 朴素贝叶斯分类算法并实现中文数据集的舆情分析案例
朴素贝叶斯分类算法并实现中文数据集的舆情分析案例

本文主要讲述朴素贝叶斯分类算法并实现中文数据集的舆情分析案例,希望这篇文章对大家有所帮助,提供些思路。内容包括:
1.朴素贝叶斯数学原理知识
2.naive_bayes用法及简单案例
3.中文文本数据集预处理
4.朴素贝叶斯中文文本舆情分析
本篇文章为基础性文章,希望对你有所帮助,如果文章中存在错误或不足之处,还请海涵。同时,推荐大家阅读我以前的文章了解基础知识。
▌一. 朴素贝叶斯数学原理知识
该基础知识部分引用文章"机器学习之朴素贝叶斯(NB)分类算法与Python实现"(https://blog.csdn.net/moxigandashu/article/details/71480251),也强烈推荐大家阅读博主moxigandashu的文章,写得很好。同时作者也结合概率论讲解,提升下自己较差的数学。
朴素贝叶斯(Naive Bayesian)是基于贝叶斯定理和特征条件独立假设的分类方法,它通过特征计算分类的概率,选取概率大的情况,是基于概率论的一种机器学习分类(监督学习)方法,被广泛应用于情感分类领域的分类器。
下面简单回顾下概率论知识:
1.什么是基于概率论的方法?
通过概率来衡量事件发生的可能性。概率论和统计学是两个相反的概念,统计学是抽取部分样本统计来估算总体情况,而概率论是通过总体情况来估计单个事件或部分事情的发生情况。概率论需要已知数据去预测未知的事件。
例如,我们看到天气乌云密布,电闪雷鸣并阵阵狂风,在这样的天气特征(F)下,我们推断下雨的概率比不下雨的概率大,也就是p(下雨)>p(不下雨),所以认为待会儿会下雨,这个从经验上看对概率进行判断。而气象局通过多年长期积累的数据,经过计算,今天下雨的概率p(下雨)=85%、p(不下雨)=15%,同样的 p(下雨)>p(不下雨),因此今天的天气预报肯定预报下雨。这是通过一定的方法计算概率从而对下雨事件进行判断。
2.条件概率
若Ω是全集,A、B是其中的事件(子集),P表示事件发生的概率,则条件概率表示某个事件发生时另一个事件发生的概率。假设事件B发生后事件A发生的概率为:
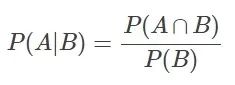
设P(A)>0,则有 P(AB) = P(B|A)P(A) = P(A|B)P(B)。
设A、B、C为事件,且P(AB)>0,则有 P(ABC) = P(A)P(B|A)P(C|AB)。
现在A和B是两个相互独立的事件,其相交概率为 P(A∩B) = P(A)P(B)。
3.全概率公式
设Ω为试验E的样本空间,A为E的事件,B1、B2、....、Bn为Ω的一个划分,且P(Bi)>0,其中i=1,2,...,n,则:

P(A) = P(AB1)+P(AB2)+...+P(ABn)
= P(A|B1)P(B1)+P(A|B2)P(B2)+...+P(A|Bn)P(Bn)
全概率公式主要用途在于它可以将一个复杂的概率计算问题,分解为若干个简单事件的概率计算问题,最后应用概率的可加性求出最终结果。
示例:有一批同一型号的产品,已知其中由一厂生成的占30%,二厂生成的占50%,三长生成的占20%,又知这三个厂的产品次品概率分别为2%、1%、1%,问这批产品中任取一件是次品的概率是多少?
