 ChatGLM2-6B解析与TPU部署
ChatGLM2-6B解析与TPU部署

概述#
算能BM1684X芯片已经实现ChatGLM2-6B的C++代码部署,代码实现链接:https://github.com/sophgo/ChatGLM2-TPU。
本文总结部署该模型过程中的一些技术点。首先是ChatGLM2-6B的整体运行流程,然后介绍如何将该动态网路转换成静态网络形式,接着介绍如何将该模型导出成ONNX。
最后如何将ONNX使用TPU-MLIR编译器实现网络的编译以及用C++代码编写应用程序,可以直接看源码就可以理解,这里不做介绍。
ChatGLM2-6b运行流程#
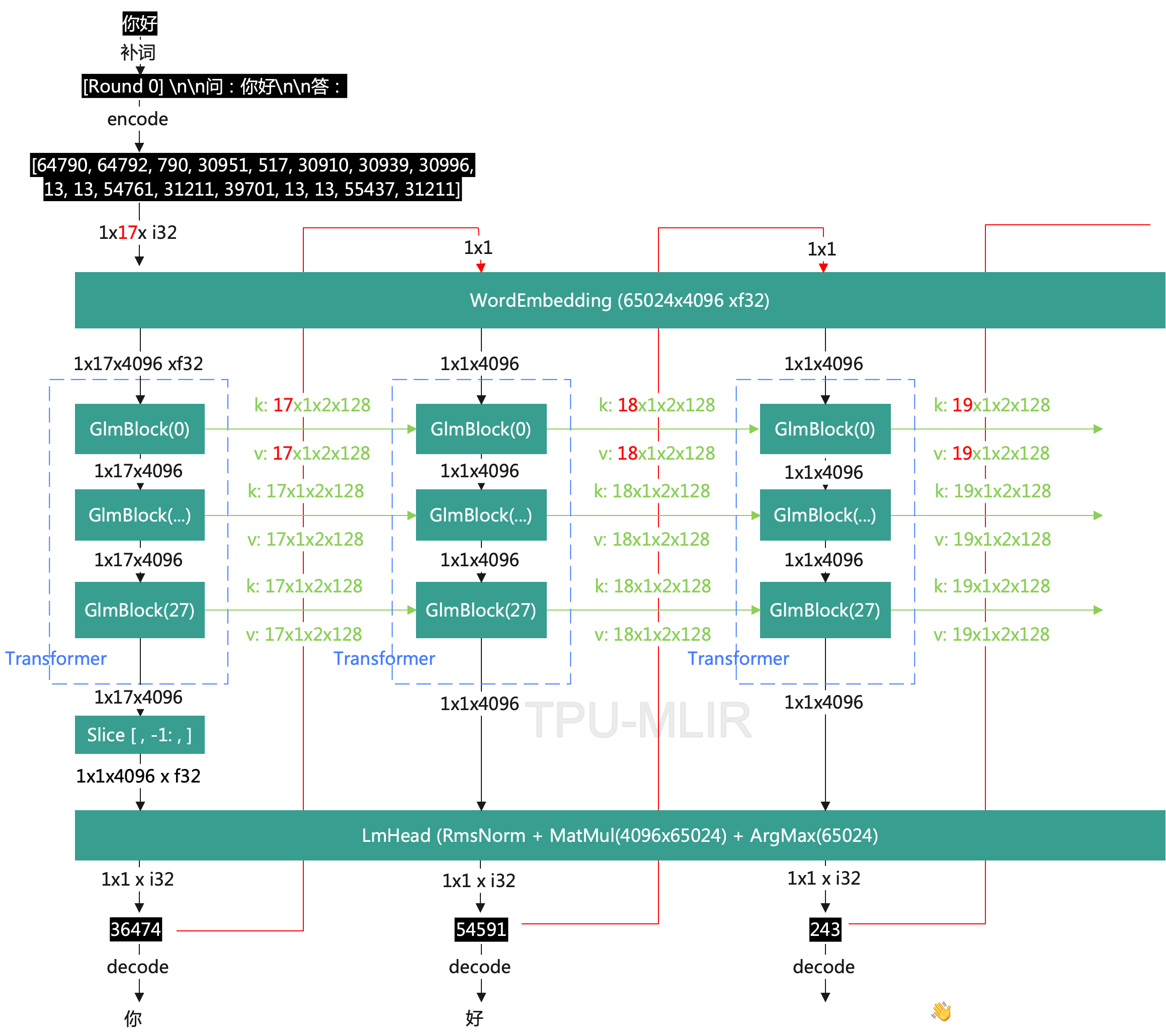
如图该网络基本上可以分为5个阶段:
将句子通过分词器(使用google的sentencepiece)转换成tokens,如图中的<1x17 xi32>的数据。注意tokens里面64790, 64792是起始符号。
通过WordEmbedding将tokens转换成词向量,得到的结果是<1x17x4096 xf32>的数据。
通过Tranformer进行神经网络推理,推理结果是<1x17x4096 xf32>,答案在最后的词向量上,所以做一个额外的slice操作,得到<1x1x4096 xf32>。这里Transformer网络是由28个Block组成,每个Block的核心是一个Attention运算,并输出kv cache给下一轮Transform做为输入。
经过LmHead操作生成<1x1 xi32>的结果,也就是输出的Token。LmHead的组成如图所示。
Token经过分词器转成词语,且传递给下一轮推理,进入第一阶段。直到token == EOS_ID结束。
转成静态网络#
ChatGLM2-6B从前面的描述中,可以看到有两处是动态的,一是因句子的长短不同,Transformer的输入Shape有所有不同;二是每一轮Transformer生成的kv cache会逐步增长。为了方便部署,根据网络特点转换成静态网络。转换后的运行流程如下:
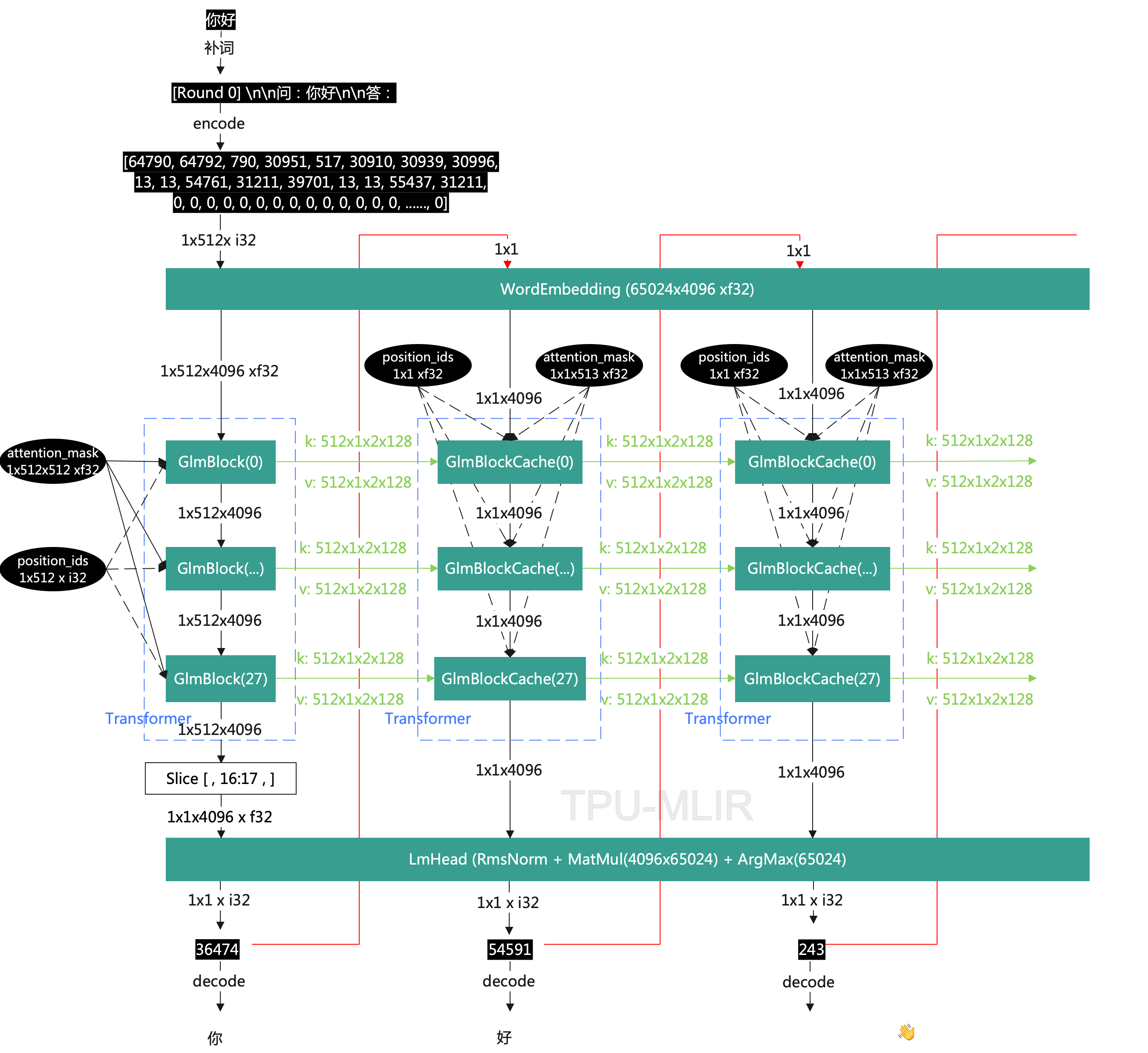
从图中可以看到句子不论长短,转换后的tokens始终是<1x512x i32>,kv cache的数据也始终是<512x1x2x128x f32>。
这里介绍最关键的几点:
