 强化学习中如何高效地与环境互动?如何从经验中高效学习?
强化学习中如何高效地与环境互动?如何从经验中高效学习?

强化学习中很多重要的难题都围绕着两个问题:我们应该如何高效地与环境互动?如何从经验中高效学习?在这篇文章中,我想对最近的深度强化学习研究做一些调查,找到解决这两个问题的方法,其中主要会讲到三部分:
分层强化学习
记忆和预测建模
有模型和无模型方法的结合
首先我们快速回顾下DQN和A3C这两种方法,之后会深入到最近的几篇论文中,看看它们在这一领域做出了怎样的贡献。

回顾DQN和A3C/A2C
DeepMind的深度Q网络(DQN)是深度学习应用到强化学习中实现的第一个重大突破,它利用一个神经网络学习Q函数,来玩经典雅达利游戏,例如《乓》和《打砖块》,模型可以直接将原始的像素输入转化成动作。
从算法上来说,DQN直接依赖经典的Q学习技术。在Q学习中,动作对的Q值,或者说“质量”,是根据基于经验的迭代更新来估计的。从本质上说,在每个状态采取的行动,我们都能利用接收到的实时奖励和新状态的价值来更新原始状态动作对的价值估计。
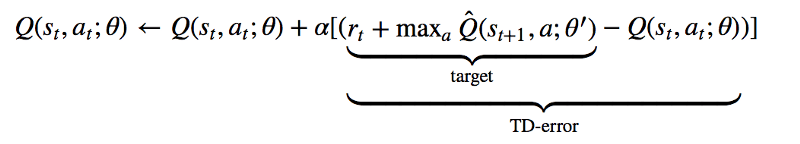
除此之外,DeepMind的A3C(Asynchronous Advantage Actor Critic)和OpenAI的变体A2C,对actor-critic方法来说都是非常成功的深度学习方法。
Actor-critic方法结合了策略梯度方法和学习价值函数。只用DQN,我们只能得到学习价值函数(Q函数),我们跟随的“策略”也只是简单的在每一步将Q值达到最大的动作。有了A3C和其他actor-critic方法,我们学习两种不同的函数:策略(或者“演员”)和价值(或者“评委”)。基于当前估计的优点,策略会调整动作的概率,价值函数也会更新基于经验和奖励的优势。策略如下:

可以看到,降至网络学习了一个基准状态值V(si;θv),有了它我们可以将目前的奖励估计R和得到的优点相比较,策略网络会根据这些优点用经典强化算法调整对数几率。
A3C之所以这么受欢迎,主要原因是它结构的平行和不同步性,具体结构不是本文重点讨论的内容,感兴趣的读者可以查看DeepMind的IMPALA论文。
DQN和A3C/A2C都是强大的基准智能体,但遇到复杂问题时,它们并不那么好用,比如可能观察补全或者在动作和奖励信号之间有延迟。所以,强化学习领域的研究者们一直致力于解决这些问题。
分层强化学习
分层强化学习是强化学习方法的一种,它从策略的多个图层中学习,每一层都负责控制不同时间下的动作。策略的最下一层负责输出环境动作,上面几层可以完成其他抽象的目标。
为什么这种方法如此受欢迎呢?首先,从认知角度来看,长久以来的研究都表示,人类和动物的行为都是有组织的。例如,当我们想做饭的时候,我会把这一任务分成好几部分完成:洗菜、切菜、烧水煮面等等。我还可以把其中的某一小任务进行替换,比如把煮面换成蒸米饭,也能完成做好一顿饭的总任务。这就说明现实世界中的任务内部是有结构的。
从技术层面来说,分层强化学习能帮助解决上述提到的第二个问题,即如何从经验中高效地学习,解决方法就是通过长期信用分配和稀疏奖励信号。在分层强化学习中,由于低层次的策略是从高层次策略分布的任务所得到的内部奖励学习的,即使奖励稀疏,也可以学到其中的小任务。另外,高层次策略生成的时间抽象可以让我们的模型处理信用分配。
说到具体工作原理,实施分层强化学习的方法有很多。最近,谷歌大脑团队的一篇论文就采取了一种简易方法,他们的模型称为HIRO。