参考百度文库资料:
https://wenku.baidu.com/view/05d0e30e856a561253d36fdb.html
4.贝叶斯公式
设Ω为试验E的样本空间,A为E的事件,如果有k个互斥且有穷个事件,即B1、B2、....、Bk为Ω的一个划分,且P(B1)+P(B2)+...+P(Bk)=1,P(Bi)>0(i=1,2,...,k),则:
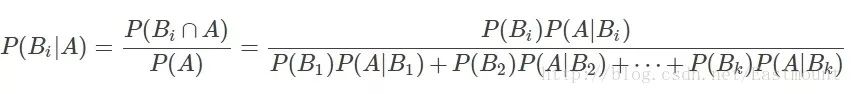
P(A):事件A发生的概率;
P(A∩B):事件A和事件B同时发生的概率;
P(A|B):事件A在时间B发生的条件下发生的概率;
意义:现在已知时间A确实已经发生,若要估计它是由原因Bi所导致的概率,则可用Bayes公式求出。
5.先验概率和后验概率
先验概率是由以往的数据分析得到的概率,泛指一类事物发生的概率,根据历史资料或主观判断未经证实所确定的概率。后验概率而是在得到信息之后再重新加以修正的概率,是某个特定条件下一个具体事物发生的概率。

6.朴素贝叶斯分类
贝叶斯分类器通过预测一个对象属于某个类别的概率,再预测其类别,是基于贝叶斯定理而构成出来的。在处理大规模数据集时,贝叶斯分类器表现出较高的分类准确性。
假设存在两种分类:
1) 如果p1(x,y)>p2(x,y),那么分入类别1
2) 如果p1(x,y)
引入贝叶斯定理即为:
其中,x、y表示特征变量,ci表示分类,p(ci|x,y)表示在特征为x,y的情况下分入类别ci的概率,因此,结合条件概率和贝叶斯定理有:
1) 如果p(c1|x,y)>p(c2,|x,y),那么分类应当属于类别c1
2) 如果p(c1|x,y)
贝叶斯定理最大的好处是可以用已知的概率去计算未知的概率,而如果仅仅是为了比较p(ci|x,y)和p(cj|x,y)的大小,只需要已知两个概率即可,分母相同,比较p(x,y|ci)p(ci)和p(x,y|cj)p(cj)即可。
7.示例讲解
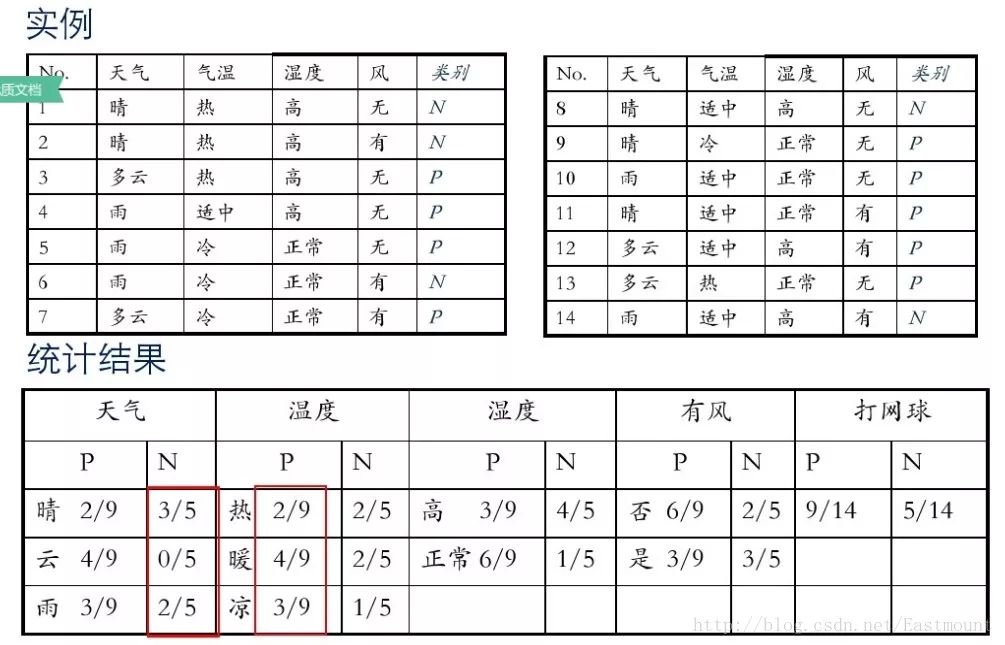
