 词对嵌入技术,可以改善现有模型在跨句推理上的表现
词对嵌入技术,可以改善现有模型在跨句推理上的表现

词嵌入现在已经成为任何基于深度学习的自然语言处理系统的标配组件。然而,Glockner等最近的工作(arXiv:1805.02266)表明,当前重度依赖无监督词嵌入的模型,难以学习词对之间的隐含关系。而词对之间的隐含关系,对问答(QA)、自然语言推理(NLI)之类的跨句推理至关重要。
例如,在NLI任务中,给定一个假设“打高尔夫球过于昂贵”(golf is prohibitively expensive),要推断出猜想“过去打高尔夫球很便宜”(golf is a cheap pastime),需要了解“昂贵”(expensive)和“便宜”(cheap)是反义词。而现有的基于词嵌入的模型很难学习这种关系。
有鉴于此,华盛顿大学的Mandar Joshi、Eunsol Choi、Daniel S. Weld和Facebook AI研究院的Omer Levy、Luke Zettlemoyer最近提出了词对嵌入(pair2vec)技术,可以改善现有模型在跨句推理上的表现。
词对嵌入表示
直觉
词对嵌入的直觉很简单,正如上下文隐含了单词的语义(词嵌入),上下文也为词对之间的关系提供了强力线索。
词对(斜体)及其上下文(取自维基百科)
不过,总体上来说,词对一起出现在同一上下文的频率不高。为了缓解这一稀疏性问题,pair2vec学习两个复合表示函数R(x, y)和C(c),分别编码词对和上下文。
表示
R(x,y)是一个简单的4层感知器,输入为两个词向量,以及这两个词向量的分素乘积:
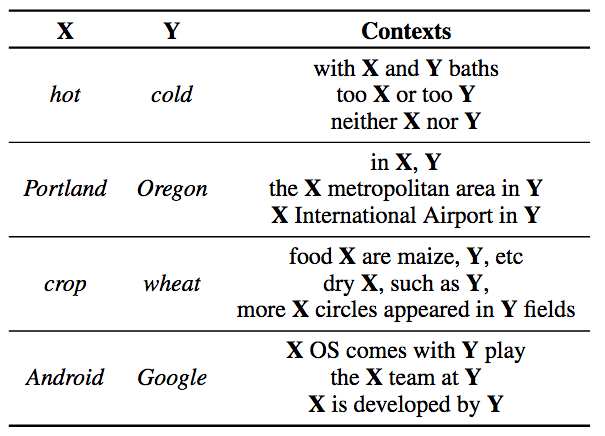
其中,x和y为经过归一化的基于共享查询矩阵Ea的嵌入:
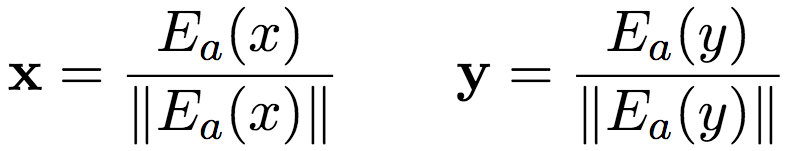
C(n)基于查询矩阵Ec嵌入每个token ci,然后将嵌入序列传入一个单层的双向LSTM,再使用注意力池化加以聚合:
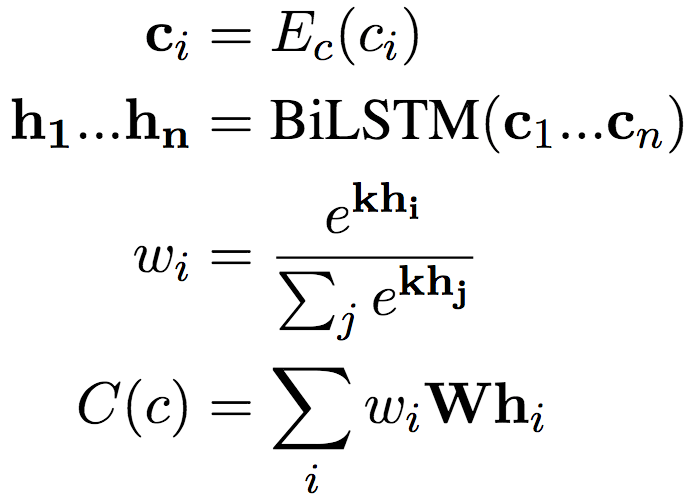
上面所有的参数,包括Ea和Ec,都是可训练的。
目标
一方面,优化目标需要使在数据中观测到的一同出现的(x, y, c)对应的R(x, y)和C(c)相似(内积较大);另一方面,又需要使词对和其他上下文不相似。当然,计算所有其他上下文和词对的相似性的算力负担太大了,因此,论文作者采用了负采样技术,转而比较随机采样的一些上下文。
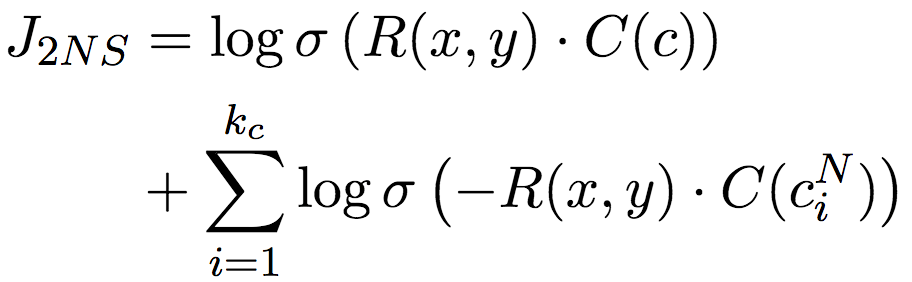
上式中的CN为随机取样的上下文。
这种做法其实和词嵌入一脉相承。词嵌入同样面临计算所有上下文(softmax)过于复杂的问题。因此,word2vec、skip-gram等词嵌入技术使用了层次softmax(使用二叉树结构保存所有词,从而大大缩减计算量)。后来Mikolov等提出,负采样可以作为层次softmax的替代方案。相比层次softmax,负采样更简单。
不过,还记得我们之前提到的词对稀疏性问题吗?这种直接借鉴词嵌入负采样的方案,也会受此影响。所以论文作者改进了负采样技术,不仅对上下文c进行负采样,还对词对中的单词x和y分别进行负采样。这一三元负采样目标,完整地捕捉了x、y、c之间的交互关系:
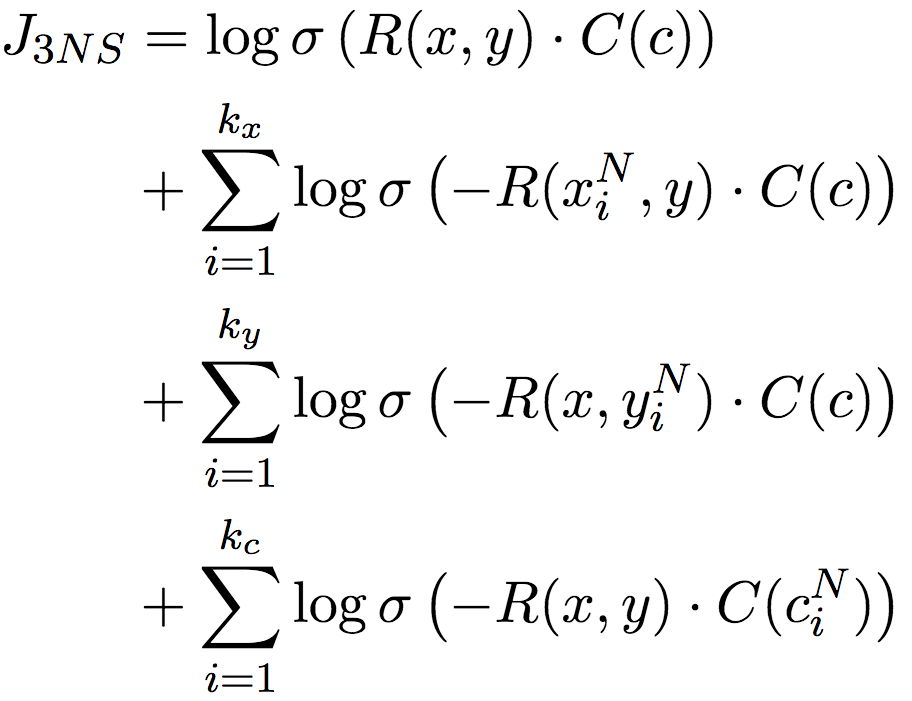
论文作者证明(见论文附录A.2),目标收敛于:
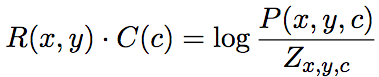
上式中,P表示分素互信息(PMI),分母Zx,y,c为边缘概率乘积的线性混合:
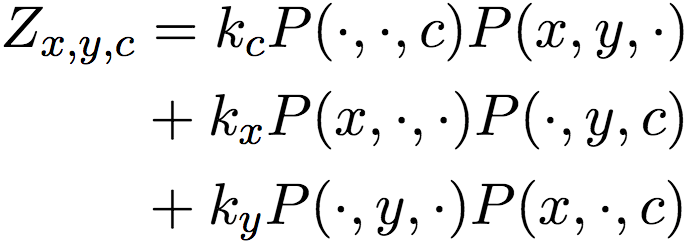
另外,负采样时,除了从均匀分布中取样外,还额外从最相似(根据余弦相似度)的100个单词中均匀取样。这一类型取样(typed sampling)方法可以鼓励模型学习具体实例间的关系。比如,使用California(加州)作为Oregon(俄勒冈州)的负样本有助于学习“X is located in Y”(X位于Y)这样的模式适用词对(Portland, Oregon)(波特兰是俄勒冈州的城市),但不适用词对(Portland, California)。
