 谷歌、DeepMind重磅推出PlaNet 强化学习新突破
谷歌、DeepMind重磅推出PlaNet 强化学习新突破

Google AI 与 DeepMind 合作推出深度规划网络 (PlaNet),这是一个纯粹基于模型的智能体,能从图像输入中学习世界模型,完成多项规划任务,数据效率平均提升50倍,强化学习又一突破。
通过强化学习 (RL),对 AI 智能体如何随着时间的推移提高决策能力的研究进展迅速。
对于强化学习,智能体在选择动作 (例如,运动命令) 时会观察一系列感官输入(例如,相机图像),并且有时会因为达成指定目标而获得奖励。
RL 的无模型方法 (Model-free) 旨在通过感官观察直接预测良好的行为,这种方法使 DeepMind 的 DQN 能够玩雅达利游戏,使其他智能体能够控制机器人。
然而,这是一种黑盒方法,通常需要经过数周的模拟交互才能通过反复试验来学习,这限制了它在实践中的有效性。
相反,基于模型的 RL 方法 (Model-basedRL) 试图让智能体了解整个世界的行为。这种方法不是直接将观察结果映射到行动,而是允许 agent 明确地提前计划,通过 “想象” 其长期结果来更仔细地选择行动。
Model-based 的方法已经取得了巨大的成功,包括 AlphaGo,它设想在已知游戏规则的虚拟棋盘上进行一系列的移动。然而,要在未知环境中利用规划(例如仅将像素作为输入来控制机器人),智能体必须从经验中学习规则或动态。
由于这种动态模型原则上允许更高的效率和自然的多任务学习,因此创建足够精确的模型以成功地进行规划是 RL 的长期目标。
为了推动这项研究挑战的进展,Google AI 与 DeepMind 合作,提出了深度规划网络 (Deep Planning Network, PlaNet),该智能体仅从图像输入中学习世界模型 (world model),并成功地利用它进行规划。
PlaNet 解决了各种基于图像的控制任务,在最终性能上可与先进的 model-free agent 竞争,同时平均数据效率提高了 5000%。研究团队将发布源代码供研究社区使用。
在 2000 次的尝试中,PlaNet 智能体学习解决了各种连续控制任务。以前的没有学习环境模型的智能体通常需要多 50 倍的尝试次数才能达到类似的性能。
PlaNet 的工作原理
简而言之,PlaNet 学习了给定图像输入的动态模型 (dynamics model),并有效地利用该模型进行规划,以收集新的经验。
与以前的图像规划方法不同,我们依赖于隐藏状态或潜在状态的紧凑序列。这被称为latent dynamics model:我们不是直接从一个图像到下一个图像地预测,而是预测未来的潜在状态。然后从相应的潜在状态生成每一步的图像和奖励。
通过这种方式压缩图像,agent 可以自动学习更抽象的表示,例如对象的位置和速度,这样就可以更容易地向前预测,而不需要沿途生成图像。
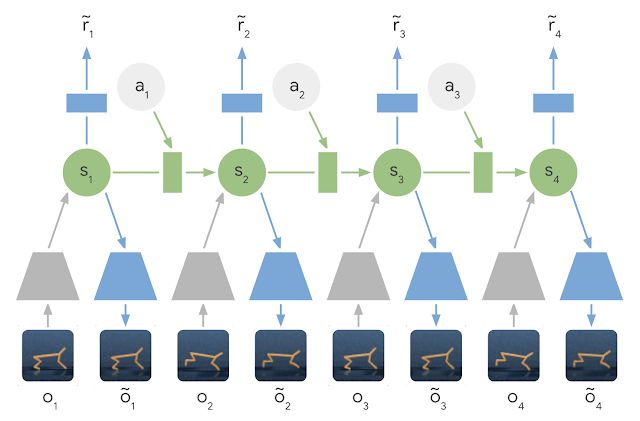
Learned Latent Dynamics Model:在 latent dynamics 模型中,利用编码器网络(灰色梯形) 将输入图像的信息集成到隐藏状态(绿色) 中。然后将隐藏状态向前投影,以预测未来的图像(蓝色梯形) 和奖励(蓝色矩形)。
为了学习一个精确的 latent dynamics 模型,我们提出了:
循环状态空间模型 (Recurrent State Space Model):一种具有确定性和随机性成分的 latent dynamics 模型,允许根据鲁棒规划的需要预测各种可能的未来,同时记住多个时间步长的信息。我们的实验表明这两个组件对于提高规划性能是至关重要的。
潜在超调目标 (Latent Overshooting Objective):我们通过在潜在空间中强制 one-step 和 multi-step 预测之间的一致性,将 latent dynamics 模型的标准训练目标推广到训练多步预测。这产生了一个快速和有效的目标,可以改善长期预测,并与任何潜在序列模型兼容。
虽然预测未来的图像允许我们教授模型,但编码和解码图像 (上图中的梯形) 需要大量的计算,这会减慢智能体的 planning 过程。然而,在紧凑的潜在状态空间中进行 planning 是很快的,因为我们只需要预测未来的 rewards 来评估一个动作序列,而不是预测图像。
例如,智能体可以想象球的位置和它到目标的距离在特定的动作中将如何变化,而不需要可视化场景。这允许我们在每次智能体选择一个动作时,将 10000 个想象的动作序列与一个大的 batch size 进行比较。然后执行找到的最佳序列的第一个动作,并在下一步重新规划。