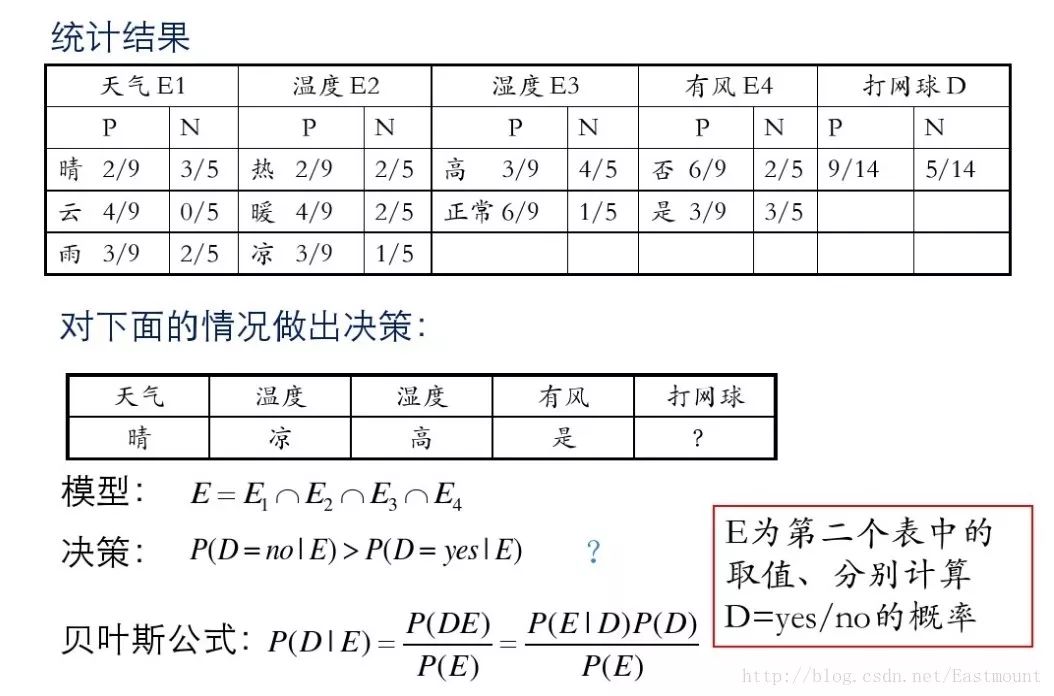
假设存在14天的天气情况和是否能打网球,包括天气、气温、湿度、风等,现在给出新的一天天气情况,需要判断我们这一天可以打网球吗?首先统计出各种天气情况下打网球的概率,如下图所示。
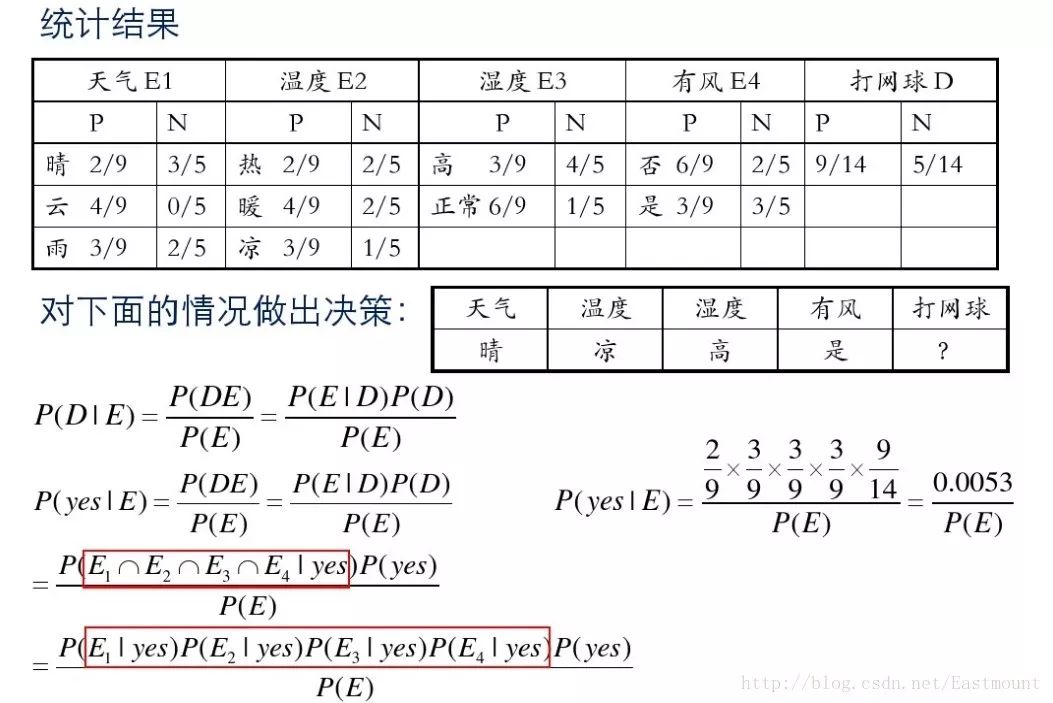
接下来是分析过程,其中包括打网球yse和不打网球no的计算方法。
最后计算结果如下,不去打网球概率为79.5%。
8.优缺点
监督学习,需要确定分类的目标
对缺失数据不敏感,在数据较少的情况下依然可以使用该方法
可以处理多个类别 的分类问题
适用于标称型数据
对输入数据的形势比较敏感
由于用先验数据去预测分类,因此存在误差
▌二. naive_bayes用法及简单案例
scikit-learn机器学习包提供了3个朴素贝叶斯分类算法:
GaussianNB(高斯朴素贝叶斯)
MultinomialNB(多项式朴素贝叶斯)
BernoulliNB(伯努利朴素贝叶斯)
1.高斯朴素贝叶斯
调用方法为:sklearn.naive_bayes.GaussianNB(priors=None)。
下面随机生成六个坐标点,其中x坐标和y坐标同为正数时对应类标为2,x坐标和y坐标同为负数时对应类标为1。通过高斯朴素贝叶斯分类分析的代码如下:
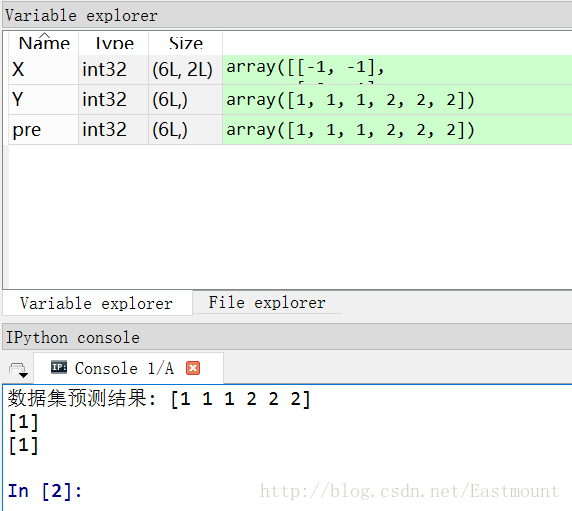
1#-*-coding:utf-8-*- 2importnumpyasnp 3fromsklearn.naive_bayesimportGaussianNB 4X=np.array([[-1,-1],[-2,-1],[-3,-2],[1,1],[2,1],[3,2]]) 5Y=np.array([1,1,1,2,2,2]) 6clf=GaussianNB() 7clf.fit(X,Y) 8pre=clf.predict(X) 