pair2vec加入推理模型
在将pair2vec加入现存跨句推理模型时,论文作者并没有用pair2vec直接替换传入编码器的词嵌入,而是通过复用跨句注意力权重,将预训练的词对表示插入模型的注意力层。
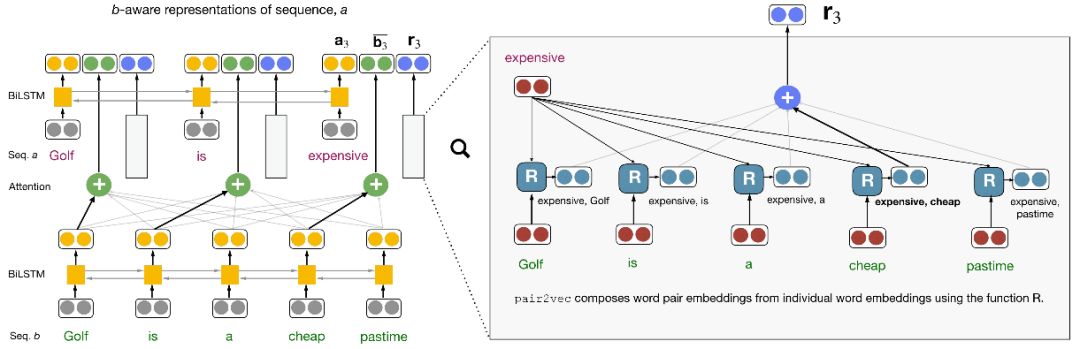
上图展示了跨句注意力模型的典型架构(左半部分)和pair2vec是如何加入这一架构的(右半部分)。简单解释一下,给定两个序列a和b,对序列a中的单词ai,模型基于双向LSTM编码ai,同时基于序列b的双向LSTM状态创建相对于ai的注意力加权表示(图中加粗的箭头表示语义对齐)。在此基础上,加上注意力加权的词对表示ri(ai, b)。
试验
数据
论文作者使用了2018年1月的维基百科数据,其中包含九千六百万句子。基于词频限制词汇量至十万(预处理阶段移除)。在经过预处理的语料库上,论文作者考虑了窗口大小5以内的所有词对,并基于词对概率(阈值为5 × 10-7)降采样实例。降采样可以压缩数据集大小以加速训练,word2vec等词嵌入也采用降采样。上下文从词对左边的一个单词开始,到词对右边的一个单词为止。另外,论文作者用X和Y替换了上下文中的词对。
超参数
词对和上下文均使用基于FastText初始化的300维词嵌入。上下文表示使用的单层双向LSTM的隐藏层尺寸为100. 每个词对-上下文元组使用2个上下文负样本和3个增强负样本。
预训练使用随机梯度下降,初始学习率为0.01,如果损失在30万步后没有下降,那么将学习率缩小至原学习率的10%。batch大小为600。预训练了12个epoch(在Titan X GPU上,预训练需要一周)。
任务模型均使用AllenNLP的实现,超参数取默认值。在插入pair2vec前后没有改动任何设置。预训练的词对嵌入使用0.15的dropout.