核心思想如下:我们有两个策略层,高层策略训练的目的是为了让环境奖励R实现最大化。每一步后,高层策略都会对新动作进行采样。低层策略训练的目的是为了采取环境行动,生成与给定的目标状态相似的状态。
训练低层策略时,HIRO用的是深度确定性策略梯度(DDPG)的变体,它的内部奖励是将目前得到的观察和目标观察之间的距离进行参数化:

DDPG是另一种开创新的深度强化学习算法,它将DQN的思想扩展到了持续动作空间中。他也是另一种actor-critic方法,使用策略梯度来优化策略。
不过,HIRO绝不是唯一的分层强化学习方法。FeUdal网络出现的时间更早,它将经过学习的“目标”表示作为输入,而不是原始状态的观察。另外还有很多方法需要一定程度的手动操作或领域知识,这就限制了其泛化能力。我个人比较喜欢的最近的一项研究成果是基于人口的训练(PBT),其中他们将内部奖励看作额外的超参数,PBT在训练时人口“增长”的过程中对这些超参数进行优化。
如今,分层强化学习是非常火热的研究对象,虽然它的核心是非常直观的,但它可扩展、多任务并行、能解决强化学习中的许多基础性问题。
存储和注意力
现在让我们谈谈另外能解决长期信用分配和稀疏奖励信号问题的方法。通俗点说,我们想知道智能体如何能擅长记忆。
深度学习中的记忆总是非常有趣,科学家们经历了千辛万苦,也很难找到一种结构能打败经过良好调校的LSTM。但是,人类的记忆机制可不像LSTM。当我们从家开车去超市时,回想的都是原来走过几百次的路线记忆,而不是怎么从伦敦的一个城市到另一个城市的路线。所以说,我们的记忆是根据情景可查询的,它取决于我们在哪里、在干什么,我们的大脑知道哪部分记忆对现在有用。
在深度学习中,Neural Turing Machine是外部、关键信息存储方面论文的标杆,这也是我最喜欢的论文之一,它提出通过向量值“读取”和“写入”特定位置,利用可区分的外部存储器对神经网络进行增强。如果把它用在强化学习上会怎样?这就是最近的MERLIN结构的思想。
MERLIN有两个组成部分:基于记忆的预测器(MBP)和一个策略网络。MBP负责将观察压缩成有用的、低维的“状态变量”,将它们直接储存在关键的记忆矩阵中。
整个过程如下:对输入观察进行编码,并将其输入到MLP中,输出结果被添加到先验分布中,生成后验分布。接着,后验分布经过采样,生成一个状态变量zt。接着,zt输入到MBP的LSTM网络中,输出结果用来更新先验,并且进行读取或书写。最后,策略网络运用z_t和读取输出生成一个动作。
关键细节在与,为了保证状态表示时有用的,MBP同样经过训练需要预测当前状态下的奖励,所以学习到的表示和目前的任务要相关。
不过,MERLIN并不是唯一使用外部存储器的深度强化学习网络,早在2016年,研究者就在一个记忆Q网络中运用了这一方法,来解决Minecraft中的迷宫问题。不过这种将存储用作预测模型的方法有一些神经科学上的阻碍。
MERLIN的基于存储的预测器对所有观察进行编码,将它们与内部先验结合,生成一个“状态变量”,可以捕捉到一些表示,并将这些状态存储到长期记忆中,让智能体在未来可以做出相应的动作。
智能体、世界模型和想象力
在传统强化学习中,我们可以做无模型学习,也可以做基于模型的学习。在无模型的强化学习中,我们学着将原始环境观察直接映射到某个值或动作上。在基于模型的强化学习中,我们首先会学习一个基于原始观察的过渡模型,然后用这个模型来选择动作。