9printu"数据集预测结果:",pre10printclf.predict([[-0.8,-1]])1112clf_pf=GaussianNB()13clf_pf.partial_fit(X,Y,np.unique(Y))#增加一部分样本14printclf_pf.predict([[-0.8,-1]])
输出如下图所示,可以看到[-0.8, -1]预测结果为1类,即x坐标和y坐标同为负数。
2.多项式朴素贝叶斯
多项式朴素贝叶斯:sklearn.naive_bayes.MultinomialNB(alpha=1.0, fit_prior=True, class_prior=None)主要用于离散特征分类,例如文本分类单词统计,以出现的次数作为特征值。
参数说明:alpha为可选项,默认1.0,添加拉普拉修/Lidstone平滑参数;fit_prior默认True,表示是否学习先验概率,参数为False表示所有类标记具有相同的先验概率;class_prior类似数组,数组大小为(n_classes,),默认None,类先验概率。
3.伯努利朴素贝叶斯
伯努利朴素贝叶斯:sklearn.naive_bayes.BernoulliNB(alpha=1.0, binarize=0.0, fit_prior=True,class_prior=None)。类似于多项式朴素贝叶斯,也主要用于离散特征分类,和MultinomialNB的区别是:MultinomialNB以出现的次数为特征值,BernoulliNB为二进制或布尔型特性
下面是朴素贝叶斯算法常见的属性和方法。
1) class_prior_属性
观察各类标记对应的先验概率,主要是class_prior_属性,返回数组。代码如下:
1printclf.class_prior_2#[0.50.5]
2) class_count_属性
获取各类标记对应的训练样本数,代码如下:
1printclf.class_count_2#[3.3.]
