 gpu加速原理
gpu加速原理

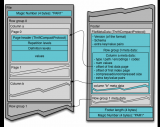
GPU一推出就包含了比CPU更多的处理单元,更大的带宽,使得其在多媒体处理过程中能够发挥更大的效能。例如:当前最顶级的CPU只有4核或者6核,模拟出8个或者12个处理线程来进行运算,但是普通级别的GPU就包含了成百上千个处理单元,高端的甚至更多,这对于多媒体计算中大量的重复处理过程有着天生的优势。下图展示了CPU和GPU架构的对比。
从硬件设计上来讲,CPU 由专为顺序串行处理而优化的几个核心组成。另一方面,GPU 则由数以千计的更小、更高效的核心组成,这些核心专为同时处理多任务而设计。
通过上图我们可以较为容易地理解串行运算和并行运算之间的区别。传统的串行编写软件具备以下几个特点:要运行在一个单一的具有单一中央处理器(CPU)的计算机上;一个问题分解成一系列离散的指令;指令必须一个接着一个执行;只有一条指令可以在任何时刻执行。而并行计算则改进了很多重要细节:要使用多个处理器运行;一个问题可以分解成可同时解决的离散指令;每个部分进一步细分为一系列指示;每个部分的问题可以同时在不同处理器上执行。
举个生活中的例子来说,你要点一份餐馆的外卖,CPU型餐馆用一辆大货车送货,每次可以拉很多外卖,但是送完一家才能到下一家送货,每个人收到外卖的时间必然很长;而GPU型餐馆用十辆小摩托车送货,每辆车送出去的不多,但是并行处理的效率高,点餐之后收货就会比大货车快很多。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
cpu
+关注
关注
68文章
11326浏览量
225876 -
gpu
+关注
关注
28文章
5271浏览量
136062
发布评论请先 登录
相关推荐
热点推荐
RK3576 单板机嵌入式 Qt 界面与多屏异显开发手册(二)
本文为创龙科技RK3576 单板机 Qt GUI 开发指南,包含环境搭建、编译调试、GPU 加速、自启动配置及多屏显示方案。提供 Qt Creator 与命令行双开发模式,覆盖界面控制、图像渲染

RK3576 单板机嵌入式 Qt 界面与多屏异显开发手册(一)
本文为创龙科技RK3576 单板机 Qt GUI 开发指南,包含环境搭建、编译调试、GPU 加速、自启动配置及多屏显示方案。提供 Qt Creator 与命令行双开发模式,覆盖界面控制、图像渲染

筑基AI4S:摩尔线程全功能GPU加速中国生命科学自主生态
精准医疗与药物研发正被人工智能深刻重塑。作为AI for Science(AI4S)领域的核心阵地,解码生命奥秘的关键已从实验观测转向算力与算法的协同突破。蛋白质结构预测、基因组分析与医学影像,构成了生命科学AI的三类关键技术,其能力直接决定了新药研发的效率与精准医疗的进程。 然而,作为这三类关键技术之一的蛋白质结构预测模型AlphaFold 3,其训练代码未完全开放,商业使用亦受限,这使得科学家难以基于该模型构建真正自主可控的研发环境。这

摩尔线程正式开源MuJoCo Warp MUSA
3月30日,摩尔线程正式开源MuJoCo Warp MUSA。这是具身智能领域首个基于MUSA架构的全功能GPU加速物理仿真后端,补齐了国产算力在强化学习仿真训练底层生态中的关键一环。

NVIDIA向Kubernetes社区捐赠动态资源分配GPU驱动程序
此外,NVIDIA 在 KubeCon Europe 大会上宣布推出适用于 GPU 加速工作负载的机密容器解决方案、NVIDIA KAI Scheduler 更新,以及用于实现大规模 AI 工作负载的全新开源项目。
Oracle和NVIDIA合作加速向量搜索和企业数据处理
Oracle 和 NVIDIA 正在与客户合作,将 GPU 加速的向量索引构建应用于实际工作负载。Oracle Private AI Services Container 初期支持 CPU 执行,现
NVIDIA携手全球工业软件巨头构建AI智能体加速设计与工程开发流程
™ 以及 GPU 加速的工业软件与工具引入 FANUC、HD 现代集团、本田、捷豹路虎、凯傲集团、梅赛德斯奔驰、联发科技、百事公司、三星、SK 海力士和 TSMC 等企业,以加速工业设计、工程开发与制造
基于NVIDIA GPU加速端点使用千问3.5 VLM开发原生多模态智能体
阿里巴巴推出了全新开源 千问3.5 系列,专为构建原生多模态智能体而设计。该系列的首个模型是一款总参数为 397B、具备推理能力的原生视觉语言模型 (VLM),基于由混合专家模型 (MoE) 和门控 Delta 网络 (Gated Delta Networks) 组成的混合架构构建。千问3.5 能够理解和导航用户界面,相较上一代 VLM 有了显著提升。
RSoft GPU加速技术重塑光子元件设计效率革命
设计效率。为了解决这个问题,RSoft 光子器件工具的 FullWAVE FDTD 模组中引入 GPU 加速,通过 NVIDIA GPU 的平行运算能力,使得模拟速度相比 CPU 计算大幅提升。

NVIDIA RTX PRO 5000 Blackwell GPU的深度评测
NVIDIA RTX PRO 5000 Blackwell 是 NVIDIA RTX 5000 Ada Generation 的升级迭代产品,其各项核心指标均针对 GPU 加速工作流的高性能

如何在NVIDIA Jetson平台上运行最新的开源AI模型
在小型、低功耗的边缘设备上运行先进的 AI 和计算机视觉工作流正变得越来越具有挑战性。机器人、智能摄像头和自主设备需要实时智能来感知、理解并做出反应,而无需依赖云端。NVIDIA Jetson 平台通过紧凑的 GPU 加速模块和专为边缘 AI 与机器人开发设计的开发套件,
沐曦股份GPU加速技术助力药物研发降本增效
沐曦股份科学计算团队近期取得突破性进展,成功将主流分子动力学模拟引擎GROMACS中的FEP计算全流程部署于GPU执行,并实现2.5倍性能提升,相关成果获得GROMACS官方团队的高度认可,该GPU
FPGA和GPU加速的视觉SLAM系统中特征检测器研究
(Nvidia Jetson Orin与AMD Versal)上最佳GPU加速方案(FAST、Harris、SuperPoint)与对应FPGA加速方案的性能,得出全新结论。

NVIDIA与合作伙伴推动物理AI发展
借助 NVIDIA RTX PRO Blackwell GPU 加速的高级蓝图、视觉语言模型和合成数据生成扩展,可提高生产力并改善各环境的安全性。
使用NVIDIA GPU加速Apache Spark中Parquet数据扫描
随着各行各业的企业数据规模不断增长,Apache Parquet 已经成为了一种主流数据存储格式。Apache Parquet 是一种列式存储格式,专为高效的大规模数据处理而设计。它按列而非按行的方式组织数据,这使得 Parquet 在查询时仅读取所需的列,而无需扫描整行数据,即可实现高性能的查询和分析。高效的数据布局使 Parquet 在现代分析生态系统中成为了受欢迎的选择,尤其是在 Apache Spark 工作负载中。



评论