能在模型上进行计划比单纯的试错法更高效,但是,学习一个好的模型通常很困难,所以早期很多深度强化学习的成功都是无模型的(例如DQN和A3C)。
这就表示,无模型和有模型的强化学习之间的界线很模糊。现在,一种新的“Imagination-augmented Agents”算法出现了,将这两种方法结合了起来。
在Imagination-Augmented Agents(I2A)中,最终策略是一个无模型模块和有模型模块并存的函数。有模型的模块可以看做智能体对环境的“想象”,其中包含了智能体内部想象的活动轨迹。但是,关键是有模型模块在终点处有一个编码器,它可以聚集想象轨迹,并将它们进行编译,让智能体在必要的时候忽略那些想象。所以,当智能体发现它的内部模型在进行无用或不精确的想象时,它可以学习忽略模型,用无模型部分继续工作。
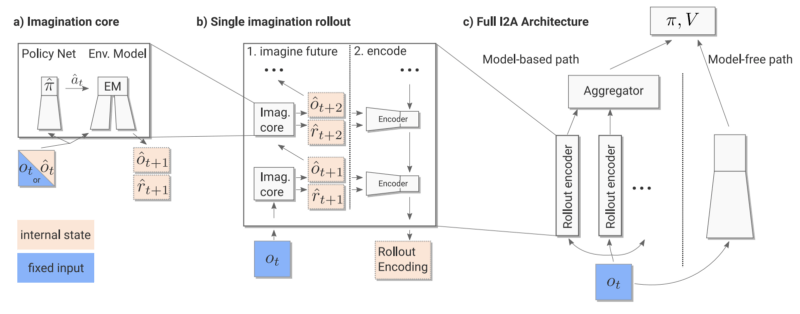
I2A的工作流程
和A3C以及MERLIN类似,该策略也是通过一个标准策略梯度损失进行训练,如下:

I2A之所以如此受欢迎的原因之一是,在某些情况下,这也是我们在现实中处理情况的方法。我们总是根据所处的环境下,目前的精神想法对未来做计划和预测,但我们知道,我们的精神模型可能不完全准确,尤其是当我们来到一个陌生环境中时。在这种情况下,我们就会进行试错法,就像无模型方法一样,但同时我们还会利用这一段新体验对内在精神环境进行更新。
除此之外,还有很多研究结合了有模型和无模型两种方法,例如伯克利的Temporal Difference Model等,这些研究论文都有着相同目标,即达到像无模型方法一样的性能,同时具有和基于模型方法相同的高效采样率。
结语
深度强化学习模型非常难以训练,但是正是因为这样的难度,我们想到了如此多种的解决方案。这篇文章只是对深度强化学习的不完全调查,除了本文提到了方法,还有很多针对深度强化学习的解决方案。但是希望文中所提到的关于记忆、分层和想象的方法对该领域中所遇到的挑战和瓶颈有所帮助。最后,Happy RL hacking!
-
函数
+关注
关注
3文章
4422浏览量
67855 -
深度学习
+关注
关注
73文章
5608浏览量
124637 -
强化学习
+关注
关注
4文章
273浏览量
11998
原文标题:除了DQN/A3C,还有哪些高级强化学习成果
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
上汽奥迪E5 Sportback车型升级搭载全新Momenta强化学习大模型
上汽大众ID. ERA 9X全球首发搭载Momenta R7强化学习世界模型
Momenta R6强化学习大模型上车东风日产NX8
Momenta强化学习大模型助力别克至境世家纯电版正式上市
Momenta R7强化学习世界模型即将推出
自动驾驶中常提的离线强化学习是什么?

强化学习会让自动驾驶模型学习更快吗?

多智能体强化学习(MARL)核心概念与算法概览

上汽别克至境E7首发搭载Momenta R6强化学习大模型
今日看点:智元推出真机强化学习;美国软件公司SAS退出中国市场
自动驾驶中常提的“强化学习”是个啥?

如何在Ray分布式计算框架下集成NVIDIA Nsight Systems进行GPU性能分析
FPGA在机器学习中的具体应用
NVIDIA Isaac Lab可用环境与强化学习脚本使用指南




评论