3) theta_属性
获取各个类标记在各个特征上的均值,代码如下:
1printclf.theta_2#[[-2.-1.33333333]3#[2.1.33333333]]
4) sigma_属性
获取各个类标记在各个特征上的方差,代码如下:
1printclf.theta_2#[[-2.-1.33333333]3#[2.1.33333333]]
5) fit(X, y, sample_weight=None)
训练样本,X表示特征向量,y类标记,sample_weight表各样本权重数组。
1#设置样本不同的权重2clf.fit(X,Y,np.array([0.05,0.05,0.1,0.1,0.1,0.2,0.2,0.2]))3printclf4printclf.theta_5printclf.sigma_
输出结果如下所示:
1GaussianNB()2[[-2.25-1.5]3[2.251.5]]4[[0.68750.25]5[0.68750.25]]
6) partial_fit(X, y, classes=None, sample_weight=None)
增量式训练,当训练数据集数据量非常大,不能一次性全部载入内存时,可以将数据集划分若干份,重复调用partial_fit在线学习模型参数,在第一次调用partial_fit函数时,必须制定classes参数,在随后的调用可以忽略。
1importnumpyasnp 2fromsklearn.naive_bayesimportGaussianNB 3X=np.array([[-1,-1],[-2,-2],[-3,-3],[-4,-4],[-5,-5], 4[1,1],[2,2],[3,3]]) 5y=np.array([1,1,1,1,1,2,2,2]) 6clf=GaussianNB() 7clf.partial_fit(X,y,classes=[1,2], 8sample_weight=np.array([0.05,0.05,0.1,0.1,0.1,0.2,0.2,0.2])) 9printclf.class_prior_10printclf.predict([[-6,-6],[4,5],[2,5]])11printclf.predict_proba([[-6,-6],[4,5],[2,5]])
输出结果如下所示:
1[0.40.6]2[122]3[[1.00000000e+004.21207358e-40]4[1.12585521e-121.00000000e+00]5[8.73474886e-111.00000000e+00]]
可以看到点[-6,-6]预测结果为1,[4,5]预测结果为2,[2,5]预测结果为2。同时,predict_proba(X)输出测试样本在各个类标记预测概率值。
7) score(X, y, sample_weight=None)
返回测试样本映射到指定类标记上的得分或准确率。
1pre=clf.predict([[-6,-6],[4,5],[2,5]])2printclf.score([[-6,-6],[4,5],[2,5]],pre)3#1.0
最后给出一个高斯朴素贝叶斯算法分析小麦数据集案例,代码如下:
1#-*-coding:utf-8-*- 2#第一部分载入数据集 3importpandasaspd 4X=pd.read_csv("seed_x.csv") 5Y=pd.read_csv("seed_y.csv") 6printX 7printY 8 9#第二部分导入模型10fromsklearn.naive_bayesimportGaussianNB11clf=GaussianNB()12clf.fit(X,Y)13pre=clf.predict(X)14printu"数据集预测结果:",pre1516#第三部分降维处理17fromsklearn.decompositionimportPCA18pca=PCA(n_components=2)19newData=pca.fit_transform(X)20printnewData[:4]2122#第四部分绘制图形23importmatplotlib.pyplotasplt24L1=[n[0]forninnewData]25L2=[n[1]forninnewData]26plt.scatter(L1,L2,c=pre,s=200)27plt.show()
输出如下图所示:
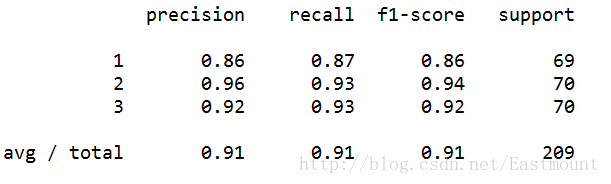
最后对数据集进行评估,主要调用sklearn.metrics类中classification_report函数实现的,代码如下:
1fromsklearn.metricsimportclassification_report2print(classification_report(Y,pre))
