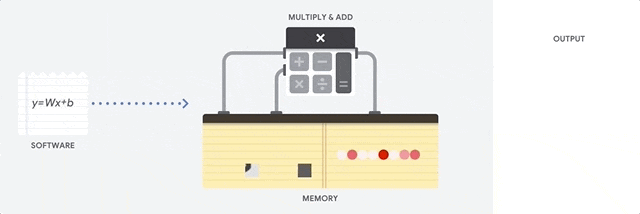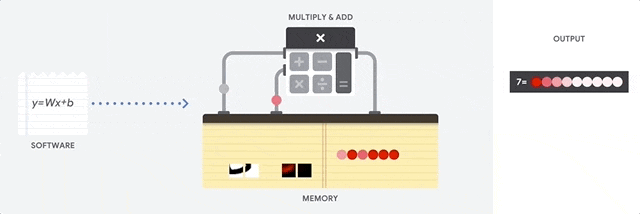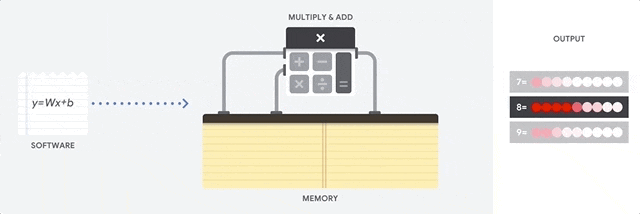
在 CPU 上进行累积乘加运算
CPU 通过从内存中读取每个输入和权重,将它们与其 ALU (上图中的计算器) 相乘,然后将它们写回内存中,最后将所有相乘的值相加,从而执行乘积累加运算。
现代 CPU 通过其每个内核上的大量缓存、分支预测和高时钟频率得到增强。这些都有助于降低 CPU 的延迟。

GPU 上的乘积累加运算
GPU 的原理类似,但它有成千上万的 ALU 来执行计算。计算可以在所有 ALU 上并行进行。这被称为 SIMD (单指令流多数据流),一个很好的例子就是神经网络中的多重加法运算。
然而,GPU 并不使用上述那些能够降低延迟的功能。它还需要协调它的数千个 ALU,这进一步减少了延迟。
简而言之,GPU 通过并行计算来大幅提高吞吐量,代价是延迟增加。或者换句话说:
CPU 是一个强大而训练有素的斯巴达战士,而 GPU 就像一支庞大的农民大军,但农民大军可以打败斯巴达战士,因为他们人多。

读取 TPU 上的乘加操作的权重
TPU 的运作方式非常不同。它的 ALU 是直接相互连接的,不需要使用内存。它们可以直接提供传递信息,从而大大减少延迟。
从上图中可以看出,神经网络的所有权重都被加载到 ALU 中。完成此操作后,神经网络的输入将加载到这些 ALU 中以执行乘积累加操作。这个过程如下图所示:

