 基于1.35M Instance设计的GPU加速实例
基于1.35M Instance设计的GPU加速实例

CPU是计算机的核心部件,由运算器、控制器、寄存器组和内部总线等部分组成。常见的x86架构CPU核心数相对较少,一般在8 - 32核左右,主要是为了解决复杂的逻辑运算和顺序执行指令的任务。它在处理单线程任务时效率很高,能够快速执行复杂的指令集,例如进行数学计算、程序的流程控制等操作。
GPU最初是为了图形渲染而设计的,其架构与CPU有很大不同,采用了大规模并行架构。以英伟达的CUDA架构为例,它拥有成千上万个CUDA核心,这些核心可以同时处理多个任务。例如,在深度学习中,GPU可以加速神经网络的训练过程,因为神经网络的训练涉及大量的矩阵运算,这些运算可以并行处理,GPU的并行架构能够大大缩短训练时间。近两年,GPU也成为EDA(电子设计自动化)加速的技术热点。
在数字SoC芯片的设计和实现中,为了达到功能、性能、功耗和面积目标,芯片设计者通常需要进行多轮次的迭代和优化。数字后端实现环节由于涉及的数据规模庞大且迭代次数多,基于CPU的计算耗时相当长。一般来说,一个后端设计大概需要半年左右的时间,以一个10M Instance规模的模块设计为例,基于常见的x86_64架构、16核×128CPU、2.8G主频的服务器运行数字后端各项任务,每轮时长大约为:布局(Place)75小时、时钟树综合(CTS)45小时、时钟优化(CTSopt)45小时、布线(Route)35小时、布线优化(RouteOpt)60小时。如果能够有效利用GPU的并行计算能力,将对芯片设计的加速非常有帮助。
芯行纪自主研发的新一代数字实现解决方案,通过适配GPU的环境,使用GPU为自研布局布线软件AmazeSys进行了加速,并且获得了可观的加速效果。以下是一个基于1.35M Instance设计的GPU加速实例,运行方案如下:
仅使用CPU,启用31个CPU线程
使用CPU和GPU,启用31个CPU线程和1个GPU (3584 CUDA cores)

图1:机器配置
从图2可以看到,通过启用1个GPU,placement各个主要阶段得到了5到20倍不等的加速比。
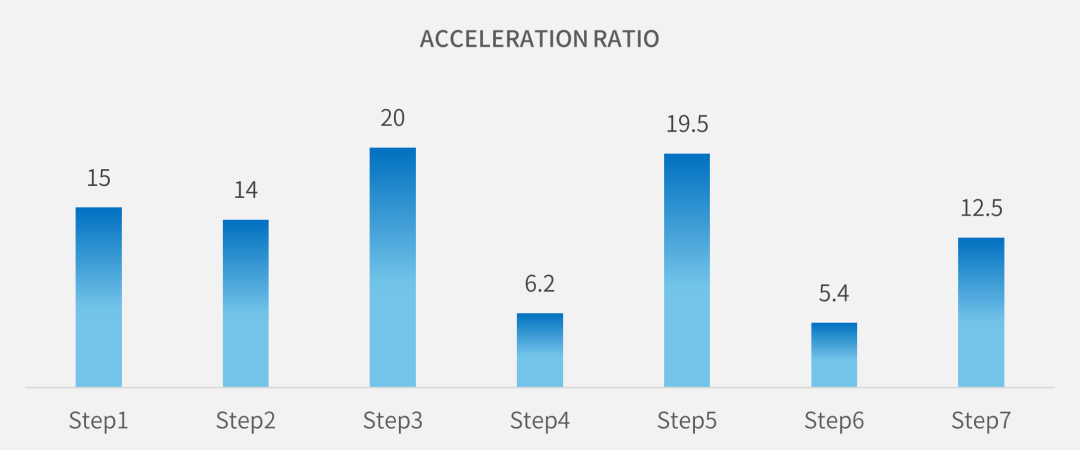
图2:Placement过程中的加速比
从图3可以看到,使用两种方案的wire length基本持平, GPU加速时虽然overflow略有增加,但总体获得了9.1倍加速的效果。并且,当GPU数量增加、性能增强,加速比也将会继续增大。
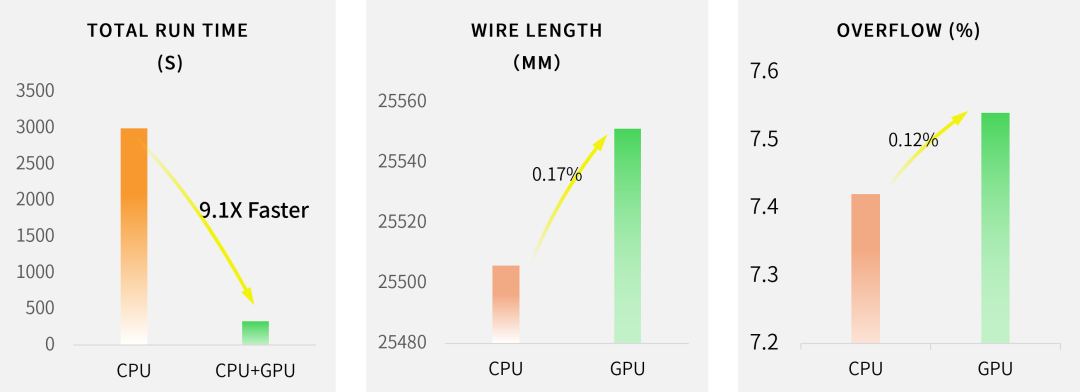
图3:使用GPU加速的结果
数字布局布线涉及的串行计算相对较多,但每一个环节只要能够有并行的可能的情况下,提前考虑算法以及GPU环境的匹配,是能够实现加速可能性的。GPU加速对数字电路的后端设计而言,属于EDA工具研发中的新挑战。芯行纪AmazeSys数字布局布线软件适配GPU硬件加速技术,为设计者缩短设计周期、加速设计创新提供了新的途径。
关于芯行纪
芯行纪科技有限公司汇聚EDA研发和技术支持精英,主营研发符合3S理念(Smart、Speedy、Simple)、包含新一代布局布线技术的数字实现EDA平台,并提供高端数字芯片设计解决方案,助力提升芯片设计效率,以科技创新推动发展新质生产力。
-
控制器
+关注
关注
114文章
17860浏览量
195018 -
gpu
+关注
关注
28文章
5259浏览量
136039 -
计算机
+关注
关注
19文章
7836浏览量
93444 -
eda
+关注
关注
72文章
3140浏览量
183665
原文标题:GPU硬件加速在数字实现EDA中的应用
文章出处:【微信号:gh_2894c3fc5359,微信公众号:芯行纪】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
《CST Studio Suite 2024 GPU加速计算指南》
GPU加速XenApp/Windows 2016/Office/IE性能会提高吗
可与NvFBC一起使用的GPU
GPU加速matlab程序
Javascript如何实现GPU加速?
算法 | 超Mask RCNN速度4倍,仅在单个GPU训练的实时实例分割算法
首个采用NVIDIA M2050 GPU的实例 开启GPU云计算下个十年
使用GPU加速RELION进行生物结构解析
OrCAD Capture CIS instance和occurrences概念解析
Oracle 云基础设施提供新的 NVIDIA GPU 加速计算实例

GPU虚拟化技术MIG简介和安装使用教程
instance是何时翻转的?每次有多少instance在翻转?




评论