运行结果如下所示,准确率、召回率和F特征为91%。
补充下Sklearn机器学习包常用的扩展类。
1#监督学习 2sklearn.neighbors#近邻算法 3sklearn.svm#支持向量机 4sklearn.kernel_ridge#核-岭回归 5sklearn.discriminant_analysis#判别分析 6sklearn.linear_model#广义线性模型 7sklearn.ensemble#集成学习 8sklearn.tree#决策树 9sklearn.naive_bayes#朴素贝叶斯10sklearn.cross_decomposition#交叉分解11sklearn.gaussian_process#高斯过程12sklearn.neural_network#神经网络13sklearn.calibration#概率校准14sklearn.isotonic#保守回归15sklearn.feature_selection#特征选择16sklearn.multiclass#多类多标签算法1718#无监督学习19sklearn.decomposition#矩阵因子分解sklearn.cluster#聚类20sklearn.manifold#流形学习21sklearn.mixture#高斯混合模型22sklearn.neural_network#无监督神经网络23sklearn.covariance#协方差估计2425#数据变换26sklearn.feature_extraction#特征提取sklearn.feature_selection#特征选择27sklearn.preprocessing#预处理28sklearn.random_projection#随机投影29sklearn.kernel_approximation#核逼近
▌三. 中文文本数据集预处理
假设现在需要判断一封邮件是不是垃圾邮件,其步骤如下:
数据集拆分成单词,中文分词技术
计算句子中总共多少单词,确定词向量大小
句子中的单词转换成向量,BagofWordsVec
计算P(Ci),P(Ci|w)=P(w|Ci)P(Ci)/P(w),表示w特征出现时,该样本被分为Ci类的条件概率
判断P(w[i]C[0])和P(w[i]C[1])概率大小,两个集合中概率高的为分类类标
下面讲解一个具体的实例。
1.数据集读取
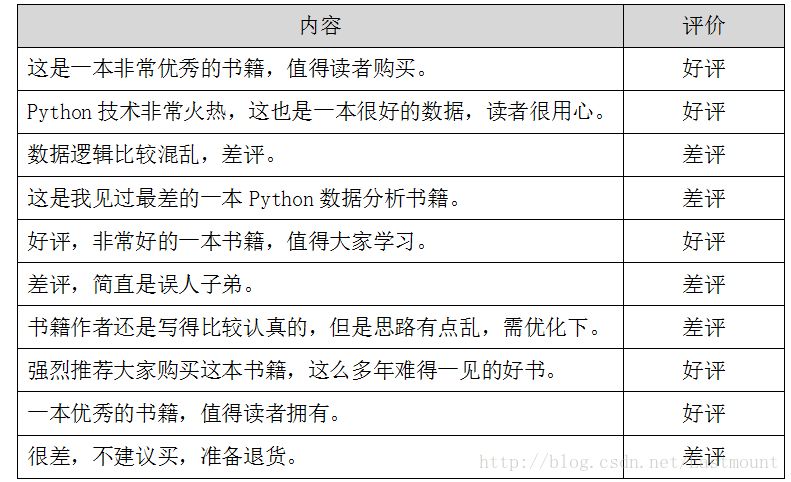
假设存在如下所示10条Python书籍订单评价信息,每条评价信息对应一个结果(好评和差评),如下图所示:
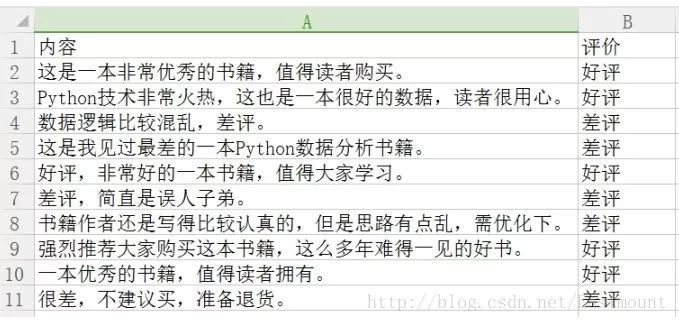
数据存储至CSV文件中,如下图所示。
下面采用pandas扩展包读取数据集。代码如下所示:
1#-*-coding:utf-8-*- 2importnumpyasnp 3importpandasaspd 4 5data=pd.read_csv("data.csv",encoding='gbk') 6printdata 7 8#取表中的第1列的所有值 9printu"获取第一列内容"10col=data.iloc[:,0]11#取表中所有值12arrs=col.values13forainarrs:14printa
输出结果如下图所示,同时可以通过data.iloc[:,0]获取第一列的内容。
2.中文分词及过滤停用词
接下来作者采用jieba工具进行分词,并定义了停用词表,即:
stopwords = {}.fromkeys([',', '。', '!', '这', '我', '非常'])
完整代码如下所示:
1#-*-coding:utf-8-*- 2importnumpyasnp 3importpandasaspd 4importjieba 5 6data=pd.read_csv("data.csv",encoding='gbk') 7printdata 8 9#取表中的第1列的所有值10printu"获取第一列内容"11col=data.iloc[:,0]12#取表中所有值13arrs=col.values14#去除停用词15stopwords={}.fromkeys([',','。','!','这','我','非常'])1617printu"
中文分词后结果:"18forainarrs:19#printa20seglist=jieba.cut(a,cut_all=False)#精确模式21final=''22forseginseglist:23seg=seg.encode('utf-8')24ifsegnotinstopwords:#不是停用词的保留25final+=seg26seg_list=jieba.cut(final,cut_all=False)27output=''.join(list(seg_list))#空格拼接28printoutput
