 实现 TensorFlow 架构的规模性和灵活性
实现 TensorFlow 架构的规模性和灵活性

TensorFlow 是为了大规模分布式训练和推理而设计的,不过它在支持新机器学习模型和系统级优化的实验中的表现也足够灵活。
本文对能够同时兼具规模性和灵活性的系统架构进行了阐述。设定的人群是已基本熟悉 TensorFlow 编程概念,例如 computation graph, operations, and sessions。有关这些主题的介绍,请参阅
https://tensorflow.google.cn/guide/low_level_intro?hl=zh-CN。如已熟悉Distributed TensorFlow,本文对您也很有帮助。行至文尾,您应该能了解 TensorFlow 架构,足以阅读和修改核心 TensorFlow 代码了。
概览
TensorFlow runtime 是一个跨平台库。图 1 说明了它的一般架构。 C API layer 将不同语言的用户级代码与核心运行时分开。
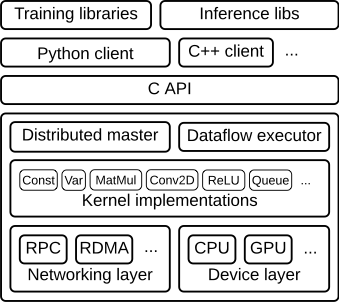
图 1
本文重点介绍以下几个方面:
客户端:
将整个计算过程转义成一个数据流图
通过 session,启动图形执行
分布式主节点
基于用户传递给 Session.run() 中的参数对整个完整的图形进行修剪,提取其中特定子图
将上述子图划分成不同片段,并将其对应不同的进程和设备当中
将上述划分的片段分布到 worker services 工作节点服务上
每个 worker services 工作节点服务上执行其收到的图形片段
工作节点服务 Worker Services(每一任务一个)
使用内核实现来计划图形表示的计算部分分配给正确的可用硬件(如 cpu,gpu 等)
与其他工作节点服务 work services 相互发送和接收计算结果
内核实现
执行单个图形操作的计算部分
图2 说明了这些组件的相互作用。“/ job:worker / task:0” 和 “/ job:ps / task:0” 都是工作节点服务 worker services 上执行的任务。“PS” 表示“参数服务器”:负责存储和更新模型参数。其他任务在迭代优化参数时会对这些参数发送更新。如果在单机环境下,上述 PS 和 worker 不是必须的,不需要在任务之间进行这种特定的分工,但是对于分布式训练,这种模式就是很常见的。
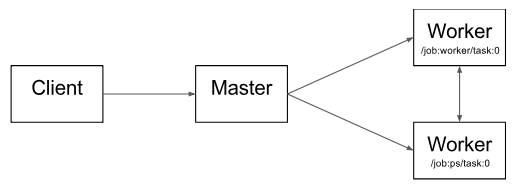
图 2
请注意,分布式主节点 Distributed Master 和工作节点服务 Worker Service 仅存在于分布式 TensorFlow 中。TensorFlow 的单进程版本包含一个特殊的 Session 实现,它可以执行分布式主服务器执行的所有操作,但只与本地进程中的设备进行通信。
下面,通过逐步处理示例图来详细介绍一下 TensorFlow 核心模块。
客户端