将原始tokens输入尾部补0,从<1x17x i32>转换成<1x512x i32>。
将position_ids从GlmBlock中提取出来,并固定长度为<1x512x i32>,也是尾部补0,本例中的数值为[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,0,0,0,0,...0],用于位置编码。因为在原始网络中这部分是变长,提取出来后就可以做成定长。
将attention_mask从GlmBlock中提取出来,并固定长度为<1x512x512x f32>,注意无效部分全部补1,因为它之后会有masked_fill操作将mask为1的部分全部配置为-inf。然后经过Softmax使超出部分全部清0,保留有效部分,从而保证最终结果与原始结果一致。如下图,为说明问题,Attention做了简化。
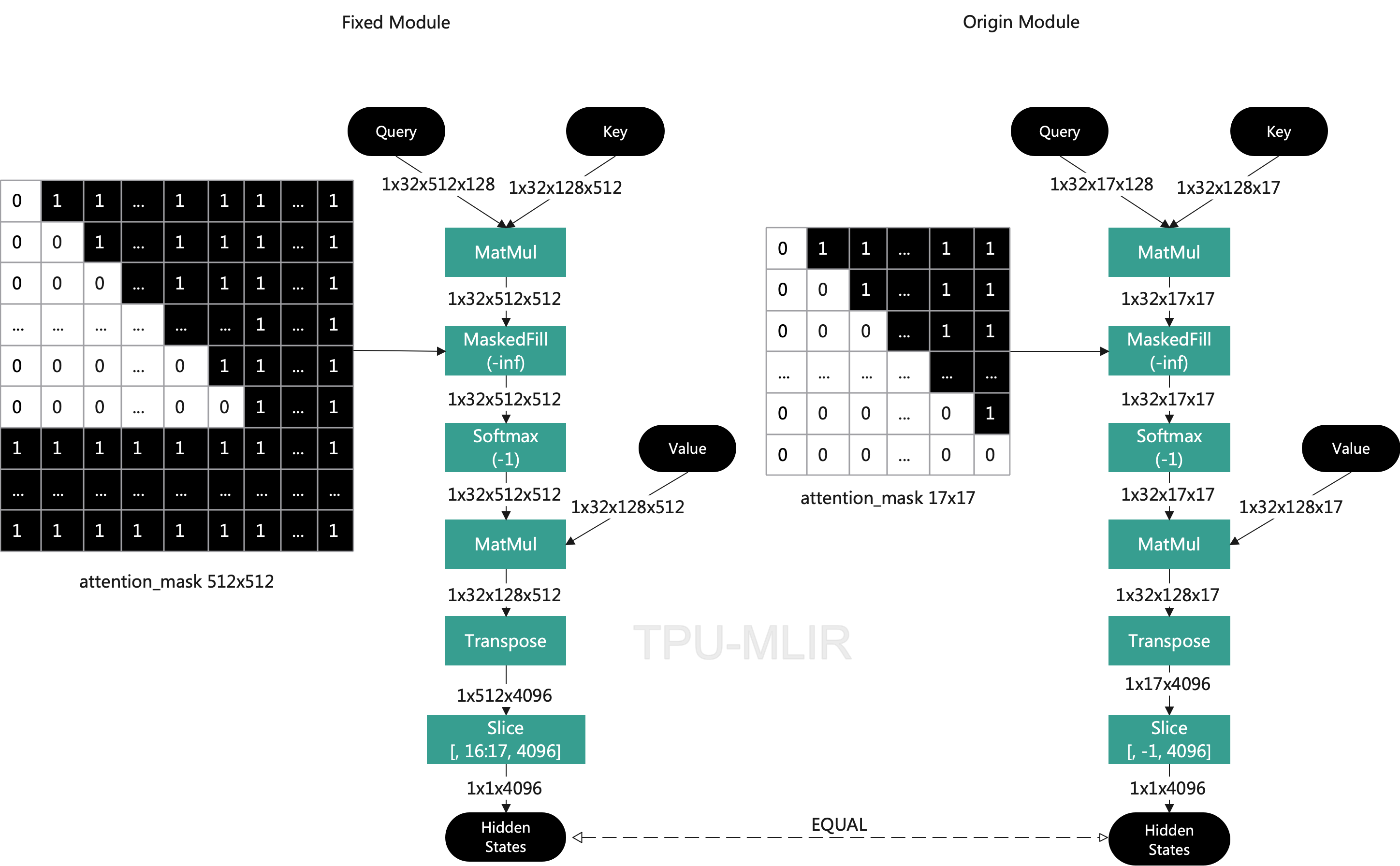
第一轮Transformer后,kv_chache有效部分是[0:17],我们将该部分移到末尾[512-17:],并头部清0。因为kv cache的累加发生在尾部。从第二轮开始累加后做Slice操作去掉头部1个单位,取[1:],这样就保证了kv cache始终保持在512。同时attention mask也要是从尾部实际token len长度的0,头部全部置1。
导出ONNX#
将该网络分为4块:WorkEmbedding,GlmBlock,GlmBlockCache,LmHead。这里分别介绍这四块是如何导出的。
导出前,先要指定python路径,如下:
1 |
export PYTHONPATH=/workspace/chatglm2-6b:$PYTHONPATH |
需要先加载原始ChatGLM2-6B,如下代码:
1 2 3 4 5 6 7 8 9 10 11 |
CHATGLM2_PATH = "/workspace/chatglm2-6b"
origin_model = AutoModel.from_pretrained(CHATGLM2_PATH,
trust_remote_code=True).float()
origin_model.eval()
transformer = origin_model.transformer
MAX_LEN = transformer.seq_length