然后分词后的数据如下所示,可以看到标点符号及“这”、“我”等词已经过滤。
3.词频统计
接下来需要将分词后的语句转换为向量的形式,这里使用CountVectorizer实现转换为词频。如果需要转换为TF-IDF值可以使用TfidfTransformer类。词频统计完整代码如下所示:
1#-*-coding:utf-8-*- 2importnumpyasnp 3importpandasaspd 4importjieba 5 6data=pd.read_csv("data.csv",encoding='gbk') 7printdata 8 9#取表中的第1列的所有值10printu"获取第一列内容"11col=data.iloc[:,0]12#取表中所有值13arrs=col.values14#去除停用词15stopwords={}.fromkeys([',','。','!','这','我','非常'])1617printu"
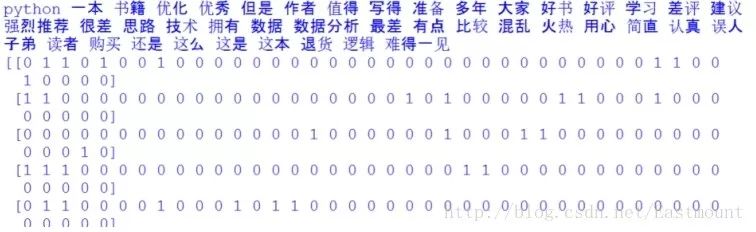
中文分词后结果:"18corpus=[]19forainarrs:20#printa21seglist=jieba.cut(a,cut_all=False)#精确模式22final=''23forseginseglist:24seg=seg.encode('utf-8')25ifsegnotinstopwords:#不是停用词的保留26final+=seg27seg_list=jieba.cut(final,cut_all=False)28output=''.join(list(seg_list))#空格拼接29printoutput30corpus.append(output)3132#计算词频33fromsklearn.feature_extraction.textimportCountVectorizer34fromsklearn.feature_extraction.textimportTfidfTransformer3536vectorizer=CountVectorizer()#将文本中的词语转换为词频矩阵37X=vectorizer.fit_transform(corpus)#计算个词语出现的次数38word=vectorizer.get_feature_names()#获取词袋中所有文本关键词39forwinword:#查看词频结果40printw,41print''42printX.toarray()
输出结果如下所示,包括特征词及对应的10行数据的向量,这就将中文文本数据集转换为了数学向量的形式,接下来就是对应的数据分析了。
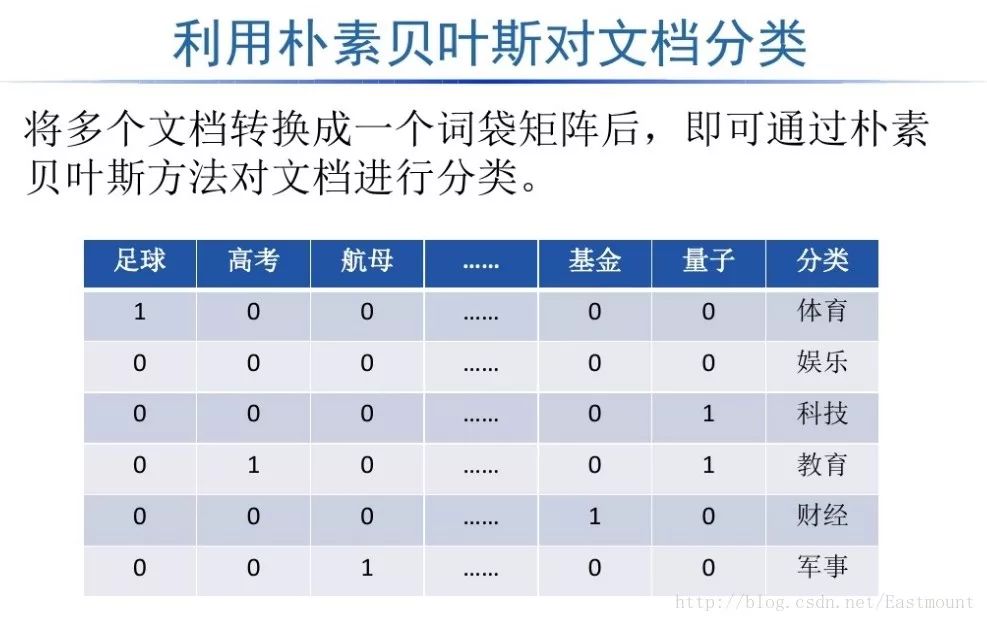
如下所示得到一个词频矩阵,每行数据集对应一个分类类标,可以预测新的文档属于哪一类。
TF-IDF相关知识推荐我的文章: [python] 使用scikit-learn工具计算文本TF-IDF值(https://blog.csdn.net/eastmount/article/details/50323063)
▌四. 朴素贝叶斯中文文本舆情分析
最后给出朴素贝叶斯分类算法分析中文文本数据集的完整代码。
1#-*-coding:utf-8-*- 2importnumpyasnp 3importpandasaspd 4importjieba 5 6#http://blog.csdn.net/eastmount/article/details/50323063 7#http://blog.csdn.net/eastmount/article/details/50256163 8#http://blog.csdn.net/lsldd/article/details/41542107 910####################################11#第一步读取数据及分词12#13data=pd.read_csv("data.csv",encoding='gbk')14printdata1516#取表中的第1列的所有值17printu"获取第一列内容"18col=data.iloc[:,0]19#取表中所有值20arrs=col.values2122#去除停用词23stopwords={}.fromkeys([',','。','!','这','我','非常'])2425printu"
