 Groq推出大模型推理芯片 超越了传统GPU和谷歌TPU
Groq推出大模型推理芯片 超越了传统GPU和谷歌TPU

Groq推出了大模型推理芯片,以每秒500tokens的速度引起轰动,超越了传统GPU和谷歌TPU。该芯片采用了全球首个LPU方案,解决了计算密度和内存带宽的瓶颈,推理速度提高了10倍,成本降低十分之一,性价比提高了100倍。芯片搭载了230MB大SRAM,内存带宽高达80TB/s,算力强大,支持多种机器学习框架进行推理。 Groq在演示中展示了多种模型的强大性能,并宣称在三年内将超越英伟达。产品特色包括API访问速度快、支持多种开源LLM模型、价格优势等,成为大模型推理领域的新兴力量。
Groq 公司的创始于2016年,旗舰产品是 Groq Tensor Streaming Processor Chip(TSP)和相应的软件,主要应用于人工智能、机器学习、深度学习等领域。目标市场包括人工智能和机器学习超大规模应用、政府部门、高性能计算集群、自动驾驶车辆以及高性能边缘设备。
Groq产品以其出色的推理性能、对多种开源LLM模型的支持以及具有竞争力的价格政策等特色,成为一个引人注目的选择。这个芯片到底是怎么做的呢?

Part 1
Groq的做法
随着人工智能(AI)和高性能计算(HPC)的融合发展,对于同时处理AI和HPC工作负载的需求日益增加。在这一背景下,Groq公司推出了其最新的AI推理加速器,旨在简化计算、提高效率,并实现更高的可扩展性,软件定义张量流多处理器(TSP),采用了一种全新的硬件软件结合的方法,为人工智能、机器学习和深度学习应用提供更高效的计算支持。
Groq AI推理加速器的设计思想是结合了HPC与AI的工作负载需求,提供了一种创新的可扩展计算架构。
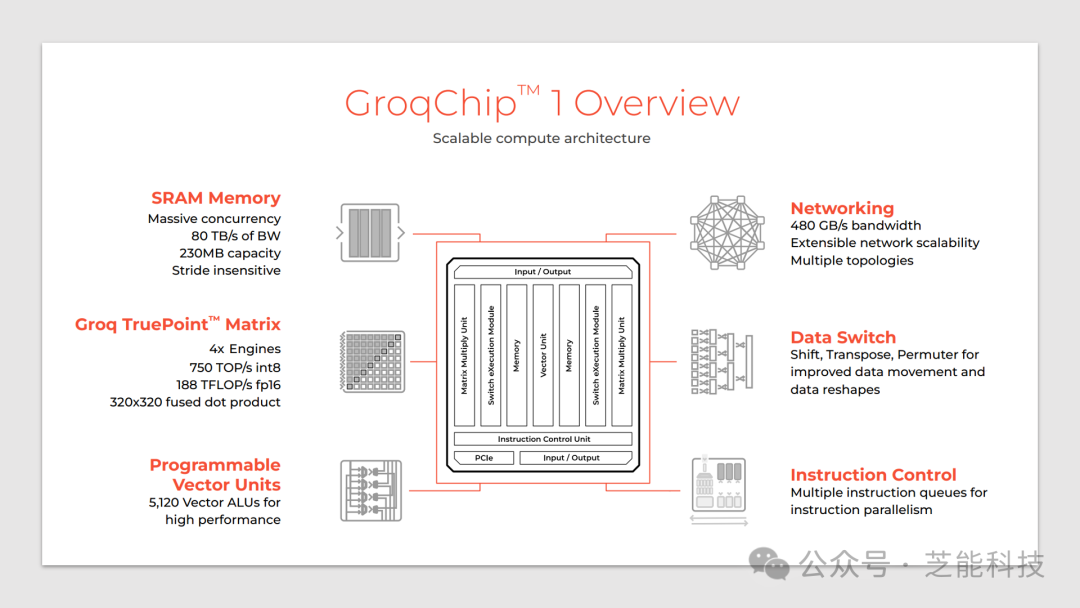
相比传统的GPU,GroqChip 1具有更简化的编程模型,更高的响应速度以及更可靠的执行。该芯片拥有多个特色组件,包括高速网络、数据交换器、指令控制、SRAM内存以及Groq TruePoint矩阵,使其具备了强大的计算能力和灵活性。
传统的 CPU 架构在控制逻辑方面隐藏了大量复杂性,如缓存、预取、乱序执行和分支预测,但这些控制逻辑会减少可用于原始计算的面积。
与此相反,Groq 公司重新审视了硬件软件的合约,创造出了更加可预测和基于流的硬件,并将更多的控制权交给了软件。
硬件(CPU)定义了软件,但随着数据流型计算需求的增长以及摩尔定律和 Dennard 缩放的减速,CPU“抽象”不再是软件开发的唯一基础。因此,Hennessy 和 Patterson 提出了“计算机体系结构的新黄金时代”的观点,Lattner 提出了“编译器的新黄金时代”的观点,Karpathy 则提出了“软件 2.0”的概念,这都预示着硬件与软件的抽象合约已经重新开启,实现了“软件定义硬件”的机会。
GroqChip 的可扩展架构以简化计算,通过使用大量单级划分 SRAM 和显式分配张量,实现了可预测的性能。
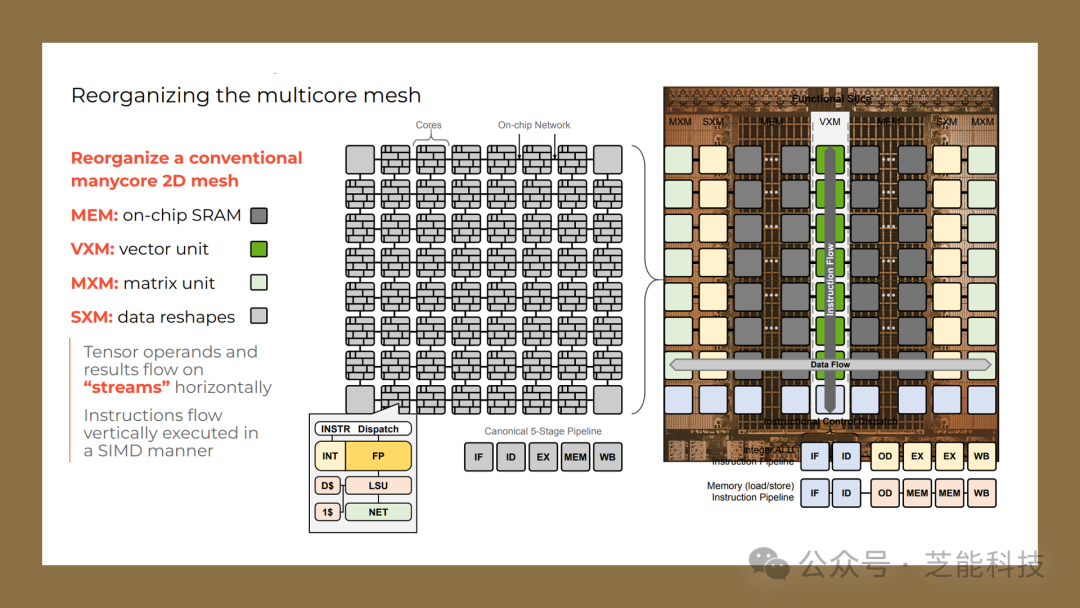
此外,Groq 公司设计了功能划分的微体系结构,重新组织了多核网格,使得编译器可以对程序执行进行精确控制,从而提高了执行效率。
Groq AI推理加速器支持各种规模的计算节点,从单个卡片到整个机架,都能实现高效的并行计算。