问答任务
在SQuAD 2.0上的试验表明,pair2vec提升了2.72 F1. 对抗SQuAD数据集上的试验说明pair2vec同时加强了模型的概括性(F1分别提升7.14和6.11)。
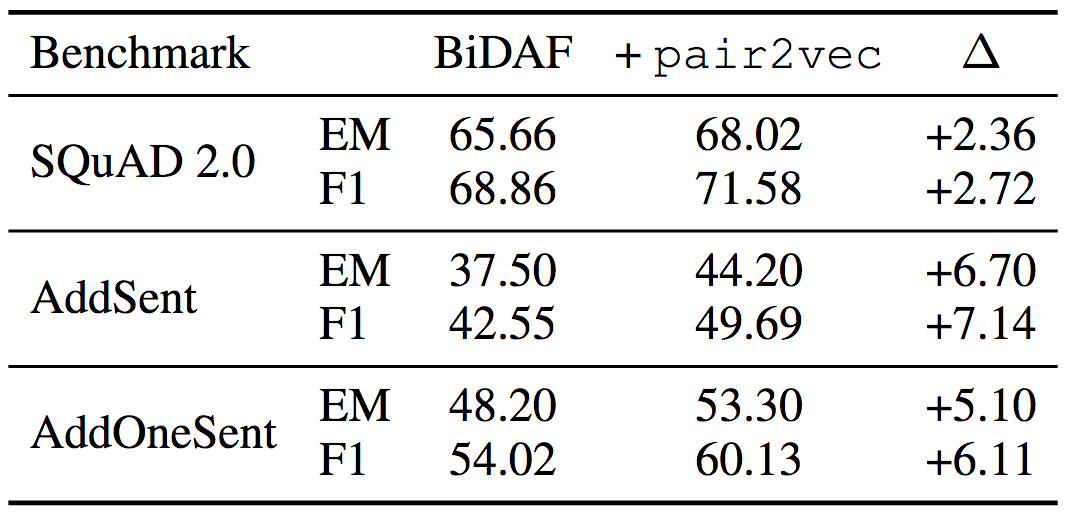
均使用ELMo词嵌入
自然语言推理
在MultiNLI数据集上,加入pair2vec后,ESIM + ELMo的表现提升了1.3.

Glockner等提出了一个领域外NLI测试集( arXiv:1805.02266),说明除了使用WordNet特征的KIM外,多个NLI模型在比SNLI更简单的新测试集上的表现反而要差不少,说明这些模型的概括性有问题。而加入pair2vec后的ESIM + ELMo模型达到了当前最先进水平,刷新了记录。
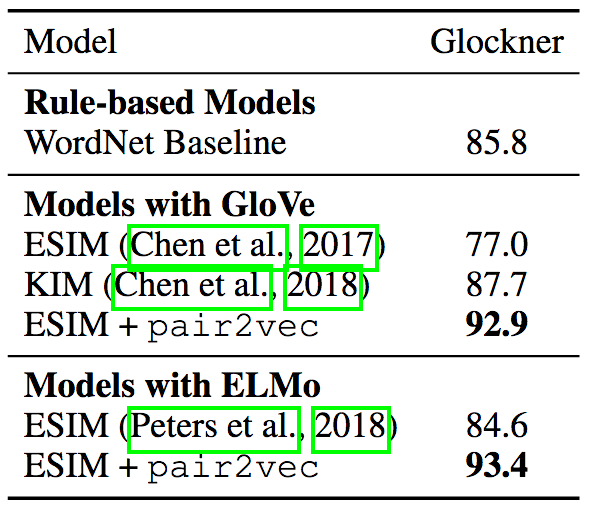
顺便提下,KIM的做法是现有研究中最接近pair2vec的。KIM同样在ESIM模型中加入了词对向量,但是它的词对向量是基于WordNet手工编码得到的。而pair2vec使用的是无监督学习,因此可以反映WordNet中不存在的关系(例如个人-职业),以及WordNet中没有直接联系的词对(例如,bronze(青铜)与statue(塑像))。
词类比
为了揭示pair2vec加入的额外信息是什么,pair2vec能够更好地捕捉哪类联系,论文作者在词类比数据集上进行了试验。
词类比任务是指,给定词对(a, b)和单词x,预测满足a : b :: x : y的单词y。论文作者使用的是BATS数据集,该数据集包括四种关系:
百科语义(encyclopedic semantics),例如Einstein-physicist(爱因斯坦-物理学家)这样的个人-职业关系。
词典语义(lexicographic semantics),例如cheap-expensive(廉价-昂贵)这样的反义词。
派生形态(derivational morphology),例如oblige(动词,迫使)与obligation(名词,义务)。