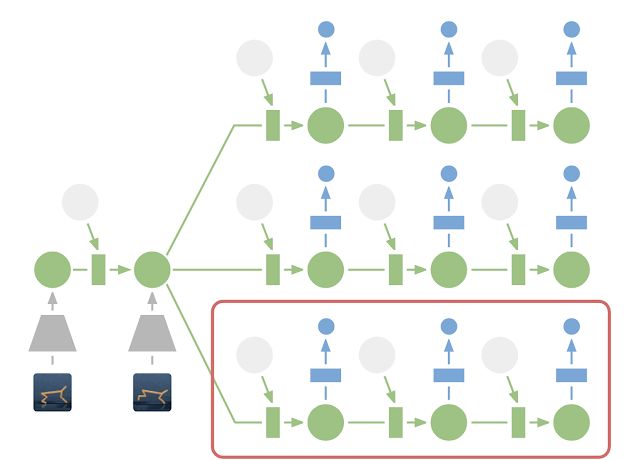
在潜在空间中进行规划:为了进行规划,我们将过去的图像 (灰色梯形) 编码为当前的隐藏状态 (绿色)。这样,我们可以有效地预测多个动作序列的未来奖励。请注意,上图中昂贵的图像解码器 (蓝色梯形) 已经消失了。然后,执行找到的最佳序列的第一个操作 (红色框)。
与我们之前关于世界模型的工作 (https://worldmodels.github.io/) 相比,PlaNet 在没有策略网络的情况下工作 —— 它纯粹通过 planning 来选择行动,因此它可以从模型当下的改进中获益。有关技术细节,请参阅我们的研究论文。
PlaNet vs. Model-Free 方法
我们在连续控制任务上评估了 PlaNet。智能体只被输入图像观察和奖励。我们考虑了具有各种不同挑战的任务:
侧手翻任务:带有一个固定的摄像头,这样推车可以移动到视线之外。因此,智能体必须吸收并记住多个帧的信息。
手指旋转任务:需要预测两个单独的对象,以及它们之间的交互。
猎豹跑步任务:包括难以准确预测的地面接触,要求模型预测多个可能的未来。
杯子接球任务:它只在球被接住时提供一个稀疏的奖励信号。这要求准确预测很远的未来,并规划一个精确的动作序列。
走路任务:模拟机器人一开始是躺在地上,然后它必须先学会站立,再学习行走。
PlaNet 智能体接受了各种基于图像的控制任务的训练。动图显示了当智能体解决任务时输入的图像。这些任务提出了不同的挑战:部分可观察性、与地面的接触、接球的稀疏奖励,以及控制一个具有挑战性的双足机器人。
这一研究是第一个使用学习模型进行规划,并在基于图像的任务上优于 model-free 方法的案例。
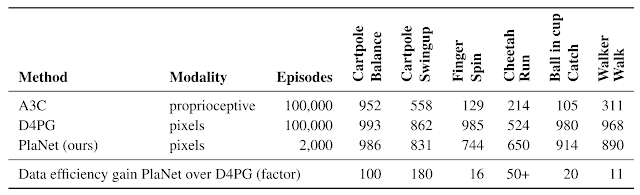
下表将PlaNet与著名的A3C 智能体和 D4PG 智能体进行了比较,后者结合了 model-free RL 的最新进展。这些基线数据来自 DeepMind 控制套件。PlaNet 在所有任务上都明显优于 A3C,最终性能接近 D4PG,同时与环境的交互平均减少了 5000%。
所有任务只需要一个智能体
此外,我们只训练了一个单一的 PlaNet 智能体来解决所有六个任务。
在不知道任务的情况下,智能体被随机放置在不同的环境中,因此它需要通过观察图像来推断任务。
在不改变超参数的情况下,多任务智能体实现了与单个智能体相同的平均性能。虽然在侧手翻任务中学习速度较慢,但在需要探索的具有挑战性的步行任务中,它的学习速度要快得多,最终表现也更好。
在多个任务上训练的 PlaNet 智能体。智能体观察前 5 个帧作为上下文以推断任务和状态,并在给定动作序列的情况下提前准确地预测 50 个步骤。
结论
我们的结果展示了构建自主 RL 智能体的学习动态模型的前景。我们鼓励进一步的研究,集中在学习更困难的任务的精确动态模型,如三维环境和真实的机器人任务。扩大规模的一个可能因素是 TPU 的处理能力。我们对 model-based 强化学习带来的可能性感到兴奋,包括多任务学习、分层规划和使用不确定性估计的主动探索。
-
谷歌
+关注
关注
27文章
6264浏览量
112155 -
强化学习
+关注
关注
4文章
275浏览量
12012 -
DeepMind
+关注
关注
0文章
131浏览量
12458
原文标题:一个智能体打天下:谷歌、DeepMind重磅推出PlaNet,数据效率提升50倍
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
在阿里云PAI平台的机器人感知强化学习规模化实践

Momenta R7强化学习世界模型助力上汽大众ID. ERA 9X正式上市
上汽奥迪E5 Sportback车型升级搭载全新Momenta强化学习大模型
上汽大众ID. ERA 9X全球首发搭载Momenta R7强化学习世界模型
Momenta R6强化学习大模型上车东风日产NX8
Momenta强化学习大模型助力别克至境世家纯电版正式上市
Momenta R7强化学习世界模型即将推出
自动驾驶中常提的离线强化学习是什么?

强化学习会让自动驾驶模型学习更快吗?

多智能体强化学习(MARL)核心概念与算法概览

上汽别克至境E7首发搭载Momenta R6强化学习大模型
今日看点:智元推出真机强化学习;美国软件公司SAS退出中国市场
自动驾驶中常提的“强化学习”是个啥?




评论