通过GroqRack和GroqNode等组件的组合,用户可以根据实际需求灵活搭建计算集群,实现对不同规模工作负载的处理。
Groq 公司提供了强大的编译器支持,通过在编译时和运行时之间建立静态-动态接口和硬件-软件接口,赋予了软件更多的数据编排权力。该编译器能够实现 SOTA(State of the Art)级别的性能,对于一些重要的矩阵操作如通用矩阵乘法(GEMM),Cholesky 分解等,取得了令人瞩目的成果。
在系统拓扑结构方面,Groq 公司采用了低直径网络 Dragonfly,以最小化网络中的跳数,提高了数据传输效率。
同时,通过 Chip-to-Chip(C2C)链接和流量控制,实现了多芯片间的通信。此外,Groq 公司还提出了一种多芯片间的分区和流水线并行执行的方法,以进一步提高多芯片系统的性能。

Part 2
实际案例
除了传统的计算流体动力学(CFD)应用外,Groq AI推理加速器还可应用于图神经网络(GNN)等领域。GNN广泛应用于非欧几里得数据的建模和预测,例如化学分子结构、社交媒体推荐系统等。Groq芯片在处理这类非结构化数据时表现出色,通过深度学习算法的加速,能够大幅提升模型训练和推理的效率。软件定义张量流多处理器提供了一种全新的硬件软件结合的方法,通过重新审视硬件软件合约,将更多的控制权交给了软件,从而实现了更高效的计算性能。随着人工智能和深度学习应用的不断发展,这种方法将有望在未来的计算领域发挥重要作用。
在实际应用中,Groq AI推理加速器已经在化学分子属性预测、药物发现等领域取得了显著的成果。

借助其高性能和可扩展性,Groq芯片在处理大规模数据集时能够实现极大的加速,从而提升了科学研究和工程实践的效率。
小结
总的来说,Groq AI推理加速器以其创新的设计思想和强大的性能,在处理融合HPC与AI工作负载的应用中展现出了巨大的潜力。随着对于高性能计算和人工智能技术的不断发展,相信Groq芯片将在各个领域展现出更广泛的应用前景。
审核编辑:刘清
-
人工智能
+关注
关注
1821文章
50453浏览量
267506 -
机器学习
+关注
关注
67文章
8569浏览量
137355 -
TSP
+关注
关注
1文章
26浏览量
17479 -
大模型
+关注
关注
2文章
3841浏览量
5289 -
Groq
+关注
关注
0文章
10浏览量
224
原文标题:Groq AI推理加速器: 三年内超越英伟达?
文章出处:【微信号:QCDZSJ,微信公众号:汽车电子设计】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
谷歌发布第八代TPU,训练推理分离,搭载自研CPU

大模型推理服务的弹性部署与GPU调度方案
AI推理芯片需求爆发,OpenAI欲寻求新合作伙伴
曦望发布新一代推理GPU芯片,单位Token推理成本降低90%
今日看点:消息称 AMD、高通考虑导入 SOCAMM 内存;曦望发布新一代推理GPU芯片启望S3
LLM推理模型是如何推理的?

英伟达重磅出手!AI 推理存储全面觉醒

AI硬件全景解析:CPU、GPU、NPU、TPU的差异化之路,一文看懂!

谷歌正式推出最新Gemini 3 AI模型

谷歌云发布最强自研TPU,性能比前代提升4倍

【「AI芯片:科技探索与AGI愿景」阅读体验】+AI芯片的需求和挑战
Groq LPU 如何让万亿参数模型「飞」起来?揭秘 Kimi K2 40 倍提速背后的黑科技
大模型推理显存和计算量估计方法研究
为什么无法在GPU上使用INT8 和 INT4量化模型获得输出?
智算加速卡是什么东西?它真能在AI战场上干掉GPU和TPU!




评论