屈折形态(inflectional morphology),例如bird-birds(鸟的单数形式和复数形式)。
每种关系各包含10个子类别。
之前我们说过,词类比任务是要预测满足a : b :: x : y的单词y,而相关词嵌入的差很大程度上能够反映相似关系,例如,queen(后) - king(王) ≈ woman(女) - man(男)很大程度上意味着queen : king :: woman : man。所以,词类比问题可以通过优化cos(b - a + x, y)求解(cos表示余弦相似度,a、b、x、y为词嵌入)。这一方法一般称为3CosAdd法。
论文作者在3CosAdd中加入了pair2vec,得到α·cos(ra,b, rx,y) + (1-α)·cos(b - a + x, y)。其中r表示pair2vec嵌入,α为线性插值系数,α=0时等价于原3CosAdd法,α=1等价于pair2vec。
下图显示了在FastText中插入pair2vec的结果,黄线表示派生形态,棕线表示词典语义,绿线表示屈折形态,蓝线表示百科语义。
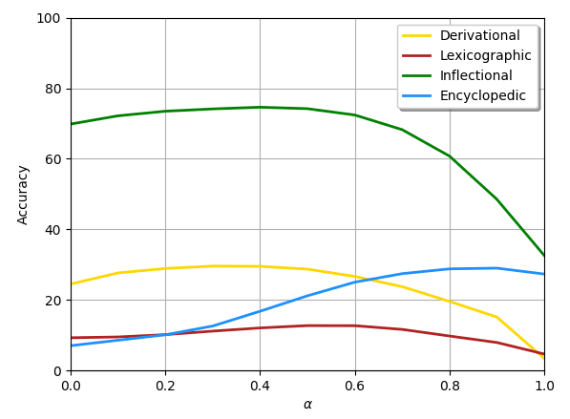
我们可以看到,在所有四个类别上,在3CosAdd上增加pair2vec都取得了显著的提升,其中百科语义(356%)和词典语义(51%)提升尤为突出。
下表显示了提升最明显的10个子类别,α*为最优插值参数。
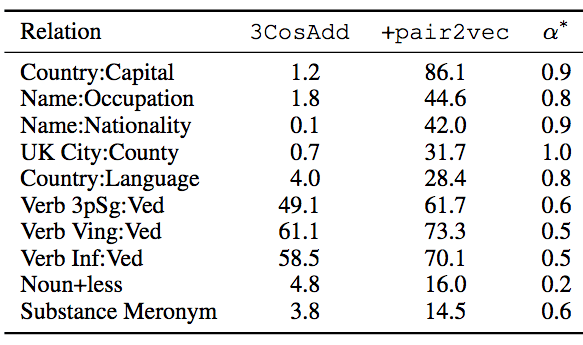
从上表我们可以看到,在FastText嵌入提供的信号十分有限的关系上,提升尤为显著。论文作者还观察到,某些情形下pair2vec和FastText存在协同效应,比如,noun+less关系中,3CosAdd原本评分为4.8,pair2vec自身评分为0,但3CosAdd加上pair2vec后,评分为16。
填槽