用户在客户端编写 TensorFlow 程序来构建计算图。该程序可以直接组成单独的操作,也可以使用 Estimators API 之类的便利库来组合神经网络层和其他更高级别的抽象概念。TensorFlow 支持多种客户端语言,我们优先考虑 Python 和 C ++,因为我们的内部用户最熟悉这些语言。随着功能的日趋完善,我们一般会将它们移植到 C ++,以便用户可以从所有客户端语言优化访问。尽管大多数训练库仍然只支持 Python,但 C ++ 确实能够支持有效的推理。
客户端创建会话,该会话将图形定义作为tf.GraphDef 协议缓冲区发送到分布式主节点。当客户端评估图中的一个或多个节点时,评估会触发对分布式主节点的调用以启动计算。
在图 3 中,客户端构建了一个图表,将权重(w)应用于特征向量(x),添加偏差项(b)并将结果保存在变量中。
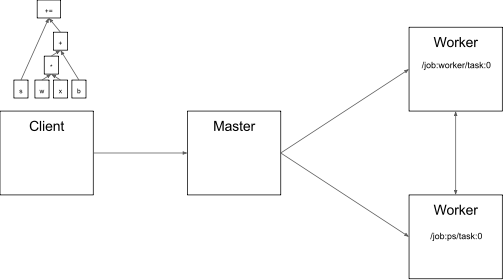
图 3
代码:
tf.Session
分布式主节点 Distributed master
分布式主节点:
基于客户端指定的节点,从完整的图形中截取所需的子图
对图表进一步进行划分,使其可以将每个图形片段映射到不同的执行设备上
以及缓存这些划分好的片段,以便在后续步骤中再次使用
由于主节点可以总揽步骤计算,因此它可以使用标准的优化方法去做优化,例如公共子表达式消除和常量的绑定。然后,对一组任务中优化后的子图或者片段执行协调。
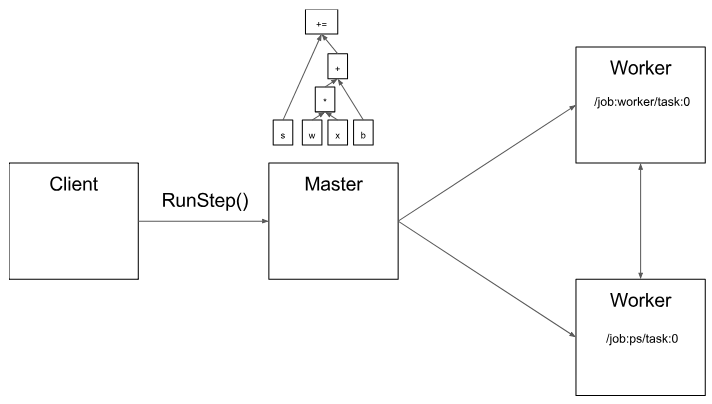
图4
图 5 显示了示例图的可能分区。分布式主节点已对模型参数进行分组,以便将它们放在参数服务器上。
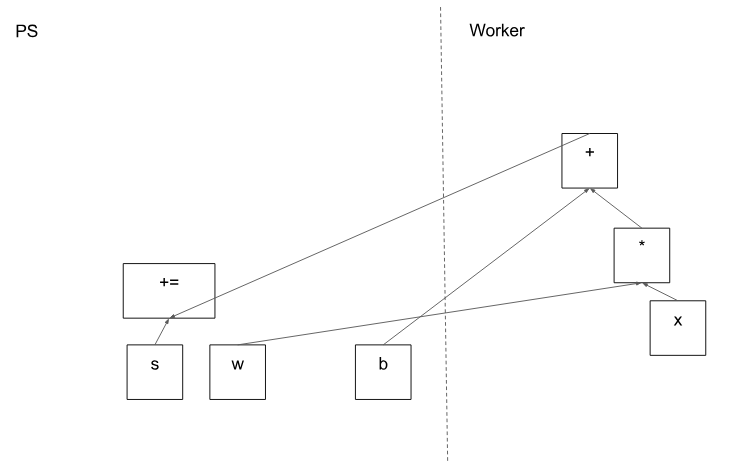
图5
在分区切割图形边缘的情况下,分布式主节点插入发送和接收节点以在分布式任务之间传递信息(图 6)。
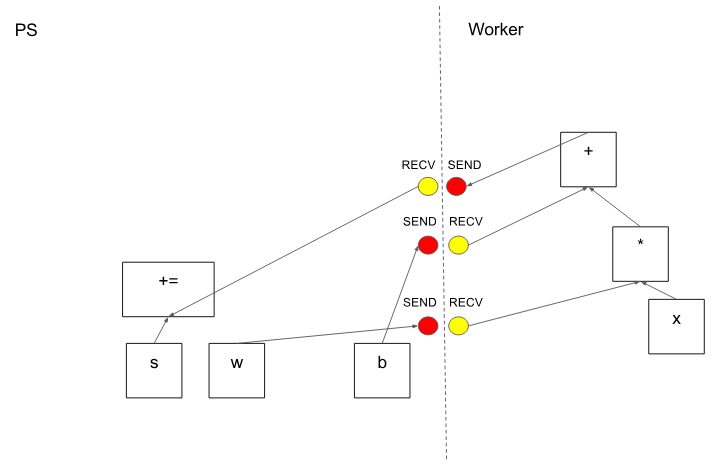
图 6
然后,分布式主节点将图形片段传送到分布式任务。
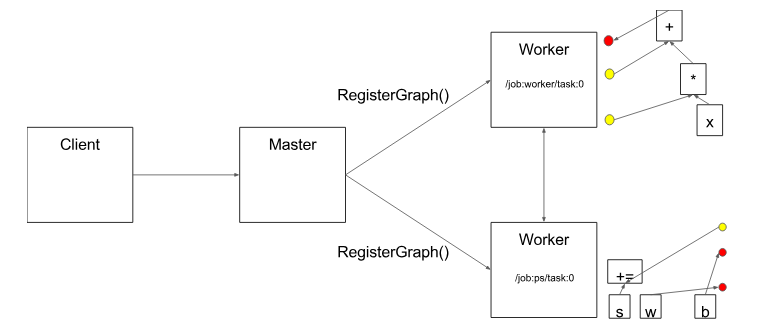
图 7
代码:
MasterService API definition
Master interface
工作节点服务 Worker Service
在每个任务中,该部分负责:
处理来自 master 发来的请求
为包含本地子图规划所需要的内核执行
协调与其他任务之间的直接信息交换
我们优化了 Worker Service,以便其以较低的负载便能够运行大型图形。当前的版本可以执行每秒上万个子图,这使得大量副本可以进行快速的,细粒度的训练步骤。Worker service 将内核分派给本地设备并在可能的情况下并行执行内核,例如通过使用多个 CPU 内核或者 GPU 流。
我们还特别针对每对源设备和目标设备类型的 Send 和 Recv 操作进行了专攻:
使用 cudaMemcpyAsync() 来进行本地 CPU 和 GPU 设备之间的重叠计算和数据传输
两个本地 GPU 之间的传输使用对等 DMA,以避免通过主机 CPU 主内存进行高负载的复制
对于任务之间的传输,TensorFlow 使用多种协议,包括:
gRPC over TCP