for param in origin_model.parameters():
param.requires_grad = False
num_layers = transformer.encoder.num_layers
layers = transformer.encoder.layers
|
WorkEmbedding#
直接使用原模型中的word_embeddings,构建成独立网络,导出即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
class Embedding(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, input_ids):
return transformer.embedding.word_embeddings(input_ids)
def convert_embedding():
model = Embedding()
torch.onnx.export(model, (torch.tensor([0, 1, 2, 3])),
f'./tmp/embedding.onnx',
verbose=False,
input_names=['input_ids'],
output_names=['input_embed'],
dynamic_axes={"input_ids": {0: "length"}},
do_constant_folding=True,
opset_version=15)
|
GlmBlock#
需要将transformer.rotary_pos_emb和transformer.encoder.layers组合构建独立网路,导出。因为有28个block,所以需要导出28个ONNX模型。这里的position_ids和attention_mask作为外部输入,前面有介绍。其实这28个Block是可以组合成一个模型,但是这样导致onnx权重过大(F16约12GB),导出麻烦,部署也麻烦,所以单个导出。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
class GlmBlock(torch.nn.Module):
def __init__(self, layer_id):
super().__init__()
self.layer = layers[layer_id]
def forward(self, hidden_states, position_ids, attention_mask):
rotary_pos_emb = transformer.rotary_pos_emb(MAX_LEN)[position_ids]
rotary_pos_emb = rotary_pos_emb.transpose(0, 1).contiguous()
hidden_states, past_kv = self.layer(hidden_states, attention_mask,
rotary_pos_emb=rotary_pos_emb)
return hidden_states, past_kv
def convert_glm_block(layer_id):
model = GlmBlock(layer_id)
torch.onnx.export(
model, (hidden_states, position_ids, attention_mask),
f'./tmp/glm_block_{layer_id}.onnx',
verbose=False,
input_names=['input_states', 'position_ids', 'attention_mask'],
output_names=['hidden_states', 'past_k', 'past_v'],
do_constant_folding=True,
opset_version=15)
|
GlmBlockCache#
与`GlmBlock是类似的,但是需要额外的kv cache参数。注意这里 最后会把头部1个单位去除掉。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
class GlmBlockCache(torch.nn.Module):
def __init__(self, layer_id):
super().__init__()
self.layer = layers[layer_id]
def forward(self, hidden_states, position_ids, attention_mask, past_k, past_v):
rotary_pos_emb = transformer.rotary_pos_emb(MAX_LEN)[position_ids]