为了进一步探索pair2vec如何编码补充信息,论文作者尝试了填槽(slot filling)任务:给定Hearst式的上下文模式c、单词x,预测取自整个词汇表的单词y。候选单词y的排序基于训练目标R(x,y)·C(c)的评分函数,采用固定的关系样本,并手工定义上下文模式和一小组候选词x。
下表显示了评分最高的三个y单词。
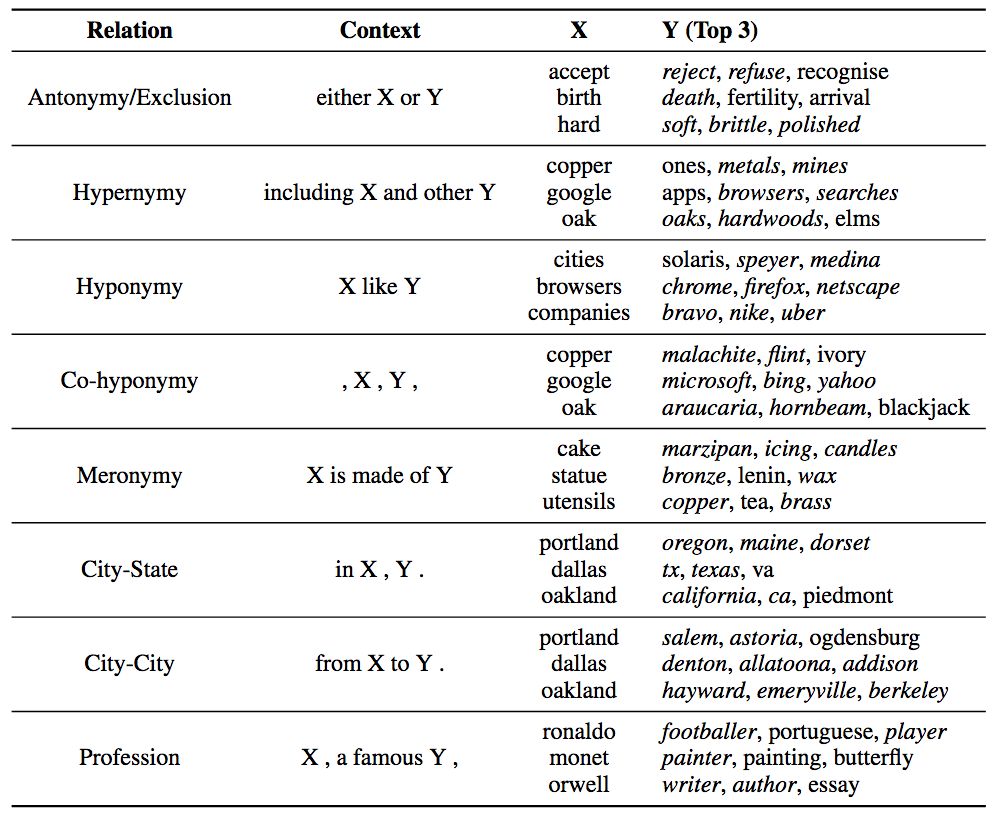
斜体表示正确匹配
上表说明,pair2vec可以捕捉词对和上下文间的三边关系,而不仅仅是单个单词和上下文之间的双边关系(词嵌入)。这一巨大差别使pair2vec可以为词嵌入补充额外信息。
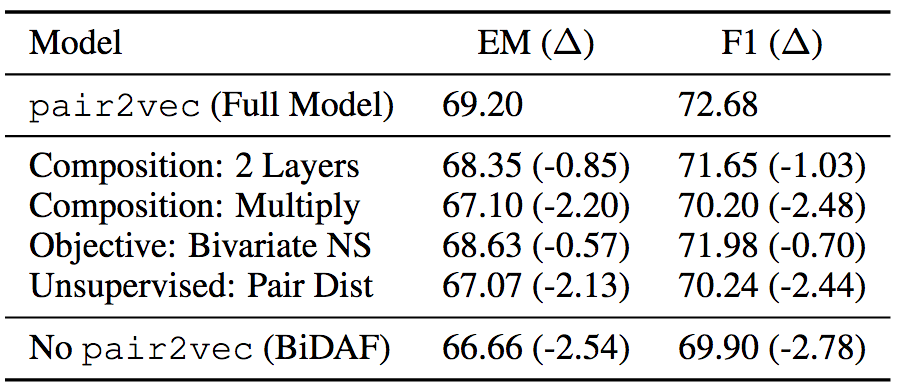
消融测试
为了验证pair2vec各组件的有效性,论文作者也在SQuAD 2.0的训练集上做了消融测试。消融测试表明,增强采样和使用较深的复合函数效果显著。
结语
pair2vec基于复合函数表示,有效缓解了词对的稀疏性问题。基于无监督学习预训练的pair2vec,能够为词嵌入补充信息,从而提升跨句推理模型的表现。
-
编码器
+关注
关注
45文章
4013浏览量
143470 -
深度学习
+关注
关注
73文章
5610浏览量
124656 -
自然语言处理
+关注
关注
1文章
630浏览量
14737
原文标题:pair2vec 基于复合词对嵌入加强跨句推理模型
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
【大语言模型:原理与工程实践】揭开大语言模型的面纱
【大语言模型:原理与工程实践】大语言模型的基础技术
大语言模型:原理与工程时间+小白初识大语言模型
大模型推理显存和计算量估计方法研究
构建词向量模型相关资料分享
压缩模型会加速推理吗?
AscendCL快速入门——模型推理篇(上)
HarmonyOS:使用MindSpore Lite引擎进行模型推理
LLM大模型推理加速的关键技术

摩尔线程宣布成功部署DeepSeek蒸馏模型推理服务
LLM推理模型是如何推理的?




评论