TPU 上的乘加操作
如上图所示,神经网络的所有输入并不是同时插入 ALU 的,而是从左到右逐步地插入。这样做是为了防止内存访问,因为 ALU 的输出将传播到下一个 ALU。这都是通过脉动阵列 (systolic array) 的方式完成的,如下图所示。
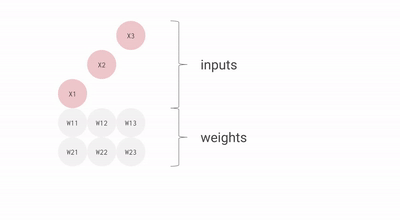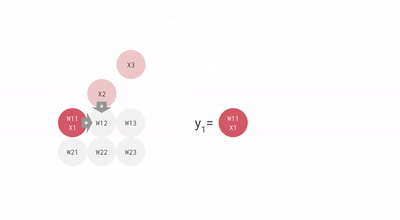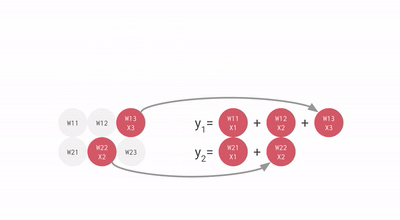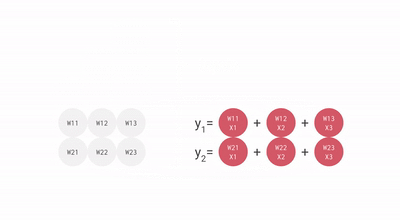
使用脉动阵列执行乘加操作
上图中的每个灰色单元表示 TPU 中的一个 ALU (其中包含一个权重)。在 ALU 中,乘加操作是通过将 ALU 从顶部得到的输入乘以它的权重,然后将它与从左编得到的值相加。此操作的结果将传播到右侧,继续完成乘加操作。ALU 从顶部得到的输入被传播到底部,用于为神经网络层中的下一个神经元执行乘加操作。
在每一行的末尾,可以找到层中每个神经元的乘加运算的结果,而不需要在运算之间使用内存。
使用这种脉动阵列显著提高了 Edge TPU 的性能。
Edge TPU 推理速度超过其他处理器架构
TPU 还有一个重要步骤是量化 (quantization)。由于谷歌的 Edge TPU 使用 8 位权重进行计算,而通常使用 32 位权重,所以我们应该将权重从 32 位转换为 8 位。这个过程叫做量化。
量化基本上是将更精确的 32 位数字近似到 8 位数字。这个过程如下图所示:
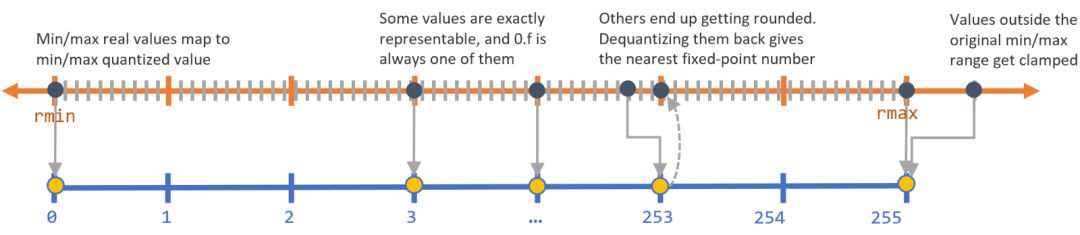
量化
四舍五入会降低精度。然而,神经网络具有很好的泛化能力 (例如 dropout),因此在使用量化时不会受到很大的影响,如下图所示。

非量化模型与量化模型的精度
量化的优势更为显著。它减少了计算量和内存需求,从而提高了计算的能源效率。
Edge TPU 执行推理的速度比任何其他处理器架构都要快。它不仅速度更快,而且通过使用量化和更少的内存操作,从而更加环保。
-
谷歌
+关注
关注
27文章
6257浏览量
111947 -
机器学习
+关注
关注
67文章
8561浏览量
137208 -
TPU
+关注
关注
0文章
171浏览量
21715
原文标题:一文读懂:谷歌千元级Edge TPU为何如此之快?
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
直击英伟达腹地?谷歌TPU v7开放部署,催生OCS产业链红利
AI芯片大单!Anthropic从博通采购100万颗TPU v7p芯片
神经网络的初步认识

谷歌云发布最强自研TPU,性能比前代提升4倍

NMSIS神经网络库使用介绍
在Ubuntu20.04系统中训练神经网络模型的一些经验
CICC2033神经网络部署相关操作
液态神经网络(LNN):时间连续性与动态适应性的神经网络
【「AI芯片:科技探索与AGI愿景」阅读体验】+神经形态计算、类脑芯片
神经网络的并行计算与加速技术
神经网络专家系统在电机故障诊断中的应用
神经网络RAS在异步电机转速估计中的仿真研究
基于FPGA搭建神经网络的步骤解析

AI神经网络降噪算法在语音通话产品中的应用优势与前景分析

TPU处理器的特性和工作原理



评论