中文分词后结果:"26corpus=[]27forainarrs:28#printa29seglist=jieba.cut(a,cut_all=False)#精确模式30final=''31forseginseglist:32seg=seg.encode('utf-8')33ifsegnotinstopwords:#不是停用词的保留34final+=seg35seg_list=jieba.cut(final,cut_all=False)36output=''.join(list(seg_list))#空格拼接37printoutput38corpus.append(output)3940####################################41#第二步计算词频42#43fromsklearn.feature_extraction.textimportCountVectorizer44fromsklearn.feature_extraction.textimportTfidfTransformer4546vectorizer=CountVectorizer()#将文本中的词语转换为词频矩阵47X=vectorizer.fit_transform(corpus)#计算个词语出现的次数48word=vectorizer.get_feature_names()#获取词袋中所有文本关键词49forwinword:#查看词频结果50printw,51print''52printX.toarray()535455####################################56#第三步数据分析57#58fromsklearn.naive_bayesimportMultinomialNB59fromsklearn.metricsimportprecision_recall_curve60fromsklearn.metricsimportclassification_report6162#使用前8行数据集进行训练,最后两行数据集用于预测63printu"
数据分析:"64X=X.toarray()65x_train=X[:8]66x_test=X[8:]67#1表示好评0表示差评68y_train=[1,1,0,0,1,0,0,1]69y_test=[1,0]7071#调用MultinomialNB分类器72clf=MultinomialNB().fit(x_train,y_train)73pre=clf.predict(x_test)74printu"预测结果:",pre75printu"真实结果:",y_test7677fromsklearn.metricsimportclassification_report78print(classification_report(y_test,pre))
输出结果如下所示,可以看到预测的两个值都是正确的。即“一本优秀的书籍,值得读者拥有。”预测结果为好评(类标1),“很差,不建议买,准备退货。”结果为差评(类标0)。
1数据分析:2预测结果:[10]3真实结果:[1,0]4precisionrecallf1-scoresupport5601.001.001.001711.001.001.00189avg/total1.001.001.002
但存在一个问题,由于数据量较小不具备代表性,而真实分析中会使用海量数据进行舆情分析,预测结果肯定页不是100%的正确,但是需要让实验结果尽可能的好。最后补充一段降维绘制图形的代码,如下:
1#降维绘制图形 2fromsklearn.decompositionimportPCA 3pca=PCA(n_components=2) 4newData=pca.fit_transform(X) 5printnewData 6 7pre=clf.predict(X) 8Y=[1,1,0,0,1,0,0,1,1,0] 9importmatplotlib.pyplotasplt10L1=[n[0]forninnewData]11L2=[n[1]forninnewData]12plt.scatter(L1,L2,c=pre,s=200)13plt.show()
输出结果如图所示,预测结果和真实结果都是一样的,即[1,1,0,0,1,0,0,1,1,0]。
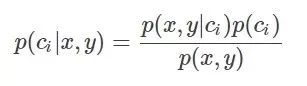




-
数据集
+关注
关注
4文章
1240浏览量
26261 -
贝叶斯分类器
+关注
关注
0文章
6浏览量
2468
原文标题:朴素贝叶斯分类器详解及中文文本舆情分析(附代码实践)
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
VirtualLab:光栅的优化与分析
小红书API+AI:舆情监控新利器
摩尔斯微电子任命乔·贝德维(Joe Bedewi)为首席财务官




评论