融合以太网上的 RDMA
另外,我们还初步支持 NVIDIA 用于多 GPU 通信的 NCCL 库
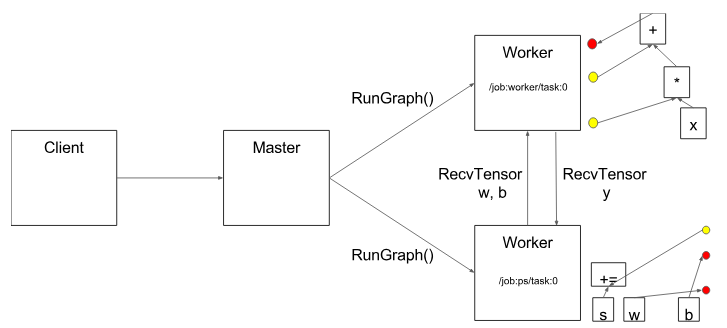
图8
代码:
WorkerService API definition
Worker interface
Remote rendezvous (for Send and Recv implementations)
内核运行
该运行时包含了 200 多个标准操作,其中涉及了数学,数组,控制流和状态管理等操作。每个操作都有对应各种设备优化后的内核运行。其中许多操作内核都是通过使用 Eigen::Tensor 实现的,它使用 C ++ 模板为多核 CPU 和 GPU 生成高效的并行代码;但是,我们可以自由地使用像 cuDNN 这样的库,就可以实现更高效的内核运行。我们还实现了 quantization 量化,可以在移动设备和高吞吐量数据中心应用等环境中实现更快的推理,并使用 gemmlowp 低精度矩阵库来加速量化计算。
如果用户发现很难去将子计算组合,或者说组合后发现效率很低,则用户可以通过注册额外的 C++ 编写的内核来提供有效的运行。例如,我们建议为一些性能的关键操作注册自己的融合内核,例如 ReLU 和 Sigmoid 激活函数及其对应的梯度等。XLA Compiler提供了一个实验性质的自动内核融合实现。
代码:
OpKernel interface
-
存储
+关注
关注
13文章
4883浏览量
90251 -
架构
+关注
关注
1文章
536浏览量
26643 -
tensorflow
+关注
关注
13文章
336浏览量
62365
原文标题:实现 TensorFlow 架构的规模性和灵活性
文章出处:【微信号:tensorflowers,微信公众号:Tensorflowers】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
探索Stellaris系列微控制器:高性能与灵活性的完美结合
80 MHz带宽IF接收器AD6677:高性能与灵活性的完美结合
慧能泰HP1010A:高灵活性数字图腾柱PFC控制器的卓越之选
AD4858数据采集系统:高精度与灵活性的完美结合
ADSP-218xN系列DSP微计算机:高性能与灵活性的完美结合
强强联合!RT-Thread助力某国产天车操作系统厂商破解晶圆厂实时性与灵活性难题|优秀案例

探索PCM510xA系列音频DAC:高性能与灵活性的完美结合
探索PCM186x-Q1音频ADC:高性能与灵活性的完美结合
TLV320ADC3140音频ADC:高性能与灵活性的完美结合
TLV320ADC6120音频ADC:高性能与灵活性的完美结合
TLV320ADC5120音频ADC:高性能与灵活性的完美结合
TAA3020音频ADC:高性能与灵活性的完美结合
深入解析 RENESAS SLG51003 PMIC:高性能与灵活性的完美结合
探索XMC7000工业微控制器:高性能与灵活性的完美结合
EtherCAT热插拔技术:提升工业自动化系统灵活性的关键




评论