rotary_pos_emb = rotary_pos_emb.transpose(0, 1).contiguous()
hidden_states, past_kv = self.layer(hidden_states, attention_mask,
kv_cache=(past_k, past_v),
rotary_pos_emb=rotary_pos_emb)
past_k, past_v = past_kv
return hidden_states, past_k[1:], past_v[1:]
def convert_glm_block_cache(layer_id):
model = GlmBlockCache(layer_id)
torch.onnx.export(
model, (hidden_states, position_ids, attention_mask, past_k, past_v),
f'./tmp/glm_block_cache_{layer_id}.onnx',
verbose=False,
input_names=['input_states', 'position_ids', 'attention_mask', 'history_k', 'history_v'],
output_names=['hidden_states', 'past_k', 'past_v'],
do_constant_folding=True,
opset_version=15)
|
LmHead#
这里取m_logits后使用topk,其实也是可以用argmax,看芯片实现哪一种效率高。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
class LmHead(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, hidden_states):
hidden_states = transformer.encoder.final_layernorm(hidden_states)
m_logits = transformer.output_layer(hidden_states)
_, token = torch.topk(m_logits, 1)
return token
def convert_lm_head():
model = LmHead()
input = torch.randn(1, 4096)
torch.onnx.export(model, (input), f'./tmp/lm_head.onnx', verbose=False,
input_names=['hidden_states'],
output_names=['token'],
do_constant_folding=True,
opset_version=15)
|
部署#
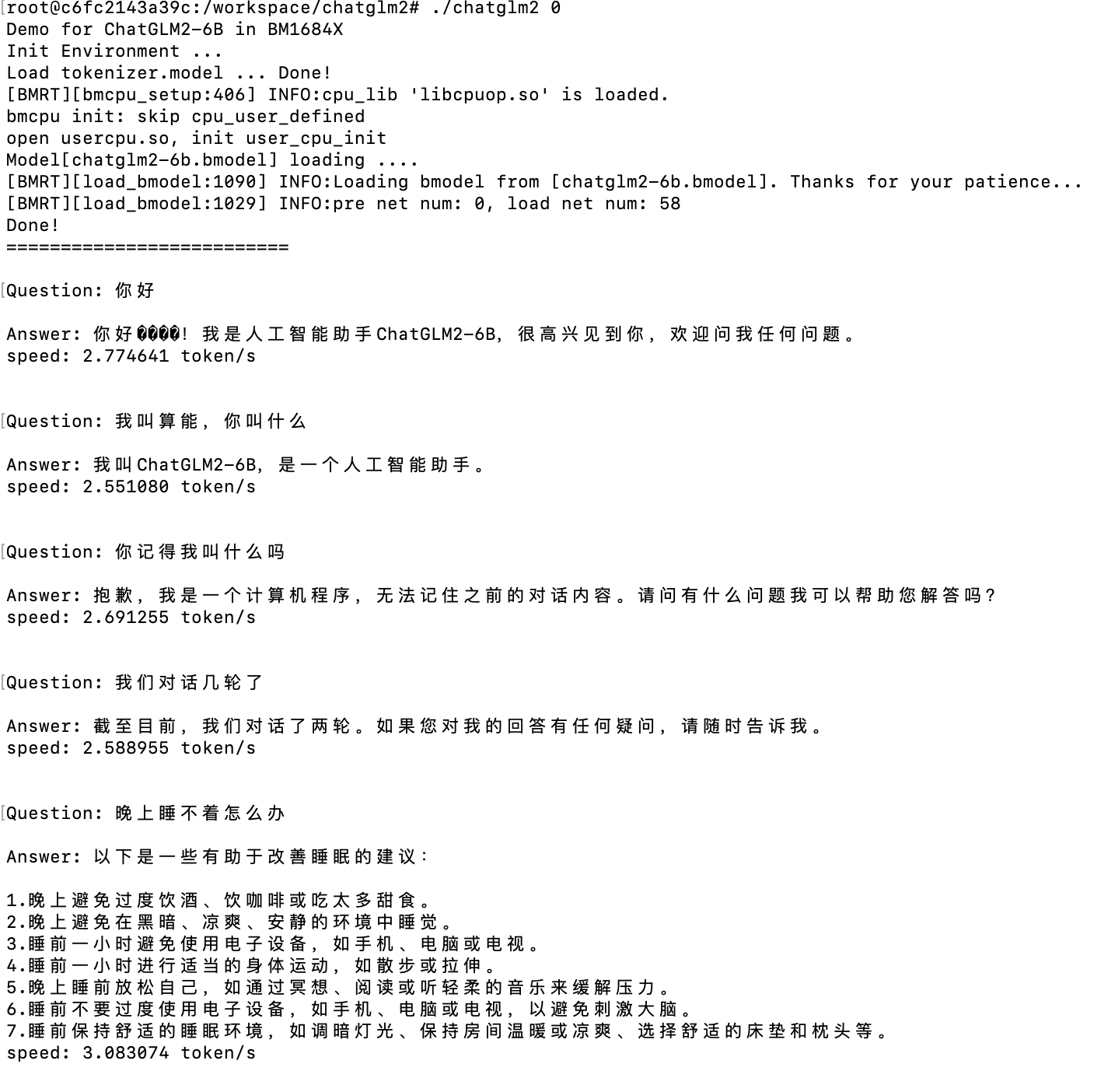
上述转完ONNX模型后都已经是静态网络,通过TPU-MLIR,可以很容易的转换成F16的模型。但是特别要注意的是RmsNorm需要用F32。之后就可以按照执行逻辑编写C++代码。演示效果如下:
-
芯片
+关注
关注
463文章
54463浏览量
469525 -
源码
+关注
关注
8文章
689浏览量
31517 -
C++
+关注
关注
22文章
2131浏览量
77404 -
TPU
+关注
关注
0文章
173浏览量
21719
发布评论请先 登录
【算能RADXA微服务器试用体验】Radxa Fogwise 1684X Mini 规格
CORAL-EDGE-TPU:珊瑚开发板TPU
TPU透明副牌.TPU副牌料.TPU抽粒厂.TPU塑胶副牌.TPU再生料.TPU低温料
TPU副牌低温料.TPU热熔料.TPU中温料.TPU低温塑胶.TPU低温抽粒.TPU中温塑料
供应TPU抽粒工厂.TPU再生工厂.TPU聚醚料.TPU聚酯料.TPU副牌透明.TPU副牌.TPU中低温料
清华系千亿基座对话模型ChatGLM开启内测
ChatGLM-6B的局限和不足
ChatGLM2-6B:性能大幅提升,8-32k上下文,推理提速42%,在中文榜单位列榜首
下载量超300w的ChatGLM-6B再升级:8-32k上下文,推理提速42%
适用于各种NLP任务的开源LLM的finetune教程~

基于ChatGLM2和OpenVINO™打造中文聊天助手

探索ChatGLM2在算能BM1684X上INT8量化部署,加速大模型商业落地

ChatGLM3-6B在CPU上的INT4量化和部署
三步完成在英特尔独立显卡上量化和部署ChatGLM3-6B模型
chatglm2-6b在P40上做LORA微调



评论